KNN缺失填补knnimpute/impyute/fancyimpute
常见的数据缺失填充方式分为很多种,比如删除法、均值法、回归法、KNN、MICE、EM等等。R语言包中在此方面比较全面,python稍差。
目前已有的两种常见的包,第一个是impyute,第二个是fancyimpute,具体的内容请百度,此方面的例子不是很多。比如fancyimpute中也集成了很多方式,包括均值、众数、频数填充,KNN填充、MCMC填充等。
本文主要对其中几种情况做个简单的介绍和附上相关的连接。
1. impyute/fancyimpute
两者为python的包,需要安装,里面集成了多种方法 。具体的方法参见链接。
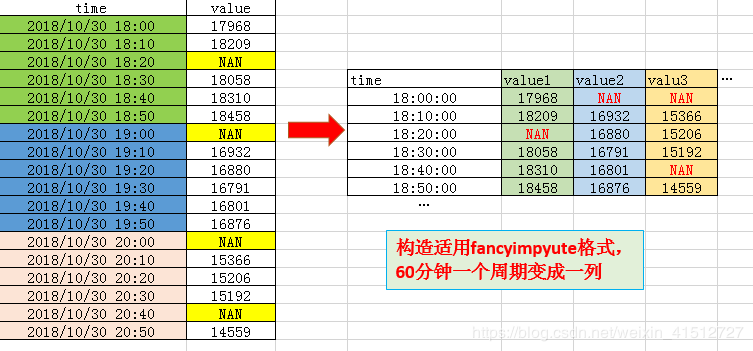
如果要使用fancyimpute,需要构造数据格式。下面是我构造的格式,如果你有其他的好办法,请留言。谢谢。
import pandas as pd
import numpy as np
from fancyimpute import KNN
import re
#KNN缺失数据填补
def knn_filled(df1) :
#数据
df = pd.read_csv("xxx.csv")
#缺失填补
if df.sump.isnull().any():#判断数据是否有null
data = pd.DataFrame()
for i in range(0,df.shape[0],6):# 以60分钟为周期分段(10分钟粒度, 6个为周期)
data1 = df["sump"][i:i+6].reset_index(drop = True).rename(index = str(i))
data = pd.concat((data, data1), axis = 1) #整合为一个dataframe,多个列
data_incomplete = np.array(data)#转为array
#预测缺失值
filled_knn = KNN(k=3).fit_transform(data_incomplete)#利用knn填补缺失值
data_complete = pd.DataFrame(filled_knn)#保存结果
for i in range(0, df.shape[0],6):#把之前构造的多个列,在整合为一个列
df.loc[i:i+287,"sump"]=data_complete.loc[:,i/288].values.tolist()
return dfhttps://impyute.readthedocs.io/en/latest/
https://github.com/eltonlaw/impyute
https://github.com/iskandr/knnimpute/tree/master/test
https://github.com/iskandr/fancyimpute/blob/master/fancyimpute/knn.py
2. KNN缺失值填补法
from sklearn.neighbors import KNeighborsClassifier, KNeighborsRegressor
def knn_missing_filled(x_train, y_train, test, k = 3, dispersed = True):
if dispersed:
clf = KNeighborsClassifier(n_neighbors = k, weights = "distance")
else:
clf = KNeighborsRegressor(n_neighbors = k, weights = "distance")
clf.fit(x_train, y_train)
return test.index, clf.predict(test)
首先从sklearn包中导入k近邻,第一个是分类器,第二个是回归器。
参数:
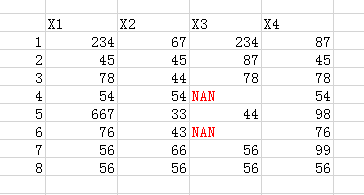

图1 原始数据(x3为预测列) 图2x_train/y_train(x1,x2,x4为训练列)
(其中x_train为蓝色部分,就是非预测列以为的,不存在nan行的列),(y_train为预测列中,非nan的部分)

图3 test(出去存在nan值得行,除了预测列的所有行)
train_x和train_y:表示模型训练集的x和y
test:待填补的缺失样本
k:K近邻的K值,此处默认为3
dipersed:待填补的缺失变量是否离散,默认是,则用K近邻分类器,投票选出K个邻居中最多的类别进行填补;如为连续变量,则用K近邻回归器,拿K个邻居中该变量的平均值填补。
返回:
待填补数据集的行号,预测的用于填补的值
KNN模型参数:
n_neighbors-KNN的K,weights-样本的权重,distance为用样本间的距离(默认欧式距离)作为权重,样本间距离越近越”重要“,n_jobs-设置跑模型时,参与计算的cpu核心的个数,-1为建模时使用cpu的所有核心;fit方法表示进行拟合模型的操作,predict表示作预测,事实上,大多数sklearn模型都有fit和predict方法,含义相同。
参考:
https://mp.weixin.qq.com/s?__biz=MzIzNDk0ODIxNg==&mid=2247483697&idx=1&sn=769babea47a36fcd2eb27e9b5586b227&chksm=e8efd226df985b3049d98471c463705161e8c2412e28e5f5d09dc6e68c675875799bc56d9621&mpshare=1&scene=1&srcid=1019sGnZIzqL4buSlqvXwydT#rd