Oracle listagg函数、lag函数、lead函数
原文:http://blog.sina.com.cn/s/blog_4cef5c7b01016efp.html
Listagg函数
我们有时候会遇到这样的需求:“对员工列表进行操作,将每个部门的员工名称横向排列,以逗号进行分割”。
员工表我们使用scott用户schema下的emp表。
SQL> select * from emp;
EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO
----- ---------- --------- ----- ----------- --------- --------- ------
7369 SMITH CLERK 7902 1980-12-17 800.00 20
7876 ADAMS CLERK 7788 1987-5-23 1100.00 20
7900 JAMES CLERK 7698 1981-12-3 950.00 30
7902 FORD ANALYST 7566 1981-12-3 3000.00 20
7934 MILLER CLERK 7782 1982-1-23 1300.00 10
(篇幅原因,有省略……)
14 rows selected这个需求的关键在于如何将ename员工名称列压扁为一行数据。如果不使用SQL解决,最直观的想法就是使用PL/SQL进行迭代遍历,获取到所有的数据行记录。
此时,我们就可以求助Oracle 11g中的函数listagg。首先我们来看一下listagg的函数描述(摘自Oracle SQL Reference)。
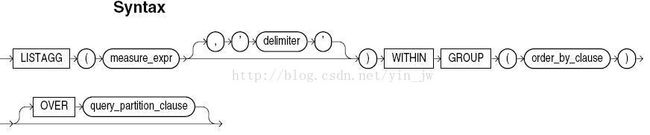
listagg的作用是将分组范围内的所有行特定列的记录加以合并成行。函数签名中的measure_expr为分组中每个列的表达式,而delimiter为合并分割符。如果delimiter不设置的话,就表示无分割符。
中间within group后面的order_by_clause表示的是进行合并中要遵守的排序顺序。而后面的over子句表明listagg是具有分析函数analyze funcation特性的。具体采用listagg有三个场景。
当无分组的single-list情况下
如果要获取到deptno为30的所有员工横行记录。
SQL> select * from emp where deptno=30;
EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO
----- ---------- --------- ----- ----------- --------- --------- ------
7499 ALLEN SALESMAN 7698 1981-2-20 1600.00 300.00 30
7521 WARD SALESMAN 7698 1981-2-22 1250.00 500.00 30
7654 MARTIN SALESMAN 7698 1981-9-28 1250.00 1400.00 30
7698 BLAKE MANAGER 7839 1981-5-1 2850.00 30
7844 TURNER SALESMAN 7698 1981-9-8 1500.00 0.00 30
7900 JAMES CLERK 7698 1981-12-3 950.00 30
6 rows selected
--按照empno进行排序
SQL> select listagg(ename, ',') within group (order by empno) from emp where deptno=30;
LISTAGG(ENAME,',')WITHINGROUP(
------------------------------------------------------------
ALLEN , WARD , MARTIN , BLAKE , TURNER , JAMES在有分组条件下的listagg使用
如果要使用分组统计各个部门的所有员工列表。
SQL> select deptno, listagg(ename,' ,') within group (order by empno) from emp group by deptno;
DEPTNO LISTAGG(ENAME,',')WITHINGROUP(
------ -------------------------------------
10 CLARK ,KING ,MILLER
20 SMITH ,JONES ,SCOTT ,ADAMS ,FORD
30 ALLEN ,WARD ,MARTIN ,BLAKE ,TURNER ,JAMES使用over分组情况
如果要统计所有工作十年以上员工和他们相同部门的员工信息,就需要在listagg的基础上加入over分析函数子句。
SQL> select deptno, ename, listagg(ename, ' , ') within group (order by empno)
2 over (partition by deptno) as emp_list
3 from emp
4 where hiredate<=add_months(sysdate,-10*12);
DEPTNO ENAME EMP_LIST
------ --------- ------------------
10 CLARK CLARK , KING , MILLER
10 KING CLARK , KING , MILLER
10 MILLER CLARK , KING , MILLER
20 SMITH SMITH , JONES , SCOTT , ADAMS , FORD
20 JONES SMITH , JONES , SCOTT , ADAMS , FORD
20 SCOTT SMITH , JONES , SCOTT , ADAMS , FORD
20 ADAMS SMITH , JONES , SCOTT , ADAMS , FORD
20 FORD SMITH , JONES , SCOTT , ADAMS , FORD
30 ALLEN ALLEN , WARD , MARTIN , BLAKE , TURNER , JAMES
30 WARD ALLEN , WARD , MARTIN , BLAKE , TURNER , JAMES
30 MARTIN ALLEN , WARD , MARTIN , BLAKE , TURNER , JAMES
30 BLAKE ALLEN , WARD , MARTIN , BLAKE , TURNER , JAMES
30 TURNER ALLEN , WARD , MARTIN , BLAKE , TURNER , JAMES
30 JAMES ALLEN , WARD , MARTIN , BLAKE , TURNER , JAMES
14 rows selectedlag函数“取到上个月的销售额”
我们在进行销售数据统计汇总时候,经常遇到这样的需求:“对比上月(上季度同月份或者上年度同月份),我们的销售变化情况如何?”。我们的销售数据通常是对应单月信息,如下所示。
SQL> select * from sales_qual;
MONT QUALITIES PRICE
---------- ----------- ------
2011-01 1000 23.40
2011-02 1020 23.40
2011-03 1030 33.40
2011-04 1035 10.30如果要获取到之前月份的信息,没有SQL专门函数就意味着需要使用PL/SQL代码进行反复的迭代获取。现在,我们可以使用lag函数来轻易实现这个功能。

lag函数是一个典型的分析函数。它提供了在不使用自连接的情况下,访问多个数据行的能力。在返回多个结果行的时候,lag函数可以访问到向上特定offset偏移行的数据。
value_expr就是访问到向上数据行进行的操作。offset是返回偏移的函数,默认值为1。over中,可以定义内部分析的顺序列。
如果我们要获取到对应上个月的销售数据,SQL语句如下:
SQL> select mont, qualities, lag(qualities,1) over (order by mont) as "Next Month Qual"
2 from sales_qual
3 order by mont;
MONT QUALITIES Next Month Qual
---------- ----------- ---------------
2011-01 1000
2011-02 1020 1000
2011-03 1030 1020
2011-04 1035 1030之后对销量变化率的处理就方便了,可以进行增长率比对等操作。那么,如果是上一年度或者上一季度的数据呢?我们只需要调节offset,从1变化为12或者3就可以了。
最后,对ignore/respect nulls子句的使用是什么呢?该子句的作用是确定当value_expr表达式计算出的数值为空null的时候,该列如何进行计算。ignore nulls的作用就是忽略上面计算为空的行,采用上上行row的计算结果。respect nulls的作用是直接反映为null。respect nulls为默认值。
SQL> select * from sales_qual;
MONT QUALITIES PRICE
---------- ----------- ------
......
2011-04 1035 10.30
2011-05 12.30
2011-06
6 rows selected
SQL> select mont, qualities, lag(qualities, 1) ignore nulls over (order by mont) as "Next Month Qual"
2 from sales_qual
3 order by mont;
MONT QUALITIES Next Month Qual
---------- ----------- ---------------
......
2011-04 1035 1030
2011-05 1035
2011-06 1035
6 rows selected
SQL> select mont,qualities, lag(qualities,1) respect nulls over (order by mont) as "Next Month Qual"
2 from sales_qual
3 order by mont;
MONT QUALITIES Next Month Qual
---------- ----------- ---------------
......
2011-04 1035 1030
2011-05 1035
2011-06
6 rows selectedlead函数获取下一个月销售量
有lag的获取上个offset处理行的函数,就有lead函数处理下一个处理行的函数。lead函数实际上就是lag的逆向过程。
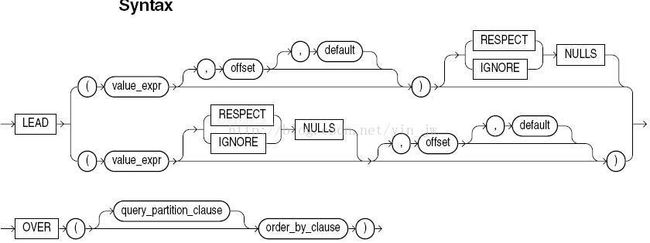
相关各项参数与lag函数的相同。区别就在于lead函数获取的是排序后结果集合的后offset数据行记录。
SQL> select mont,qualities, lead(qualities,1) over (order by mont) as "Next Month Qual"
2 from sales_qual
3 order by mont;
MONT QUALITIES Next Month Qual
---------- ----------- ---------------
2011-01 1000 1020
2011-02 1020 1030
2011-03 1030 1035
2011-04 1035