一种数据增广方案(Data Augmentation)MixMatch算法 另附代码分析
MixMatch 算法来源于 MixMatch: A Holistic Approach to Semi-Supervised Learning 这篇文章,客观来说这篇文章并不能严格的算作是数据增广,应该是一种半监督的训练方法,即使用少量数据训练模型使模型达到举一反三的目的。但是我认为这仍然可以归为数据增广的范畴,因为数据增广的目的就是防止模型训练过拟合,使之能在更大的数据集上也有好的表现,只不过与其他方法所不同的是该方法并不侧重于通过各种变换来增加数据集数据量,我认为它的核心也是在训练中隐式的进行数据增广上做文章。
MixMatch的过程如下图所示:

1. 从数据集中随机挑选一个Batch记为A,并且对这个Batch的数据做常规增广,但是不改变label
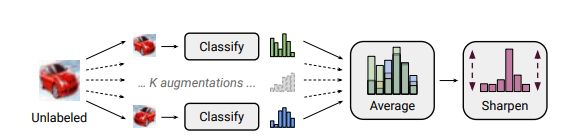
2. 取出一个同A一样大小的Batch记为B,此时不考虑该Batch的label,然后做k次的随机增广(文章中推荐k取值为2),将这些增广后的数据送入预先训练的一个简单的分类器,这样会计算得到一个平均分类概率,然后使用温度Sharpen算法进行处理,此时可以得到batch B样本的一个猜测label,这一步的过程如下图所示:
这里的Sharpen算法是这样一回事,首先 Sharpen公式如下所示:
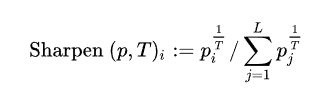
这里面T是一个超参,被称之为温度,P是样本从属于某label的概率,Sharpen算法有助于修正模型,使之给出低熵的判断,因为这里不是主要内容,因此不赘述。总之此时通过Sharpen过后可以获得每一个增广数据通过分类器所获得的预测label。
3. 此时Batch A数据增广后有确定的label,而经过第二步处理后,可以获得k个Batch,并且这种Batch的label是预测出来的,到这一步就可以看出数据进行了增广;然后将A和这k个Batch进行随机重排,对随机重排的数据挑出一个Batch 记为C,将C和原先的A进行MixUp处理,MixUp方法在上一篇文章中详细论述,这里不赘述。
4. 然后将重排后数据挑选非A的再进行MixUp,可以获得新的Batch D,在下面的公式中,将D和A与C mixup的结果记为![]()
和![]()
5. 对上述数据集分别计算loss

4. 最后计算混合loss
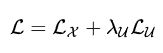
这里的lambda 是超参,文章推荐使用100
接下来进行代码分析:
import torch
import numpy as np
import imgaug as ia
import imgaug.augmenters as iaa
def get_augmentor():
seq = iaa.Sequential([
iaa.Crop(px=(0, 16)),
iaa.Fliplr(0.5),
iaa.GaussianBlur(sigma=(0, 3.0))
])
def augment(images):
return seq.augment(images.transpose(0, 2, 3, 1)).transpose(0, 2, 3, 1)
return augment
def sharpen(x, T):
temp = x**(1/T)
return temp / temp.sum(axis=1, keepdims=True)
def mixup(x1, x2, y1, y2, alpha):
beta = np.random.beta(alpha, -alpha)
x = beta * x1 + (1 - beta) * x2
y = beta * y1 + (1 - beta) * y2
return x, y
def mixmatch(x, y, u, model, augment_fn, T=0.5, K=2, alpha=0.75):
xb = augment_fn(x)
ub = [augment_fn(u) for _ in range(K)]
qb = sharpen(sum(map(lambda i: model(i), ub)) / K)
Ux = np.concatenate(ub, axis=0)
Uy = np.concatenate([qb for _ in range(K)], axis=0)
indices = np.random.shuffle(np.arange(len(xb) + len(Ux)))
Wx = np.concatenate([Ux, xb], axis=0)[indices]
Wy = np.concatenate([qb, y], axis=0)[indices]
X, p = mixup(xb, Wx[:len(xb)], y, Wy[:len(xb)], alpha)
U, q = mixup(Ux, Wx[len(xb):], Uy, Wy[len(xb):], alpha)
return X, p, U, q
class MixMatchLoss(torch.nn.Module):
def __init__(self, lambda_u=100):
self.lambda_u = lambda_u
self.xent = torch.nn.CrossEntropyLoss()
self.mse = torch.nn.MSELoss()
super(MixMatchLoss, self).__init__()
def forward(X, U, p, q):
X_ = np.concatenate([X, U], axis=1)
y_ = np.concatenate([p, q], axis=1)
return self.xent(preds[:len(p)], p) + self.mse(preds[len(p):], q)
根据实际的操作来看,作者分析了具体某项改进对于模型的贡献

我定性的解释下这里的情况:
我认为这里的方法实际上类似于一种自洽的正则化,这相当于在告诉模型,来源一样的数据应该给出同样的评判,这样从逻辑上是对人类小样本学习的映射。