PaddlePaddle 7日训练营CV疫情特辑总结
PaddlePaddle 7日训练营CV疫情特辑总结
- 什么是paddle paddle?
- 7日训练营CV疫情特辑
- Day 1:新冠疫情可视化
- 一、数据准备
- 部分代码展示
- 二、疫情地图
- 三、成果展示
- 非常漂亮有木有!!!!
- Day 2 ~ Day 6:
- 成果展示
- 手势识别
- 车牌识别
- 口照分类
- PaddleSlim模型压缩
- 我们这次项目涉及到的就是对模型进行无损量化
- 结果展示
- Finally:Day 5 比赛——人流密度检测
- 感想与心得
什么是paddle paddle?
飞桨 (PaddlePaddle) 以百度多年的深度学习技术研究和业务应用为基础,集深度学习核心框架、基础模型库、端到端开发套件、工具组件和服务平台于一体,2016 年正式开源,是全面开源开放、技术领先、功能完备的产业级深度学习平台。
7日训练营CV疫情特辑
百度官方经常举办这样7日训练营的活动,来给大家普及非常实用且有趣的有关于机器学习的知识。无论你是新手小白还是技术大佬,都一定能在这里学到知识,还能交到好的朋友,互相交流学习经验,共同进步。最终还有paddleHub比赛,如果你是深度学习达人,这一定是你大展身手的好地方!当然,如果你是小白,这也是你踏入深度学习大门的最佳途径!
Day 1:新冠疫情可视化
第一天,我们学习了较为简单但有趣的新冠疫情可视化方法,这次课的内容,让我们学会了爬取数据,分析数据,以及可视化。还让我入门了一个非常有用的包:百度开源的pyecharts。这个包对数据进行可视化,还可以调许多参数得到自己想要的图形,包括3D,渲染出的图像也非常的好看,非常值得一学!
涉及知识点:爬虫、python http方法、pyecharts库
一、数据准备

部分代码展示
def crawl_dxy_data():
"""
爬取丁香园实时统计数据,保存到data目录下,以当前日期作为文件名,存JSON文件
"""
response = requests.get('https://ncov.dxy.cn/ncovh5/view/pneumonia') #request.get()用于请求目标网站
try:
url_text = response.content.decode() #更推荐使用response.content.deocde()的方式获取响应的html页面
url_content = re.search(r'window.getAreaStat = (.*?)}]}catch',
url_text, re.S)
texts = url_content.group() #获取匹配正则表达式的整体结果
content = texts.replace('window.getAreaStat = ', '').replace('}catch', '') #去除多余的字符
json_data = json.loads(content)
with open('data/' + today + '.json', 'w', encoding='UTF-8') as f:
json.dump(json_data, f, ensure_ascii=False)
except:
print('' % response.status_code)
二、疫情地图
这里我们用到了:pyecharts 他是一个由百度开源的数据可视化工具,凭借着良好的交互性,精巧的图表设计,得到了众多开发者的认可。而 Python 是一门富有表达力的语言,很适合用于数据处理。当数据分析遇上数据可视化时,pyecharts 诞生了。pyecharts api可以参考:https://pyecharts.org/#/zh-cn/chart_api
下载方式(清华源非常快哦 : ) )
! pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyecharts
三、成果展示
全国疫情地图

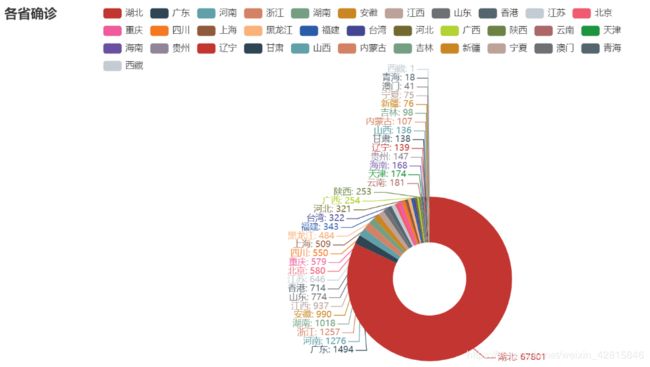
各省确诊情况
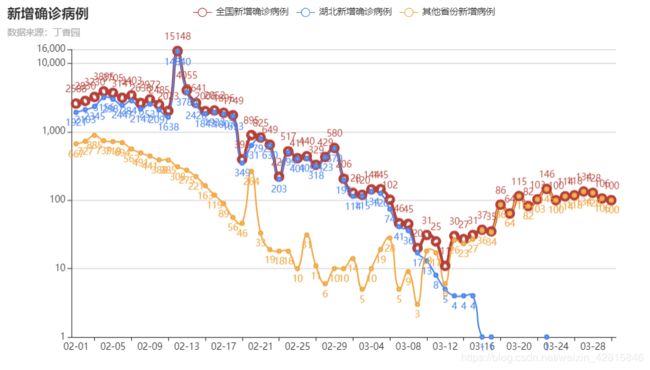
疫情增长趋势
非常漂亮有木有!!!!
Day 2 ~ Day 6:
接下来的任务就开始进入正题了,每天都在写代码,调试代码,为了让自己的代码跑出更好的结果,为了获取更多的知识,更为了不辜负 班主任小姐姐 (❤ ω ❤)一片苦心与付出!!!
以下展示我们这么多天以来的艰辛!当然同时也伴随着学习的快乐!
| 天数 | 项目 | 任务 |
|---|---|---|
| Day 2 | 手势识别 | 识别手上比的数字 |
| Day 3 | 车牌识别 | 识别车牌号号码 |
| Day 4 | 口罩分类 | 对口罩进行识别 |
| Day 6 | PaddleSlim模型压缩 | 实现无损定点量化 |
想必大家也注意到了,这里没有给出Day 5。
别着急~ 因为这是非常有趣的一个项目,所以放到最后~
成果展示
这里就不放出代码啦,直接给出我的训练结果。若是大家看了我的成果后心动了,可以亲自去百度训练营试一试哦~ 百度提供了很好的框架,还有免费V100可用呢!!!
手势识别
还记得当时做这个实验的时候,历经千辛万苦,终于才识别成功。这不是一个简单的实验,对我的考验很大,是一次历练的过程哈哈哈

车牌识别
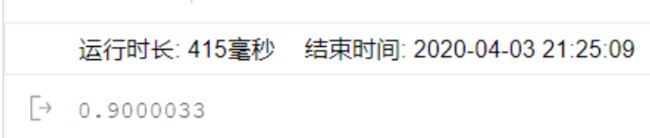
好吧我认输… 我承认这次的实验没有得到满意的结果…

但是!!!我的正确率是有90以上的!!以图为证!证明我是真的有努力的T﹏T
口照分类
看吧,这个结果还不错是吧(●’◡’●)

PaddleSlim模型压缩
资料
PaddleSlim代码地址: https://github.com/PaddlePaddle/PaddleSlim
文档地址:https://paddlepaddle.github.io/PaddleSlim/
介绍
PaddleSlim是一个模型压缩工具库,包含模型剪裁、定点量化、知识蒸馏、超参搜索和模型结构搜索等一系列模型压缩策略。
我们这次项目涉及到的就是对模型进行无损量化
量化步骤
- 导入依赖
- 构建模型
- 训练模型
- 量化
- 训练和测试量化后的模型
- 保存量化后的模型
1、导入依赖
PaddleSlim依赖Paddle1.7版本,请确认已正确安装Paddle,然后按以下方式导入Paddle和PaddleSlim:
import paddle
import paddle.fluid as fluid
import paddleslim as slim
import numpy as np
2、构建模型
该章节构造一个用于对MNIST数据进行分类的分类模型,选用MobileNetV1,并将输入大小设置为[1, 28, 28],输出类别数为10。 为了方便展示示例,我们在paddleslim.models下预定义了用于构建分类模型的方法,执行以下代码构建分类模型:
use_gpu = fluid.is_compiled_with_cuda()
exe, train_program, val_program, inputs, outputs = slim.models.image_classification("MobileNet", [1, 28, 28], 10, use_gpu=use_gpu)
place = fluid.CUDAPlace(0) if fluid.is_compiled_with_cuda() else fluid.CPUPlace()
3、定义输入数据
为了快速执行该示例,我们选取简单的MNIST数据,Paddle框架的paddle.dataset.mnist包定义了MNIST数据的下载和读取。 代码如下:
import paddle.dataset.mnist as reader
> train_reader = paddle.batch(
reader.train(), batch_size=128, drop_last=True)
> test_reader = paddle.batch(
reader.test(), batch_size=128, drop_last=True)
data_feeder = fluid.DataFeeder(inputs, place)
4、训练和测试
为了快速执行该示例,我们选取简单的MNIST数据,Paddle框架的paddle.dataset.mnist包定义了MNIST数据的下载和读取。 代码如下:
def train(prog):
iter = 0
for data in train_reader():
acc1, acc5, loss = exe.run(prog, feed=data_feeder.feed(data), fetch_list=outputs)
if iter % 25 == 0:
print('train iter={}, top1={}, top5={}, loss={}'.format(iter, acc1.mean(), acc5.mean(), loss.mean()))
iter += 1
def test(prog):
iter = 0
res = [[], []]
for data in test_reader():
acc1, acc5, loss = exe.run(prog, feed=data_feeder.feed(data), fetch_list=outputs)
if iter % 100 == 0:
print('test iter={}, top1={}, top5={}, loss={}'.format(iter, acc1.mean(), acc5.mean(), loss.mean()))
res[0].append(acc1.mean())
res[1].append(acc5.mean())
iter += 1
print('final test result top1={}, top5={}'.format(np.array(res[0]).mean(), np.array(res[1]).mean()))
train(train_program)
test(val_program)
5、量化模型
按照配置在train_program和val_program中加入量化和反量化op.
place = exe.place
quant_program = slim.quant.quant_aware(train_program, exe.place, for_test=False)
val_quant_program = slim.quant.quant_aware(val_program, exe.place, for_test=True)
6、训练和测试量化后的模型
按照配置在train_program和val_program中加入量化和反量化op.
train(quant_program)
test(val_quant_program)
结果展示
量化前:
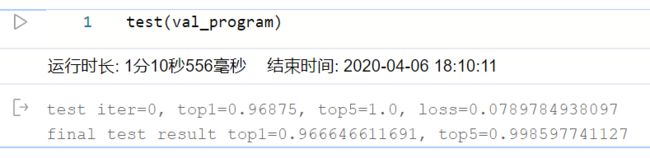
量化后:
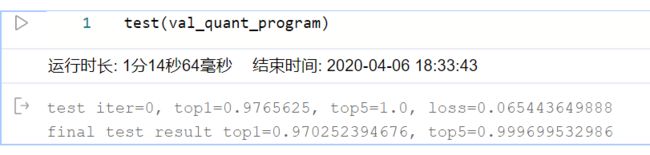
至此,我成功地实现了模型的无损量化!(表扬一下自己哈哈)
Finally:Day 5 比赛——人流密度检测
这个比赛非常有趣,最终大概有300来人提交,不论你的模型是什么类型:BP神经网络,反馈型,CNN,都能拿上来跑一跑,生成自己的排名。而且排名是个很大的激励,让你总想优化自己的模型,得到更高的rank。
感想与心得
好了,终于到最后了,终于可以暂时抛开学术性的东西,来谈一谈个人的想法和这几天的经历了哈哈哈。
刚开始看到这个比赛的时候还不到4月份。因为我是大三的学生,这学期呢又正好上人工智能,我们教授也要求我们使用百度AI Stuido平台,使用百度的框架。因此呢就想来学一学,入个门,就当提前预习一下,然后就报名了。
当我被拉进群的时候,是在第4群,人非常多,大家的热情也很高。有问题随时都能发到群里问,会有助教,班主任,甚至是同期的训练营的厉害的学员都会来帮你解答,都非常热心。
这7天里其实我也挺忙的,课程非常繁重,每天还要抽时间学习训练营的东西,写代码,调式,优化。确实是差点没坚持过来。但,幸运的是,我坚持过来了,每天抽出时间先把paddle paddle的代码和作业做了,代码就让它在那里跑,然后继续回去写学校的作业。当然,没有忘记要顶个闹钟⏰,因为要看看自己跑的代码怎么样了哈哈
印象最深刻的一点是什么呢…当然是抢GPU啦!
用过的小伙伴都知道,V100很香!但也很难枪!因为大家的热情都实在太高了,要是你稍微没那么积极的话,就别想用GPU了哈哈哈。做PaddleHub比赛——人流密度期间,为了用上GPU来跑代码(要是没GPU那真是…)半夜起来跑代码。。。跑上之后睡一觉,几个小时之后又起来看哈哈~ 真是一件令人哭笑不得的事情。不过没关系,学习嘛,值得~