论文阅读:More Data, More Relations, More Context and More Openness:A Review and Outlook for RE关系抽取的回顾与展望
More Data, More Relations, More Context and More Openness:A Review and Outlook for Relation Extraction
关系抽取的回顾与展望
目录
- More Data, More Relations, More Context and More Openness:A Review and Outlook for Relation Extraction
- 关系抽取的回顾与展望
- 摘要
- 1 引言
- 2 背景和现有工作
- 2.1 模式抽取模型
- 2.2 统计关系抽取模型
- 2.3 神经关系抽取模型
- 3 RE的“更多”指示
- 3.1 利用更多数据
- 3.2 进行更有效的学习
- 3.3 处理更复杂的上下文
- 3.4 定向更多开放域
- 4 其他挑战
- 4.1 从文本或名称中学习
- 4.2 针对特殊兴趣的RE数据集
- 5 结论
摘要
关系事实是人类知识的重要组成部分,隐藏在大量文本中。为了从文本中抽取这些事实,人们多年来一直在进行关系抽取(RE)。从早期的模式匹配到当前的神经网络,现有的RE方法已经取得了重大进展。但是随着Web文本的爆炸式增长和新关系的出现,人类的知识正在急剧增加,因此我们要求RE提供“更多”的知识:功能更强大的RE系统,可以可靠地利用更多数据,有效地学习更多关系,轻松处理更复杂的上下文,并灵活地推广到更多开放域。在本文中,我们回顾了现有的RE方法,分析了当前我们面临的主要挑战,为更强大的RE指明了希望的发展方向。我们希望我们的观点能够推动这一领域的发展,并激励社会做出更大的努力。
1 引言
关系事实以三元组形式表现世界知识。这些结构化事实充当人类知识的重要角色,并以显式或隐式隐藏在文本中。例如,“Steve Jobs co-founded Apple”表明了事实(Apple Inc., founded by, Steve Jobs),我们还可以从“Hamilton made its debut in New York, USA”推断出事实(USA,contains,New York)。
由于这些结构化事实可以使下游应用受益,例如知识图谱的完成(Bordes et al., 2013; Wang et al., 2014),搜索引擎(Xiong et al., 2017; Schlichtkrull et al.,2018)和问答(Bordes et al., 2014;Dong et al., 2015),人们致力于研究关系抽取(RE),旨在从纯文本中抽取关系事实。更具体地说,在识别实体提及之后(例如USA and New York),RE的主要目标是从上下文中对这些实体提及之间的关系进行分类(例如contains)。
对RE的开拓性探索在于统计方法,例如模式挖掘(Huffman,1995; Califf and Mooney, 1997),基于特征的方法(Kambhatla, 2004)和图模型(Roth and Yih, 2002)。近年来,随着深度学习的发展,神经模型已广泛应用于RE(Zeng et al., 2014; Zhang et al., 2015),并取得了较好的效果。这些RE方法弥合了非结构化文本和结构化知识之间的鸿沟,并在几种公共基准上显示了其有效性。
尽管现有的RE方法取得了成功,但大多数方法仍在简化的环境中工作。这些方法主要集中在具有大量人工注释的训练模型上,以将一句话中的两个给定实体分类为预定义关系。但是,现实世界比这种简单的设置要复杂得多:(1)收集高质量的人工注释既昂贵又耗时;(2)许多长尾关系无法提供大量的训练示例;(3)大多数事实由包含多个句子的较长上下文表示,而且(4)很难使用预定义集合来覆盖那些开放式增长的关系。因此,要为实际部署构建有效而强大的RE系统,还有一些更复杂的场景需要进一步研究。
在本文中,我们回顾了现有的RE方法(第2节)以及针对更复杂的RE场景的最新RE探索(第3节)。那些导致更好的RE能力的可行方法仍然需要进一步的努力,在这里我们将它们概括为四个方向:
(1)利用更多数据(第3.1节)。监督式RE方法严重依赖于昂贵的人工注释,而远程监督(Mintz et al.,2009)引入了更多的自动标记数据来缓解这一问题。然而,远程的方法带来了噪声示例,仅能提及实体对的单个句子,这大大削弱了提取性能。设计模式以获取高质量和高覆盖率的数据以训练RE模型的鲁棒性仍然是一个有待探索的问题。
(2)进行更有效的学习(第3.2节)。许多长尾关系仅包含一些训练示例。但是,传统的RE方法很难很好地概括人类等有限实例的关系模式。因此,开发有效的学习模式以更好地利用有限或小样本的例子是一个潜在的研究方向。
(3)处理更复杂的上下文(第3.3节)。许多关系事实是在复杂的上下文中表达的(例如,多个句子或文档),而大多数现有的RE模型都侧重于提取句子内关系。为了涵盖这些复杂的事实,在更复杂的环境中研究RE是很有价值的。
(4)面向更多开放域(第3.4节)。每天都有来自现实世界中不同领域的新关系出现,因此很难一一涵盖。但是,常规的RE框架通常设计用于预定义关系。因此,如何在开放域中自动检测未定义的关系仍然是一个公认问题。
除了介绍有希望的方向外,我们还指出了现有方法的两个主要挑战:(1)从文本或名称中学习(第4.1节)和(2)针对特殊兴趣的数据集(第4.2节)。我们希望所有这些内容可以鼓励社会进一步探索和突破,以实现更好的RE。
2 背景和现有工作
==信息抽取(IE)==旨在从非结构化文本中提取结构信息,这是自然语言处理(NLP)的重要领域。==关系抽取(RE)==作为IE中的一项重要任务,特别着重于抽取实体之间的关系。完整的关系抽取系统包括:一个命名实体识别器,用于从文本中识别命名实体(例如,people, organizations, locations);一个实体链接器,用于将实体链接到现有知识图谱(KGs, necessary when using relation extraction for knowledge graph completion),以及一个关系分类器来确定给定上下文的实体之间的关系。
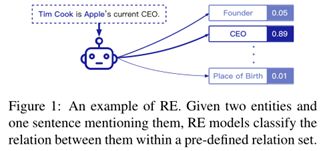
在这些步骤中,关系识别是最关键和最困难的任务,因为它需要模型来很好地理解上下文的语义。因此,RE通常专注于研究分类部分,这也称为关系分类。如图1所示,典型的RE设置是给定一个带有两个标记实体的句子,模型需要将该句子分类为一种预定义关系。
在本节中,我们将按照典型的监督设置介绍RE方法的开发,从早期的基于模式的方法、统计的方法到最新的神经模型。
2.1 模式抽取模型
开创性方法是使用句子分析工具来识别文本中的句法元素,然后根据这些元素自动构建模式规则(Soderland et al., 1995; Kim and Moldovan,1995; Huffman, 1995; Califf and Mooney, 1997)。为了抽取具有更好覆盖率和准确性的模式,以后的工作涉及更大的语料库(Carlson et al., 2010),更多模式的格式(Nakashole et al., 2012; Jiang et al., 2017)以及更有效的抽取方法(Zheng et al.,2019)。由于自动构建的模式可能会出错,因此上述大多数方法都需要由专家进行进一步检查,这是基于模式的模型的主要局限性。
2.2 统计关系抽取模型
与使用模式规则相比,统计方法具有更好的覆盖范围,且需要更少的人力。因此,对统计关系抽取(SRE)进行了广泛的研究。
一种典型的SRE方法是基于特征的方法(Kambhatla, 2004; Zhou et al., 2005;Jiang and Zhai, 2007; Nguyen et al., 2007),它为实体对及其对应的上下文设计了词汇、句法和语义特征,然后将这些特征输入到关系分类器中。
由于支持向量机(SVM)的广泛使用,已经广泛探索了核方法,该方法设计了SVM的核功能以测量关系表示和文本实例之间的相似性(Culotta and Sorensen, 2004; Bunescu and Mooney, 2005; Zhao and Grishman, 2005; Mooney and Bunescu, 2006;Zhang et al., 2006b,a; Wang, 2008)。
还有一些其他的统计方法,着重于抽取和推断隐藏在文本中的潜在信息。图解法(Roth and Yih, 2002, 2004; Sarawagi and Cohen, 2005; Yu and Lam, 2010)以有向无环图的形式抽象实体、文本和关系之间的依赖关系,然后使用推理模型来识别正确的关系。
受到其他NLP任务中成功嵌入模型的启发(Mikolov et al., 2013a,b),人们也在努力将文本编码到低维语义空间中,并从文本嵌入中抽取关系(Weston et al., 2013; Riedel et al.,2013; Gormley et al., 2015)。此外,Bordes et al. (2013),Wang et al. (2014) and Lin et al. (2015)利用KG嵌入进行RE。
尽管对SRE进行了广泛研究,但仍然面临一些挑战。基于特征和基于核的模型需要付出很多努力来设计功能或内核功能。尽管图和嵌入方法可以在无需过多人工干预的情况下预测关系,但是它们在模型能力方面仍然受到限制。有一些调查系统地介绍了SRE模型(Zelenko et al.,2003; Bach and Badaskar, 2007; Pawar et al., 2017)。在本文中,我们不会在SRE上花费太多的空间,而将更多的精力放在基于神经的模型上。
2.3 神经关系抽取模型
神经关系抽取(NRE)模型引入了神经网络以自动从文本中抽取语义特征。与SRE模型相比,NRE方法可以有效地捕获文本信息并推广到更广泛的数据范围。
NRE的研究主要集中在设计和利用各种网络体系结构来捕获文本中的关系语义,例如递归神经网络(Socher et al., 2012; Miwa and Bansal, 2016),它以递归方式学习句子的组成表示;卷积神经网络(CNNs)(Liu et al., 2013; Zeng et al., 2014; Santos et al., 2015; Nguyen and Grishman, 2015b; Zeng et al., 2015; Huang and Wang,2017)有效地建模了本地文本模式;递归神经网络(RNNs)(Zhang and Wang, 2015; Nguyen and Grishman, 2015a; Vu et al., 2016; Zhang et al., 2015)可以更好地处理较长的顺序数据;图神经网络(GNNs)(Zhang et al., 2018; Zhu et al.,2019a)构建用于推理的词/实体图;以及基于注意力的神经网络(Zhou et al., 2016; Wang et al., 2016; Xiao and Liu, 2016),利用注意力机制来汇总全局关系信息。
与SRE模型不同,NRE主要利用词嵌入和位置嵌入代替输入的手工特征。词嵌入(Turian et al., 2010; Mikolov et al.,2013b)是NLP中最常用的输入表示形式,其将词的语义编码为向量。为了在文本中捕获实体信息,引入了位置嵌入(Zeng et al., 2014)来指定词和实体之间的相对距离。除了词嵌入和位置嵌入,还有其他将语法信息集成到NRE模型中的工作。Xu et al. (2015a) 和 Xu et al. (2015b) 分别在最短的依赖路径上采用了CNNs和RNNs。Liu et al. (2015) 提出了一种基于增强依赖路径的递归神经网络。Xu et al. (2016) 和Cai et al. (2016) 利用深层RNNs来进一步利用依赖路径。此外,还有一些努力将NRE与通用模式结合起来(Verga et al., 2016; Verga and McCallum, 2016; Riedel et al., 2013)。最近,针对NRE也探索了Transformers(Vaswani et al., 2017)和预训练语言模型(Devlin et al., 2019)(Du et al., 2018; Verga et al., 2018;Wu and He, 2019; Baldini Soares et al., 2019),并取得了新技术的最新突破。
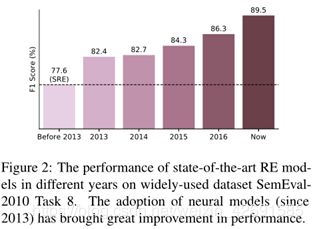
通过简要回顾上述技术,我们能够跟踪RE从模式和统计方法到神经模型的发展。比较多年来最先进的RE模型的性能(图2),我们可以看到自NRE出现以来的巨大增长,这证明了神经方法的强大功能。
3 RE的“更多”指示
尽管上述NRE模型在基准测试中取得了优异的结果,但距离解决RE问题还差很远。这些模型中的大多数都利用大量的人工注释,并且仅抽取单个句子中的预定义关系。因此,它们很难在复杂的情况下工作。实际上,已经有各种各样的工作在探索可行的方法,这些方法可以在现实世界中实现更好的RE能力。在本节中,我们将这些探索性工作总结为四个方向,并对这些方向进行回顾和展望。
3.1 利用更多数据
受监督的NRE模型缺乏大规模的高质量训练数据,因为手动标记数据既费时又费力。为了缓解这个问题,远程监督(DS)假设已用于通过将现有KG与纯文本对齐来自动标记数据(Mintz et al., 2009; Nguyen and Moschitti, 2011; Min et al., 2013)。如图3所示,对于KG中的任何实体对,提及两个实体的句子将在KG中标有它们的对应关系。通过这种启发式方案可以轻松构建大规模的训练示例。
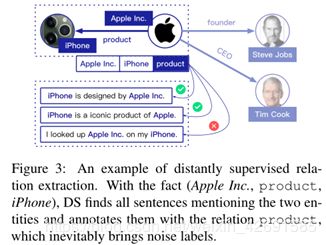 尽管DS提供了一种利用更多数据的可行方法,但是这种自动标记机制不可避免地会伴随着错误的标记问题。原因是并非所有提及两个实体的句子都准确地表达了它们之间的关系。例如,如果(Bill Gates, founder, Microsoft)是KGs中的关系事实,我们可能会错误地用关系创建者来标记“Bill Gates retired from Microsoft”。
尽管DS提供了一种利用更多数据的可行方法,但是这种自动标记机制不可避免地会伴随着错误的标记问题。原因是并非所有提及两个实体的句子都准确地表达了它们之间的关系。例如,如果(Bill Gates, founder, Microsoft)是KGs中的关系事实,我们可能会错误地用关系创建者来标记“Bill Gates retired from Microsoft”。
现有的减轻噪声问题的方法可分为三种主要方法:
(1)一些方法采用多实例学习,即将具有相同实体对的句子组合在一起,然后从中选择信息量大的实例。 Riedel et al. (2010); Hoffmann et al. (2011); Surdeanu et al. (2012) 利用图形模型来推断信息句子,而Zeng et al. (2015) 使用简单的启发式选择策略。后来,Lin et al. (2016); Zhang et al. (2017); Han et al. (2018c); Li et al. (2019); Zhu et al. (2019c); Hu et al. (2019) 设计注意力机制以突出RE的信息实例。
(2)还探索了将额外的上下文信息用于去噪DS数据的方法,例如将KG用作外部信息来指导实例选择(Ji et al., 2017; Han et al., 2018b;Zhang et al., 2019a; Qu et al., 2019),并采用多语言语料库来实现信息的一致性和互补性(Verga et al., 2016; Linet al., 2017; Wang et al., 2018)。
(3)许多方法倾向于利用复杂的机制和训练策略来增强远程监督的NRE模型。 Vu et al. (2016) ;Beltagy et al. (2019) 结合了不同的架构和训练策略来构建混合框架。Liu et al. (2017) 通过在训练期间更改未确认的标签来合并软标签方案。此外,强化学习(Feng et al., 2018; Zeng et al., 2018)和对抗训练(Wu et al., 2017; Wang et al., 2018; Han et al., 2018a)也已在DS中采用。
研究人员已经达成共识,即利用更多数据是建立更强大的RE模型的潜在方法,但仍然存在一些值得探讨的未解决问题:
(1)现有的DS方法着重于对自动标记的实例进行去噪,因此遵循它当然是有意义的这个研究方向。此外,当前的DS方案仍与(Mintz et al., 2009)中的原始DS方案相似,后者仅涵盖了在同一句子中提到实体对的情况。为了获得更好的覆盖范围和更少的噪声,探索更好的DS方案来自动标记数据也很有价值。
(2)受最近采用预训练语言模型(Zhang et al., 2019b; Wu and He, 2019; Baldini Soares et al., 2019)和主动学习RE(Zheng et al., 2019)的启发利用大型未标记数据以及KGs的知识在循环中引入人类专家的无监督或半监督学习也很有希望。
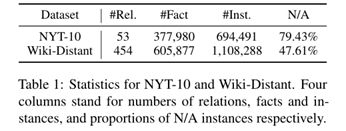
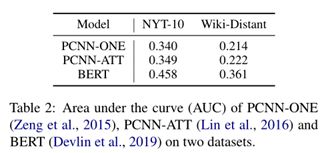
除了解决现有方法和未来方向外,我们还提出了一个新的DS数据集来推进这一领域,该数据将在论文发表后发布。 DS中使用最多的基准,即NYT-10(Riedel et al., 2010),其关系数量少、关系域有限、长尾关系性能极高。为了减轻这些弊端,我们利用Wikipedia的Wikidata(Vrandeci ˇ c and Kr ´ otzsch ¨ , 2014)以与Riedel et al. (2010) 相同的方式构建Wiki-Distant 。如表1所示,WikiDistant涵盖了更多的关系并拥有更多的实例,并且具有更合理的N / A比例。表2显示了这两个数据集上的最新模型的比较结果,表明Wiki-Distant更具挑战性,并且解决远程监管RE还有很长的路要走。
3.2 进行更有效的学习
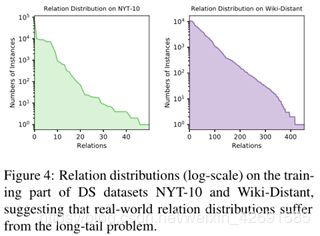
现实世界中的关系分布是长尾的:只有公共关系才能获得足够的训练实例,而大多数关系只有非常有限关系事实和相应的句子。从图4中我们可以看到两个DS数据集上的长尾关系分布,其中许多关系甚至少于10个训练实例。这种现象要求模型可以更有效地学习长尾关系。few-shot learning是一种非常适合这种需求的学习方法,它关注的是拥有的任务,只有很少训练实例。
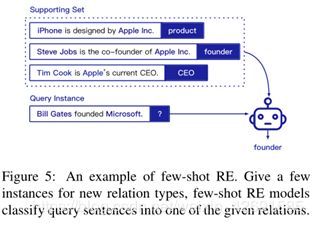
 为了推进这一领域,Han et al. (2018d) 首先建立了一个大规模的few-shot关系抽取数据集(FewRel)。此基准采用N-way K-shot设置,其中为模型提供了N个随机采样的新关系,以及每个关系的K个训练示例。在信息有限的情况下,需要使用RE模型将查询实例分类为给定的关系(图5)。
为了推进这一领域,Han et al. (2018d) 首先建立了一个大规模的few-shot关系抽取数据集(FewRel)。此基准采用N-way K-shot设置,其中为模型提供了N个随机采样的新关系,以及每个关系的K个训练示例。在信息有限的情况下,需要使用RE模型将查询实例分类为给定的关系(图5)。
 few-shot模型的总体思想是训练实例的良好表示或从现有的大规模数据中学习快速适应的方法,然后转移到新任务上。处理few-shot学习的方法主要有两种:(1)Metric learning通过对现有数据进行语义度量来学习,并通过将其与训练示例进行比较来对查询进行分类(Koch et al., 2015; Vinyals et al., 2016; Snell et al., 2017; Baldini Soares et al., 2019)。虽然大多数metric learning模型都对句子级表示进行距离测量,但Ye and Ling (2019); Gao et al. (2019) 利用token级注意进行更细粒度的比较。 (2)Meta-learning,也被称为“learning to learn”,旨在通过元训练数据的经验,掌握参数的初始化和优化方法(Ravi and Larochelle, 2017; Finn et al., 2017; Mishra et al., 2018)。
few-shot模型的总体思想是训练实例的良好表示或从现有的大规模数据中学习快速适应的方法,然后转移到新任务上。处理few-shot学习的方法主要有两种:(1)Metric learning通过对现有数据进行语义度量来学习,并通过将其与训练示例进行比较来对查询进行分类(Koch et al., 2015; Vinyals et al., 2016; Snell et al., 2017; Baldini Soares et al., 2019)。虽然大多数metric learning模型都对句子级表示进行距离测量,但Ye and Ling (2019); Gao et al. (2019) 利用token级注意进行更细粒度的比较。 (2)Meta-learning,也被称为“learning to learn”,旨在通过元训练数据的经验,掌握参数的初始化和优化方法(Ravi and Larochelle, 2017; Finn et al., 2017; Mishra et al., 2018)。
研究人员在这方面取得了很大的进展。然而,仍有许多对其应用很重要的挑战尚未讨论。Gao et al. (2019) 提出了两个值得进一步研究的问题:
(1)Few-shot domain adaptation研究few-shot模型如何跨领域转移。有人认为,在实际应用中,测试域通常缺少注释,并且可能与训练域有很大差异。因此,至关重要的一点是,要评估跨区域few-shot模型的可传递性。
(2)Few-shot none-of-the-above detection是关于检测不属于任何抽样的N个关系的查询实例。在N-way K-shot设置中,假定所有查询都表达给定关系之一。但是,实际情况是,大多数句子与我们感兴趣的关系无关。由于难以形成none-of-the-above(NOTA)的关系,传统的few-shot模型无法很好地处理此问题。因此,研究如何识别NOTA实例至关重要。
(3)除上述挑战外,还有一点很重要,那就是,现有的evaluation protocol可能会高估我们在few-shot RE方面取得的进展。与传统的RE任务不同,很少RE为每个评估集随机抽取N个关系;在这种情况下,关系的数量通常很少(5或10),并且很有可能对N个不同的关系进行采样,从而简化为非常简单的分类任务。
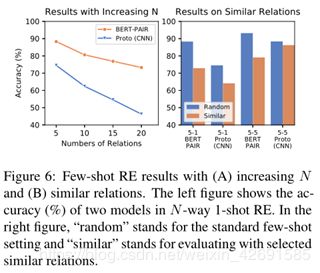 我们进行了两个简单的实验来显示问题(图6):(A)我们评估了N增加时的few-shot模型,而关联数越大,性能急剧下降。考虑到实际案例中包含的关系更多,这表明现有模型仍无法应用。 (B)代替随机采样N个关系,我们手动选择5个语义相似的关系,并评估它们的少量RE模型。观察到结果急剧下降也就不足为奇,这表明现有的few-shot模型可能过度适合关系之间的简单文本提示,而不是真正理解上下文的语义。有关实验的更多详细信息,请参见附录A。
我们进行了两个简单的实验来显示问题(图6):(A)我们评估了N增加时的few-shot模型,而关联数越大,性能急剧下降。考虑到实际案例中包含的关系更多,这表明现有模型仍无法应用。 (B)代替随机采样N个关系,我们手动选择5个语义相似的关系,并评估它们的少量RE模型。观察到结果急剧下降也就不足为奇,这表明现有的few-shot模型可能过度适合关系之间的简单文本提示,而不是真正理解上下文的语义。有关实验的更多详细信息,请参见附录A。
3.3 处理更复杂的上下文
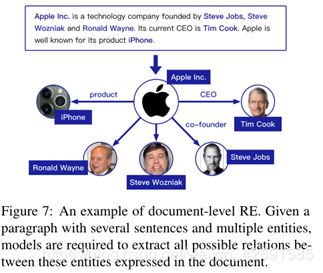 如图7所示,一个文档通常提到许多表现出复杂交叉句关系的实体。现有的大多数方法都集中在句子内的RE,因此不足以集体识别较长段落中表达的这些关系事实。实际上,大多数关系事实只能从诸如文档之类的复杂语境中抽取,而不是从单个句子中抽取(Yao et al., 2019),这一点不容忽视。
如图7所示,一个文档通常提到许多表现出复杂交叉句关系的实体。现有的大多数方法都集中在句子内的RE,因此不足以集体识别较长段落中表达的这些关系事实。实际上,大多数关系事实只能从诸如文档之类的复杂语境中抽取,而不是从单个句子中抽取(Yao et al., 2019),这一点不容忽视。
已经提出了一些建议来抽取多个句子之间的关系:
(1)句法方法(Wick et al., 2006; Gerber and Chai, 2010; Swampillai and Stevenson, 2011; Yoshikawa et al., 2011; Quirk and Poon,2017)依靠从各种句法结构中抽取的文本特征(例如共指消解、依存关系分析树和语篇关系)来连接文档中的句子。
(2)Zeng et al. (2017); Christopoulou et al. (2018) 构建句子间实体图,该图可以利用实体之间的multi-hop paths来推断正确的关系。
(3)Peng et al. (2017); Song et al. (2018); Zhu et al. (2019b) 使用图结构神经网络为交叉句子相关性建模以进行关系抽取,从而引入了记忆和推理能力。
为了推进这一领域,已经提出了一些文档级的RE数据集。Quirk and Poon (2017); Peng et al. (2017) 通过DS构建数据集。Li et al. (2016); Peng et al. (2017) 提出了特定领域的数据集。Yao et al. (2019) 构建了一个由众包工作注释的通用文档级RE数据集,适用于评估通用文档级RE系统。
尽管已进行了一些努力来从复杂的上下文(例如文档)中抽取关系,但是当前针对此挑战的RE模型仍然是粗糙而直接的。以下是一些值得进一步研究的方向:
(1)从复杂的上下文中抽取关系是一项艰巨的任务,需要阅读、记忆和推理才能发现多个句子中的相关事实。当前大多数RE模型在这些能力上仍然非常薄弱。
(2)除了文档之外,还需要探索更多形式的上下文,例如跨文档抽取关系事实,或基于异构数据理解关系信息。
(3)受Narasimhan et al. (2016) 的启发利用搜索引擎获取外部信息,自动搜索和分析RE的背景信息,可以帮助RE模型更广泛地识别关系事实,并适用于日常场景。
3.4 定向更多开放域
大多数RE系统在人类专家设计的预先指定的关系集中工作。但是,我们的世界经历着关系的开放式增长,不可能仅靠人类来处理所有这些新兴关系类型。因此,我们需要不依赖于预定义关系模式并且可以在开放方案中工作的RE系统。

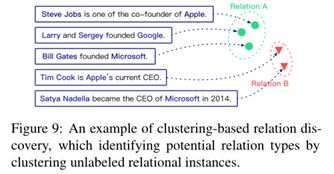
在处理开放关系方面已经进行了一些探索:(1)开放信息抽取(Open IE),如图8所示,从文本中抽取关系短语和论元(实体)(Banko et al., 2007; Fader et al., 2011; Mausam et al., 2012; Del Corro and Gemulla, 2013; Angeli et al., 2015; Stanovsky and Dagan, 2016; Mausam, 2016; Cui et al., 2018)。开放式IE不依赖特定的关系类型,因此可以处理各种关系事实。 (2)关系发现,如图9所示,旨在从无监督的数据中发现看不见的关系类型。Yao et al. (2011); Marcheggiani and Titov (2016) 提出使用生成模型并将这些关系视为潜在变量,而Shinyama and Sekine (2006); Elsahar et al. (2017); Wu et al. (2019) 将关系发现转换为聚类任务。
尽管对开放域中的关系抽取进行了广泛的研究,但仍有许多悬而未解决的研究问题尚待解决:
(1)在开放式IE中规范化关系短语和论元对于下游任务至关重要(Niklaus et al., 2018)。如果不规范,抽取的关系事实可能是多余的和不明确的。例如,Open IE可以抽取两个三元组(Barack Obama, was born in, Honolulu)和(Obama, place of birth, Honolulu),表示相同的事实。因此,标准化抽取结果将大大有利于Open IE的应用。该领域已经有一些前期工作(Galarraga et al. ´ , 2014; Vashishth et al., 2018),需要更多的努力。
(2)不适用(N / A)关系是在关系发现中几乎没有解决。在以前的工作中,通常假设该句子始终表示两个实体之间的关系(Marcheggiani and Titov, 2016)。但是,在现实世界中,句子中出现的大部分实体对没有关系,而忽略它们或使用简单的启发式方法摆脱它们可能会导致不良结果。因此,研究如何在关系发现中处理这些N / A实例将引起人们的兴趣。
4 其他挑战
在本节中,我们分析了RE模型面临的两个主要挑战,并通过实验加以解决,并显示了它们在RE系统的研发中的重要性。
4.1 从文本或名称中学习
在RE的过程中,实体名称及其上下文均提供了有用的分类信息。实体名称提供了键入信息(例如,we can easily tell JFK International Airport is an airport),并有助于缩小可能的关系范围;在训练过程中,也可以形成实体嵌入来帮助进行关系分类(例如在KG的链接预测任务中)。另一方面,通常可以从实体对周围的文本语义中抽取关系。在某些情况下,只能通过对上下文进行推理来隐式推断关系。
由于有两个信息源,研究它们各自对RE重新表现的贡献有多大是很有趣的。因此,我们为实验设计了三种不同的设置:(1)normal设置,其中名称和文本均作为输入;(2)masked-entity(ME)设置,其中实体名称被特殊token替换;(3)only-entity(OE)设置,其中仅提供两个实体的名称。
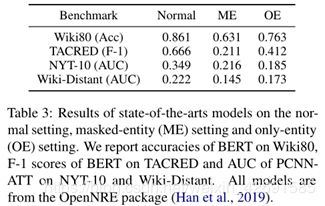 表3的结果表明,与normal设置相比,模型的ME和OE设置均遭受巨大的性能下降。此外,令人惊讶的是,在大多数情况下,仅使用实体名称会优于仅使用带有被屏蔽实体的文本。它表明:(1)实体名称和文本都为RE提供了关键信息,(2)对于现有的最新模型和基准,实体名称的贡献更大。
表3的结果表明,与normal设置相比,模型的ME和OE设置均遭受巨大的性能下降。此外,令人惊讶的是,在大多数情况下,仅使用实体名称会优于仅使用带有被屏蔽实体的文本。它表明:(1)实体名称和文本都为RE提供了关键信息,(2)对于现有的最新模型和基准,实体名称的贡献更大。
该观察结果与人类的直觉相反:我们主要根据文本描述对给定实体之间的关系进行分类,而模型则从其名称中学习更多。为了在理解语言如何表达关系事实方面取得真正的进步,应该进一步研究这个问题,并且需要付出更多的努力。
4.2 针对特殊兴趣的RE数据集
已经有很多数据集可以使RE研究受益:对于受监督的RE,有MUC(Grishman and Sundheim, 1996),ACE-2005(Ntroduction, 2005),SemEval-2010 Task 8(Hendrickx et al., 2009),KBP37(Zhang and Wang, 2015)和TACRED(Zhang et al., 2017);我们有NYT10(Riedel et al., 2010),FewRel(Han et al., 2018d)和DocRED(Yao et al., 2019)分别用于远程监管、few-shot和文档级RE。
但是,几乎没有针对特殊问题的数据集。例如,跨句子的RE(如,两个不同的句子中提到了两个实体)是一个重要的问题,但是没有特定的数据集可以帮助研究人员对其进行研究。尽管现有的文档级RE数据集包含这种情况的实例,但是很难分析此特定方面的确切性能提升。通常,研究人员(1)使用手工制作的通用数据集的子集,或者(2)进行案例研究以显示其模型在特定问题上的有效性,而这些问题缺乏令人信服的定量分析。因此,为了进一步研究这些在RE的发展中具有重要意义的问题,社区有必要构建针对特殊利益的、公认的、设计良好的和细粒度的数据集。
5 结论
在本文中,我们对关系抽取模型的开发进行了全面、详细的综述,概括了四个有前途的方向,这些方向导致了功能更强大的RE系统(利用更多的数据,执行更有效的学习,处理更复杂的上下文以及定向更多的开放域) ),并进一步调查现有RE模型面临的两个关键挑战。我们会彻底调查以前的RE文献,并通过统计和实验来支持我们的观点。通过本文,我们希望展示现有RE研究的进展和存在的问题,并鼓励在这一领域做出更多努力。