Python 使用Pandas进行数据预处理
1.转换数据
1.1哑变量处理类别型数据
利用pandas库中的get_dummies函数对类别型特征进行哑变量处理。
get_dummies语法:
pandas.get_dummies(data,prefix=None,prefix_sep='_',dummy_na=False,columns=None,sparse=False,drop_first=False)- data: 表示需要哑变量处理的数据
- prefix:哑变量后列名的前缀
- prefix_sep='_':连接符
- dummy_na=False:是否为Nan值添加一列
对类别型特征进行哑变量处理主要解决了部分算法模型无法处理类别性数据的问题,在一定程度上起到了扩充特征的作用
哑变量处理前:
import pandas as pd
city_data=pd.DataFrame({"城市":["广州","上海","杭州","北京","深圳","杭州","上海"]})
print(city_data) 
cdummies_data=pd.get_dummies(city_data) #哑变量处理
print(cdummies_data) 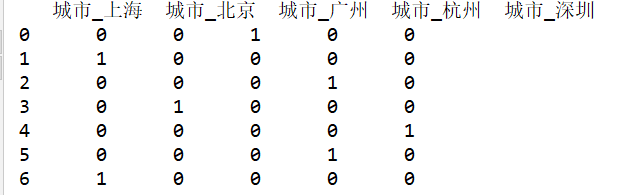
1.2离散化连续型数据:等宽法、等频法和聚类分析法(一维)
1.2.1等宽法
pandas提供了cut函数,完成连续性数据的等宽离散化。
cut基础语法:
pandas.cut(x,bins,right,labels=None)- x: 需要进行离散化的数据
- bins: 若为int,代表离散化后的类别数目;若为序列类型的数据,则表示进行切分的区间,每两个数的间隔为一个区间
- right: 代表右侧是否为闭区间,默认True
- labels: 接收list、array。离散后各个类别的名称
age_data=pd.DataFrame({"年龄":[14,16,18,19,23,34,67,87]})
print(age_data) 
agec_data=pd.cut(age_data.iloc[:,0],3)
#pandas中的value_counts函数,帮助我们自动统计某一列不同类别出现的次数,而且自动进行排序
print("离散化后的年龄分布为:\n",agec_data.value_counts())结果:
离散化后的年龄分布为:
(13.927, 38.333] 6
(62.667, 87.0] 2
(38.333, 62.667] 0
Name: 年龄, dtype: int64
等宽法缺陷:等宽法离散化对数据分布具有较高的要求,若数据分布不均匀,那么各类别的数目会变得非常不均匀,会严重损坏所建立的模型
1.2.2等频法
等频法避免了分布不均匀的问题,但可能将数值接近的两个值分配到不同的区间以满足每个区间对个数的要求
cut虽然不能直接实现等频离散化,但可以通过定义函数将相同数量的记录放进每个区间
import pandas as pd
import numpy as np
age_data=pd.DataFrame({"年龄":[14,16,18,19,23,34,67,87]})
def SameRateCut(data,k):
w=data.quantile(np.arange(0,1+1.0/k,1.0/k))
data=pd.cut(data,w)
return data
#对年龄数据进行离散化
result=SameRateCut(age_data.iloc[:,0],3).value_counts()
print('对年龄进行等频离散化后各类别数目分布状况为:\n',result)
注意:进行离散化处理的数据必须是一维,否则会报错。
结果:
对年龄进行等频离散化后各类别数目分布状况为:
(30.333, 87.0] 3
(18.333, 30.333] 2
(14.0, 18.333] 2
Name: 年龄, dtype: int641.2.3聚类分析法
一维聚类步骤:首先将连续性数据用聚类算法(K-Means算法等)进行聚类,然后处理聚类得到的簇,为合并到一个簇的连续型数据做同一种标记
聚类分析的离散化方法需要用户指定簇的个数,用来决定产生的区间数
理解即可:
import pandas as pd
def KmeanCut(data,k):
from sklearn.cluster import KMeans
#建立模型 n_jobs
kmodel=KMeans(n_clusters=k,n_jobs=4)
kmodel.fit(data.reshape((len(data),1)))#训练模型
#输出聚类中心并排序
c=pd.DataFrame(kmodel.cluster_centers_).sort_values(0)
w=pd.rolling_mean(c,2).iloc[1:]#相邻两项求中点,作为边界点
w=[0]+list(w[0])+[data.max()] #把首末边界点加上
data=pd.cut(data,w)
return data