GBDT+LR记录- 9.7代码训练GBDT与LR混合模型
GBDT+LR记录
9.7代码训练GBDT与LR混合模型
在上一节课的train.py中,新建一个函数train_tree_and_lr_model
def train_tree_and_lr_model(train_file, feature_num_file, mix_tree_model_file, mix_lr_model_file):
"""
gbdt+lr 混合模型 ,分开 训练 顺序训练(耗时较长)
:param train_file: 训练数据
:param feature_num_file: 特征维度文件
:param mix_tree_model_file: 混合模型树模型部分的文件
:param mix_lr_model_file: 混合模型逻辑回归部分的文件
:return: None
"""
train_feature, train_label = get_train_data(train_file, feature_num_file) # 传入 训练数据 和 特征维度文件
train_mat = xgb.DMatrix(train_feature, train_label) # 将数据结构转化成gbdt所需要的数据结构,因为我们用的xgboost,所以与之前树模型一样
tree_num, tree_depth, learning_rate = 10,6, 0.3 # 上一节已经选出了最优的参数
# (tree_depth, tree_num, learning_rate) = get_mix_model_tree_info()
# 这里树的深度由 6 改为4,原因:如下: 深度为6:总共:127个节点,64个叶子节点,63个非叶子节点
# 1.训练出的label,没有落在叶子节点上(或者落在叶子节点上比较少)
# 2. 特征与样本量的比值:1:100。 因为: 10颗数,深度为6,则叶子节点有 有640个维度,而样本有3万条,不满足
#训练树模型的代码,因为混合模型是分开训练,所以把树模型存储一下save_model
bst = train_tree_model_core(train_mat,tree_depth,tree_num,learning_rate) #此处调用一下训练树的主体函数,分别传入所需参数
bst.save_model(mix_tree_model_file)
# 理论部分已经讲过,lr模型所需特征是通过树模型通过编码得到的,所以只需叶的结点编成离散化特征,先预测一下样本
tree_leaf = bst.predict(train_mat,pred_leaf=True) #预测最终结果落在哪一个叶子节点上
# print(tree_leaf) #[81 84 84 84 85 77 68 91 97 61] 代表10颗数,81代表最终1 落到那一颗叶子节点上
# print(np.max(tree_leaf))
# sys.exit()
# 将上边落在哪一个叶子节点上的结果进行加工,最终获取训练lr所需要的特征,定义get_gbdt_and_lr_featrue专门完成特征转化
# 定义get_gbdt_and_lr_featrue专门完成特征转化,因为我们最终看落哪个叶的结点,所以这里的总的结点需要把它转换一下
total_feature_list = get_gbdt_and_lr_feature(tree_leaf,tree_num,tree_depth)
# 逻辑回归(前面课程详细讲过,所以这里就直接复制一下)
# zin模型训练中要注意的参数
# 1.正则化参数,这里支持多种参数进行选择,分别选一下,Cs=[1,10,100],这里边填入数的倒数便是正则化参数即1,0.1,0.01
# 2,penalty="l2",正则化选用l2(L2),之前讲过l1正则化倾向于将特征对应的参数学为0,而这里一共就100多列特征,我们倾向于将这些特征的参数选小而不是学为0
# 3.参数迭代停止的条件tol=0.0001,选为万分之1
# 4.最大迭代次数选择500次
# 5.cv=5,指定几轴交叉验证,意思是将训练数据分为5份,每一次拿出20%作为测试,80%作为训练,一共进行5次
# 最优化方法的选择:坐标轴下降法、牛顿法、梯度下降法(随机梯度下降):为了适应大数据训练,采用了随机梯度下降,我在每带选择一部分,近似整个代的记录,减少计算量提高计算速度
# 我们这里选了penalty="l2",所以只能选牛顿法/梯度下降法(随机梯度下降),这里默认选择牛顿法,因为我们样本不是特别多,我们希望所有样本都参与到训练中
lr_cf = LRCV(Cs=[1],penalty="l2",tol=0.0001,max_iter=500,cv=5).fit(train_feature,train_label)
#需要观察一下训练的结果//视频下边一行为scores = lr_cf.scores_.values()[0],改为源代码中如下两行
scores = lr_cf.scores_.values()
scores = list(scores)[0] # 提取values值
# 得到的scores是个5行3列的数组,所以我们看下每个正则化参数对应的5轴交叉验证之后平均的准确率是多少
print("diff %s : " % (",".join([str(ele) for ele in scores.mean(axis=0)]))) # 按照列求均值
print("Accuracy:%s (+- %0.2f ) "%(scores.mean(),scores.std()*2))
#print("Accuracy:%s " % (scores.mean())) #视频中不是mean(),mean后边没有(),后来又加上了()
# 模型的auc Cs=[1,10,100] #输出一下AUC,在lr_cf里加上scoring='roc_auc'
lr_cf = LRCV(Cs=[1], penalty="l2", tol=0.00001, max_iter=1000, cv=5, scoring='roc_auc').fit(train_feature,train_label)
scores = lr_cf.scores_.values()
scores = list(scores)[0] # 提取values值
#print(scores)
print("diff %s : " % (" ".join([str(ele) for ele in scores.mean(axis=0)]))) # 按照列求均值
print("AUC:%s (+- %0.2f )" % (scores.mean(),scores.std()*2))
添加get_gbdt_and_lr_feature
返回值为稀疏矩阵。
原因:深度是6,叶的节点2的6次方=64,10棵树们就是2的6次方*10=640个特征,实际深度更深,棵树更多,显然特征是非常非常长的,但是每一棵树所对应的特征编码只有一个位置是1,其余位置是0,所以用稀疏矩阵来存储更接近于实战时的存储。
首先计算一下叶的节点和非叶节点
1)总节点——深度为2的数,总节点为7,分别是根节点1+再两个2+再两个4=7
即(2的(深度+1)次方-1)
2)叶的节点——2的深度次方
3)非叶的节点——总节点-叶的节点
4)总维度——叶的节点的数目*棵树
5)样本数——total_row_num来储存
录入稀疏矩阵中
get_gbdt_and_lr_feature代码如下
def get_gbdt_and_lr_feature(tree_leaf,tree_num,tree_depth):
"""
提取特征的代码
:param tree_leaf: predict of tree model
:param tree_num: total_num
:param tree_depth:
:return: 返回稀疏矩阵: 因为树的深度越深,叶子节点就越多,再加上树很多。那叶子节点就更稀疏
"""
total_node_num = 2**(tree_depth +1) -1
leaf_num = 2**tree_depth
not_leaf_num = total_node_num - leaf_num
total_col_num = leaf_num * tree_num # 总叶子节点数,总维度
total_row_num = len(tree_leaf) # 多少样本
col=[]
row= []
data = []
把前面train_tree_and_lr_model注释掉sys.exit()用的#去掉 需要这行sys.exit(),并在sys.exit()上边加一行print(tree_leaf[0])
此时train_tree_and_lr_model代码如下
def train_tree_and_lr_model(train_file, feature_num_file, mix_tree_model_file, mix_lr_model_file):
"""
gbdt+lr 混合模型 ,分开 训练 顺序训练(耗时较长)
:param train_file: 训练数据
:param feature_num_file: 特征维度文件
:param mix_tree_model_file: 混合模型树模型部分的文件
:param mix_lr_model_file: 混合模型逻辑回归部分的文件
:return: None
"""
train_feature, train_label = get_train_data(train_file, feature_num_file) # 传入 训练数据 和 特征维度文件
train_mat = xgb.DMatrix(train_feature, train_label) # 将数据结构转化成gbdt所需要的数据结构,因为我们用的xgboost,所以与之前树模型一样
tree_num, tree_depth, learning_rate = 10,6, 0.3 # 上一节已经选出了最优的参数
# (tree_depth, tree_num, learning_rate) = get_mix_model_tree_info()
# 这里树的深度由 6 改为4,原因:如下: 深度为6:总共:127个节点,64个叶子节点,63个非叶子节点
# 1.训练出的label,没有落在叶子节点上(或者落在叶子节点上比较少)
# 2. 特征与样本量的比值:1:100。 因为: 10颗数,深度为6,则叶子节点有 有640个维度,而样本有3万条,不满足
#训练树模型的代码,因为混合模型是分开训练,所以把树模型存储一下save_model
bst = train_tree_model_core(train_mat,tree_depth,tree_num,learning_rate) #此处调用一下训练树的主体函数,分别传入所需参数
bst.save_model(mix_tree_model_file)
# 理论部分已经讲过,lr模型所需特征是通过树模型通过编码得到的,所以只需叶的结点编成离散化特征,先预测一下样本
tree_leaf = bst.predict(train_mat,pred_leaf=True) #预测最终结果落在哪一个叶子节点上
# print(tree_leaf) #[81 84 84 84 85 77 68 91 97 61] 代表10颗数,81代表最终1 落到那一颗叶子节点上
# print(np.max(tree_leaf))
print(tree_leaf[0])
sys.exit()
# 将上边落在哪一个叶子节点上的结果进行加工,最终获取训练lr所需要的特征,定义get_gbdt_and_lr_featrue专门完成特征转化
# 定义get_gbdt_and_lr_featrue专门完成特征转化,因为我们最终看落哪个叶的结点,所以这里的总的结点需要把它转换一下
total_feature_list = get_gbdt_and_lr_feature(tree_leaf,tree_num,tree_depth)
# 逻辑回归(前面课程详细讲过,所以这里就直接复制一下)
# zin模型训练中要注意的参数
# 1.正则化参数,这里支持多种参数进行选择,分别选一下,Cs=[1,10,100],这里边填入数的倒数便是正则化参数即1,0.1,0.01
# 2,penalty="l2",正则化选用l2(L2),之前讲过l1正则化倾向于将特征对应的参数学为0,而这里一共就100多列特征,我们倾向于将这些特征的参数选小而不是学为0
# 3.参数迭代停止的条件tol=0.0001,选为万分之1
# 4.最大迭代次数选择500次
# 5.cv=5,指定几轴交叉验证,意思是将训练数据分为5份,每一次拿出20%作为测试,80%作为训练,一共进行5次
# 最优化方法的选择:坐标轴下降法、牛顿法、梯度下降法(随机梯度下降):为了适应大数据训练,采用了随机梯度下降,我在每带选择一部分,近似整个代的记录,减少计算量提高计算速度
# 我们这里选了penalty="l2",所以只能选牛顿法/梯度下降法(随机梯度下降),这里默认选择牛顿法,因为我们样本不是特别多,我们希望所有样本都参与到训练中
lr_cf = LRCV(Cs=[1],penalty="l2",tol=0.0001,max_iter=500,cv=5).fit(train_feature,train_label)
#需要观察一下训练的结果//视频下边一行为scores = lr_cf.scores_.values()[0],改为源代码中如下两行
scores = lr_cf.scores_.values()
scores = list(scores)[0] # 提取values值
# 得到的scores是个5行3列的数组,所以我们看下每个正则化参数对应的5轴交叉验证之后平均的准确率是多少
print("diff %s : " % (",".join([str(ele) for ele in scores.mean(axis=0)]))) # 按照列求均值
print("Accuracy:%s (+- %0.2f ) "%(scores.mean(),scores.std()*2))
#print("Accuracy:%s " % (scores.mean())) #视频中不是mean(),mean后边没有(),后来又加上了()
# 模型的auc Cs=[1,10,100] #输出一下AUC,在lr_cf里加上scoring='roc_auc'
lr_cf = LRCV(Cs=[1], penalty="l2", tol=0.00001, max_iter=1000, cv=5, scoring='roc_auc').fit(train_feature,train_label)
scores = lr_cf.scores_.values()
scores = list(scores)[0] # 提取values值
#print(scores)
print("diff %s : " % (" ".join([str(ele) for ele in scores.mean(axis=0)]))) # 按照列求均值
print("AUC:%s (+- %0.2f )" % (scores.mean(),scores.std()*2))
main函数加点东西
if __name__ == "__main__":
train_tree_model("data/gbdt_train_file", "data/gbdt_feature_num", "data/test.model")
# 由于我们这里还没有实例化,所以先随便写两个文件
train_tree_and_lr_model("data/gbdt_train_file", "data/gbdt_feature_num", "test","test1")
此时train.py为如下
# -*- coding: utf-8 -*-
"""
==================================================
File Name: train
Description : Practical Lessons from Predicting Clicks on Ads at Facebook (2014)论文阅读
==================================================
"""
import xgboost as xgb
#import utils
import numpy as np # np读入文件
from sklearn.linear_model import LogisticRegressionCV as LRCV
from scipy.sparse import coo_matrix
import sys
#sys.path.append("../util")
sys.path.append("../..")
import p_recommendation_myself.gbdt_lr.util.get_feature_num as GF
#from p_recommendation_myself.gbdt_lr.util.get_feature_num import get_feature_num as GF
#from p_recommendation_myself.gbdt_lr.util.get_feature_num import get_feature_num as GF
#from p_recommendation_myself.gbdt_lr.util.utils import get_feature_num as GF
# zin 01
def get_train_data(train_file, feature_num_file):
"""获得训练数据 label和特征"""
total_feature_num = GF.get_feature_num(feature_num_file)
train_label = np.genfromtxt(train_file, dtype=np.int32, delimiter=",", usecols=-1) # label最后1列,label
feature_list = range(0, total_feature_num)
train_feature = np.genfromtxt(train_file, dtype=np.int32, delimiter=",", usecols=feature_list)
return train_feature, train_label
def train_tree_model_core(train_mat, tree_depth, tree_num, learning_rate):
"""
:param train_mat: 训练数据和label
:param tree_depth: 树的深度
:param tree_num:树的数量
:param learning_rate: 学习率
:return:Booster
"""
para_dict = {"max_depth": tree_depth, "eta": learning_rate, "objective": "reg:linear", "silent": 1}
bst = xgb.train(params=para_dict, dtrain=train_mat, num_boost_round=tree_num) #para_dict为几个参数组成的字典
# 交叉验证
#print(xgb.cv(params=para_dict, dtrain=train_mat, num_boost_round=tree_num, nfold=5, metrics={"auc"}))
return bst
#9-6
def choose_parameter():
"""生成参数
zin:list是元组,分别是树深度,树数目,步长;
这3个参数列表中的数目也可以增加,当然耗时也就会增加了
比如tree_depth_list = [4,5,6]可以为tree_depth_list = [4,5,6,7,8,9...]
"""
result_list = [] # 定义输出列表
tree_depth_list = [4,5,6] # [4,5,6]
tree_num_list = [10,50,100] # [10,50,100]
learning_rate_list = [0.3,0.5,0.7] # [0.3,,]
for ele_tree_depth in tree_depth_list:
for ele_tree_num in tree_num_list:
for ele_learning_rate in learning_rate_list:
result_list.append((ele_tree_depth, ele_tree_num, ele_learning_rate)) # 将结果以元组形式装载,注意顺序:深度,数目,步长
return result_list # 将最终结果返回
# 9-6
def grid_search(train_mat):
"""网格搜索参数"""
para_list = choose_parameter() # 定义一个构建参数的函数
for ele in para_list:
(tree_depth, tree_num, learning_rate) = ele # 元组包括这3个参数
para_dict = {"max_depth": tree_depth, "eta": learning_rate, "objective": "reg:linear", "silent": 1}
res = xgb.cv(params=para_dict, dtrain=train_mat, num_boost_round=tree_num, nfold=5, metrics={"auc"})
# 上一次课是10棵树,有10行,所以我们应该选最后一行结果,行号为树的总的数目,列为test-auc-mean,用values[0]把值获取出来
auc_score = res.loc[tree_num - 1, ["test-auc-mean"]].values[0] # 获取最后一棵树的得分就行了。
# 输出一下每一组参数和auc得分,把对应值tree_depth, tree_num, learning_rate, auc_score填进去,太长了,换下行
print("tree depth: %s , tree_num: %s , learning_rate: %s , auc: %f" % (
tree_depth, tree_num, learning_rate, auc_score))
# zin 9-5 T2-1-1 三个参数(筛选好的特征及样本文件,记录特征维度的文件,模型的存储文件)
def train_tree_model(train_file, feature_num_file, tree_model_file):
"""
训练树模型
"""
train_feature, train_label = get_train_data(train_file, feature_num_file)
train_mat = xgb.DMatrix(train_feature, train_label) # xgboost 需要的结构需要此类包装,训练的数据以及label
#grid_search(train_mat) # 参数选择,选择一次,就行,后面就无需继续使用了。,9.6刚开始未注释这行,运行后得到了最优参数后,便可以不再参数选择了,所以之后注释掉了这行
#sys.exit()
tree_num = 10
tree_depth = 6
learning_rate = 0.3 # 步长fm=fm-1+step_size*Tm
bst = train_tree_model_core(train_mat, tree_depth, tree_num, learning_rate) # 3个参数,训练的数据以及label,深度,数量,步长
#
bst.save_model(tree_model_file) # 将模型实例化输出,之后也就不需要再进行交叉验证参数选择了
#9-7
def get_gbdt_and_lr_feature(tree_leaf,tree_num,tree_depth):
"""
提取特征的代码
:param tree_leaf: predict of tree model
:param tree_num: total_num
:param tree_depth:
:return: 返回稀疏矩阵: 因为树的深度越深,叶子节点就越多,再加上树很多。那叶子节点就更稀疏
"""
total_node_num = 2**(tree_depth +1) -1
leaf_num = 2**tree_depth
not_leaf_num = total_node_num - leaf_num
total_col_num = leaf_num * tree_num # 总叶子节点数,总维度
total_row_num = len(tree_leaf) # 多少样本
col=[]
row= []
data = []
# base_row_index = 0
# for one_result in tree_leaf:
# base_col_index = 0
# for fix_index in one_result:
# leaf_index = fix_index - not_leaf_num
# leaf_index = leaf_index if leaf_index >=0 else 0
# col.append(base_col_index +leaf_index)
# row.append(base_row_index)
# data.append(1)
# base_col_index += leaf_num # zin-在基础列索引之上加上叶子数目
# base_row_index +=1
# total_feature_list = coo_matrix((data,(row,col)),shape=(total_row_num,total_col_num)) # 转化为稀疏矩阵形式
#
# return total_feature_list
#9-7
def train_tree_and_lr_model(train_file, feature_num_file, mix_tree_model_file, mix_lr_model_file):
"""
gbdt+lr 混合模型 ,分开 训练 顺序训练(耗时较长)
:param train_file: 训练数据
:param feature_num_file: 特征维度文件
:param mix_tree_model_file: 混合模型树模型部分的文件
:param mix_lr_model_file: 混合模型逻辑回归部分的文件
:return: None
"""
train_feature, train_label = get_train_data(train_file, feature_num_file) # 传入 训练数据 和 特征维度文件
train_mat = xgb.DMatrix(train_feature, train_label) # 将数据结构转化成gbdt所需要的数据结构,因为我们用的xgboost,所以与之前树模型一样
tree_num, tree_depth, learning_rate = 10,6, 0.3 # 上一节已经选出了最优的参数
# (tree_depth, tree_num, learning_rate) = get_mix_model_tree_info()
# 这里树的深度由 6 改为4,原因:如下: 深度为6:总共:127个节点,64个叶子节点,63个非叶子节点
# 1.训练出的label,没有落在叶子节点上(或者落在叶子节点上比较少)
# 2. 特征与样本量的比值:1:100。 因为: 10颗数,深度为6,则叶子节点有 有640个维度,而样本有3万条,不满足
#训练树模型的代码,因为混合模型是分开训练,所以把树模型存储一下save_model
bst = train_tree_model_core(train_mat,tree_depth,tree_num,learning_rate) #此处调用一下训练树的主体函数,分别传入所需参数
bst.save_model(mix_tree_model_file)
# 理论部分已经讲过,lr模型所需特征是通过树模型通过编码得到的,所以只需叶的结点编成离散化特征,先预测一下样本
tree_leaf = bst.predict(train_mat,pred_leaf=True) #预测最终结果落在哪一个叶子节点上
# print(tree_leaf) #[81 84 84 84 85 77 68 91 97 61] 代表10颗数,81代表最终1 落到那一颗叶子节点上
# print(np.max(tree_leaf))
print(tree_leaf[0])
sys.exit()
# 将上边落在哪一个叶子节点上的结果进行加工,最终获取训练lr所需要的特征,定义get_gbdt_and_lr_featrue专门完成特征转化
# 定义get_gbdt_and_lr_featrue专门完成特征转化,因为我们最终看落哪个叶的结点,所以这里的总的结点需要把它转换一下
total_feature_list = get_gbdt_and_lr_feature(tree_leaf,tree_num,tree_depth)
# 逻辑回归(前面课程详细讲过,所以这里就直接复制一下)
# zin模型训练中要注意的参数
# 1.正则化参数,这里支持多种参数进行选择,分别选一下,Cs=[1,10,100],这里边填入数的倒数便是正则化参数即1,0.1,0.01
# 2,penalty="l2",正则化选用l2(L2),之前讲过l1正则化倾向于将特征对应的参数学为0,而这里一共就100多列特征,我们倾向于将这些特征的参数选小而不是学为0
# 3.参数迭代停止的条件tol=0.0001,选为万分之1
# 4.最大迭代次数选择500次
# 5.cv=5,指定几轴交叉验证,意思是将训练数据分为5份,每一次拿出20%作为测试,80%作为训练,一共进行5次
# 最优化方法的选择:坐标轴下降法、牛顿法、梯度下降法(随机梯度下降):为了适应大数据训练,采用了随机梯度下降,我在每带选择一部分,近似整个代的记录,减少计算量提高计算速度
# 我们这里选了penalty="l2",所以只能选牛顿法/梯度下降法(随机梯度下降),这里默认选择牛顿法,因为我们样本不是特别多,我们希望所有样本都参与到训练中
lr_cf = LRCV(Cs=[1],penalty="l2",tol=0.0001,max_iter=500,cv=5).fit(train_feature,train_label)
#需要观察一下训练的结果//视频下边一行为scores = lr_cf.scores_.values()[0],改为源代码中如下两行
scores = lr_cf.scores_.values()
scores = list(scores)[0] # 提取values值
# 得到的scores是个5行3列的数组,所以我们看下每个正则化参数对应的5轴交叉验证之后平均的准确率是多少
print("diff %s : " % (",".join([str(ele) for ele in scores.mean(axis=0)]))) # 按照列求均值
print("Accuracy:%s (+- %0.2f ) "%(scores.mean(),scores.std()*2))
#print("Accuracy:%s " % (scores.mean())) #视频中不是mean(),mean后边没有(),后来又加上了()
# 模型的auc Cs=[1,10,100] #输出一下AUC,在lr_cf里加上scoring='roc_auc'
lr_cf = LRCV(Cs=[1], penalty="l2", tol=0.00001, max_iter=1000, cv=5, scoring='roc_auc').fit(train_feature,train_label)
scores = lr_cf.scores_.values()
scores = list(scores)[0] # 提取values值
#print(scores)
print("diff %s : " % (" ".join([str(ele) for ele in scores.mean(axis=0)]))) # 按照列求均值
print("AUC:%s (+- %0.2f )" % (scores.mean(),scores.std()*2))
#我改成如下,后来没试
# #train_tree_model("gbdt_lr/data/train_file", "gbdt_lr/data/feature_num_file", "")
if __name__ == "__main__":
train_tree_model("data/gbdt_train_file", "data/gbdt_feature_num", "data/test.model")
# 由于我们这里还没有实例化,所以先随便写两个文件
train_tree_and_lr_model("data/gbdt_train_file", "data/gbdt_feature_num", "test","test1")
运行train.py,我的结果如下
D:\develop\Anaconda3\python.exe "D:/develop/PyCharm 2018.3.5_workspace/p_recommendation_myself/gbdt_lr/train.py"
[81 84 84 84 85 77 68 91 97 61]
Process finished with exit code 0
视频课的代码如下
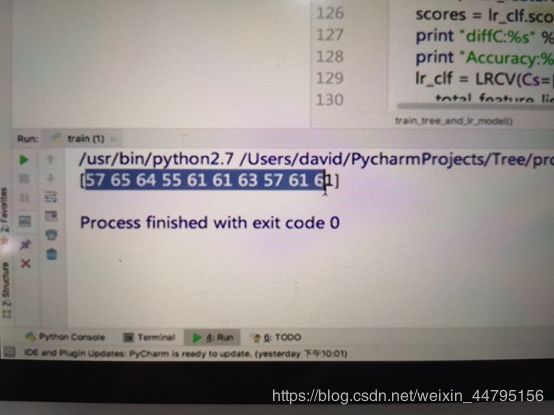
我们看到结果10个元素,代表10棵树每一棵树最终样本输出结果是落在了哪一个节点上
深度为6时,一共有64个叶的节点,63个非叶的节点,我们发现真正的树被训练完全出来的棵树不是很多,所以我们应该不采用6棵树做混合模型,
第2个原因是,如果我们采用6棵树,我们要求每一棵树最终造出的向量是64位,10棵树640位,而我们这里样本30000多条,不符合实战中——至少应该保持特征与样本,1:100的比例这个要求,
所以混合模型我们最终选择4棵树,但是实战中由于样本和特征增多,我们可以相应的对参数进行调整
接下来我们输出一下,最大的索引
train_tree_and_lr_model函数的sys.exit()上边再加一行print(np.max(tree_leaf))
train_tree_and_lr_model函数此时如下
def train_tree_and_lr_model(train_file, feature_num_file, mix_tree_model_file, mix_lr_model_file):
"""
gbdt+lr 混合模型 ,分开 训练 顺序训练(耗时较长)
:param train_file: 训练数据
:param feature_num_file: 特征维度文件
:param mix_tree_model_file: 混合模型树模型部分的文件
:param mix_lr_model_file: 混合模型逻辑回归部分的文件
:return: None
"""
train_feature, train_label = get_train_data(train_file, feature_num_file) # 传入 训练数据 和 特征维度文件
train_mat = xgb.DMatrix(train_feature, train_label) # 将数据结构转化成gbdt所需要的数据结构,因为我们用的xgboost,所以与之前树模型一样
tree_num, tree_depth, learning_rate = 10,6, 0.3 # 上一节已经选出了最优的参数
# (tree_depth, tree_num, learning_rate) = get_mix_model_tree_info()
# 这里树的深度由 6 改为4,原因:如下: 深度为6:总共:127个节点,64个叶子节点,63个非叶子节点
# 1.训练出的label,没有落在叶子节点上(或者落在叶子节点上比较少)
# 2. 特征与样本量的比值:1:100。 因为: 10颗数,深度为6,则叶子节点有 有640个维度,而样本有3万条,不满足
#训练树模型的代码,因为混合模型是分开训练,所以把树模型存储一下save_model
bst = train_tree_model_core(train_mat,tree_depth,tree_num,learning_rate) #此处调用一下训练树的主体函数,分别传入所需参数
bst.save_model(mix_tree_model_file)
# 理论部分已经讲过,lr模型所需特征是通过树模型通过编码得到的,所以只需叶的结点编成离散化特征,先预测一下样本
tree_leaf = bst.predict(train_mat,pred_leaf=True) #预测最终结果落在哪一个叶子节点上
# print(tree_leaf) #[81 84 84 84 85 77 68 91 97 61] 代表10颗数,81代表最终1 落到那一颗叶子节点上
# print(np.max(tree_leaf))
print(tree_leaf[0])
print(np.max(tree_leaf))
sys.exit()
# 将上边落在哪一个叶子节点上的结果进行加工,最终获取训练lr所需要的特征,定义get_gbdt_and_lr_featrue专门完成特征转化
# 定义get_gbdt_and_lr_featrue专门完成特征转化,因为我们最终看落哪个叶的结点,所以这里的总的结点需要把它转换一下
total_feature_list = get_gbdt_and_lr_feature(tree_leaf,tree_num,tree_depth)
# 逻辑回归(前面课程详细讲过,所以这里就直接复制一下)
# zin模型训练中要注意的参数
# 1.正则化参数,这里支持多种参数进行选择,分别选一下,Cs=[1,10,100],这里边填入数的倒数便是正则化参数即1,0.1,0.01
# 2,penalty="l2",正则化选用l2(L2),之前讲过l1正则化倾向于将特征对应的参数学为0,而这里一共就100多列特征,我们倾向于将这些特征的参数选小而不是学为0
# 3.参数迭代停止的条件tol=0.0001,选为万分之1
# 4.最大迭代次数选择500次
# 5.cv=5,指定几轴交叉验证,意思是将训练数据分为5份,每一次拿出20%作为测试,80%作为训练,一共进行5次
# 最优化方法的选择:坐标轴下降法、牛顿法、梯度下降法(随机梯度下降):为了适应大数据训练,采用了随机梯度下降,我在每带选择一部分,近似整个代的记录,减少计算量提高计算速度
# 我们这里选了penalty="l2",所以只能选牛顿法/梯度下降法(随机梯度下降),这里默认选择牛顿法,因为我们样本不是特别多,我们希望所有样本都参与到训练中
lr_cf = LRCV(Cs=[1],penalty="l2",tol=0.0001,max_iter=500,cv=5).fit(train_feature,train_label)
#需要观察一下训练的结果//视频下边一行为scores = lr_cf.scores_.values()[0],改为源代码中如下两行
scores = lr_cf.scores_.values()
scores = list(scores)[0] # 提取values值
# 得到的scores是个5行3列的数组,所以我们看下每个正则化参数对应的5轴交叉验证之后平均的准确率是多少
print("diff %s : " % (",".join([str(ele) for ele in scores.mean(axis=0)]))) # 按照列求均值
print("Accuracy:%s (+- %0.2f ) "%(scores.mean(),scores.std()*2))
#print("Accuracy:%s " % (scores.mean())) #视频中不是mean(),mean后边没有(),后来又加上了()
# 模型的auc Cs=[1,10,100] #输出一下AUC,在lr_cf里加上scoring='roc_auc'
lr_cf = LRCV(Cs=[1], penalty="l2", tol=0.00001, max_iter=1000, cv=5, scoring='roc_auc').fit(train_feature,train_label)
scores = lr_cf.scores_.values()
scores = list(scores)[0] # 提取values值
#print(scores)
print("diff %s : " % (" ".join([str(ele) for ele in scores.mean(axis=0)]))) # 按照列求均值
print("AUC:%s (+- %0.2f )" % (scores.mean(),scores.std()*2))
train.py此时如下
# -*- coding: utf-8 -*-
"""
==================================================
File Name: train
Description : Practical Lessons from Predicting Clicks on Ads at Facebook (2014)论文阅读
==================================================
"""
import xgboost as xgb
#import utils
import numpy as np # np读入文件
from sklearn.linear_model import LogisticRegressionCV as LRCV
from scipy.sparse import coo_matrix
import sys
#sys.path.append("../util")
sys.path.append("../..")
import p_recommendation_myself.gbdt_lr.util.get_feature_num as GF
#from p_recommendation_myself.gbdt_lr.util.get_feature_num import get_feature_num as GF
#from p_recommendation_myself.gbdt_lr.util.get_feature_num import get_feature_num as GF
#from p_recommendation_myself.gbdt_lr.util.utils import get_feature_num as GF
# zin 01
def get_train_data(train_file, feature_num_file):
"""获得训练数据 label和特征"""
total_feature_num = GF.get_feature_num(feature_num_file)
train_label = np.genfromtxt(train_file, dtype=np.int32, delimiter=",", usecols=-1) # label最后1列,label
feature_list = range(0, total_feature_num)
train_feature = np.genfromtxt(train_file, dtype=np.int32, delimiter=",", usecols=feature_list)
return train_feature, train_label
def train_tree_model_core(train_mat, tree_depth, tree_num, learning_rate):
"""
:param train_mat: 训练数据和label
:param tree_depth: 树的深度
:param tree_num:树的数量
:param learning_rate: 学习率
:return:Booster
"""
para_dict = {"max_depth": tree_depth, "eta": learning_rate, "objective": "reg:linear", "silent": 1}
bst = xgb.train(params=para_dict, dtrain=train_mat, num_boost_round=tree_num) #para_dict为几个参数组成的字典
# 交叉验证
#print(xgb.cv(params=para_dict, dtrain=train_mat, num_boost_round=tree_num, nfold=5, metrics={"auc"}))
return bst
#9-6
def choose_parameter():
"""生成参数
zin:list是元组,分别是树深度,树数目,步长;
这3个参数列表中的数目也可以增加,当然耗时也就会增加了
比如tree_depth_list = [4,5,6]可以为tree_depth_list = [4,5,6,7,8,9...]
"""
result_list = [] # 定义输出列表
tree_depth_list = [4,5,6] # [4,5,6]
tree_num_list = [10,50,100] # [10,50,100]
learning_rate_list = [0.3,0.5,0.7] # [0.3,,]
for ele_tree_depth in tree_depth_list:
for ele_tree_num in tree_num_list:
for ele_learning_rate in learning_rate_list:
result_list.append((ele_tree_depth, ele_tree_num, ele_learning_rate)) # 将结果以元组形式装载,注意顺序:深度,数目,步长
return result_list # 将最终结果返回
# 9-6
def grid_search(train_mat):
"""网格搜索参数"""
para_list = choose_parameter() # 定义一个构建参数的函数
for ele in para_list:
(tree_depth, tree_num, learning_rate) = ele # 元组包括这3个参数
para_dict = {"max_depth": tree_depth, "eta": learning_rate, "objective": "reg:linear", "silent": 1}
res = xgb.cv(params=para_dict, dtrain=train_mat, num_boost_round=tree_num, nfold=5, metrics={"auc"})
# 上一次课是10棵树,有10行,所以我们应该选最后一行结果,行号为树的总的数目,列为test-auc-mean,用values[0]把值获取出来
auc_score = res.loc[tree_num - 1, ["test-auc-mean"]].values[0] # 获取最后一棵树的得分就行了。
# 输出一下每一组参数和auc得分,把对应值tree_depth, tree_num, learning_rate, auc_score填进去,太长了,换下行
print("tree depth: %s , tree_num: %s , learning_rate: %s , auc: %f" % (
tree_depth, tree_num, learning_rate, auc_score))
# zin 9-5 T2-1-1 三个参数(筛选好的特征及样本文件,记录特征维度的文件,模型的存储文件)
def train_tree_model(train_file, feature_num_file, tree_model_file):
"""
训练树模型
"""
train_feature, train_label = get_train_data(train_file, feature_num_file)
train_mat = xgb.DMatrix(train_feature, train_label) # xgboost 需要的结构需要此类包装,训练的数据以及label
#grid_search(train_mat) # 参数选择,选择一次,就行,后面就无需继续使用了。,9.6刚开始未注释这行,运行后得到了最优参数后,便可以不再参数选择了,所以之后注释掉了这行
#sys.exit()
tree_num = 10
tree_depth = 6
learning_rate = 0.3 # 步长fm=fm-1+step_size*Tm
bst = train_tree_model_core(train_mat, tree_depth, tree_num, learning_rate) # 3个参数,训练的数据以及label,深度,数量,步长
#
bst.save_model(tree_model_file) # 将模型实例化输出,之后也就不需要再进行交叉验证参数选择了
#9-7
def get_gbdt_and_lr_feature(tree_leaf,tree_num,tree_depth):
"""
提取特征的代码
:param tree_leaf: predict of tree model
:param tree_num: total_num
:param tree_depth:
:return: 返回稀疏矩阵: 因为树的深度越深,叶子节点就越多,再加上树很多。那叶子节点就更稀疏
"""
total_node_num = 2**(tree_depth +1) -1
leaf_num = 2**tree_depth
not_leaf_num = total_node_num - leaf_num
total_col_num = leaf_num * tree_num # 总叶子节点数,总维度
total_row_num = len(tree_leaf) # 多少样本
col=[]
row= []
data = []
# base_row_index = 0
# for one_result in tree_leaf:
# base_col_index = 0
# for fix_index in one_result:
# leaf_index = fix_index - not_leaf_num
# leaf_index = leaf_index if leaf_index >=0 else 0
# col.append(base_col_index +leaf_index)
# row.append(base_row_index)
# data.append(1)
# base_col_index += leaf_num # zin-在基础列索引之上加上叶子数目
# base_row_index +=1
# total_feature_list = coo_matrix((data,(row,col)),shape=(total_row_num,total_col_num)) # 转化为稀疏矩阵形式
#
# return total_feature_list
#9-7
def train_tree_and_lr_model(train_file, feature_num_file, mix_tree_model_file, mix_lr_model_file):
"""
gbdt+lr 混合模型 ,分开 训练 顺序训练(耗时较长)
:param train_file: 训练数据
:param feature_num_file: 特征维度文件
:param mix_tree_model_file: 混合模型树模型部分的文件
:param mix_lr_model_file: 混合模型逻辑回归部分的文件
:return: None
"""
train_feature, train_label = get_train_data(train_file, feature_num_file) # 传入 训练数据 和 特征维度文件
train_mat = xgb.DMatrix(train_feature, train_label) # 将数据结构转化成gbdt所需要的数据结构,因为我们用的xgboost,所以与之前树模型一样
tree_num, tree_depth, learning_rate = 10,6, 0.3 # 上一节已经选出了最优的参数
# (tree_depth, tree_num, learning_rate) = get_mix_model_tree_info()
# 这里树的深度由 6 改为4,原因:如下: 深度为6:总共:127个节点,64个叶子节点,63个非叶子节点
# 1.训练出的label,没有落在叶子节点上(或者落在叶子节点上比较少)
# 2. 特征与样本量的比值:1:100。 因为: 10颗数,深度为6,则叶子节点有 有640个维度,而样本有3万条,不满足
#训练树模型的代码,因为混合模型是分开训练,所以把树模型存储一下save_model
bst = train_tree_model_core(train_mat,tree_depth,tree_num,learning_rate) #此处调用一下训练树的主体函数,分别传入所需参数
bst.save_model(mix_tree_model_file)
# 理论部分已经讲过,lr模型所需特征是通过树模型通过编码得到的,所以只需叶的结点编成离散化特征,先预测一下样本
tree_leaf = bst.predict(train_mat,pred_leaf=True) #预测最终结果落在哪一个叶子节点上
# print(tree_leaf) #[81 84 84 84 85 77 68 91 97 61] 代表10颗数,81代表最终1 落到那一颗叶子节点上
# print(np.max(tree_leaf))
print(tree_leaf[0])
print(np.max(tree_leaf))
sys.exit()
# 将上边落在哪一个叶子节点上的结果进行加工,最终获取训练lr所需要的特征,定义get_gbdt_and_lr_featrue专门完成特征转化
# 定义get_gbdt_and_lr_featrue专门完成特征转化,因为我们最终看落哪个叶的结点,所以这里的总的结点需要把它转换一下
total_feature_list = get_gbdt_and_lr_feature(tree_leaf,tree_num,tree_depth)
# 逻辑回归(前面课程详细讲过,所以这里就直接复制一下)
# zin模型训练中要注意的参数
# 1.正则化参数,这里支持多种参数进行选择,分别选一下,Cs=[1,10,100],这里边填入数的倒数便是正则化参数即1,0.1,0.01
# 2,penalty="l2",正则化选用l2(L2),之前讲过l1正则化倾向于将特征对应的参数学为0,而这里一共就100多列特征,我们倾向于将这些特征的参数选小而不是学为0
# 3.参数迭代停止的条件tol=0.0001,选为万分之1
# 4.最大迭代次数选择500次
# 5.cv=5,指定几轴交叉验证,意思是将训练数据分为5份,每一次拿出20%作为测试,80%作为训练,一共进行5次
# 最优化方法的选择:坐标轴下降法、牛顿法、梯度下降法(随机梯度下降):为了适应大数据训练,采用了随机梯度下降,我在每带选择一部分,近似整个代的记录,减少计算量提高计算速度
# 我们这里选了penalty="l2",所以只能选牛顿法/梯度下降法(随机梯度下降),这里默认选择牛顿法,因为我们样本不是特别多,我们希望所有样本都参与到训练中
lr_cf = LRCV(Cs=[1],penalty="l2",tol=0.0001,max_iter=500,cv=5).fit(train_feature,train_label)
#需要观察一下训练的结果//视频下边一行为scores = lr_cf.scores_.values()[0],改为源代码中如下两行
scores = lr_cf.scores_.values()
scores = list(scores)[0] # 提取values值
# 得到的scores是个5行3列的数组,所以我们看下每个正则化参数对应的5轴交叉验证之后平均的准确率是多少
print("diff %s : " % (",".join([str(ele) for ele in scores.mean(axis=0)]))) # 按照列求均值
print("Accuracy:%s (+- %0.2f ) "%(scores.mean(),scores.std()*2))
#print("Accuracy:%s " % (scores.mean())) #视频中不是mean(),mean后边没有(),后来又加上了()
# 模型的auc Cs=[1,10,100] #输出一下AUC,在lr_cf里加上scoring='roc_auc'
lr_cf = LRCV(Cs=[1], penalty="l2", tol=0.00001, max_iter=1000, cv=5, scoring='roc_auc').fit(train_feature,train_label)
scores = lr_cf.scores_.values()
scores = list(scores)[0] # 提取values值
#print(scores)
print("diff %s : " % (" ".join([str(ele) for ele in scores.mean(axis=0)]))) # 按照列求均值
print("AUC:%s (+- %0.2f )" % (scores.mean(),scores.std()*2))
#我改成如下,后来没试
# #train_tree_model("gbdt_lr/data/train_file", "gbdt_lr/data/feature_num_file", "")
if __name__ == "__main__":
train_tree_model("data/gbdt_train_file", "data/gbdt_feature_num", "data/test.model")
# 由于我们这里还没有实例化,所以先随便写两个文件
train_tree_and_lr_model("data/gbdt_train_file", "data/gbdt_feature_num", "test","test1")
运行一下train.py
我的运行结果如下
D:\develop\Anaconda3\python.exe "D:/develop/PyCharm 2018.3.5_workspace/p_recommendation_myself/gbdt_lr/train.py"
[81 84 84 84 85 77 68 91 97 61]
122
Process finished with exit code 0
视频课运行结果如下
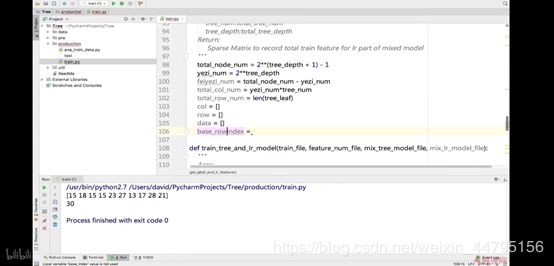
视频讲解为:深度为4,非叶的节点为15,看到输出的一般都落在了第16个节点之后;最大索引是30,又因为一共有31个节点,输出结果的第2行是30,就是说明这里的节点是从0开始计数的,所以输出的第一行的15就是第16个节点,也就是叶的节点的第1个节点
接下来完善get_gbdt_and_lr_feature
# 刚才输出的[15 18 15 15 23 27 13 17 28 21]
# 第1行的第1个数表示,预测的结果占据的是0-15位,第2棵树表示占据的是16-31位,以此类推
col.append(base_col_index +leaf_index) # 稀疏矩阵开始填数字,所以把基础序列base_col_index加上
完善好的get_gbdt_and_lr_feature此时如下
def get_gbdt_and_lr_feature(tree_leaf,tree_num,tree_depth):
"""
提取特征的代码
:param tree_leaf: predict of tree model
:param tree_num: total_num
:param tree_depth:
:return: 返回稀疏矩阵: 因为树的深度越深,叶子节点就越多,再加上树很多。那叶子节点就更稀疏
"""
total_node_num = 2**(tree_depth +1) -1
leaf_num = 2**tree_depth
not_leaf_num = total_node_num - leaf_num
total_col_num = leaf_num * tree_num # 总叶子节点数,总维度
total_row_num = len(tree_leaf) # 多少样本
col=[]
row= []
data = []
base_row_index = 0 # 总的行号
for one_result in tree_leaf: # 每个结点对应特征的列的序号
base_col_index = 0
for fix_index in one_result: # fix_index为获取的每一个数字
leaf_index = fix_index - not_leaf_num #最终转化为叶子结点,视频里leaf用的yezi
leaf_index = leaf_index if leaf_index >=0 else 0 # 为防止有一些树学习的不完全我们这里判断一下,叶子树不应该小于0
# 刚才输出的[15 18 15 15 23 27 13 17 28 21]
# 第1行的第1个数表示,预测的结果占据的是0-15位,第2棵树表示占据的是16-31位,以此类推
col.append(base_col_index +leaf_index) # 稀疏矩阵开始填数字,把基础序列base_col_index加上
row.append(base_row_index) #同样,有行索引
data.append(1) #数据在该位置是1
base_col_index += leaf_num # zin-对于第2棵树预测结果,我们在基础列索引之上加上叶子数目
base_row_index +=1 #同样,每一个样本都需要更新一下行索引
total_feature_list = coo_matrix((data,(row,col)),shape=(total_row_num,total_col_num)) # 最终结果转化为稀疏矩阵形式
return total_feature_list
把上一版的train_tree_and_lr_model中的
print(tree_leaf[0])
print(np.max(tree_leaf))
sys.exit()
删掉
此时train_tree_and_lr_model为如下
def train_tree_and_lr_model(train_file, feature_num_file, mix_tree_model_file, mix_lr_model_file):
"""
gbdt+lr 混合模型 ,分开 训练 顺序训练(耗时较长)
:param train_file: 训练数据
:param feature_num_file: 特征维度文件
:param mix_tree_model_file: 混合模型树模型部分的文件
:param mix_lr_model_file: 混合模型逻辑回归部分的文件
:return: None
"""
train_feature, train_label = get_train_data(train_file, feature_num_file) # 传入 训练数据 和 特征维度文件
train_mat = xgb.DMatrix(train_feature, train_label) # 将数据结构转化成gbdt所需要的数据结构,因为我们用的xgboost,所以与之前树模型一样
tree_num, tree_depth, learning_rate = 10,6, 0.3 # 上一节已经选出了最优的参数
# (tree_depth, tree_num, learning_rate) = get_mix_model_tree_info()
# 这里树的深度由 6 改为4,原因:如下: 深度为6:总共:127个节点,64个叶子节点,63个非叶子节点
# 1.训练出的label,没有落在叶子节点上(或者落在叶子节点上比较少)
# 2. 特征与样本量的比值:1:100。 因为: 10颗数,深度为6,则叶子节点有 有640个维度,而样本有3万条,不满足
#训练树模型的代码,因为混合模型是分开训练,所以把树模型存储一下save_model
bst = train_tree_model_core(train_mat,tree_depth,tree_num,learning_rate) #此处调用一下训练树的主体函数,分别传入所需参数
bst.save_model(mix_tree_model_file)
# 理论部分已经讲过,lr模型所需特征是通过树模型通过编码得到的,所以只需叶的结点编成离散化特征,先预测一下样本
tree_leaf = bst.predict(train_mat,pred_leaf=True) #预测最终结果落在哪一个叶子节点上
# print(tree_leaf) #[81 84 84 84 85 77 68 91 97 61] 代表10颗数,81代表最终1 落到那一颗叶子节点上
# print(np.max(tree_leaf))
print(tree_leaf[0])
print(np.max(tree_leaf))
sys.exit()
# 将上边落在哪一个叶子节点上的结果进行加工,最终获取训练lr所需要的特征,定义get_gbdt_and_lr_featrue专门完成特征转化
# 定义get_gbdt_and_lr_featrue专门完成特征转化,因为我们最终看落哪个叶的结点,所以这里的总的结点需要把它转换一下
total_feature_list = get_gbdt_and_lr_feature(tree_leaf,tree_num,tree_depth)
# 逻辑回归(前面课程详细讲过,所以这里就直接复制一下)
# zin模型训练中要注意的参数
# 1.正则化参数,这里支持多种参数进行选择,分别选一下,Cs=[1,10,100],这里边填入数的倒数便是正则化参数即1,0.1,0.01
# 2,penalty="l2",正则化选用l2(L2),之前讲过l1正则化倾向于将特征对应的参数学为0,而这里一共就100多列特征,我们倾向于将这些特征的参数选小而不是学为0
# 3.参数迭代停止的条件tol=0.0001,选为万分之1
# 4.最大迭代次数选择500次
# 5.cv=5,指定几轴交叉验证,意思是将训练数据分为5份,每一次拿出20%作为测试,80%作为训练,一共进行5次
# 最优化方法的选择:坐标轴下降法、牛顿法、梯度下降法(随机梯度下降):为了适应大数据训练,采用了随机梯度下降,我在每带选择一部分,近似整个代的记录,减少计算量提高计算速度
# 我们这里选了penalty="l2",所以只能选牛顿法/梯度下降法(随机梯度下降),这里默认选择牛顿法,因为我们样本不是特别多,我们希望所有样本都参与到训练中
lr_cf = LRCV(Cs=[1],penalty="l2",tol=0.0001,max_iter=500,cv=5).fit(train_feature,train_label)
#需要观察一下训练的结果//视频下边一行为scores = lr_cf.scores_.values()[0],改为源代码中如下两行
scores = lr_cf.scores_.values()
scores = list(scores)[0] # 提取values值
# 得到的scores是个5行3列的数组,所以我们看下每个正则化参数对应的5轴交叉验证之后平均的准确率是多少
print("diff %s : " % (",".join([str(ele) for ele in scores.mean(axis=0)]))) # 按照列求均值
print("Accuracy:%s (+- %0.2f ) "%(scores.mean(),scores.std()*2))
#print("Accuracy:%s " % (scores.mean())) #视频中不是mean(),mean后边没有(),后来又加上了()
# 模型的auc Cs=[1,10,100] #输出一下AUC,在lr_cf里加上scoring='roc_auc'
lr_cf = LRCV(Cs=[1], penalty="l2", tol=0.00001, max_iter=1000, cv=5, scoring='roc_auc').fit(train_feature,train_label)
scores = lr_cf.scores_.values()
scores = list(scores)[0] # 提取values值
#print(scores)
print("diff %s : " % (" ".join([str(ele) for ele in scores.mean(axis=0)]))) # 按照列求均值
print("AUC:%s (+- %0.2f )" % (scores.mean(),scores.std()*2))
此时train.py如下
# -*- coding: utf-8 -*-
"""
==================================================
File Name: train
Description : Practical Lessons from Predicting Clicks on Ads at Facebook (2014)论文阅读
==================================================
"""
import xgboost as xgb
#import utils
import numpy as np # np读入文件
from sklearn.linear_model import LogisticRegressionCV as LRCV
from scipy.sparse import coo_matrix
import sys
#sys.path.append("../util")
sys.path.append("../..")
import p_recommendation_myself.gbdt_lr.util.get_feature_num as GF
#from p_recommendation_myself.gbdt_lr.util.get_feature_num import get_feature_num as GF
#from p_recommendation_myself.gbdt_lr.util.get_feature_num import get_feature_num as GF
#from p_recommendation_myself.gbdt_lr.util.utils import get_feature_num as GF
# zin 01
def get_train_data(train_file, feature_num_file):
"""获得训练数据 label和特征"""
total_feature_num = GF.get_feature_num(feature_num_file)
train_label = np.genfromtxt(train_file, dtype=np.int32, delimiter=",", usecols=-1) # label最后1列,label
feature_list = range(0, total_feature_num)
train_feature = np.genfromtxt(train_file, dtype=np.int32, delimiter=",", usecols=feature_list)
return train_feature, train_label
def train_tree_model_core(train_mat, tree_depth, tree_num, learning_rate):
"""
:param train_mat: 训练数据和label
:param tree_depth: 树的深度
:param tree_num:树的数量
:param learning_rate: 学习率
:return:Booster
"""
para_dict = {"max_depth": tree_depth, "eta": learning_rate, "objective": "reg:linear", "silent": 1}
bst = xgb.train(params=para_dict, dtrain=train_mat, num_boost_round=tree_num) #para_dict为几个参数组成的字典
# 交叉验证
#print(xgb.cv(params=para_dict, dtrain=train_mat, num_boost_round=tree_num, nfold=5, metrics={"auc"}))
return bst
#9-6
def choose_parameter():
"""生成参数
zin:list是元组,分别是树深度,树数目,步长;
这3个参数列表中的数目也可以增加,当然耗时也就会增加了
比如tree_depth_list = [4,5,6]可以为tree_depth_list = [4,5,6,7,8,9...]
"""
result_list = [] # 定义输出列表
tree_depth_list = [4,5,6] # [4,5,6]
tree_num_list = [10,50,100] # [10,50,100]
learning_rate_list = [0.3,0.5,0.7] # [0.3,,]
for ele_tree_depth in tree_depth_list:
for ele_tree_num in tree_num_list:
for ele_learning_rate in learning_rate_list:
result_list.append((ele_tree_depth, ele_tree_num, ele_learning_rate)) # 将结果以元组形式装载,注意顺序:深度,数目,步长
return result_list # 将最终结果返回
# 9-6
def grid_search(train_mat):
"""网格搜索参数"""
para_list = choose_parameter() # 定义一个构建参数的函数
for ele in para_list:
(tree_depth, tree_num, learning_rate) = ele # 元组包括这3个参数
para_dict = {"max_depth": tree_depth, "eta": learning_rate, "objective": "reg:linear", "silent": 1}
res = xgb.cv(params=para_dict, dtrain=train_mat, num_boost_round=tree_num, nfold=5, metrics={"auc"})
# 上一次课是10棵树,有10行,所以我们应该选最后一行结果,行号为树的总的数目,列为test-auc-mean,用values[0]把值获取出来
auc_score = res.loc[tree_num - 1, ["test-auc-mean"]].values[0] # 获取最后一棵树的得分就行了。
# 输出一下每一组参数和auc得分,把对应值tree_depth, tree_num, learning_rate, auc_score填进去,太长了,换下行
print("tree depth: %s , tree_num: %s , learning_rate: %s , auc: %f" % (
tree_depth, tree_num, learning_rate, auc_score))
# zin 9-5 T2-1-1 三个参数(筛选好的特征及样本文件,记录特征维度的文件,模型的存储文件)
def train_tree_model(train_file, feature_num_file, tree_model_file):
"""
训练树模型
"""
train_feature, train_label = get_train_data(train_file, feature_num_file)
train_mat = xgb.DMatrix(train_feature, train_label) # xgboost 需要的结构需要此类包装,训练的数据以及label
#grid_search(train_mat) # 参数选择,选择一次,就行,后面就无需继续使用了。,9.6刚开始未注释这行,运行后得到了最优参数后,便可以不再参数选择了,所以之后注释掉了这行
#sys.exit()
tree_num = 10
tree_depth = 6
learning_rate = 0.3 # 步长fm=fm-1+step_size*Tm
bst = train_tree_model_core(train_mat, tree_depth, tree_num, learning_rate) # 3个参数,训练的数据以及label,深度,数量,步长
#
bst.save_model(tree_model_file) # 将模型实例化输出,之后也就不需要再进行交叉验证参数选择了
#9-7
def get_gbdt_and_lr_feature(tree_leaf,tree_num,tree_depth):
"""
提取特征的代码
:param tree_leaf: predict of tree model
:param tree_num: total_num
:param tree_depth:
:return: 返回稀疏矩阵: 因为树的深度越深,叶子节点就越多,再加上树很多。那叶子节点就更稀疏
"""
total_node_num = 2**(tree_depth +1) -1
leaf_num = 2**tree_depth
not_leaf_num = total_node_num - leaf_num
total_col_num = leaf_num * tree_num # 总叶子节点数,总维度
total_row_num = len(tree_leaf) # 多少样本
col=[]
row= []
data = []
base_row_index = 0 # 总的行号
for one_result in tree_leaf: # 每个结点对应特征的列的序号
base_col_index = 0
for fix_index in one_result: # fix_index为获取的每一个数字
leaf_index = fix_index - not_leaf_num #最终转化为叶子结点,视频里leaf用的yezi
leaf_index = leaf_index if leaf_index >=0 else 0 # 为防止有一些树学习的不完全我们这里判断一下,叶子树不应该小于0
# 刚才输出的[15 18 15 15 23 27 13 17 28 21]
# 第1行的第1个数表示,预测的结果占据的是0-15位,第2棵树表示占据的是16-31位,以此类推
col.append(base_col_index +leaf_index) # 稀疏矩阵开始填数字,基础序列base_col_index加上
row.append(base_row_index) #同样,有行索引
data.append(1) #数据在该位置是1
base_col_index += leaf_num # zin-对于第2棵树预测结果,我们在基础列索引之上加上叶子数目
base_row_index +=1 #同样,每一个样本都需要更新一下行索引
total_feature_list = coo_matrix((data,(row,col)),shape=(total_row_num,total_col_num)) # 最终结果转化为稀疏矩阵形式
return total_feature_list
#9-7
def train_tree_and_lr_model(train_file, feature_num_file, mix_tree_model_file, mix_lr_model_file):
"""
gbdt+lr 混合模型 ,分开 训练 顺序训练(耗时较长)
:param train_file: 训练数据
:param feature_num_file: 特征维度文件
:param mix_tree_model_file: 混合模型树模型部分的文件
:param mix_lr_model_file: 混合模型逻辑回归部分的文件
:return: None
"""
train_feature, train_label = get_train_data(train_file, feature_num_file) # 传入 训练数据 和 特征维度文件
train_mat = xgb.DMatrix(train_feature, train_label) # 将数据结构转化成gbdt所需要的数据结构,因为我们用的xgboost,所以与之前树模型一样
tree_num, tree_depth, learning_rate = 10,6, 0.3 # 上一节已经选出了最优的参数
# (tree_depth, tree_num, learning_rate) = get_mix_model_tree_info()
# 这里树的深度由 6 改为4,原因:如下: 深度为6:总共:127个节点,64个叶子节点,63个非叶子节点
# 1.训练出的label,没有落在叶子节点上(或者落在叶子节点上比较少)
# 2. 特征与样本量的比值:1:100。 因为: 10颗数,深度为6,则叶子节点有 有640个维度,而样本有3万条,不满足
#训练树模型的代码,因为混合模型是分开训练,所以把树模型存储一下save_model
bst = train_tree_model_core(train_mat,tree_depth,tree_num,learning_rate) #此处调用一下训练树的主体函数,分别传入所需参数
bst.save_model(mix_tree_model_file)
# 理论部分已经讲过,lr模型所需特征是通过树模型通过编码得到的,所以只需叶的结点编成离散化特征,先预测一下样本
tree_leaf = bst.predict(train_mat,pred_leaf=True) #预测最终结果落在哪一个叶子节点上
# print(tree_leaf) #[81 84 84 84 85 77 68 91 97 61] 代表10颗数,81代表最终1 落到那一颗叶子节点上
# print(np.max(tree_leaf))
print(tree_leaf[0])
print(np.max(tree_leaf))
sys.exit()
# 将上边落在哪一个叶子节点上的结果进行加工,最终获取训练lr所需要的特征,定义get_gbdt_and_lr_featrue专门完成特征转化
# 定义get_gbdt_and_lr_featrue专门完成特征转化,因为我们最终看落哪个叶的结点,所以这里的总的结点需要把它转换一下
total_feature_list = get_gbdt_and_lr_feature(tree_leaf,tree_num,tree_depth)
# 逻辑回归(前面课程详细讲过,所以这里就直接复制一下)
# zin模型训练中要注意的参数
# 1.正则化参数,这里支持多种参数进行选择,分别选一下,Cs=[1,10,100],这里边填入数的倒数便是正则化参数即1,0.1,0.01
# 2,penalty="l2",正则化选用l2(L2),之前讲过l1正则化倾向于将特征对应的参数学为0,而这里一共就100多列特征,我们倾向于将这些特征的参数选小而不是学为0
# 3.参数迭代停止的条件tol=0.0001,选为万分之1
# 4.最大迭代次数选择500次
# 5.cv=5,指定几轴交叉验证,意思是将训练数据分为5份,每一次拿出20%作为测试,80%作为训练,一共进行5次
# 最优化方法的选择:坐标轴下降法、牛顿法、梯度下降法(随机梯度下降):为了适应大数据训练,采用了随机梯度下降,我在每带选择一部分,近似整个代的记录,减少计算量提高计算速度
# 我们这里选了penalty="l2",所以只能选牛顿法/梯度下降法(随机梯度下降),这里默认选择牛顿法,因为我们样本不是特别多,我们希望所有样本都参与到训练中
lr_cf = LRCV(Cs=[1],penalty="l2",tol=0.0001,max_iter=500,cv=5).fit(train_feature,train_label)
#需要观察一下训练的结果//视频下边一行为scores = lr_cf.scores_.values()[0],改为源代码中如下两行
scores = lr_cf.scores_.values()
scores = list(scores)[0] # 提取values值
# 得到的scores是个5行3列的数组,所以我们看下每个正则化参数对应的5轴交叉验证之后平均的准确率是多少
print("diff %s : " % (",".join([str(ele) for ele in scores.mean(axis=0)]))) # 按照列求均值
print("Accuracy:%s (+- %0.2f ) "%(scores.mean(),scores.std()*2))
#print("Accuracy:%s " % (scores.mean())) #视频中不是mean(),mean后边没有(),后来又加上了()
# 模型的auc Cs=[1,10,100] #输出一下AUC,在lr_cf里加上scoring='roc_auc'
lr_cf = LRCV(Cs=[1], penalty="l2", tol=0.00001, max_iter=1000, cv=5, scoring='roc_auc').fit(train_feature,train_label)
scores = lr_cf.scores_.values()
scores = list(scores)[0] # 提取values值
#print(scores)
print("diff %s : " % (" ".join([str(ele) for ele in scores.mean(axis=0)]))) # 按照列求均值
print("AUC:%s (+- %0.2f )" % (scores.mean(),scores.std()*2))
#我改成如下,后来没试
# #train_tree_model("gbdt_lr/data/train_file", "gbdt_lr/data/feature_num_file", "")
if __name__ == "__main__":
train_tree_model("data/gbdt_train_file", "data/gbdt_feature_num", "data/test.model")
# 由于我们这里还没有实例化,所以先随便写两个文件
train_tree_and_lr_model("data/gbdt_train_file", "data/gbdt_feature_num", "test","test1")
我咋没运行出来呢??咋还是下边这个东东??
D:\develop\Anaconda3\python.exe "D:/develop/PyCharm 2018.3.5_workspace/p_recommendation_myself/gbdt_lr/train.py"
[81 84 84 84 85 77 68 91 97 61]
122
Process finished with exit code 0
噢,我发现视频中把train_tree_and_lr_model函数中如下部分注销掉了,
# print(tree_leaf[0])
# print(np.max(tree_leaf))
# sys.exit()
此时train.py为如下
# -*- coding: utf-8 -*-
"""
==================================================
File Name: train
Description : Practical Lessons from Predicting Clicks on Ads at Facebook (2014)论文阅读
==================================================
"""
import xgboost as xgb
#import utils
import numpy as np # np读入文件
from sklearn.linear_model import LogisticRegressionCV as LRCV
from scipy.sparse import coo_matrix
import sys
#sys.path.append("../util")
sys.path.append("../..")
import p_recommendation_myself.gbdt_lr.util.get_feature_num as GF
#from p_recommendation_myself.gbdt_lr.util.get_feature_num import get_feature_num as GF
#from p_recommendation_myself.gbdt_lr.util.get_feature_num import get_feature_num as GF
#from p_recommendation_myself.gbdt_lr.util.utils import get_feature_num as GF
# zin 01
def get_train_data(train_file, feature_num_file):
"""获得训练数据 label和特征"""
total_feature_num = GF.get_feature_num(feature_num_file)
train_label = np.genfromtxt(train_file, dtype=np.int32, delimiter=",", usecols=-1) # label最后1列,label
feature_list = range(0, total_feature_num)
train_feature = np.genfromtxt(train_file, dtype=np.int32, delimiter=",", usecols=feature_list)
return train_feature, train_label
def train_tree_model_core(train_mat, tree_depth, tree_num, learning_rate):
"""
:param train_mat: 训练数据和label
:param tree_depth: 树的深度
:param tree_num:树的数量
:param learning_rate: 学习率
:return:Booster
"""
para_dict = {"max_depth": tree_depth, "eta": learning_rate, "objective": "reg:linear", "silent": 1}
bst = xgb.train(params=para_dict, dtrain=train_mat, num_boost_round=tree_num) #para_dict为几个参数组成的字典
# 交叉验证
#print(xgb.cv(params=para_dict, dtrain=train_mat, num_boost_round=tree_num, nfold=5, metrics={"auc"}))
return bst
#9-6
def choose_parameter():
"""生成参数
zin:list是元组,分别是树深度,树数目,步长;
这3个参数列表中的数目也可以增加,当然耗时也就会增加了
比如tree_depth_list = [4,5,6]可以为tree_depth_list = [4,5,6,7,8,9...]
"""
result_list = [] # 定义输出列表
tree_depth_list = [4,5,6] # [4,5,6]
tree_num_list = [10,50,100] # [10,50,100]
learning_rate_list = [0.3,0.5,0.7] # [0.3,,]
for ele_tree_depth in tree_depth_list:
for ele_tree_num in tree_num_list:
for ele_learning_rate in learning_rate_list:
result_list.append((ele_tree_depth, ele_tree_num, ele_learning_rate)) # 将结果以元组形式装载,注意顺序:深度,数目,步长
return result_list # 将最终结果返回
# 9-6
def grid_search(train_mat):
"""网格搜索参数"""
para_list = choose_parameter() # 定义一个构建参数的函数
for ele in para_list:
(tree_depth, tree_num, learning_rate) = ele # 元组包括这3个参数
para_dict = {"max_depth": tree_depth, "eta": learning_rate, "objective": "reg:linear", "silent": 1}
res = xgb.cv(params=para_dict, dtrain=train_mat, num_boost_round=tree_num, nfold=5, metrics={"auc"})
# 上一次课是10棵树,有10行,所以我们应该选最后一行结果,行号为树的总的数目,列为test-auc-mean,用values[0]把值获取出来
auc_score = res.loc[tree_num - 1, ["test-auc-mean"]].values[0] # 获取最后一棵树的得分就行了。
# 输出一下每一组参数和auc得分,把对应值tree_depth, tree_num, learning_rate, auc_score填进去,太长了,换下行
print("tree depth: %s , tree_num: %s , learning_rate: %s , auc: %f" % (
tree_depth, tree_num, learning_rate, auc_score))
# zin 9-5 T2-1-1 三个参数(筛选好的特征及样本文件,记录特征维度的文件,模型的存储文件)
def train_tree_model(train_file, feature_num_file, tree_model_file):
"""
训练树模型
"""
train_feature, train_label = get_train_data(train_file, feature_num_file)
train_mat = xgb.DMatrix(train_feature, train_label) # xgboost 需要的结构需要此类包装,训练的数据以及label
#grid_search(train_mat) # 参数选择,选择一次,就行,后面就无需继续使用了。,9.6刚开始未注释这行,运行后得到了最优参数后,便可以不再参数选择了,所以之后注释掉了这行
#sys.exit()
tree_num = 10
tree_depth = 6
learning_rate = 0.3 # 步长fm=fm-1+step_size*Tm
bst = train_tree_model_core(train_mat, tree_depth, tree_num, learning_rate) # 3个参数,训练的数据以及label,深度,数量,步长
#
bst.save_model(tree_model_file) # 将模型实例化输出,之后也就不需要再进行交叉验证参数选择了
#9-7
def get_gbdt_and_lr_feature(tree_leaf,tree_num,tree_depth):
"""
提取特征的代码
:param tree_leaf: predict of tree model
:param tree_num: total_num
:param tree_depth:
:return: 返回稀疏矩阵: 因为树的深度越深,叶子节点就越多,再加上树很多。那叶子节点就更稀疏
"""
total_node_num = 2**(tree_depth +1) -1
leaf_num = 2**tree_depth
not_leaf_num = total_node_num - leaf_num
total_col_num = leaf_num * tree_num # 总叶子节点数,总维度
total_row_num = len(tree_leaf) # 多少样本
col=[]
row= []
data = []
base_row_index = 0 # 总的行号
for one_result in tree_leaf: # 每个结点对应特征的列的序号
base_col_index = 0
for fix_index in one_result: # fix_index为获取的每一个数字
leaf_index = fix_index - not_leaf_num #最终转化为叶子结点,视频里leaf用的yezi
leaf_index = leaf_index if leaf_index >=0 else 0 # 为防止有一些树学习的不完全我们这里判断一下,叶子树不应该小于0
# 刚才输出的[15 18 15 15 23 27 13 17 28 21]
# 第1行的第1个数表示,预测的结果占据的是0-15位,第2棵树表示占据的是16-31位,以此类推
col.append(base_col_index +leaf_index) # 稀疏矩阵开始填数字,基础序列base_col_index加上
row.append(base_row_index) #同样,有行索引
data.append(1) #数据在该位置是1
base_col_index += leaf_num # zin-对于第2棵树预测结果,我们在基础列索引之上加上叶子数目
base_row_index +=1 #同样,每一个样本都需要更新一下行索引
total_feature_list = coo_matrix((data,(row,col)),shape=(total_row_num,total_col_num)) # 最终结果转化为稀疏矩阵形式
return total_feature_list
#9-7
def train_tree_and_lr_model(train_file, feature_num_file, mix_tree_model_file, mix_lr_model_file):
"""
gbdt+lr 混合模型 ,分开 训练 顺序训练(耗时较长)
:param train_file: 训练数据
:param feature_num_file: 特征维度文件
:param mix_tree_model_file: 混合模型树模型部分的文件
:param mix_lr_model_file: 混合模型逻辑回归部分的文件
:return: None
"""
train_feature, train_label = get_train_data(train_file, feature_num_file) # 传入 训练数据 和 特征维度文件
train_mat = xgb.DMatrix(train_feature, train_label) # 将数据结构转化成gbdt所需要的数据结构,因为我们用的xgboost,所以与之前树模型一样
tree_num, tree_depth, learning_rate = 10,6, 0.3 # 上一节已经选出了最优的参数
# (tree_depth, tree_num, learning_rate) = get_mix_model_tree_info()
# 这里树的深度由 6 改为4,原因:如下: 深度为6:总共:127个节点,64个叶子节点,63个非叶子节点
# 1.训练出的label,没有落在叶子节点上(或者落在叶子节点上比较少)
# 2. 特征与样本量的比值:1:100。 因为: 10颗数,深度为6,则叶子节点有 有640个维度,而样本有3万条,不满足
#训练树模型的代码,因为混合模型是分开训练,所以把树模型存储一下save_model
bst = train_tree_model_core(train_mat,tree_depth,tree_num,learning_rate) #此处调用一下训练树的主体函数,分别传入所需参数
bst.save_model(mix_tree_model_file)
# 理论部分已经讲过,lr模型所需特征是通过树模型通过编码得到的,所以只需叶的结点编成离散化特征,先预测一下样本
tree_leaf = bst.predict(train_mat,pred_leaf=True) #预测最终结果落在哪一个叶子节点上
# print(tree_leaf) #[81 84 84 84 85 77 68 91 97 61] 代表10颗数,81代表最终1 落到那一颗叶子节点上
# print(np.max(tree_leaf))
# print(tree_leaf[0])
# print(np.max(tree_leaf))
# sys.exit()
# 将上边落在哪一个叶子节点上的结果进行加工,最终获取训练lr所需要的特征,定义get_gbdt_and_lr_featrue专门完成特征转化
# 定义get_gbdt_and_lr_featrue专门完成特征转化,因为我们最终看落哪个叶的结点,所以这里的总的结点需要把它转换一下
total_feature_list = get_gbdt_and_lr_feature(tree_leaf,tree_num,tree_depth)
# 逻辑回归(前面课程详细讲过,所以这里就直接复制一下)
# zin模型训练中要注意的参数
# 1.正则化参数,这里支持多种参数进行选择,分别选一下,Cs=[1,10,100],这里边填入数的倒数便是正则化参数即1,0.1,0.01
# 2,penalty="l2",正则化选用l2(L2),之前讲过l1正则化倾向于将特征对应的参数学为0,而这里一共就100多列特征,我们倾向于将这些特征的参数选小而不是学为0
# 3.参数迭代停止的条件tol=0.0001,选为万分之1
# 4.最大迭代次数选择500次
# 5.cv=5,指定几轴交叉验证,意思是将训练数据分为5份,每一次拿出20%作为测试,80%作为训练,一共进行5次
# 最优化方法的选择:坐标轴下降法、牛顿法、梯度下降法(随机梯度下降):为了适应大数据训练,采用了随机梯度下降,我在每带选择一部分,近似整个代的记录,减少计算量提高计算速度
# 我们这里选了penalty="l2",所以只能选牛顿法/梯度下降法(随机梯度下降),这里默认选择牛顿法,因为我们样本不是特别多,我们希望所有样本都参与到训练中
lr_cf = LRCV(Cs=[1],penalty="l2",tol=0.0001,max_iter=500,cv=5).fit(train_feature,train_label)
#需要观察一下训练的结果//视频下边一行为scores = lr_cf.scores_.values()[0],改为源代码中如下两行
scores = lr_cf.scores_.values()
scores = list(scores)[0] # 提取values值
# 得到的scores是个5行3列的数组,所以我们看下每个正则化参数对应的5轴交叉验证之后平均的准确率是多少
print("diff %s : " % (",".join([str(ele) for ele in scores.mean(axis=0)]))) # 按照列求均值
print("Accuracy:%s (+- %0.2f ) "%(scores.mean(),scores.std()*2))
#print("Accuracy:%s " % (scores.mean())) #视频中不是mean(),mean后边没有(),后来又加上了()
# 模型的auc Cs=[1,10,100] #输出一下AUC,在lr_cf里加上scoring='roc_auc'
lr_cf = LRCV(Cs=[1], penalty="l2", tol=0.00001, max_iter=1000, cv=5, scoring='roc_auc').fit(train_feature,train_label)
scores = lr_cf.scores_.values()
scores = list(scores)[0] # 提取values值
#print(scores)
print("diff %s : " % (" ".join([str(ele) for ele in scores.mean(axis=0)]))) # 按照列求均值
print("AUC:%s (+- %0.2f )" % (scores.mean(),scores.std()*2))
#我改成如下,后来没试
# #train_tree_model("gbdt_lr/data/train_file", "gbdt_lr/data/feature_num_file", "")
if __name__ == "__main__":
train_tree_model("data/gbdt_train_file", "data/gbdt_feature_num", "data/test.model")
# 由于我们这里还没有实例化,所以先随便写两个文件
train_tree_and_lr_model("data/gbdt_train_file", "data/gbdt_feature_num", "test","test1")
运行一下,这回出来结果了,运行结果如下(和视频课不一样)
D:\develop\Anaconda3\python.exe "D:/develop/PyCharm 2018.3.5_workspace/p_recommendation_myself/gbdt_lr/train.py"
diff 0.8426498972714616 :
Accuracy:0.8426498972714616 (+- 0.01 )
diff 0.8991034606259747 :
AUC:0.8991034606259747 (+- 0.01 )
Process finished with exit code 0
视频课运行结果如下图
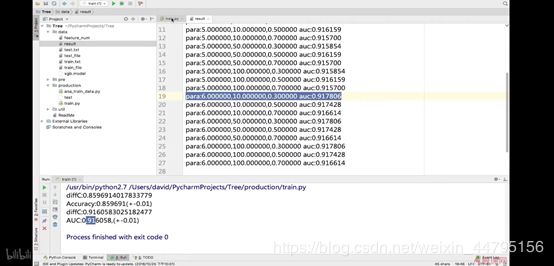
由视频课结果可见,GBDT+LR混合训练后auc为0.916058如上图,与之前的最优的0.917806相比还是差一点。那么为什么要混合呢?
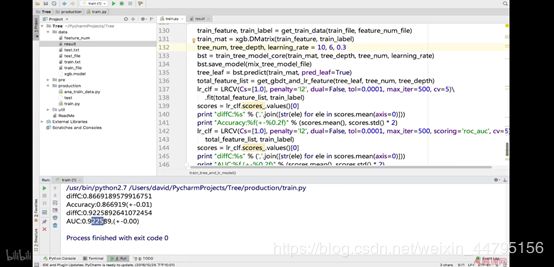
为的是更好的泛化模型在测试集的表现,我们故意把深度降低了,如果把深度调高会怎么样深度调成6后,如下图,已经高于0.917806
为了模型在测试数据集上的表现,还是将深度改为4,我们将LR模型也实例化一下,这里还采用之前的代码,在train_tree_and_lr_model最下边加上如下
fw=open(mix_lr_model_file,"w+")
coef = lr_cf.coef_[0]
fw.write(",".join([str(ele) for ele in coef]))
次时train_tree_and_lr_model如下
def train_tree_and_lr_model(train_file, feature_num_file, mix_tree_model_file, mix_lr_model_file):
"""
gbdt+lr 混合模型 ,分开 训练 顺序训练(耗时较长)
:param train_file: 训练数据
:param feature_num_file: 特征维度文件
:param mix_tree_model_file: 混合模型树模型部分的文件
:param mix_lr_model_file: 混合模型逻辑回归部分的文件
:return: None
"""
train_feature, train_label = get_train_data(train_file, feature_num_file) # 传入 训练数据 和 特征维度文件
train_mat = xgb.DMatrix(train_feature, train_label) # 将数据结构转化成gbdt所需要的数据结构,因为我们用的xgboost,所以与之前树模型一样
tree_num, tree_depth, learning_rate = 10,6, 0.3 # 上一节已经选出了最优的参数
# (tree_depth, tree_num, learning_rate) = get_mix_model_tree_info()
# 这里树的深度由 6 改为4,原因:如下: 深度为6:总共:127个节点,64个叶子节点,63个非叶子节点
# 1.训练出的label,没有落在叶子节点上(或者落在叶子节点上比较少)
# 2. 特征与样本量的比值:1:100。 因为: 10颗数,深度为6,则叶子节点有 有640个维度,而样本有3万条,不满足
#训练树模型的代码,因为混合模型是分开训练,所以把树模型存储一下save_model
bst = train_tree_model_core(train_mat,tree_depth,tree_num,learning_rate) #此处调用一下训练树的主体函数,分别传入所需参数
bst.save_model(mix_tree_model_file)
# 理论部分已经讲过,lr模型所需特征是通过树模型通过编码得到的,所以只需叶的结点编成离散化特征,先预测一下样本
tree_leaf = bst.predict(train_mat,pred_leaf=True) #预测最终结果落在哪一个叶子节点上
# print(tree_leaf) #[81 84 84 84 85 77 68 91 97 61] 代表10颗数,81代表最终1 落到那一颗叶子节点上
# print(np.max(tree_leaf))
# print(tree_leaf[0])
# print(np.max(tree_leaf))
# sys.exit()
# 将上边落在哪一个叶子节点上的结果进行加工,最终获取训练lr所需要的特征,定义get_gbdt_and_lr_featrue专门完成特征转化
# 定义get_gbdt_and_lr_featrue专门完成特征转化,因为我们最终看落哪个叶的结点,所以这里的总的结点需要把它转换一下
total_feature_list = get_gbdt_and_lr_feature(tree_leaf,tree_num,tree_depth)
# 逻辑回归(前面课程详细讲过,所以这里就直接复制一下)
# zin模型训练中要注意的参数
# 1.正则化参数,这里支持多种参数进行选择,分别选一下,Cs=[1,10,100],这里边填入数的倒数便是正则化参数即1,0.1,0.01
# 2,penalty="l2",正则化选用l2(L2),之前讲过l1正则化倾向于将特征对应的参数学为0,而这里一共就100多列特征,我们倾向于将这些特征的参数选小而不是学为0
# 3.参数迭代停止的条件tol=0.0001,选为万分之1
# 4.最大迭代次数选择500次
# 5.cv=5,指定几轴交叉验证,意思是将训练数据分为5份,每一次拿出20%作为测试,80%作为训练,一共进行5次
# 最优化方法的选择:坐标轴下降法、牛顿法、梯度下降法(随机梯度下降):为了适应大数据训练,采用了随机梯度下降,我在每带选择一部分,近似整个代的记录,减少计算量提高计算速度
# 我们这里选了penalty="l2",所以只能选牛顿法/梯度下降法(随机梯度下降),这里默认选择牛顿法,因为我们样本不是特别多,我们希望所有样本都参与到训练中
lr_cf = LRCV(Cs=[1],penalty="l2",tol=0.0001,max_iter=500,cv=5).fit(train_feature,train_label)
#需要观察一下训练的结果//视频下边一行为scores = lr_cf.scores_.values()[0],改为源代码中如下两行
scores = lr_cf.scores_.values()
scores = list(scores)[0] # 提取values值
# 得到的scores是个5行3列的数组,所以我们看下每个正则化参数对应的5轴交叉验证之后平均的准确率是多少
print("diff %s : " % (",".join([str(ele) for ele in scores.mean(axis=0)]))) # 按照列求均值
print("Accuracy:%s (+- %0.2f ) "%(scores.mean(),scores.std()*2))
#print("Accuracy:%s " % (scores.mean())) #视频中不是mean(),mean后边没有(),后来又加上了()
# 模型的auc Cs=[1,10,100] #输出一下AUC,在lr_cf里加上scoring='roc_auc'
lr_cf = LRCV(Cs=[1], penalty="l2", tol=0.00001, max_iter=1000, cv=5, scoring='roc_auc').fit(train_feature,train_label)
scores = lr_cf.scores_.values()
scores = list(scores)[0] # 提取values值
#print(scores)
print("diff %s : " % (" ".join([str(ele) for ele in scores.mean(axis=0)]))) # 按照列求均值
print("AUC:%s (+- %0.2f )" % (scores.mean(),scores.std()*2))
fw=open(mix_lr_model_file,"w+")
coef = lr_cf.coef_[0]
fw.write(",".join([str(ele) for ele in coef]))
main函数改成如下
train_tree_and_lr_model("data/gbdt_train_file", "data/gbdt_feature_num", "data/xgb_mix_model","data/xgb_lr_coef_mix_model")
此时train.py如下,
# -*- coding: utf-8 -*-
"""
==================================================
File Name: train
Description : Practical Lessons from Predicting Clicks on Ads at Facebook (2014)论文阅读
==================================================
"""
import xgboost as xgb
#import utils
import numpy as np # np读入文件
from sklearn.linear_model import LogisticRegressionCV as LRCV
from scipy.sparse import coo_matrix
import sys
#sys.path.append("../util")
sys.path.append("../..")
import p_recommendation_myself.gbdt_lr.util.get_feature_num as GF
#from p_recommendation_myself.gbdt_lr.util.get_feature_num import get_feature_num as GF
#from p_recommendation_myself.gbdt_lr.util.get_feature_num import get_feature_num as GF
#from p_recommendation_myself.gbdt_lr.util.utils import get_feature_num as GF
# zin 01
def get_train_data(train_file, feature_num_file):
"""获得训练数据 label和特征"""
total_feature_num = GF.get_feature_num(feature_num_file)
train_label = np.genfromtxt(train_file, dtype=np.int32, delimiter=",", usecols=-1) # label最后1列,label
feature_list = range(0, total_feature_num)
train_feature = np.genfromtxt(train_file, dtype=np.int32, delimiter=",", usecols=feature_list)
return train_feature, train_label
def train_tree_model_core(train_mat, tree_depth, tree_num, learning_rate):
"""
:param train_mat: 训练数据和label
:param tree_depth: 树的深度
:param tree_num:树的数量
:param learning_rate: 学习率
:return:Booster
"""
para_dict = {"max_depth": tree_depth, "eta": learning_rate, "objective": "reg:linear", "silent": 1}
bst = xgb.train(params=para_dict, dtrain=train_mat, num_boost_round=tree_num) #para_dict为几个参数组成的字典
# 交叉验证
#print(xgb.cv(params=para_dict, dtrain=train_mat, num_boost_round=tree_num, nfold=5, metrics={"auc"}))
return bst
#9-6
def choose_parameter():
"""生成参数
zin:list是元组,分别是树深度,树数目,步长;
这3个参数列表中的数目也可以增加,当然耗时也就会增加了
比如tree_depth_list = [4,5,6]可以为tree_depth_list = [4,5,6,7,8,9...]
"""
result_list = [] # 定义输出列表
tree_depth_list = [4,5,6] # [4,5,6]
tree_num_list = [10,50,100] # [10,50,100]
learning_rate_list = [0.3,0.5,0.7] # [0.3,,]
for ele_tree_depth in tree_depth_list:
for ele_tree_num in tree_num_list:
for ele_learning_rate in learning_rate_list:
result_list.append((ele_tree_depth, ele_tree_num, ele_learning_rate)) # 将结果以元组形式装载,注意顺序:深度,数目,步长
return result_list # 将最终结果返回
# 9-6
def grid_search(train_mat):
"""网格搜索参数"""
para_list = choose_parameter() # 定义一个构建参数的函数
for ele in para_list:
(tree_depth, tree_num, learning_rate) = ele # 元组包括这3个参数
para_dict = {"max_depth": tree_depth, "eta": learning_rate, "objective": "reg:linear", "silent": 1}
res = xgb.cv(params=para_dict, dtrain=train_mat, num_boost_round=tree_num, nfold=5, metrics={"auc"})
# 上一次课是10棵树,有10行,所以我们应该选最后一行结果,行号为树的总的数目,列为test-auc-mean,用values[0]把值获取出来
auc_score = res.loc[tree_num - 1, ["test-auc-mean"]].values[0] # 获取最后一棵树的得分就行了。
# 输出一下每一组参数和auc得分,把对应值tree_depth, tree_num, learning_rate, auc_score填进去,太长了,换下行
print("tree depth: %s , tree_num: %s , learning_rate: %s , auc: %f" % (
tree_depth, tree_num, learning_rate, auc_score))
# zin 9-5 T2-1-1 三个参数(筛选好的特征及样本文件,记录特征维度的文件,模型的存储文件)
def train_tree_model(train_file, feature_num_file, tree_model_file):
"""
训练树模型
"""
train_feature, train_label = get_train_data(train_file, feature_num_file)
train_mat = xgb.DMatrix(train_feature, train_label) # xgboost 需要的结构需要此类包装,训练的数据以及label
#grid_search(train_mat) # 参数选择,选择一次,就行,后面就无需继续使用了。,9.6刚开始未注释这行,运行后得到了最优参数后,便可以不再参数选择了,所以之后注释掉了这行
#sys.exit()
tree_num = 10
tree_depth = 6
learning_rate = 0.3 # 步长fm=fm-1+step_size*Tm
bst = train_tree_model_core(train_mat, tree_depth, tree_num, learning_rate) # 3个参数,训练的数据以及label,深度,数量,步长
#
bst.save_model(tree_model_file) # 将模型实例化输出,之后也就不需要再进行交叉验证参数选择了
#9-7
def get_gbdt_and_lr_feature(tree_leaf,tree_num,tree_depth):
"""
提取特征的代码
:param tree_leaf: predict of tree model
:param tree_num: total_num
:param tree_depth:
:return: 返回稀疏矩阵: 因为树的深度越深,叶子节点就越多,再加上树很多。那叶子节点就更稀疏
"""
total_node_num = 2**(tree_depth +1) -1
leaf_num = 2**tree_depth
not_leaf_num = total_node_num - leaf_num
total_col_num = leaf_num * tree_num # 总叶子节点数,总维度
total_row_num = len(tree_leaf) # 多少样本
col=[]
row= []
data = []
base_row_index = 0 # 总的行号
for one_result in tree_leaf: # 每个结点对应特征的列的序号
base_col_index = 0
for fix_index in one_result: # fix_index为获取的每一个数字
leaf_index = fix_index - not_leaf_num #最终转化为叶子结点,视频里leaf用的yezi
leaf_index = leaf_index if leaf_index >=0 else 0 # 为防止有一些树学习的不完全我们这里判断一下,叶子树不应该小于0
# 刚才输出的[15 18 15 15 23 27 13 17 28 21]
# 第1行的第1个数表示,预测的结果占据的是0-15位,第2棵树表示占据的是16-31位,以此类推
col.append(base_col_index +leaf_index) # 稀疏矩阵开始填数字,基础序列base_col_index加上
row.append(base_row_index) #同样,有行索引
data.append(1) #数据在该位置是1
base_col_index += leaf_num # zin-对于第2棵树预测结果,我们在基础列索引之上加上叶子数目
base_row_index +=1 #同样,每一个样本都需要更新一下行索引
total_feature_list = coo_matrix((data,(row,col)),shape=(total_row_num,total_col_num)) # 最终结果转化为稀疏矩阵形式
return total_feature_list
#9-7
def train_tree_and_lr_model(train_file, feature_num_file, mix_tree_model_file, mix_lr_model_file):
"""
gbdt+lr 混合模型 ,分开 训练 顺序训练(耗时较长)
:param train_file: 训练数据
:param feature_num_file: 特征维度文件
:param mix_tree_model_file: 混合模型树模型部分的文件
:param mix_lr_model_file: 混合模型逻辑回归部分的文件
:return: None
"""
train_feature, train_label = get_train_data(train_file, feature_num_file) # 传入 训练数据 和 特征维度文件
train_mat = xgb.DMatrix(train_feature, train_label) # 将数据结构转化成gbdt所需要的数据结构,因为我们用的xgboost,所以与之前树模型一样
tree_num, tree_depth, learning_rate = 10,6, 0.3 # 上一节已经选出了最优的参数
# (tree_depth, tree_num, learning_rate) = get_mix_model_tree_info()
# 这里树的深度由 6 改为4,原因:如下: 深度为6:总共:127个节点,64个叶子节点,63个非叶子节点
# 1.训练出的label,没有落在叶子节点上(或者落在叶子节点上比较少)
# 2. 特征与样本量的比值:1:100。 因为: 10颗数,深度为6,则叶子节点有 有640个维度,而样本有3万条,不满足
#训练树模型的代码,因为混合模型是分开训练,所以把树模型存储一下save_model
bst = train_tree_model_core(train_mat,tree_depth,tree_num,learning_rate) #此处调用一下训练树的主体函数,分别传入所需参数
bst.save_model(mix_tree_model_file)
# 理论部分已经讲过,lr模型所需特征是通过树模型通过编码得到的,所以只需叶的结点编成离散化特征,先预测一下样本
tree_leaf = bst.predict(train_mat,pred_leaf=True) #预测最终结果落在哪一个叶子节点上
# print(tree_leaf) #[81 84 84 84 85 77 68 91 97 61] 代表10颗数,81代表最终1 落到那一颗叶子节点上
# print(np.max(tree_leaf))
# print(tree_leaf[0])
# print(np.max(tree_leaf))
# sys.exit()
# 将上边落在哪一个叶子节点上的结果进行加工,最终获取训练lr所需要的特征,定义get_gbdt_and_lr_featrue专门完成特征转化
# 定义get_gbdt_and_lr_featrue专门完成特征转化,因为我们最终看落哪个叶的结点,所以这里的总的结点需要把它转换一下
total_feature_list = get_gbdt_and_lr_feature(tree_leaf,tree_num,tree_depth)
# 逻辑回归(前面课程详细讲过,所以这里就直接复制一下)
# zin模型训练中要注意的参数
# 1.正则化参数,这里支持多种参数进行选择,分别选一下,Cs=[1,10,100],这里边填入数的倒数便是正则化参数即1,0.1,0.01
# 2,penalty="l2",正则化选用l2(L2),之前讲过l1正则化倾向于将特征对应的参数学为0,而这里一共就100多列特征,我们倾向于将这些特征的参数选小而不是学为0
# 3.参数迭代停止的条件tol=0.0001,选为万分之1
# 4.最大迭代次数选择500次
# 5.cv=5,指定几轴交叉验证,意思是将训练数据分为5份,每一次拿出20%作为测试,80%作为训练,一共进行5次
# 最优化方法的选择:坐标轴下降法、牛顿法、梯度下降法(随机梯度下降):为了适应大数据训练,采用了随机梯度下降,我在每带选择一部分,近似整个代的记录,减少计算量提高计算速度
# 我们这里选了penalty="l2",所以只能选牛顿法/梯度下降法(随机梯度下降),这里默认选择牛顿法,因为我们样本不是特别多,我们希望所有样本都参与到训练中
lr_cf = LRCV(Cs=[1],penalty="l2",tol=0.0001,max_iter=500,cv=5).fit(train_feature,train_label)
#需要观察一下训练的结果//视频下边一行为scores = lr_cf.scores_.values()[0],改为源代码中如下两行
scores = lr_cf.scores_.values()
scores = list(scores)[0] # 提取values值
# 得到的scores是个5行3列的数组,所以我们看下每个正则化参数对应的5轴交叉验证之后平均的准确率是多少
print("diff %s : " % (",".join([str(ele) for ele in scores.mean(axis=0)]))) # 按照列求均值
print("Accuracy:%s (+- %0.2f ) "%(scores.mean(),scores.std()*2))
#print("Accuracy:%s " % (scores.mean())) #视频中不是mean(),mean后边没有(),后来又加上了()
# 模型的auc Cs=[1,10,100] #输出一下AUC,在lr_cf里加上scoring='roc_auc'
lr_cf = LRCV(Cs=[1], penalty="l2", tol=0.00001, max_iter=1000, cv=5, scoring='roc_auc').fit(train_feature,train_label)
scores = lr_cf.scores_.values()
scores = list(scores)[0] # 提取values值
#print(scores)
print("diff %s : " % (" ".join([str(ele) for ele in scores.mean(axis=0)]))) # 按照列求均值
print("AUC:%s (+- %0.2f )" % (scores.mean(),scores.std()*2))
fw=open(mix_lr_model_file,"w+")
coef = lr_cf.coef_[0]
fw.write(",".join([str(ele) for ele in coef]))
#我改成如下,后来没试
# #train_tree_model("gbdt_lr/data/train_file", "gbdt_lr/data/feature_num_file", "")
if __name__ == "__main__":
train_tree_model("data/gbdt_train_file", "data/gbdt_feature_num", "data/test.model")
# 由于我们这里还没有实例化,所以先随便写两个文件
# 视频课里如下
# train_tree_and_lr_model("data/gbdt_train_file", "data/gbdt_feature_num", "data/xgb_mix_model","data/xgb_lr_coef_mix_model")
train_tree_and_lr_model("data/gbdt_train_file", "data/gbdt_feature_num", "data/xgb_mix_model","data/xgb_lr_coef_mix_model")
运行一下,就实例化输出了