(机器学习)-knn分类器的两个实例
文章目录
- 1 KNN电影的分类K-Nearest Neighbor
- 2.约会app的改进
1 KNN电影的分类K-Nearest Neighbor
根据打斗镜头和接吻镜头来给电影分出到底是动作片还是爱情片

存在一个样本数据集合,也称作训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一个数据与所属分类的对应关系。输入本有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取出样本集中特征最相似数据(最近邻)的分类标签。一般来说,我们只选择样本数据集中前k个最相似的数据,通常k是不大于20的整数
最后,选择k个最相似数据中出现次数最多的分类,作为新数据的分类

# -*- coding:utf-8 -*-
# @Time : 19-4-14 下午4:16
# @Author : flower
# @Filename : 7_knn1.py
# @software : PyCharm
import numpy as np
def createDataSet():
group = np.array([[3,104],[2,100],[1,81],[101,10],[95,5],[98,2]])
labels = ['Roman','Roman','Roman','Action','Action','Action']
return group,labels
def classify(inX,dataSet,labels,k):
"""
:param inX:要预测的电影数据 eg[18,90]
:param dataSet: 我们要传入的已知数据集
:param labels: 我们传入的标签 eg,labels
:param k: KNN里的K,也就是要选几个近邻
:return: 电影类型的排序
"""
dataSetSize = dataSet.shape[0] # 取6:(6,2)(数据集一共6行 2列)
# 重复inx,把他重复成((dataSetSize,1))矩阵(6,1)
diffMat = np.tile(inX,(dataSetSize,1))-dataSet # [[18,90],[18,90].....] - [[3,104],[2,100],[1,81],[101,10],[95,5],[98,2]]
sqDiffMat = diffMat **2 # 平方
sqDistance = sqDiffMat.sum(axis=1) # axis=1 行相加
distances = sqDistance ** 0.5 # 开根号
sortedDistIndicies = distances.argsort() # 排序 ,输出index值 [1 2 0 4 3 5]
classCount={}
for i in range(k):
voteLable = labels[sortedDistIndicies[i]]
classCount[voteLable] = classCount.get(voteLable,0) +1
# 为了避免0影响计算 所以加1
# print(classCount)
sortClassCount = sorted(classCount.items(),key=lambda d:float(d[1]),reverse=True)
return sortClassCount
if __name__ == '__main__':
group,label = createDataSet()
result = classify([18,90],group,label,3)
print(result)
输出:
[(‘Roman’, 1)]
2.约会app的改进
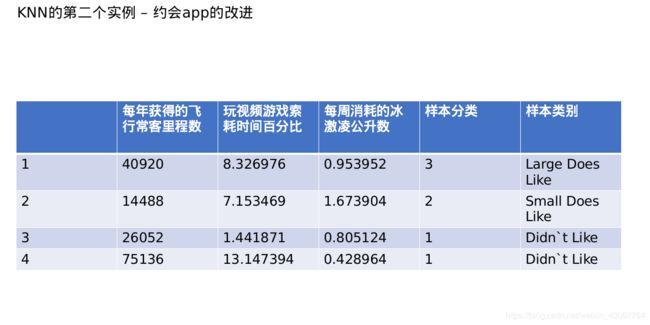
原数据:链接: https://pan.baidu.com/s/11L68F1Of386DcvKQzK9JKw 提取码: hwj6
#encoding:utf-8
"""
KNN实现,海伦的约会
"""
import numpy as np
import matplotlib.pyplot as plt
def file2matrix(filename):
fr = open(filename)
arrayOfLines = fr.readlines()
# print(arrayOfLines)
numerOfLines = len(arrayOfLines)
returnMat = np.zeros((numerOfLines, 3))
classLabelVetor = []
index = 0
for line in arrayOfLines:
line = line.strip()
listFromLine = line.split('\t')
returnMat[index, :] = listFromLine[0:3]
classLabelVetor.append(listFromLine[-1])
index += 1
return returnMat, classLabelVetor
def autoNorm(dataSet):
maxVals = dataSet.max(0)
m = dataSet.shape[0]
normDataSet = dataSet/np.tile(maxVals, (m, 1))
return normDataSet, maxVals
def classify(inX, dataSet, labels, k):
"""
:param inX: 要预测的电影数据 e.g. [18, 90]
:param dataSet: 我们要传入的已知数据集 e.g. group 相当于x
:param labels: 我们要传入的标签 e.g. labels 相当于y
:param k: KNN里的k, 也就是说我们要选几个近邻
:return: 电影类型的排序
"""
dataSetSize = dataSet.shape[0] # (6,2) 6
# tile会重复inX, 把他重复成(datasetsize, 1)型的矩阵
# print(inX)
# (x1 - y1), (x2- y2)
diffMat = np.tile(inX, (dataSetSize, 1)) - dataSet
# 平方
sqDiffMat = diffMat ** 2
# 相加, axis=1 行相加
sqDistance = sqDiffMat.sum(axis=1)
# 开根号
distances = sqDistance ** 0.5
# print(distances)
# 排序 输出的是序列号index,并不是值
sortedDistIndicies = distances.argsort()
# print(sortedDistIndicies)
classCount = {}
for i in range(k):
voteLabel = labels[sortedDistIndicies[i]]
classCount[voteLabel] = classCount.get(voteLabel, 0) + 1
# print(classCount)
sortedClassCount = sorted(classCount.items(), key=lambda d: float(d[1]), reverse=True)
return sortedClassCount
def datingClassTest(Person):
datingDataMat, datingLabels = file2matrix('./datingTestSet2.txt')
print(datingDataMat, datingLabels)
normDataSet, maxVals = autoNorm(datingDataMat)
classiferResult = classify(Person/maxVals, normDataSet, datingLabels, 3)
# print(classiferResult)
if classiferResult[0][0] == '1':
print("Didn`t Like")
elif classiferResult[0][0] == '2':
print("Smalll Does Like")
else:
print("Large Does Like")
if __name__ == '__main__':
datingDataMat, datingLabels = file2matrix('./datingTestSet2.txt')
#我们要把数据改成astype形式
datingLabels = np.array(datingLabels)
datingLabels = datingLabels.astype('float64')
# print(datingLabels)
# 创建画布
fig = plt.figure()
ax = fig.add_subplot(111)
# print(datingDataMat)
ax.scatter(datingDataMat[:, 0], datingDataMat[:, 2], 15.0*datingLabels, datingLabels)
plt.show()
normDataSet, maxVals = autoNorm(datingDataMat)
print(normDataSet)
datingClassTest([30000, 10 ,1.3])
输出:
Large Does Like