机器学习系列24-迁移学习
Transfer Learning
如果本文对你有帮助,请给我的github打个star叭,上面附有全系列目录和内容!
更多优质内容欢迎关注我的微信公众号“Sakura的知识库”:

迁移学习,主要介绍共享layer的方法以及属性降维对比的方法
Introduction
迁移学习,transfer learning,旨在利用一些不直接相关的数据对完成目标任务做出贡献
not directly related
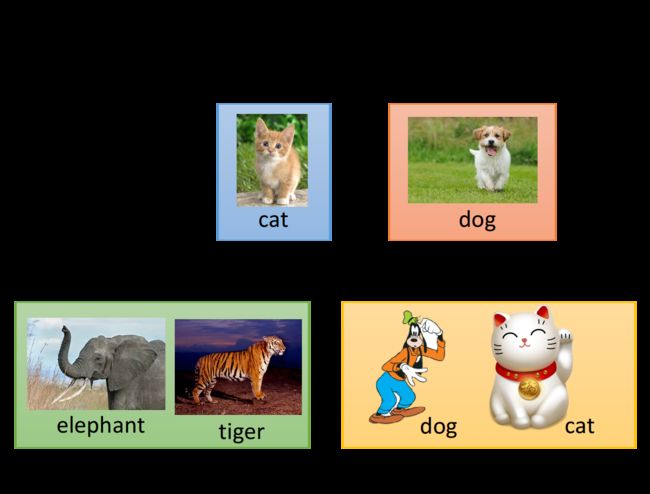
以猫狗识别为例,解释“不直接相关”的含义:
-
input domain是类似的,但task是无关的
比如输入都是动物的图像,但这些data是属于另一组有关大象和老虎识别的task
-
input domain是不同的,但task是一样的
比如task同样是做猫狗识别,但输入的是卡通类型的图像
compare with real life
事实上,我们在日常生活中经常会使用迁移学习,比如我们会把漫画家的生活自动迁移类比到研究生的生活

overview
迁移学习是很多方法的集合,这里介绍一些概念:
- Target Data:和task直接相关的data
- Source Data:和task没有直接关系的data
按照labeled data和unlabeled data又可以划分为四种:

Case 1
这里target data和source data都是带有标签的:
-
target data: ( x t , y t ) (x^t,y^t) (xt,yt),作为有效数据,通常量是很少的
如果target data量非常少,则被称为one-shot learning
-
source data: ( x s , y s ) (x^s, y^s) (xs,ys),作为不直接相关数据,通常量是很多的
Model Fine-tuning
Introduction
模型微调的基本思想:用source data去训练一个model,再用target data对model进行微调(fine tune)
所谓“微调”,类似于pre-training,就是把用source data训练出的model参数当做是参数的初始值,再用target data继续训练下去即可,但当直接相关的数据量非常少时,这种方法很容易会出问题
所以训练的时候要小心,有许多技巧值得注意
Conservation Training
如果现在有大量的source data,比如在语音识别中有大量不同人的声音数据,可以拿它去训练一个语音识别的神经网络,而现在你拥有的target data,即特定某个人的语音数据,可能只有十几条左右,如果直接拿这些数据去再训练,肯定得不到好的结果
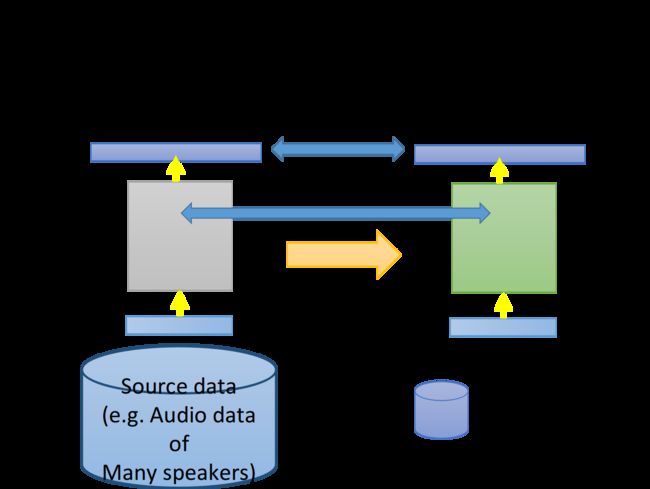
此时我们就需要在训练的时候加一些限制,让用target data训练前后的model不要相差太多:
- 我们可以让新旧两个model在看到同一笔data的时候,output越接近越好
- 或者让新旧两个model的L2 norm越小越好,参数尽可能接近
- 总之让两个model不要相差太多,防止由于target data的训练导致过拟合
注:这里的限制就类似于regularization
Layer Transfer
现在我们已经有一个用source data训练好的model,此时把该model的某几个layer拿出来复制到同样大小的新model里,接下来只用target data去训练余下的没有被复制到的layer
这样做的好处是target data只需要考虑model中非常少的参数,这样就可以避免过拟合
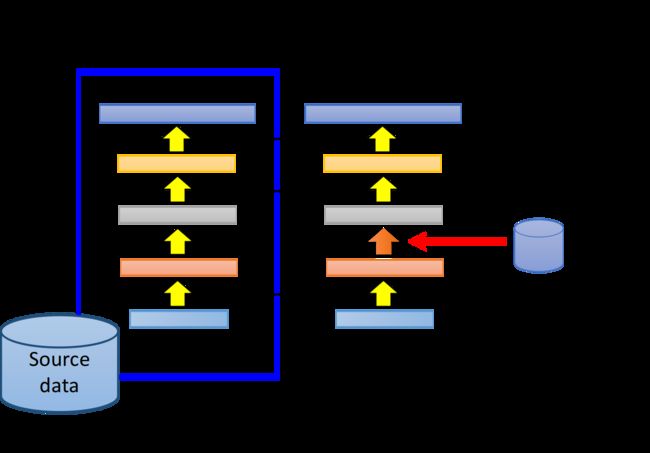
这个对部分layer进行迁移的过程,就体现了迁移学习的思想,接下来要面对的问题是,哪些layer需要被复制迁移,哪些不需要呢?
值得注意的是,在不同的task上,需要被复制迁移的layer往往是不一样的:
-
在语音识别中,往往迁移的是最后几层layer,再重新训练与输入端相邻的那几层
由于口腔结构不同,同样的发音方式得到的发音是不一样的,NN的前几层会从声音信号里提取出发音方式,再用后几层判断对应的词汇,从这个角度看,NN的后几层是跟特定的人没有关系的,因此可做迁移
-
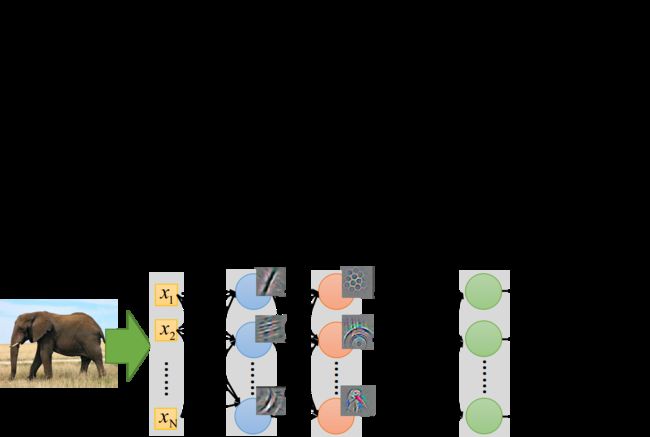
在图像处理中,往往迁移的是前面几层layer,再重新训练后面的layer
CNN在前几层通常是做最简单的识别,比如识别是否有直线斜线、是否有简单的几何图形等,这些layer的功能是可以被迁移到其它task上通用的
-
主要还是具体问题具体分析
Multitask Learning
Introduction
fine-tune仅考虑在target data上的表现,而多任务学习,则是同时考虑model在source data和target data上的表现
如果两个task的输入特征类似,则可以用同一个神经网络的前几层layer做相同的工作,到后几层再分方向到不同的task上,这样做的好处是前几层得到的data比较多,可以被训练得更充分
有时候task A和task B的输入输出都不相同,但中间可能会做一些类似的处理,则可以让两个神经网络共享中间的几层layer,也可以达到类似的效果
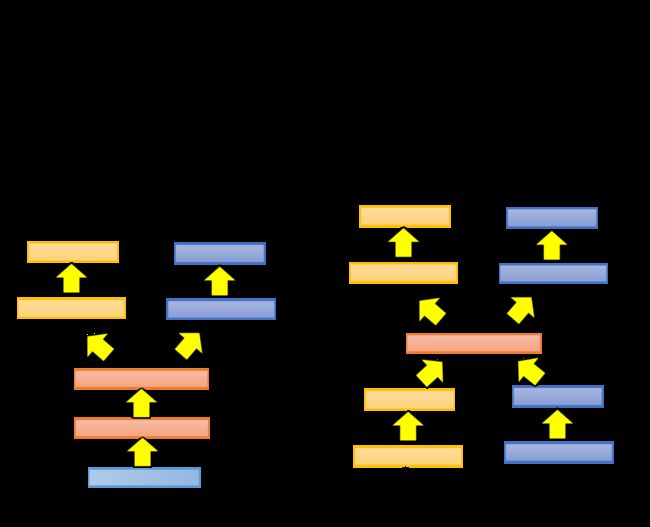
注意,以上方法要求不同的task之间要有一定的共性,这样才有共用一部分layer的可能性
Multilingual Speech Recognition
多任务学习在语音识别上比较有用,可以同时对法语、德语、西班牙语、意大利语训练一个model,它们在前几层layer上共享参数,而在后几层layer上拥有自己的参数
在机器翻译上也可以使用同样的思想,比如训练一个同时可以中翻英和中翻日的model
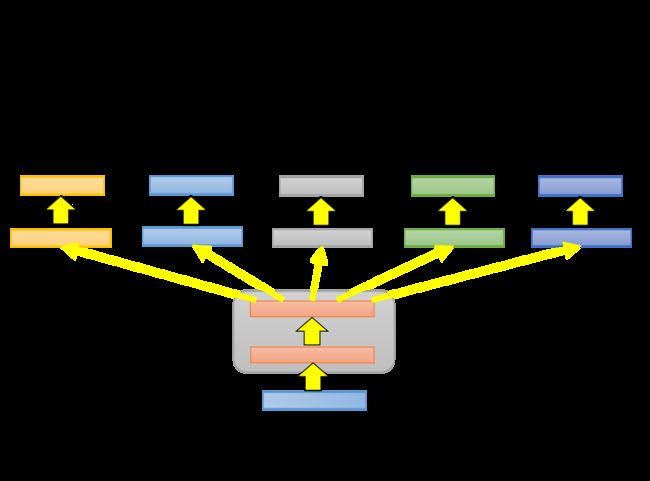
注意到,属于同一个语系的语言翻译,比如欧洲国家的语言,几乎都是可以做迁移学习的;而语音方面则可迁移的范围更广
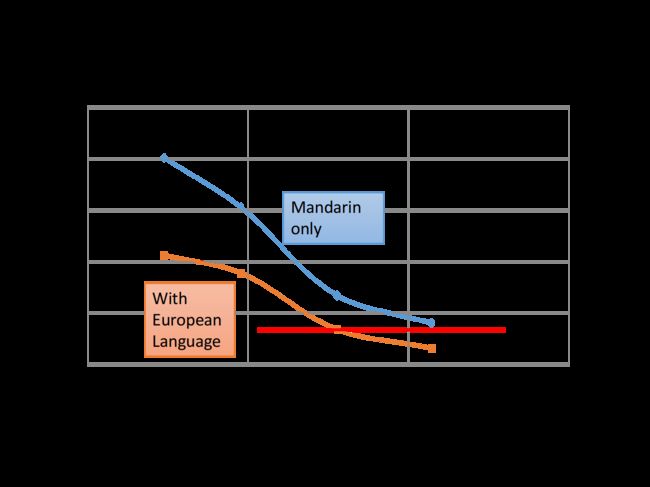
下图展示了只用普通话的语音数据和加了欧洲话的语音数据之后得到的错误率对比,其中横轴为使用的普通话数据量,纵轴为错误率,可以看出使用了迁移学习后,只需要原先一半的普通话语音数据就可以得到几乎一样的准确率
Progressive Neural Network
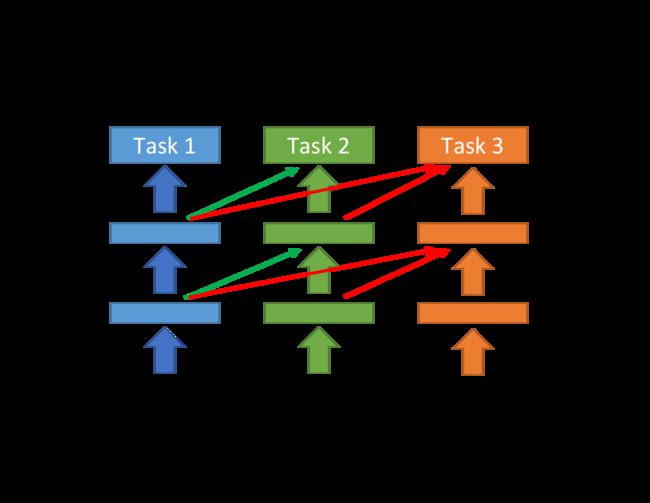
如果两个task完全不相关,硬是把它们拿来一起训练反而会起到负面效果
而在Progressive Neural Network中,每个task对应model的hidden layer的输出都会被接到后续model的hidden layer的输入上,这样做的好处是:
-
task 2的data并不会影响到task 1的model,因此task 1一定不会比原来更差
-
task 2虽然可以借用task 1的参数,但可以将之直接设为0,最糟的情况下就等于没有这些参数,也不会对本身的表现产生影响
-
task 3也做一样的事情,同时从task 1和task 2的hidden layer中得到信息
Case 2
这里target data不带标签,而source data带标签:
-
target data: ( x t ) (x^t) (xt)
-
source data: ( x s , y s ) (x^s, y^s) (xs,ys)
Domain-adversarial Training
如果source data是有label的,而target data是没有label的,该怎么处理呢?
比如source data是labeled MNIST数字集,而target data则是加了颜色和背景的unlabeled数字集,虽然都是做数字识别,但两者的情况是非常不匹配的

这个时候一般会把source data当做训练集,而target data当做测试集,如果不管训练集和测试集之间的差异,直接训练一个普通的model,得到的结果准确率会相当低
实际上,神经网络的前几层可以被看作是在抽取feature,后几层则是在做classification,如果把用MNIST训练好的model所提取出的feature做t-SNSE降维后的可视化,可以发现MNIST的数据特征明显分为紫色的十团,分别代表10个数字,而作为测试集的数据却是挤成一团的红色点,因此它们的特征提取方式根本不匹配
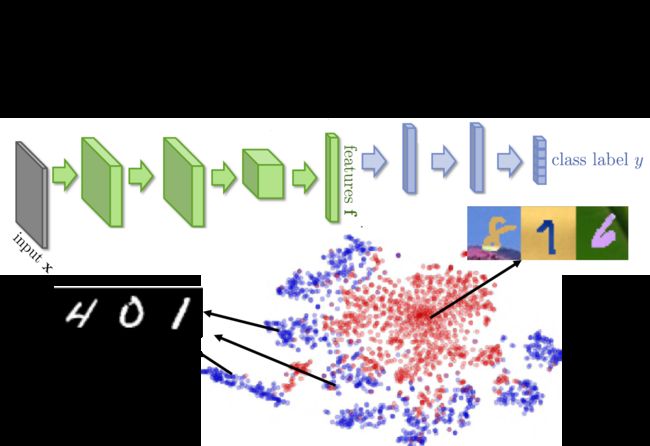
所以我们希望前面的特征提取器(feature extractor)可以把domain的特性去除掉,不再使红点与蓝点分成两群,而是让它们都混在一起
这里采取的做法是,在特征提取器(feature extractor)之后接一个域分类器(domain classifier),以便分类出这些提取到的feature是来自于MNIST的数据集还是来自于MNIST-M的数据集,这个生成+辨别的架构与GAN非常类似
只不过在这里,feature extractor可以通过把feature全部设为0,很轻易地骗过domain classifier,因此还需要给feature classifier增加任务的难度,它不只要骗过domain classifier,还要同时满足label predictor的需求
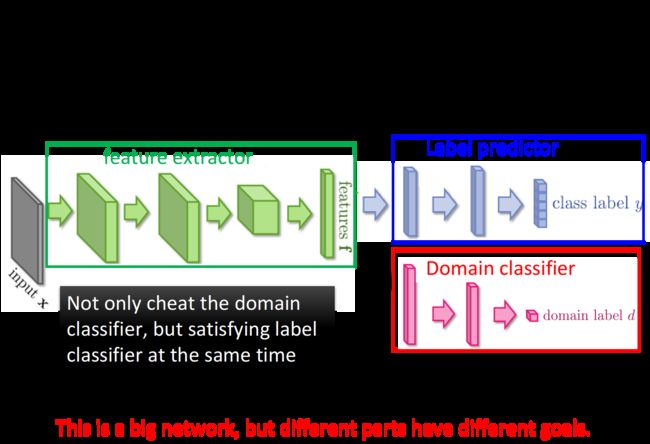
此时通过特征提取器得到的feature不仅可以消除不同domain的特性,还要保留原先digit的特性,既可以区分不同类别的数字集,又可以正确地识别出不同的数字
通常神经网络的参数都是朝着最小化loss的目标共同前进的,但在这个神经网络里,三个组成部分的参数各怀鬼胎:
- 对Label predictor,要把不同数字的分类准确率做的越高越好
- 对Domain classifier,要正确地区分某张image是属于哪个domain
- 对Feature extractor,要提高Label predictor的准确率,但要降低Domain classifier的准确率
这里可以看出,Feature extractor和Domain classifier的目标是相反的,要做到这一点,只需要在两者之间加一层梯度反转的layer即可,当NN做backward的时候,两者的参数更新往相反的方向走
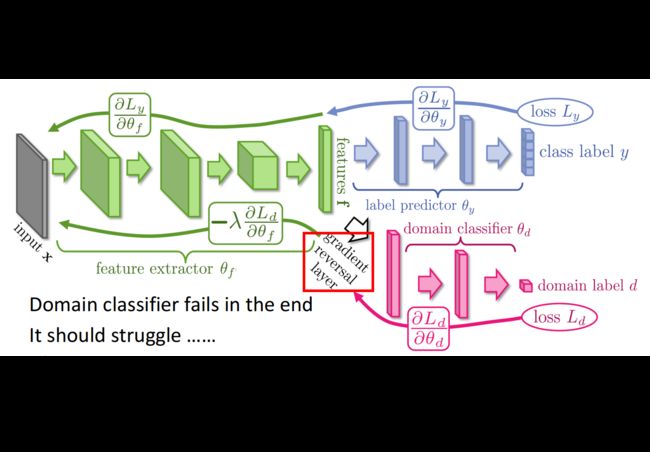
注意到,Domain classifier只能接受到Feature extractor给到的特征信息,而无法直接看到图像的样子,因此它最后一定会鉴别失败,所以如何提高Domain classifier的能力,让它经过一番奋力挣扎之后才牺牲是很重要的,如果它一直很弱,就无法把Feature extractor的潜能激发到极限
Zero-shot Learning
同样是source data有label,target data没有label的情况,但在Zero-shot Learning中的定义更严格一些,它假设source和target是两个完全不同的task,数据完全不相关
在语音识别中,经常会遇到这个问题,毕竟词汇千千万万,总有一些词汇是训练时不曾遇到过的,它的处理方法是不要直接将识别的目标定成word,而是定成phoneme(音素),再建立文字与phoneme之间的映射表即可
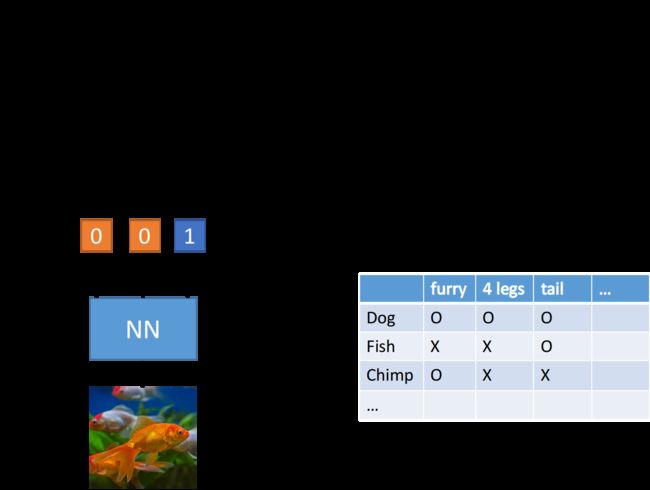
在图像处理中,我们可以把每个类别都用其属性表示,并且要具备独一无二的属性,在数据集中把每种动物按照特性划分,比如是否毛茸茸、有几只脚等,在训练的时候我们不直接去判断类别,而是去判断该图像的属性,再根据这些属性去找到最契合的类别即可
有时候属性的维数也很大,以至于我们对属性要做embedding的降维映射,同样的,还要把训练集中的每张图像都通过某种转换投影到embedding space上的某个点,并且要保证属性投影的 g ( y i ) g(y^i) g(yi)和对应图像投影的 f ( x i ) f(x^i) f(xi)越接近越好,这里的 f ( x n ) f(x^n) f(xn)和 g ( y n ) g(y^n) g(yn)可以是两个神经网络
当遇到新的图像时,只需要将其投影到相同的空间,即可判断它与哪个属性对应的类别更接近

但如果我们根本就无法找出每个动物的属性 y i y^i yi是什么,那该怎么办?可以使用word vector,比如直接从维基百科上爬取图像对应的文字描述,再用word vector降维提取特征,映射到同样的空间即可
以下这个loss function存在些问题,它会让model把所有不同的x和y都投影到同一个点上:
f ∗ , g ∗ = arg min f , g ∑ n ∣ ∣ f ( x n ) − g ( y n ) ∣ ∣ 2 f^*,g^*=\arg \min\limits_{f,g} \sum\limits_n ||f(x^n)-g(y^n)||_2 f∗,g∗=argf,gminn∑∣∣f(xn)−g(yn)∣∣2
类似用t-SNE的思想,我们既要考虑同一对 x n x^n xn和 y n y^n yn距离要接近,又要考虑不属于同一对的 x n x^n xn与 y m y^m ym距离要拉大(这是前面的式子没有考虑到的),于是有:
f ∗ , g ∗ = arg min f , g ∑ n max ( 0 , k − f ( x n ) ⋅ g ( y n ) + max m ≠ n f ( x n ) ⋅ g ( y m ) ) f^*,g^*=\arg \min\limits_{f,g} \sum\limits_n \max(0, k-f(x^n)\cdot g(y^n)+\max\limits_{m\ne n} f(x^n)\cdot g(y^m)) f∗,g∗=argf,gminn∑max(0,k−f(xn)⋅g(yn)+m=nmaxf(xn)⋅g(ym))