细谈Hadoop生态圈
Hadoop生态系统
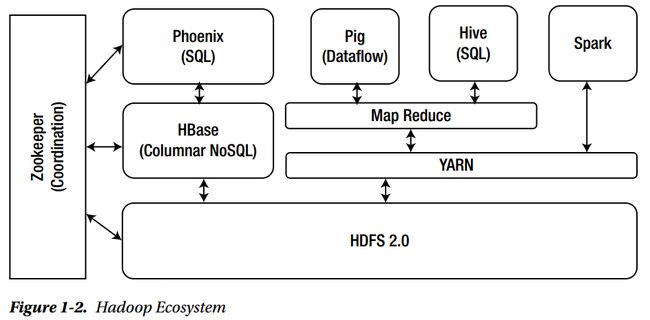
Hadoop在过去的几年里已经变得很成熟了。下面的图1-2显示了Hadoop生态系统堆栈。Apache Phoenix是HBase的SQL包装,它需要基本的HBase理解,在某种程度上,还需要理解它原生的调用行为。了解其他Hadoop生态系统组件以及HBase,将有助于更好地理解大数据领域,并利用Phoenix及其最佳可用特性。在本章中,我们将概述这些组件及其在生态系统中的位置。
HDFS
HDFS (Hadoop分布式文件系统)是一个分布式文件系统,提供高吞吐量的数据访问。HDFS以块的形式存储数据。旧版本,每个块64 MB,新Hadoop版本,每个块128 MB。大于块大小的文件将自动分割成多个块,并存储备份在各个节点上,默认情况下每个块的副本数为3;这意味着每个块将在三个节点上可用,以确保高可用性和容错性。副本数是可配置的,可以在HDFS配置文件中更改。
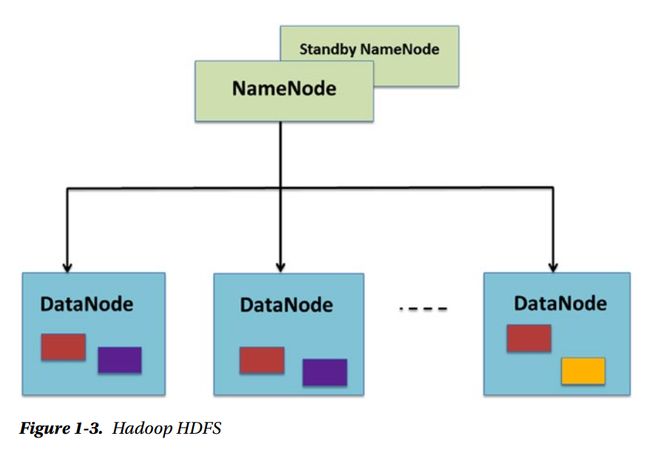
NameNode: NameNode负责协调和管理系统中的其他节点。NameNode是整个系统的管理者。它通过元数据使用命名系统来跟踪文件和目录。它管理存储在数据节点(包含实际数据的节点)上的数据块。可以将NameNode配置为高可用性,备用节点中的备份节点和主节点作为活动节点。
Datanode: Datanode是集群中实际存储数据(HDFS块)的机器。在HDFS中,数据块分布在网络上。数据块被复制到多个数据节点上,以处理节点故障场景。数据节点服务器向客户端提供数据块的读写请求。
Secondary NameNode :Secondary NameNode 提供内存或磁盘存储本地数据的备份。它定期连接到主NameNode,并在内存中执行元数据备份检查点。如果NameNode失败,您可以使用收集到的检查点信息重新构建NameNode。在当前的Hadoop版本中,Secondary NameNode 几乎被弃用,并且没有被大量使用。
下图(见图1-3)显示了HDFS组件和块的数据存储。
MapReduce
Hadoop MapReduce是一个软件框架,我们可以使用它轻松地编写应用程序,以可靠的、容错的方式并行处理大量数据。MapReduce是一种包含Map和Reduce两种算法的编程技术。
Map任务:Map stage或mapper的工作是处理输入并将其转换为键/值对形式的较小部分。
Reduce任务:Reduce阶段或减速器的工作是将阶段数据输出处理为更小的元组(键/值对)。这个阶段结合了shuffle和reduce任务。

让我们以单词计数为例来理解MapReduce是如何工作的。
单词计数问题是一个非常基本的例子,就像Java编程中的HelloWorld一样,Hadoop开发人员通常从WordCount开始他们的MapReduce编程。在下面的示例中,使用MapReduce计算输入文件中每个单词出现的次数。
单词计数处理分两个阶段进行:映射阶段和减速器阶段。在mapper阶段(由mapper完成),首先将输入标记为单词,然后我们用这些单词组成键/值对,其中键是单词本身,值是单词的计数,所以这里的值是“1”。
例如,将这句话作为MapReduce处理的输入:
“hello phoenix world by phoenix”
在map阶段,句子被分成单词,每个单词被分配给一个初始键值对,反映一个单一的事件:
在reduce阶段,将键组合在一起,并添加类似键的值。因此,只有一对类似的键,这些键的值(count)将被添加,因此输出键/值对将是
这给出了输入文件中每个单词的出现次数。因此,减速机形成了映射键的聚合。我们还可以在reduce阶段应用排序。这里需要注意的一点是,首先映射器在整个数据集中完全执行,分解单词并使它们的键值对。只有mapper完成其过程后,减速器才会启动。假设我们的输入文件中总共有50行,首先对50行进行标记,并并行地形成键值对(每个节点并行执行的任务);只有在此之后,减速器才会开始聚合。
请参见下面的图1-5,以了解如何对单词计数示例进行MapReduce处理。

在这里,我们将不描述如何用Java或任何其他语言实现MapReduce。其目的是说明MapReduce概念。
HBase
HBase是一个运行在Hadoop HDFS之上的NoSQL列族数据库。HBase是为处理具有数十亿行和数百万列的大型存储表而开发的,具有容错能力和水平可伸缩性。HBase概念的灵感来自谷歌的Big Table。Hadoop主要用于批处理,在批处理中,数据只能按顺序访问,其中HBase用于快速随机访问海量数据。
HBase是一个分布式的、面向列的NoSQL数据库,它使用HDFS作为底层存储。我们已经提到过,HDFS使用的是写一次和读多次(WORM)模式,但并不总是这样。有时甚至一个巨大的数据集也需要实时的读/写随机访问;这就是HBase发挥作用的地方。HBase构建在HDFS之上,并分布在一个面向列的数据库上。
图1-6显示了一个简单的HBase体系结构及其组件。

Hive
Hive是一种交互式的、简单的、类似sql的脚本语言,用于查询存储在HDFS中的数据。虽然我们可以使用Java来处理HDFS,但是许多数据程序员最习惯使用SQL。Hive最初由Facebook创建,用于自己的基础设施处理,后来他们将其开源并捐赠给Apache软件基金会。Hive的优点是它在幕后运行MapReduce作业,但是程序员不必担心这是如何发生的。程序员只需编写HQL (Hive查询语言),结果就会显示在控制台上。
Hive是Hadoop生态系统的一部分,它为Hadoop的底层HDFS提供了一个类似sql的交互界面。您可以编写特别查询并分析存储在HDFS中的大型数据集。当用Hive查询语言编写这种逻辑不方便或效率低下时,程序员可以插入他们的定制映射器和缩减器。
Hive可以分为以下几个部分:
元数据存储:包含关于分区、列和系统目录的元数据。
驱动程序:为HQL (Hive查询语言)语句生命周期提供管理。
查询编译器:将HQL编译成一个有向无环图。
执行引擎:按编译器生成任务的顺序执行任务。
HiveServer:提供一个节俭的接口和JDBC/ODBC服务器。
Yarn
Apache HadoopYarn是Apache Software Foundation (ASF)中Apache Hadoop的一种集群管理技术,与其他HDFS、Hadoop Common和MapReduce一样是hadoop的一个子项目。Yarn是另一个资源管理平台。yarn是一个通用的分布式应用程序管理框架,它取代了用于处理Hadoop集群中的数据的经典MapReduce框架。
在Hadoop生态系统中,HDFS是存储层,MapReduce是数据处理层。然而,MapReduce算法对于各种用例来说是不够的。yarn是一个中央资源管理器和分布式应用程序框架,可用于多个数据处理应用程序。它将应用程序使用资源的方式与监视单个集群节点的处理操作的节点管理器代理进行协调。
Spark
Apache Spark是一个开放源码的快速内存数据处理引擎,旨在提高速度、易用性和复杂的分析能力。Spark用于管理文本数据、图形数据等多种数据集的大数据处理,以及数据来源(批量/实时流数据)。Spark允许Hadoop中的应用程序在内存中运行,这比在磁盘上运行快得多。除了Map和Reduce操作之外,Spark还支持流数据、SQL查询、机器学习和图形数据处理。除此之外,它还减少了维护单独工具的管理问题。
Pig
Apache Pig用于查询存储在Hadoop集群中的数据。它允许用户使用高级的类似SQL的脚本语言Pig Latin编写复杂的MapReduce转换。Pig通过使用它的Pig引擎组件将Pig拉丁脚本转换成MapReduce任务,这样它就可以在YARN中执行,从而访问存储在HDFS中的单个数据集。程序员不需要为MapReduce任务编写复杂的Java代码,而是可以使用Pig Latin来执行MapReduce任务。SQL开发人员喜欢编写脚本,而Pig Latin是他们的首选代码。Apache Pig提供了嵌套的数据类型,如元组、包和映射,这些数据类型是MapReduce中缺少的,同时还提供了内置的操作符,如连接、过滤器和排序等。
Zookeeper
由于主机之间可能发生部分故障,所以很难编写分布式应用程序。Apache Zookeeper就是为了缓解这个问题而开发的。Zookeeper维护一个开源服务器,它支持高度可靠的分布式协调。
Zookeeper框架由Yahoo创建,供内部使用,并捐赠给开源社区。Zookeeper是一个分布式协调服务,它管理大量节点。在任何部分故障时,客户端可以连接到任何节点以接收正确的最新信息。没有管理员,HBase无法运行。ZooKeeper是Apache Phoenix中协调服务的关键组件。
Zookeeper处理应用程序的分布式特性,让程序员专注于应用程序逻辑。
phoenix在大数据系统中的地位
虽然Phoenix不是Hadoop生态系统不可分割的一部分,但它是有效使用Hadoop的必要工具。现在,它正在吸引那些编写查询来处理HBase数据的程序员。在本节中,我们将从数据库管理员的角度研究执行大数据分析的挑战,以及Phoenix如何帮助减轻这些挑战。
Phoenix 在 Hadoop 生态系统
编写代码的开发人员可以使用HBase API从HBase存储、检索或查询数据。与用Java或其他语言编写代码相比,许多程序员更喜欢结构化查询语言(SQL)。Phoenix是一种SQL接口,可以用来查询HBase存储中的数据。它是一个为用户提供工具的系统,可以进行强大的查询并获得结果,通常是实时的。与Hive相比,Phoenix对Hbase进行了高度优化,提供了比其他类似框架更好的性能,并支持许多其他有趣的特性,我们将在接下来的章节中讨论这些特性。HBase用作Hadoop的主数据库,也称为Hadoop的数据库。Phoenix作为Hbase的SQL接口,在hadoop相关的大数据分析中发挥着至关重要的作用。
请参阅下面的示例Phoenix查询示例,该查询从employee表检索记录。如果您分析查询,您会发现它与SQL相似,并且易于编写和理解。
例如:
SELECT EMP_ID, FNAME,CITY FROM EMPLOYEE;
Apache Phoenix的大数据分析
大数据的增长使得企业参与云计算和物联网等技术的使用变得至关重要。大数据分析对于组织跟上市场趋势变得越来越必要。Phoenix和其他大数据工具正在获得发展势头,因为它们支持舒适的类似sql的界面、可读性和快速学习曲线。在幕后,Phoenix将SQL查询编译为HBase本机调用,并并行运行扫描或计划进行优化。Phoenix应用程序可以根据用户的要求运行MapReduce作业,并利用大数据的基本原理,但程序员不需要知道这些;他或她应该专注于业务逻辑和编写脚本来访问大数据存储。
Apache Phoenix在其领域内比其他可用工具更受欢迎。其优点在于Phoenix提供了一些特性,比如跳过全表扫描、提高整个系统的性能、服务器/客户机端并行化、过滤器下推和Phoenix查询服务器,从而将处理与应用程序、事务和辅助索引解耦。Phoenix查询与SQL非常相似,这使得每个传统数据库管理员都喜欢它。当然,还有许多其他工具可以与大数据系统交互来查询和执行分析,但是Phoenix对HBase的强大支持和优化使得它更有可能成为使用Hadoop HBase数据库的首选SQL接口。尽管它不是Hadoop生态系统的必要部分,但对Hbase的需求很大。Phoenix与诸如Spark、Flume、Hive、Pig和MapReduce等etl的大数据技术的集成使其成为Hadoop生态系统中受欢迎的一部分。
传统的基于sql的工具的重要性和Phoenix的作用
几十年来,SQL一直是与关系数据库系统交互的主要工具。人们熟悉并熟悉这种技术及其语法。在大数据的世界里,没有像SQL这样的标准工具,但是许多分销商提供了选项,为查询大数据系统提供类似SQL的接口。这些工具针对底层支持进行了优化,速度足以查询数百万行。phoenix,hive,和其他属于这一类。
如果你是DBA,你可能不想学习或理解在Hadoop系统中处理数据的Java代码。这些工具提供了这种支持;您不必是开发人员才能理解Hadoop API来查询数据。Phoenix为您提供了编写查询的灵活性,就像处理数据时编写SQL一样。