图算法知识点和模板(未完待续)
目录
- 图的储存(邻接表和邻接矩阵)
- 图的遍历(DFS和BFS)
- 最短路径(Dijkstra算法、Bellman-Ford算法与SPFA算法,Floyd算法)
- 最小生成树(Prim算法,Kruskal算法)
- 拓扑排序
- 关键路径
1. 图的储存
1.1 邻接矩阵
就是一个二维数组G[N][N],当G[i][j]=1时,说明顶点i和顶点j存在边;当当G[i][j]=0时,说明顶点i和顶点j不存在边。
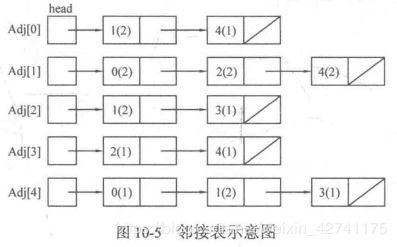
1.2 邻接表
把一个顶点的所有出边都放在一个列表中那么N个顶点就有N个列表,这N个列表称为图G的邻接表,称为Adj[N]。可用链表实现,但用变长数组实现vector比较简单且不容易出错。若同时存放编号和边权,可以用Node结构体
struct Node{
int v; //边的终点编号
int w;//边的边权
}
之后,边长数组就可以这样vector声明。
如果要添加边,可以这样
Node temp;
temp.v=2;
temp.w=4;
Adj[1].push_back(temp);
更快的方法是构建Node结构函数
struct Node{
int v,w;
Node(int _v,int_w) : v(_v),w(_w) {}
}
如果要添加边,可以这样
Adj[1].push_back(Node(2,4));

2.图的遍历
2.1 DFS
2.1.1 方法
沿着一条路径直到无法继续前进,才退回到路径上离当前顶点最近的还存在未访问分支顶点的岔路口,并前往访问那些未访问分支顶点,直到遍历完整个图。(对比树)
2.1.2 伪代码
DFS(u){ //访问顶点u
vis[u]=true;
for(u能到的结点v){
if(vis[v]==false){
DFS(v); //递归访问v
}
}
}
DFSTrave(G){ //遍历图G
for(G的所有顶点u){
if(vis[u]==false){
DFS(u); //访问u所在的连通块
}
}
}
2.1.3 实现
邻接矩阵版
const int maxv=100;
const int inf=10000000;
int n,G[maxv][maxv];
bool vis[maxv]={false};
void DFS(int u,int depth){
vis[u]=true;
//如果对u有什么操作,可以写在这里,如输出等
for(int v=0;v<n;v++){
if(vis[v]==false&&G[u][v]!=INF){
DFS(v,depth+1);
}
}
}
void DFSTrave(){
for(int u=0;u<n;u++){
if(vis[u]==false){
DFS(u,1);
}
}
}
邻接表
const int maxv=100;
const int inf=10000000;
int n;
bool vis[maxv]={false};
vector<int> Adj[maxv];
void DFS(int u,int depth){
vis[u]=true;
for(int i=0;i<Adj[u].size();i++){ //对从u出发可以到达的所有顶点v
int v=Adj[u][i];
if(vis[v]==false){
DFS(v,depth+1);
}
}
}
void DFSTrave(){
for(int u=0;u<n;u++){
if(vis[u]==false){
DFS(u,1);
}
}
}
2.2 BFS
2.2.1 方法
BFS一般使用队列,通过反复取出队首结点,将该顶点可到达的未曾加入过队列的顶点全部入队。(对比树)
2.2.2 伪代码
BFS(u){
queue q;
将q入队;
inq[u]=true; //设置u是否进入过队列
while(q非空){
取出q的队首元素u进行访问;
for(u可到的所有结点v){
if(inq[v]=false){
将v入队;
inq[v]=true;
}
}
}
}
BFSTrave(G){
for(G的所有顶点u){
if(inq[u]==false){
BFS(u);
}
}
}
2.2.3 实现
邻接矩阵
int n,G[maxv][maxv];
bool inq[maxv]={false};
void BFS(int u){
queue<int> q;
q.push(u);
inq[u]=true;
while(!q.empty()){
int u=q.front();
q.pop();
for(int v=0;v<n;v++){
if(inq[v]==false&&G[u][v]!=inf){
q.push(v);
inq[v]=true;
}
}
}
}
BFSTrave(G){
for(int u=0;u<n;u++){
if(inq[u]==false){
BFS(q);//遍历u所在的连通块
}
}
}
邻接表
小应用:给定顶点,输出该连通块内所有顶点的层号(与这些差不多的题目只需稍微修改一下模板就可以了)
struct Node{ //也可以用Node函数的方式
int v; //顶点编号
int layer; //层号
};
vector<Node> Adj[N];
void BFS(int s){ //起始顶点编号
queue<Node> q;
Node start; //其实顶点编号
start.v=s;
start.layer=0;
q.push(start);
inq[start.v]=true;
while(!q.empty()){
Node top=q.front();
q.pop();
int u=top.v; //队首节点的编号
for(int i=0;i<Adj[u].size();i++){
Node next=Adj[u][i];
next.layer=top.layer+1;
if(inq[next.v]==false){
q.push(next);
inq[next.v]==true;
}
}
}
}
3.最短路径
3.1 Dijkstra 算法(单源最短路径)
3.1.1 方法
设置集合S存放已被访问的结点,然后执行n次以下步骤
1.每次从集合V-S(未被访问)中选择与起点s的最短距离最小的一个顶点(记为u),标记成访问(加入集合S)。
2. 之后,以顶点u为中介点,优化起点s与所有从u能到达的顶点v之间的最短距离。

3.1.2 伪代码(只是求出最短路径)
//G为图,一般设置成全局变量,数组d为源点到达各点的最短路径长度,s为起点
Dijkstra(G,d[],s){
初始化;
for(循环n次){
u=使d[u]最小的还未访问的顶点的编号;
标记u被访问;
for(u能到的顶点v){
if(v没有被访问&&以u为中介点使s到v的最短路径d[v]更优){
优化d[v]; //又叫松弛操作
}
}
}
}
3.1.3 实现(求出最短路径+解最短路径)
3.1.3.1 最普通的模板
const int maxv=1000;
const int inf=100000000000;
int n,G[maxv][maxv];
int d[maxv]; //记录到达各点的最短路径长度
int pre[maxv]; //记录前驱顶点
bool vis[maxv]={false};
void Dijkstra(int s){
//初始化
fill(d,d+maxv,inf);
d[s]=0;
for(int i=0;i<n;i++){
//u=使d[u]最小的还未访问的顶点的编号;
int u=-1,MIN=inf;
for(int j=0;j<n;j++){
if(vis[j]==false&&d[j]<MIN){
u=j;
MIN=d[j];
}
}
if(u==-1) return; //找不到剩下inf的d[u],说明剩下的顶点和起点s不连通
vis[u]=true; //标记u被访问
//如果是邻接表写法,下面开始不同
for(int v=0;v<n;v++){
if(vis[v]==false&&G[u][v]==false&&d[u]+d[u][v]<d[v]){
d[v]=d[u]+d[u][v];
pre[v]=u; //记录v的前驱顶点是u
}
}
}
}
//注意的是要从终点往起点递归
void DFS(int s,int v){ //s为起点编号,v为当前访问的顶点编号
if(v==s){
printf("%d\n",s);
return;
}
DFS(s,pre[v]);
printf("%d\n",v);
}
3.1.3.2 多个标尺
多个标尺的意思是,有多条路径的最短路径相等,需要比较其他的条件(如点权、花费、直接问有多少条最短路径)进行判断
直接看一道例题:
给出N个城市,M条无向边。每个城市中都有一定数目的救援小组,所有边的边权已知,现在给出起点和终点,求从起点到终点的最短路径条数及最短路径上的救援小组数目之和。如果有多条最短路径,则输出数目最大的。
分析:
1.在普通Dijkstra基础上所需要增加的数据结构:数组num[]->记录最短路径条数,w[]->记录最大点权之和(最大救援小组数目之和),weight[]->边权,起点和终点 st,ed
2.想想在原模板的基础上哪里要在增加?
完整代码(方法一):
#include 方法二:Dijkstra+DFS(模板)
之前的Dijkstra算法利用pre保持最优路径,而这显然需要在执行Dijkstra算法的过程中使用严谨的思路确定何时更新每个结点v的前驱pre[v]。不妨换一种方法:先在Dijkstra算法中记录下所有最短路径(只考虑距离),然后从这些最短路径中选出一条第二标尺最优路径。
1.使用Dijkstra算法记录所有最短路径
因为要记录所有的最短路径,每个结点就会存在多个前驱结点,所以要使用变长数组vector来存放结点v的所有能产生最短路径的前驱结点。(对需要查询某个结点u是否在顶点v的前驱中的题目,也可以把pre数组设置成set数组,此时使用pre[v].count(u)来查询比较方便)。
注意:如果d[u]+G[u][v]
vector<int> pre[maxv];
void Dijkstra(int s){
fill(d,d+maxv,inf);
d[s]=0;
for(int i=0;i<n;i++){
int u=-1,MIN=inf;
for(int j=0;j<n;j++){
if(vis[j]==false&&d[j]<min){
u=j;
min=d[j];
}
}
if(u==-1) return;
vis[u]=true;
for(int v=0;v<n;v++){
if(vis[v]==false&&G[u][v]!=inf){
if(d[u]+d[u][v]<d[v]){
d[v]=d[u]+d[u][v];
pre[v].clear();
pre[v].push_back(u);
}
else if(d[u]+d[u][v]==d[v]){
pre[v].push_back(u);
}
}
}
}
}
2.遍历所有路径,找出一条使第二标尺最优的路径(DFS)
分析:遍历的过程会形成一颗递归树。每得到一条完整的路径,就可以计算其第二标尺的值,令其与当前第二标尺的最优值进行比较,如果比当前最优值更优,就覆盖当前最优值。所以,必须要有的数据结构如下:
- 作为全局变量的第二标尺optValue
- 记录当前的最优路径path
- 临时记录DFS遍历到叶子结点时的路径tempPath
附上代码:
int optvalue; //第二标尺最优值
vector<int> pre[maxv];
vector<int> path,tempPath; //最优路径,临时路径
void DFS(int v){ //v为当前访问的结点
//递归边界
if(v==st){ //因为是倒着访问,所以叶子结点就是起点st
tempPath.push_back(v);
int value;
计算路径tempPath上value的值;
if(value优于optvalue){
optvalue=value;
path=tempPath;
}
tempPath.pop_back(); //将刚加入的结点删除
return;
}
//递归式
tempPath.push_back(v);
for(int i=0;i<pre[v].size();i++){
DFS(pre[v][i]); //结点v的前驱结点,递归
}
tempPath.pop_back();
}
对于上述的“计算路径tempPath上value的值”,value有可能是边权或者是点权,计算时要注意存放在tempPath中的结点路径是逆序的,因此访问结点也要倒着进行。
附上代码:
//边权之和
int value=0;
for(int i=tempPath.size();i>0;i--){ //因为访问的是边,所以i>0
//当前结点为id,下一个结点为idnext
int id=tempPath[i],idnext=tempPath[i-1];
value+=V[id][idnext]; //value增加id->idnext的边权
}
//点权之和
int value=0;
for(int i=tempPath.size();i>=0;i--){ //因为访问的是结点,所以i>=0
int id=tempPath[i];
value+=W[id]; //value增加结点id的点权
}
3.1.4 总结
对于简单的第二标尺题目(有且只有第二标尺),使用第一种Dijkstra算法会更快。另外,应注意顶点坐标的范围,根据题意是0-n-1还是1-n。
3.2 Bellman-Ford算法与SPFA算法(含有负权边的单源最短路径)
3.2.1 Bellman-Ford算法
3.2.1.1 方法
与Dijkstra算法相同,Bellman-Ford算法需要设置一个数组d,用来存放从源点到达各个顶点的最短距离。同时Bellman-Ford算法返回一个bool值,如果其中存在从源点可达的负环,那么函数将返回false,否则返回true,此时数组d中存放的值就是从源点到达各顶点的最短距离。

3.2.1.2 伪代码
for(int i=0;i<n-1;i++){ //注意,执行n-1次操作
for(each edge u->v){ //每轮操作遍历所有边
if(d[u]+length[u->v]<d[v]){
d[v]=d[u]+length[u->v];
}
}
}
for(each edge u->v){ //对每条边进行判断
if(d[u]+length[u->v]<d[v]){ //如果还能被松弛,说明存在源点可达的负环
return false;
}
}
return true;
3.2.1.3 实现
因为Bellman-Ford算法需要遍历所有的边,使用邻接表会比较方便
struct Node{
int v,dis; //v为邻接边的目标顶点,dis为邻接边的边权
};
vector<Node> Adj[maxv];
int n;
int d[maxv];
bool Bellman_ford(int s){
fill(d,d+maxv,inf);
d[s]=0;
for(int i=0;i<n-1;i++){ //进行n-1轮操作
for(int u=0;u<n;u++){ //每轮操作遍历所有边
for(int j=0;j<Adj[u].size();j++){
int v=Adj[u][j].v;
int dis=Adj[u][j].dis;
if(d[u]+dis<d[v]){
d[v]=d[u]+dis;
}
}
}
}
for(u=0;u<n;u++){ //对每条边进行判断
for(int j=0;j<Adj[u].size();j++){
int v=Adj[u][j].v;
int dis=Adj[u][j].dis;
if(d[u]+dis<d[v]){
return false;
}
}
}
return true;
}
3.2.1.4 例子
Bellman-Ford 求解最短路径的方法和Dijkstra相同(包括多重标尺),值得一提的是总计最短路径的做法。由于Bellman-Ford算法期间会多次访问曾经访问过得结点,如果单纯按照Dijkstra算法中介绍的num数组写法,将会反复累计已经计算过的结点。为了解决这个问题,需要设置记录前驱的数组set,当遇到一条和已有最短路径长度相同的路径时,必须重新计算最短路径的条数。
接下来用Bellman-Ford算法重新做这道题:给出N个城市,M条无向边。每个城市中都有一定数目的救援小组,所有边的边权已知,现在给出起点和终点,求从起点到终点的最短路径条数及最短路径上的救援小组数目之和。如果有多条最短路径,则输出数目最大的。
#include3.2.2 SPFA算法(Bellman-Ford算法的优化)
3.2.2.1 解释及方法
Bellman-Ford算法复杂度为O(VE),显然太高。仔细分析,Bellman算法每轮都要操作所有边,显然会有很多无意义的操作。注意到:**只有当某个顶点u的d[u]值改变时,从它出发的边的邻接点v的d[v]值才可能被改变。**于是做以下优化:建立一个队列,每次将队首结点u取出,然后判断d[u]+length[u->v] SPFA的复杂的为O(kE),但如果有可达负环,就会退化为O(VE)。另外SPFA算法还能使用SLF优化和LLL优化以及其他方式优化,这里不再叙述。 如果存在顶点k,使得k作为中介点时让i和j之间的距离缩短,则采用k作为中介点,即 定义:给定无向图G(V,E)中求一棵树,使得这棵树拥有G中的所有顶点,且边也是G的边,并且满足这棵树的边权最小。 其思路与Dijkstra算法思路极为相似,就是d[ ]的含义不同(Dijkstra算法中d[]的含义是起点s到顶点vi的最短距离,Prim算法中d[]含义为顶点Vi与集合S的最短距离)。其基本思想是:对图G(V,E)设置集合S,存放已被访问的顶点,然后每次从集合V-S中选择与集合S的最短距离最小的一个顶点(记为u),访问并加入集合S。之后令u为中介点,优化所有u能到达的顶点v与集合S之间的最短距离。这样的操作执行n次,直到集合S已包含所有顶点。 和Dijkstra一样,可以用邻接矩阵或邻接表写。这里只写邻接矩阵,邻接表可以参考Dijkstra的。 使用边贪心的策略。基本思想为:在执行之前先隐去所有的边,这样的话每个顶点都可以自成一个连通块,然后执行下面步骤: 注意:判断“当前测试边的两个顶点不是在同一个连通块”和“将该测试边加入最小生成树”要用并查集实现。(并查集详细做法在另一篇文章分析) 拓扑排序是对**有向无环图(DAG)**的顶点的一种排序,它使得如果存在一条从从vi和vj的路径,那么在排序中vj出现在vi的后面。 用邻接表实现 应用: 有向图判环 AOV网:用顶点表示活动,用弧表示活动间的优先关系的有向图。3.2.2.2 伪代码
queue<int> Q;
源点s入队;
while(队列非空){
取出队首元素;
for(u的所有邻接边u->v){
if(d[u]+length[u->v]<d[v]){
d[v]=d[u]+length[u->v];
if(v不在当前队列){
v入队;
if(v入队次数>n-1){
说明有负环,return;
}
}
}
}
}
3.2.2.3 实现
vector<Node> Adj[maxv];
int n,d[maxv],num[maxv]; //num数组记录顶点入队次数(用来判断有没负环)
bool inq[maxv];
bool SPFA(int s){
//初始化
memset(inq,false,sizeof(inq));
memset(num,0,sizeof(num));
fill(d,d+maxv,inf);
//源点入队部分
queue<int> q;
q.push(s);
inq[s]=true;
num[s]++;
d[s]=0;
//主体部分
while(!q.empty()){
int u=q.front();
q.pop();
inq[u]=false;
for(j=0;j<Adj[u].size();j++){
int v=Adj[u][j].v;
int dis=Adj[u][j].dis;
//松弛操作
if(d[u]+dis<d[v]){
d[v]=d[u]+dis;
if(!inq[v]){ //v不在队列中,就加入
q.push(v);
inq[v]=true;
num[v]++;
if(num[v]>=n) return false; //有可达负环
}
}
}
}
return true;
}
3.2.2.4 注意
3.3 Floyd算法(全源最短路)
3.3.1 方法
d[i][k]+d[k][j]3.3.2 算法描述
枚举结点k∈[1,n];
以顶点k为中介点,枚举所有的顶点对i和j(i∈[1,n],j∈[1,n])
如果d[i][k]+d[k][j]3.3.3 实现
#include4.最小生成树
4.1 最小生成树的定义和性质
性质:
4.2 Prim算法
4.2.1 方法
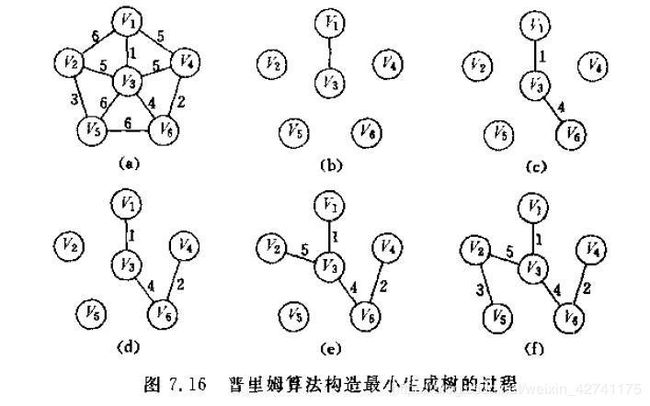
4.2.2 算法描述
Prim(G,d[]){
初始化:
循环n次{
u=使d[u]最小且还被被访问的结点;
记d[u]被访问;
for(u能到的结点){
if(v还没被访问&&以u为中介点使得v与集合S的最短距离d[v]更优){
将G[u][v]赋值给V与集合S最短距离d[v];
}
}
}
}
4.2.3 实现
//邻接矩阵,其中标记*地方与dijkstra不同
#include4.2.4 注意
4.3 Kruskal算法
4.3.1 方法

4.3.2 算法描述
int Kruskal(){
初始化ans(最小边权之和),当前边数num_edge;
将所有边从小到大排序;
for(从小到大枚举所有的边){
if(当前测试边的两个顶点不是在同一个连通块){
将该测试边加入最小生成树;
ans+=该测试边
num_edge+=1;
当num_edge==顶点数-1结束循环;
}
}
return ans;
}
4.3.3 实现
#include5.拓扑排序
5.1 定义
5.2 步骤
5.3 实现
vector<int> G[maxv];
int n,m,indegree[maxv];
bool topologicalSort(){
int num=0; //记录加入序列的顶点数
queue<int> q;
for(int i=0;i<n;i++){
if(indegree[i]==0){
q.push(i);
}
}
while(!q.empty()){
int u=q.front();
printf("%d",u); //可以输出u作为拓扑序列的顶点
q.pop();
for(int i=0;i<G[u].size();i++){
int v=G[u][i]; //u的后继结点
indegree[v]--;
if(indegree[v]==0){
q.push(v);
}
}
G[u].clear(); //清空顶点u的所有出边(如果没必要可以不写)
num++;
}
if(num==n) return true;
else return false;
}
5.4 应用和注意事项
注意:若要求有多个入度为0的结点,选择编号最小的结点,把queue改成priority_queue,并保持队首元素是最小元素即可6.关键路径
6.1 AOV网和AOE网
AOE(Activity On Edge)网:带权的边集表示活动,用顶点表示事件的有向图。
AOE网解决的问题:1. 完成整项工程至少需要多少时间? 2. 哪些活动是影响工程进度的关键?**
AOE网中的最长路径叫做关键路径,而关键路径上的活动叫做关键活动。**