KNN机器学习实战(sklearn)(包含训练数据)
本文直接给出sklearn里面KNN 算法的用法。具体实现过程如下:
# -*- coding: utf-8 -*-
import numpy as np
import pandas as pd
from sklearn import datasets
import operator
from sklearn import neighbors
import sklearn.model_selection as ms
import matplotlib.pyplot as plt
digits = datasets.load_digits()
totalNum = len(digits.data)
# 选出80%样本作为训练样本,其余20%测试
trainNum = int(0.8 * totalNum)
trainX,testX, trainY,testY = ms.train_test_split(digits.data, digits.target, random_state = 1, train_size = 0.8)
np.shape(digits.data)
np.shape(digits.target)
#用图像来初步认识下特征的长相
X_train = trainX.reshape(len(trainX), 8,8)
X_train = X_train/X_train.max() # 数据归一化
print("After reshaping, the shape of the X_train is:", X_train.shape)
np.shape(X_train)
a = X_train[1]
a.shape
plt.imshow(a, cmap = 'Greys_r') #画图
#训练模型,并计算不同K的情况下ER的变化情况
ER = []
for n_neighbors in range(1,16):
clf = neighbors.KNeighborsClassifier(n_neighbors, weights='uniform') #测试不同的K 对最终结果的影响
clf.fit(trainX, trainY) #训练器
Z = clf.predict(testX) #预测
x = 1- np.mean(Z == testY) #计算错误率
ER.append(x) #将错误率储存在ER 中
pd.DataFrame(ER).plot(title = 'the plot of error rate') #画图显示不同K对模型正确的影响
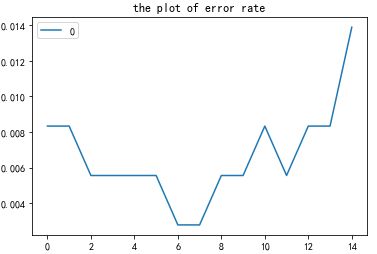
通过以上的图形可知,n_neighbors = 7,8 时较为合适, 此时的error rate 为0.002778
# -*- coding: utf-8 -*-
import numpy as np
from sklearn import neighbors, datasets
from sklearn.model_selection import train_test_split
from sklearn.utils.testing import assert_equal
rng = np.random.RandomState(0)
# load and shuffle digits
digits = datasets.load_digits()
perm = rng.permutation(digits.target.size)
digits.data = digits.data[perm]
digits.target = digits.target[perm]
def test_neighbors_digits():
# Sanity check on the digits dataset
# the 'brute' algorithm has been observed to fail if the input
# dtype is uint8 due to overflow in distance calculations.
X = digits.data.astype('uint8')
Y = digits.target
(n_samples, n_features) = X.shape
train_test_boundary = int(n_samples * 0.8)
train = np.arange(0, train_test_boundary)
test = np.arange(train_test_boundary, n_samples)
(X_train, Y_train, X_test, Y_test) = X[train], Y[train], X[test], Y[test]
clf = neighbors.KNeighborsClassifier(n_neighbors=1, algorithm='brute')
clf_unit8 = clf.fit(X_train, Y_train)
clf_float = clf.fit(X_train.astype(float), Y_train)
score_uint8 = clf_unit8.score(X_test, Y_test)
score_float = clf_float.score(X_test.astype(float), Y_test)
assert_equal(score_uint8, score_float)
pred_y = clf_unit8.predict(X_test)
print("the acurracy rate is :", np.mean(pred_y == Y_test))
test_neighbors_digits()
以下是机器学习实战书中的源代码。
# -*- coding: utf-8 -*-
"""
Created on Mon Sep 17 15:03:26 2018
"""
from numpy import *
import operator
path = r'C:\Users\Administrator\Desktop\python\MLiA_SourceCode\machinelearninginaction\KNN'
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
diffMat = tile(inX, (dataSetSize,1)) - dataSet
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances**0.5
sortedDistIndicies = distances.argsort()
classCount={}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
return int(sortedClassCount[0][0])
def createDataSet():
group = array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])
labels = ['A','A','B','B']
return group, labels
def file2matrix(filename):
fr = open(filename)
numberOfLines = len(fr.readlines()) #get the number of lines in the file
returnMat = zeros((numberOfLines,3)) #prepare matrix to return
classLabelVector = [] #prepare labels return
fr = open(filename)
index = 0
for line in fr.readlines():
line = line.strip()
listFromLine = line.split('\t')
returnMat[index,:] = list(map(float,listFromLine[0:3]))
classLabelVector.append(int(listFromLine[-1]))
index += 1
return returnMat,classLabelVector
#normalize
def autoNorm(dataSet):
minVals = dataSet.min(0)
maxVals = dataSet.max(0)
ranges = maxVals - minVals
normDataSet = zeros(shape(dataSet))
m = dataSet.shape[0]
normDataSet = dataSet - tile(minVals, (m,1))
normDataSet = normDataSet/tile(ranges, (m,1)) #element wise divide
return normDataSet, ranges, minVals
#autoNorm(datingDataMat)
def datingClassTest():
hoRatio = 0.50 #hold out 10%
datingDataMat,datingLabels = file2matrix(path+'/datingTestSet2.txt') #load data setfrom file
normMat, ranges, minVals = autoNorm(datingDataMat)
m = normMat.shape[0]
numTestVecs = int(m*hoRatio)
errorCount = 0.0
for i in range(numTestVecs):
classifierResult = classify0(normMat[i,:],normMat[numTestVecs:m,:],datingLabels[numTestVecs:m],3)
print ("the classifier came back with: %d, the real answer is: %d" % (classifierResult, datingLabels[i]))
if (classifierResult != datingLabels[i]): errorCount += 1.0
print ("the total error rate is: %f" % (errorCount/float(numTestVecs)))
print (errorCount)
#datingClassTest()
###########################################################deal with digit
from os import listdir
pat = r'C:\Users\Administrator\Desktop\python\MLiA_SourceCode\machinelearninginaction\KNN\digits'
#将数据转化成1*1024的举证
def img2vector(filename):
returnVect = zeros((1,1024))
fr = open(filename)
for i in range(32):
lineStr = fr.readline()
for j in range(32):
returnVect[0,32*i+j] = int(lineStr[j])
return returnVect
def handwritingClassTest():
hwLabels = []
trainingFileList = listdir(pat + '/trainingDigits') #load the training set
m = len(trainingFileList)
trainingMat = zeros((m,1024))
for i in range(m):
fileNameStr = trainingFileList[i]
fileStr = fileNameStr.split('.')[0] #take off .txt
classNumStr = int(fileStr.split('_')[0])
hwLabels.append(classNumStr)
trainingMat[i,:] = img2vector(pat +'/trainingDigits/%s' % fileNameStr)
testFileList = listdir(pat +'/testDigits') #iterate through the test set
errorCount = 0.0
mTest = len(testFileList)
for i in range(mTest):
fileNameStr = testFileList[i]
fileStr = fileNameStr.split('.')[0] #take off .txt
classNumStr = int(fileStr.split('_')[0])
vectorUnderTest = img2vector(pat +'/testDigits/%s' % fileNameStr)
classifierResult = classify0(vectorUnderTest, trainingMat, hwLabels, 3)
print ("the classifier came back with: %d, the real answer is: %d" % (classifierResult, classNumStr))
if (classifierResult != classNumStr): errorCount += 1.0
print ("\nthe total number of errors is: %d" % errorCount)
print ("\nthe total error rate is: %f" % (errorCount/float(mTest)))
return classifierResult, classNumStr, trainingMat
#以下为测试代码:
if __main__ == '__name__':
datingDataMat, datingLabels = file2matrix(path + '/datingTestSet2.txt')
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
d1 = pd.DataFrame(data = datingDataMat, columns = ['km', 'GameTime', 'IceCream'])
d2 = pd.DataFrame(datingLabels, columns = ['label'])
df = pd.concat([d1, d2], axis = 1)
df.info()
g = sns.FacetGrid(data = df, hue = 'label', size = 6, palette='Set2')
g.map(plt.scatter,'GameTime','IceCream').add_legend()
ax = sns.countplot(x = 'label', data = df, palette= 'Set3') #数据均匀分布
ax = sns.boxplot(y = 'GameTime', x = 'label', data = df, palette= 'Set3')
ax = sns.boxplot(y = 'IceCream', x = 'label', data = df, palette= 'Set3')
ax = sns.boxplot(y = 'km', x = 'label', data = df, palette= 'Set3')
g = sns.FacetGrid(data= df, hue = 'label', size = 6, palette='Set3')
g.map(plt.scatter,'GameTime','km').add_legend()
handwritingClassTest()
zero = trainingMat[8,:]
img_0 = zero.reshape(32,32)
plt.imshow(img_0)