直播实录|百度大脑EasyDL·NVIDIA专场 部署专家
EasyDL—Jetson Nano部署方案技术解析
时间:2020年5月28日
讲师:百度AI开发平台部高级研发工程师 川峰
【直播回放】
EasyDL-Jetson Nano部署方案技术解析与应用实战:https://www.bilibili.com/video/BV1Rz411v7wS
【课程笔记】
课程大纲:
1. EasyDL专业版技术原理介绍
2. 训练并部署模型到Jetson Nano演示
【EasyDL专业版技术原理介绍】
EasyDL是一个零门槛的AI开发平台,目前发布了三个版本:经典版、专业版和零售版。经典版是零算法基础可以定制高精度AI模型,我们基本上使用鼠标点一点就可以获取自己数据集训练出来的模型,以及包含训练模型和部署代码的SDK,并且支持的AI任务比较多,像图像分类、物体检测、图像分割、文本分类、声音分类和视频分类。专业版主要是面向AI开发者或企业用户推出的AI模型训练及服务平台,也是提供了脚本调参功能,可以自定义超参和网络的头部结构,可深度定制自己的模型。最近我们也上了一个新的功能Notebook,提供了Notebook开发环境,大家可以完全从头定制代码,定制模型。零售版是专用于零售行业用户,训练商品检测、货架拼接的模型训练平台。

今天我们主要介绍EasyDL专业版的一些技术原理,包括也会用专业版演示如何从准备数据集开始训练一个模型,以及获取到SDK,到最后在Nano上完成部署。专业版支持脚本调参和Notebook,可深度调参和定制模型,并且支持飞桨Master模式。提供了基于百度海量数据集训练的预训练模型,加上EasyDL优秀的迁移学习的产业实践,使得大家在专业版使用少量数据集就可以达到很好的训练效果。目前专业版是支持了CV和NLP两大任务,CV支持图像分类和物体检测,NLP支持文本分类,短文本匹配和序列化标注,提供了一系列的训练模型。这里是目前EasyDL专业版已经支持的部分模型,包括14类图像分类和7种物体检测算法,并且这个模型库也是在不断丰富,具体的大家可以去EasyDL官网查看相关技术文档了解。

这一页主要是讲EasyDL专业版的技术框架图。上层业务系统,是大家可以感受到的或者可以交互的,包括数据集管理、模型训练、模型评估、模型校验、模型发布。再往下是深度学习工作流,支撑上层业务系统,有数据服务,提供了数据管理,智能标注和数据闭环。智能标注我一会也会用到,数据闭环的意思是在使用公有云API预测的时候,可以将API接口识别错误的图片添加到指定的数据集并纠正结果,后续训练模型的时候就可以增加包含接口数据的数据集,这样就可以提升模型的效果。数据预处理这块提供了数据增强的功能,包括手动和自动数据增强,后面我们会再讲到一些细节。模型训练稍微复杂一点,我这里列了几个功能点,包括迁移学习、分布式训练加速、自动超参调优、Auto DL Search和Anchor自适应调优。模型评估,有mAP,F1-score,精确率,召回率,平均精度。模型部署的部分也是支持了将模型发布为适配各种硬件形态的SDK,大致分为这四大类,包括公有云部署,私有服务器部署,设备端通用SDK和专项硬件适配,大家可以根据自己的需要发布。这一整套流程都是通过AI Workflow串起来的,并工作在深度学习平台飞桨之上的。

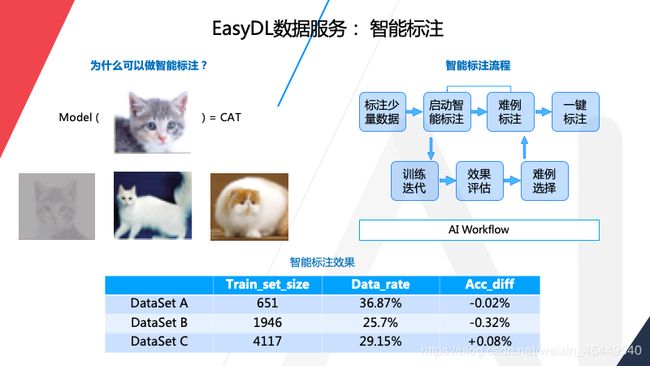
数据的智能标注,这部分是提升效率的工具,使用智能标注可以只标注数据集一小部分,最低要求是每个标签标注量不少于10张图片,然后启动智能标注,让AI帮你标注,它会筛选出一些图片,你直接确认就行了。为什么可以使用智能标注呢,我这里举个例子,比如我们有一个模型,是可以识别猫的模型,现在想加入新的图片到训练集当中,比如下面还有三张猫图,什么样的图片会对效果提升有帮助呢,显然就是第二和第三张,因为第一张和原有数据集的图太相似了,对于提升模型的泛化能力不是很好,智能标注就是为大家挑选出第二第三张这样的图片让大家标注,第一张就是自动标注,节省标注成本。在流程上,就像刚才说的,需要为每个标签至少标注10张以上的图,然后启动智能标注,其实后端会帮大家训练一个模型,用这个模型在数据集标注的图片进行识别,标注有问题的图片会反馈回来进行人工标注,反复多次迭代,剩下的数据可以一键标注或者大家手动结束这样的流程。
EasyDL还对数据预处理提供了自动数据增强的功能,这里有两个问题,一个是如何在有限的样本下提供更好的模型效果,要么是优化模型,要么就是使用数据增强。还有一个问题,如何构建与数据集特性强相关的数据增强策略呢,EasyDL专业版提供了自动增强的策略,以视觉训练为例,我们可以结合数据集的特性做一些,例如平移、旋转、亮度调整和裁剪等操作,以生成新的图加入数据集。比如这个猫,右边的6个图是对原数据的数据增强得到的新图,这就可以达到更好的泛化能力。在现实场景中,我们可能会有一些在有限场景中拍摄的数据集,但是目标存在不同的条件,比如不同的方向、位置、亮度等等,这时候就可以通过额外合成数据向模型提供这些数据分布,但是数据增强需要的配置参数非常多,像刚才提到的调整的对比度、亮度以及缩放比例,具体调多少,参数太多了,组合起来的空间非常大,人工调参就需要很多的经验,费时费力,所以我们就需要进行自动搜索数据增强的超参。EasyDL的数据增强也是提供了一系列的增强策略,用户可以手动设置数据增强的超参,当然这个可能对用户要求比较高,你需要对领域知识和数据特征比较熟悉才行,不过也可以选择自动数据增强,我们后端会根据大家的数据集的特征和增强策略进行自动搜索,以产出一个最佳的增强参数,从而提升数据集的规模,来获得更好的模型的性能。

这里列出来的是EasyDL专业版的图像分类和物体检测支持的数据增强的策略,比如像剪切、平移、旋转,调整对比度和亮度等等,物体检测数据增强操作是多一点,主要是对标注框里的物体做了一些处理。

接下来这张图是使用数据增强和不使用数据增强的效果对比图,黄色柱状图是使用了数据增强的,准确率还是有所提升的。

迁移学习。如果你想训练一个深度学习的模型,从头训练模型通常需要大量的数据,但是数据其实并不容易获得,包括采集、标注、算力等方面成本比较高,我们可以使用预训练模型,在预训练模型的基础上重新调优,并利用预训练模型以及学习到的知识来提高对另一项任务的泛化性,简单说就是在大数据集预训练的模型上进行小数据集的迁移,以获得对新数据较好的识别效果。我们为什么要用迁移学习,正像刚才说的,其中一个原因就是数据并不是很容易获得的,也就是数据的稀缺性。还有一个就是算力要求高,通常从头训练一个模型至少需要几天甚至几周的时间,利用迁移学习就可以很快,可能只需要几小时甚至几十分钟,在EasyDL通常就十几分钟就可以训练出一个效果不错的模型,原因就是EasyDL内置了基于百度海量数据集训练的预训练模型,再加上优秀的迁移学习工具,使得模型训练效率高,效果也是不错的。


然后是AutoDL,AutoDL就是用深度学习设计深度学习,硬件应用场景和模态的多样化,使得AI算法的维度空间是非常大,想要尽可能探索这个空间就必然要从手工设计模型转到自动化生产模型。所以,我们也是利用了深度强化学习设计模型,整个系统由两部分组成,一个是网络的编码器,右边这个是网络评测器,编码器负责设计网络,然后交给评测器进行训练和评估,评估就包括像准确率、模型大小在内的指标,然后反馈给编码器再进行修改再次编码,反复迭代,经过若干次迭代最终就会得到设计好的模型。
在基于百度海量数据搜索出的网络模型后,也可以通过AutoDL Transfer进行迁移训练,在小数据集上进行finetune,这是经典网络和AutoDL迁移学习的效果对比,效果还是有优势的。同时EasyDL经典版也是开放了优秀的AutoDL预训练模型供大家使用。

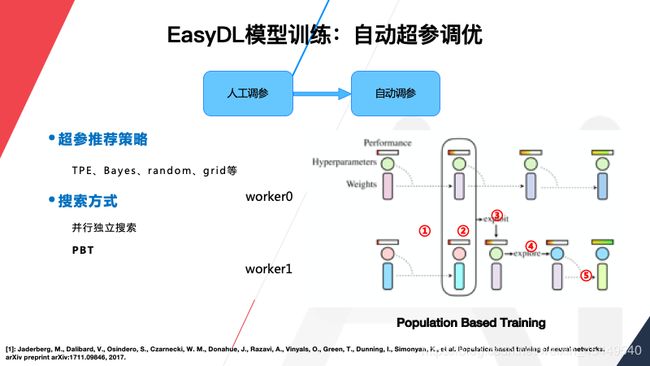
然后是自动超参调优,EasyDL模型训练也支持自动超参调优。为什么要自动调参?因为参数太多了,通常需要不断的调整参数,不断的迭代训练来验证,就是太费时费力了,所以EasyDL也是使用了自动超参调优的机制。比如右边这张图,有两个并发进行了试验,初始的时候超参和模型权重都相同,经过一定轮数的训练以后,第二步就会进行对比,如果发现worker0的效果好就进行第三步,把worker0的权重和超参值复制给worker1,worker0本身接着训练,不受影响,但是对worker1还要进行第四步,就是复制过来的权重和超参加入一些扰动,使它与worker0的参数有所差异,然后再继续训练,这就相当于在训练过程中把worker1上的原始超参值过滤了,并在好的基础上进行进一步的试验,从而加快搜索效率。从试验效果来看使用自动超参调优机制的模型在平均准确率上面也是有一定的优势。
其实EasyDL的模型训练使用了深度梯度压缩机制,也就是DGC,飞桨是从1.6.2版本已经支持了DGC算法,加速比较明显,大家可以看一下这个表格,右边这个数据是在V100GPU统计的,在2机2卡统计下总训练时间是从520秒缩短到了74秒。

EasyDL专业版还有多个即将上线新功能,大家可以关注一下,包括Anchor自适应优化,可能大多数用户不知道怎么设置,我们会加入Anchor的优化机制,根据用户数据集特征自动计算出合适的aspect ratios。

EasyDL模型深度定制是通过脚本调参和Notebook的方式实现的,刚才我们也提到过。脚本调参的形式是将模型的超参配置和网络的头部定义函数都暴露给大家,比如像这里的自定义layer和loss函数都是可以自定义,右边包括batchsize,输入尺寸,学习率衰减,都可以根据自己的数据集调整,这是脚本调参。

还有一个是Notebook,Notebook是我们前不久刚上线的一项功能,也是基于自研的深度学习平台飞桨提供端到端的训练方案,并且提供了高性能大显存的V100显卡,数据集也是和专业版打通,大家使用Notebook可以从头完全定制代码,训练出来模型可以发布并且部署到云端。它的使用流程也不复杂,这块我不深入讲了,大家可以自行探索一下。


EasyDL的模型部署也是非常丰富,大致分为四大类,包括公有云部署,私有服务器部署,通用设备端SDK,以及软硬一体产品。这边列出了目前EasyDL支持的一些芯片和操作系统,大家可以看到,我们支持了10余类的芯片和4大类的操作系统。这个标红的地方就是对Jetson Nano的支持,除此之外我们也支持X86平台的GPU,大家可以体验一下。


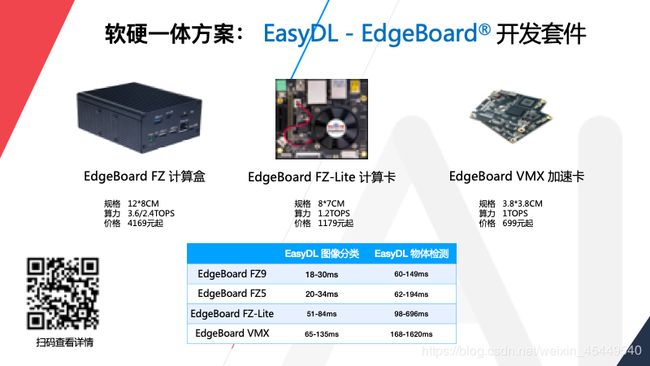
软硬一体刚才我们讲到部署方式,EasyDL四大类,其中一个是软硬一体方案。软硬一体方案目前支持两个系列的产品,一个是EdgeBoard系列,包括计算盒,计算卡和加速卡,它们价格各不相同,功能和性能也各不相同,大家可以根据自己的业务需求进行选择。这里也有EasyDL模型实测性能,大家可以通过扫码了解一下详情,也可以到EasyDL的官网了解。
另一个系列是Jetson软硬一体方案,目前支持Jetson Nano Jetson TX2和Jetson AGX Xavier,算力也是非常强劲,昨天有人问EasyDL模型和SDK在Jetson上跑用的CPU还是GPU,肯定是用GPU,不然很难发挥它的优势。我们这边就是对图片的处理和推理预测都是做了优化和加速的,速度非常快的,比如像EasyDL-Jetson AGX Xavier,跑EasyDL图像分类可以达到几毫秒的速度。

讲了这么多,EasyDL究竟长什么样子,定制模型应该怎么做呢,我训练完模型以后发布为SDK,我拿到SDK了怎么在Nano上跑起来,今天通过解决一个车辆和人物识别的任务进行全流程的演示。

刚才我们说要解决车辆和人物识别的任务,其实大致流程可以分为三步,我今天会使用EasyDL专业版脚本调参训练一个模型。大致就是准备数据集,车辆和行人的识别数据集,然后去EasyDL专业版训练一个模型,最后发布为SDK并下载到Nano上使用。

首先第一步就是先准备数据集,我的数据集是我自己收集了一些行车场景和骑行场景,以及步行场景的城市街景视频,我是抽帧成了很多图片,但是我得到这些图片要筛选。因为是抽帧的,肯定存在很多图片相似度太高的以及模糊的图片怎么办。所以我使用了EasyData数据清洗和智能标注的功能,清洗了一些模糊的图片,也减轻了我标注的工作量。
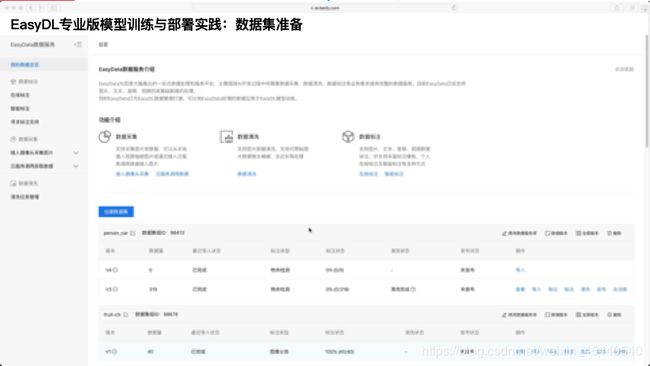
立即访问EasyData:https://ai.baidu.com/easydata/
在EasyData的主页,下拉可以看到数据服务-数据清洗,点击了解详情即可。进入后,可以点击【新建清洗任务】,可以进入到清洗方式的选择。在选择清洗方式时,最多可以同时选择三种清洗方式。




在数据准备好、并训练好模型之后,可以在部署方式中选择专项硬件的适配。之后在审核通过之后可以在【服务详情】-【下载链接】处下载SDK。
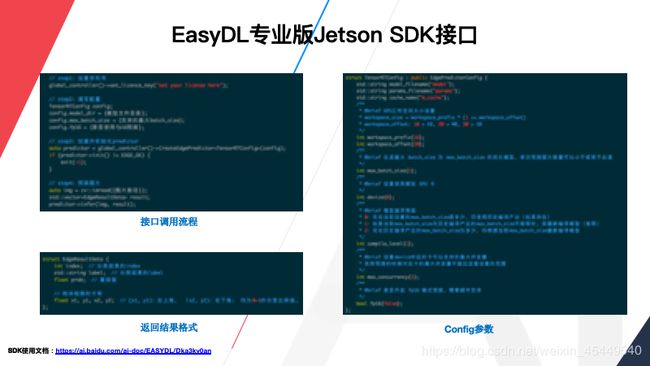
之后把SDK放到Nano中进行部署。首先连接Nano,我们解压SDK后,得到两个文件:CPP和RES,RES里是模型文件,CPP就是SDK,解压一下看看,提供了三个DEMO,有serving的,可以起一个简单的服务,大家可以在浏览器里输入相应的地址,可以体验到和H5差不多的效果。Multi_thread是支持多线程的预测,如果大家有需求可以看一下。还有batch inference,可以支持单张图片预测或多张图片预测,我们编译一下看看。编译之前要填写一个序列号,我们要使用batch inference预测,需要设置一下序列号。先看一下代码结构,这个函数非常简单,首先是设置序列号,然后有一个config,在这里进行参数的配置,包括模型的路径,支持的最大batchsize,我这里设置8,意思是下次预测可以使用小于等于8张图片预测。并发量,指的是可以支持最大的线程数,如果跑单线程可以设置成1,如果设置比较大会占用资源。FP16就是你要不要用FP16预测。config设置完了以后,创建一个predictor,然后init,整个环境已经准备好了,之后就可以调用infer进行预测。
整体简单来说可以分为四个步骤:
- 设置序列号
- 配置
- 创建一个predictor并将它init
- 最后进行infer

先设置序列号。Batchsize可以设小一点,比如我们设置成2,保存,然后开始编译。有三个文件,产出也有三个,我们使用batch inference预测一下,它有两个参数,一个是模型的路径,还有一个是图片的名字或者图片的路径,因为是支持batch预测的,它会把路径下面所有的图片进行预测(需保证路径下只有图片)。我先预测一张。这个时候可以看到,在优化模型,你第一次使用可能比较慢,后面再跑就比较快。当然你也可以在刚才的cofig一个选项,设置你是不是每次都要优化模型,因为我设置的1,意味着只优化一次,下次如果再有就直接使用。
这里有一个error是什么呢,是鉴权的问题,因为我没有联网,所以大家首次使用的时候一定要联网。Nano性能还是不比TX2和Xavier,我现在使用的Nano,是通过网线连接到了电脑,所以没有网络访问权限,当然你也可以设置一个代理。预测结果出来之后,demo里有一个注释的代码,打开后可以把结果的图片保存。因为我刚才提到这个过程,如果有这个提示,说明它正在编译模型,这个过程确实非常慢,如果编译好以后再次运行就比较快了,我们再运行一次。很快就出来了,当然如果实际的预测,init这个过程不需要每次都跑的,直接infer的话预测速度更快一些。在这里会有一个图片保存在这里,我们看一下识别的结果。
这个是它的识别结果,这是一个单图的预测。我们刚才提到可以指定一个文件夹,我把刚才生成的结果图片删掉,这里有两张图片的,我们看看预测文件夹会怎么样,它会把两张图片的结果都打印出来,结果保存在这里,这就是Nano的预测过程。
其实大家可以看到,从我下载SDK到现在运行起来,我也没有写代码,就填了一个序列号,我们这个SDK已经做的非常简便,包括batch的预测,都是非常简便,接口也是非常简单,就是init和infer两个。刚才我们提到还有一个serving,这个是起HTTP的服务,起来以后可以通过端口在浏览器里输入,打开页面上传图片,和我们刚才演示的是一样的。看一下吧,它需要的参数,模型路径,序列号,服务地址,端口,后面使用默认的。这个时候再重新编译模型,还需要等会,第一次使用确实是需要编译模型。
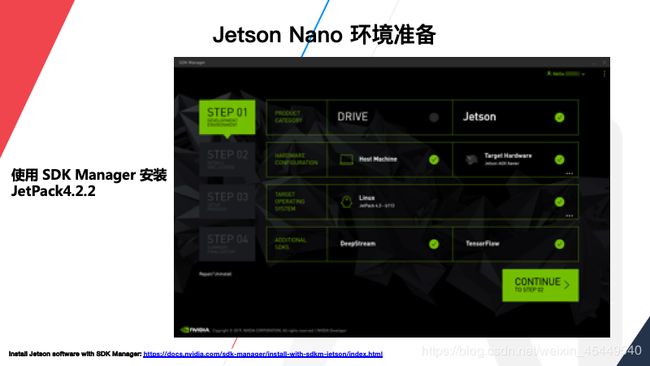
如果使用Nano需要先准备它的运行环境,我们推荐是使用SD Card Image,Host上下载安装并安装Etcher,如果用过Nano比较简单,如果是TX2和Xavier就稍微麻烦一些,可能需要使用SDK Manager来安装,当然Nano也可以使用这个工具安装,推荐大家安装这个JetPack4.2.2。流程就是这么简单。
这里贴出的是config的配置结构体,这是支持的配置参数,包括模型的名字以及缓存的名字,以及工作空间大小的设置,以及你想支持的最大的batchsize。Device ID不用设置,在使用X86平台的多卡GPU时才会使用这个。编译选项,就是我刚才设置为1,意思就是我有历史编译的模型可以直接使用,不需重新编译。这个是支持最大的并发量,这里是是否使用FP16预测。
【Q&A】
Q:有同学问合作的板子和正常板子价格一样吗。
A:我们合作的板子是限量直降,全网最低的价格。
Q:超参自动搜索用的是什么算法?
A:刚才PPT里已经讲到了,如果有兴趣可以看一下回放,查一下我里面提到的几种算法。
Q:运行部署模型花钱吗?
A:运行部署不会花钱,比如软硬一体授权一个license,SDK是随便使用不会再收钱的,只会收授权的费用。
Q:模型下载下来可以自己调用吗?咱们模型支持下载下来吗?
A:是支持下载,就是我刚才说的SDK包括两个部分,包括在Nano上演示的时候,可以看到有CPP目录和RES目录,RES就是你训练的模型 。
Q:NX支持EasyDL的SDK吗?
A:这个是比较新的套件,理论上是支持的,但为什么没有写上去,因为我们也要深度适配一下,不久会上到线上,大家可以关注一下。大家也可以在百度AI市场搜索查看。
Q:套件需要神经计算棒吗?
A:Nano和Xavier和TX2不需要神经计算棒,神经计算棒跟这个不是太相关,它也是一种计算型的硬件,用来加速。
Q:EasyData清洗收费吗?
A:清洗不收费。比如视频抽帧可以使用清洗的功能,以及智能标注。
Q:现在支持多人标注吗?
A:多人标注的话,在群里问一下吧,据我所知是支持的。
Q:模型可以在本地进行训练吗?
A:本地目前还不行,目前都是在云端训练的。
Q:增强好的数据可以下载吗?
A:数据增强我理解应该只是一个策略,数据集并不会真实的扩充,你下载下来还是原始的数据集,但是具体能不能扩充到你的数据集,以及能不能下载,如果真的需要可以提一个工单,我们会评估一下。
好,提示一下开发者,大家要善用提交工单的功能,EasyDL遇到一些问题的时候,可以提交工单输入你的问题,研发老师就会为您解答。
Q:EasyDL底层是哪个框架?
A:底层框架,现在EasyDL都是基于飞桨深度学习平台的,其实现在飞桨这个生态已经非常好了,各种工具也比较齐全,我们底层平台都是用飞桨。
Q:TX2的torchvision最高的版本是多少?
A:其实这个版本是要看TX2上用的是JetPack版本是什么,JetPack每个版本支持的最高版本的torchvision都是不一样的,所以说我建议大家到官网上看一下,随后我可以把这部分的链接发到群里,大家看一下自己使用的JetPack是哪个版本,上面都有支持到最高版本的相关说明。
Q:如何通过笔记本远程访问Jetson Nano?
A:你只需要拿个网线把Nano连到你的电脑,然后登录到Jetson Nano,你可以设置一个固定的IT地址,在电脑设置上配置一下路由器和IP地址,跟它一个网段就可以,然后连接到你的Nano上,我刚才就是这么干的。
Q:其他框架的模型能不能也用Nano部署?
A:其他框架当然可以,但是你的部署成本可能会比较高,不像EasyDL,像图片的预处理和底层的推理都做好了,封装的接口已经非常简单了,当然你自己做可以,就是复杂一些,答案是支持的。
Q:是不是Nano刚开始使用是否需要做系统,能否简单展示一下?
A:需要做系统,Nano需要先刷机。有两种方法,一种是直接拿SD卡往里写Image,这个在网上都能直接下到,也有一个工具,大家可以到NVIDIA相应的网站上看到教程,就几步很简单,下载一个工具,加载硬件,然后插到板子上开机就行了。另一种方式就是用SDK Manager。
具体刷机的流程和方式,可以看一下NVIDIA官网,上面有具体的介绍。
Q:有同学问训练模型能和别的框架模型互相转化吗?
A:目前没有提供这种功能,因为我们训练的模型已经是深度定制了,包括集成SDK,拿来即用,目前是没有提供往其他框架转,当然Paddle本身是支持往其他框架转,比如Paddle2onnx或x2paddle工具。
Q:视频流预测部署应该怎么做?
A:视频流的可以关注明天的deepstream课程,就是讲视频流这块,你一定要收听一下。刚才我做的视频流用的不是deepstream,而是通过调用HTTP服务地址做预测,就是这样。
Q:应该是SDK只支持一个模型还是适用于多个模型?
A:如果你是EasyDL训练的话,其实可以跑多个模型,但是它是和模型绑定的,不建议你这么做,每次训练一个模型建议你下载一个SDK,这样不会出现什么问题。
Q:Nano支持VMX吗?
A:我理解你是想用LinuxARM跑VMX,首先你要确定openvino是否能在Nano上编译的出来,如果可以,你可以尝试。SDK的话我们后续会有,可以保持关注。
Q: EasyData数据会共享吗?
A:不会。
Q:编程可以用python的方式吗?
A::目前就只有C++版本,如果用python可以像我刚才的,起HTPP服务,通过python代码调用这个接口,这是一个方式。
Q:有没有行为识别的例子,昨天是不是有行为识别DEMO的例子。
A:是的,昨天云原生的技术有一个。
Q:EasyDL上面可以做一个行为识别吗?
A:目前还不行,像经典版我提到有一些分类、检测、分割的任务,专业版提供的是分类和检测,如果做行为识别要在这些任务基础上看你怎么写逻辑实现。
Q:有同学问Nano支持同时跑多个EasyDL的模型吗?
A:我不建议你这么做,为什么,因为Nano的性能本身有限,如果跑多个模型会非常慢。
Q:如果这样是不是还是使用TX2或者Xavier好一些。
A:对,使用Xavier是最好的。
Q:Nano支持POE吗,电流多大?
A:所有的信息在我们的官网上都有,非常详细的信息,大家可以到官网上找到你感兴趣的Jetson的平台,比如Nano里就有所有的配置信息,包括电源信息、接口信息都有。
好。大家如果对Nano电流和接口信息感兴趣可以访问一下NVIDIA官网,上面有一张大表,记录各种细节的信息。
Q:Nano安装EasyDL SDK以后,通过接口这样的开发方式可以不可以简单介绍一下。
A:下载SDK以后,放到Nano,解压出来,里面是有DEMO,可以直接编译,对单张图和多张图预测,有多线程的预测,还有起服务的形式都有,如果你还有疑问,你可以再看一下回放,或者在群里提其他的问题,都可以。
Q:刚才老师用的shell工具是什么?
A:我的电脑是mac,我的shell工具是iTerm2。
Q:脚本调参的训练计费是多少钱?
A:初始应该是提供了100个小时的免费额度,后面再用,计费在主页上都写了,你可以看一下。
Q:就EdgeBoard和Nano哪个更快一些。
A:EdgeBoard刚才讲了几个,有计算卡,加速卡,计算盒,你可以看回放或者到EasyDL主页查看对比。
Q:Jetson、TX2和Xavier能运行caffe吗?
A:没问题,可以运行。
Q:支持的摄像头列表在哪里能看到?
A:比如说用Jetson的产品外接哪些摄像头,所有的硬件接口支持什么样的相机,也是在官网信息上都有,会有非常详细的外界传感器的支持信息列表。关于接口、电流,就是外接设备,可以在EasyDL官网上看一下细节介绍。
Q:新的Nano如何通过SSH设置网址?
A:ssh登录首先需要知道ip,你可以通过串口设置ip,然后再用SSH登录。或者直接连接显示器鼠标键盘进去设置,在主机上配置网络。
Q:Nano控制继电器需要GPIO吗?
A:我印象中是需要的,我建议还是到官网上查看一下。
Q:笔记本远程访问Jetson Nano,如何通过SSH访问?
A:刚才有两个问题都类似,你先知道它的IP地址,可以通过串口设置或者是接个显示器或鼠标键盘设置,然后在主机上配置一下网络就可以了,网上教程比较多。另外就是刚才的问题,EasyDL怎么接deepstream这个问题,其实我们也在看,大家可以关注一下,这个也会深度支持的。
主持人:好的。QA环节就到这里,如果有其他问题,可以看一下小助手的微信号,或搜索一下BaiduEasyDL的拼音,群里有百度的专家和NVIDIA的专家为大家解答。
现在介绍一下Jetson和EasyDL软硬一体方案,EasyDLJetson Nano是800,原价是1099,800是全网最低,性能非常好,搭载EasyDL定制模型深度适配,可轻松实现定制AI的离线计算。中间是EasyDL和JetsonTX2方案,原价3500,现在是3200,感兴趣可以扫描二维码。右侧是EasyDL和JetsonXavier软硬一体方案,售价是5600,原价是5999。同时大家可以看到,左侧有一本书,如果现在购买EasyDL和Jetson的软硬一体方案,可以获赠这本基于NVIDIA Jetson人工智能开发入门。

刚同学说到已经单独购买NVIDIA硬件,训练模型之后,选择发布为SDK,点击服务详情下载SDK并进入控制台,进入控制台左侧导航,专项硬件适配服务器,点击新增测试序列号,即可获得专用序列号,即可获得三个月有效期的专用SDK,在SDK购买上线后即可购买。

在百度AI市场搜索EasyDL,选择EasyDLJetson Nano/TX2软硬一体开发套件进行购买。获得Jetson Nano和用于激活专用SDK的专用序列号,在EasyDL训练专项适配Jetson的图像分类/物体检测模型,迭代模型致效果满足业务需求,发布模型时选择专项硬件适配SDK—Jetson专用SDK,参考文档进行部署集成,即可实现离线AI预测。


在下周的课程中,来到了百度AI快车道-EasyDL产业应用系列:领域信息处理专场。在6月2日-6月3日,主要为CV方向,内容将会包括直播平台、互联网社区等业务,如何构建图像审核、文本审核内容安全方案和利用EasyDL图像分类能力构建膀胱肿瘤识别模型并进行临床部署。
想要快速提升自己,转型AI应用专家的小伙伴,一定不要错过哦!下周课程海报: