Scrapy中Spiders的用法
本文来自官方文档
包括Spiders的简介、一些参数的实例讲解和一些例子。
Spiders
Spider类定义了如何爬取某个(或某些)网站。包括了爬取的动作(例如:是否跟进链接)以及如何从网页的内容中提取结构化数据(爬取item)。 换句话说,Spider就是您定义爬取的动作及分析某个网页(或者是有些网页)的地方。
对spider来说,爬取的循环类似下文:
-
以初始的URL初始化Request,并设置回调函数。 当该request下载完毕并返回时,将生成response,并作为参数传给该回调函数。
spider中初始的request是通过调用
start_requests()来获取的。start_requests()读取start_urls中的URL, 并以 parse 为回调函数生成 Request 。 -
在回调函数内分析返回的(网页)内容,返回
Item对象或者Request或者一个包括二者的可迭代容器。 返回的Request对象之后会经过Scrapy处理,下载相应的内容,并调用设置的callback函数(函数可相同)。 -
在回调函数内,您可以使用 选择器(Selectors) (您也可以使用BeautifulSoup, lxml 或者您想用的任何解析器) 来分析网页内容,并根据分析的数据生成
item。 -
最后,由spider返回的item将被存到数据库(由某些 Item Pipeline 处理)或使用 Feed exports 存入到文件中。
虽然该循环对任何类型的spider都(多少)适用,但Scrapy仍然为了不同的需求提供了多种默认spider。 之后将讨论这些spider。
Spider参数
Spider是最简单的spider。每个其他的spider必须继承自该类(包括Scrapy自带的其他spider以及您自己编写的spider)。 Spider并没有提供什么特殊的功能。 其仅仅请求给定的 start_urls/start_requests ,并根据返回的结果(resulting responses)调用spider的 parse 方法。
name
定义spider名字的字符串(string)。spider的名字定义了Scrapy如何定位(并初始化)spider,所以其必须是唯一的。 不过您可以生成多个相同的spider实例(instance),这没有任何限制。 name是spider最重要的属性,而且是必须的。
如果该spider爬取单个网站(single domain),一个常见的做法是以该网站(domain)(加或不加 后缀 )来命名spider。 例如,如果spider爬取 mywebsite.com ,该spider通常会被命名为 mywebsite 。
allowed_domains
这是一个可选属性。包含了spider允许爬取的域名(domain)列表(list)。 当 OffsiteMiddleware 启用时, 域名不在列表中的URL不会被跟进。

比如之前的例子,如果yield生成的url不在allowed_domains的域名范围内则不会生效。
start_urls
URL列表。当没有制定特定的URL时,spider将从该列表中开始进行爬取。 因此,第一个被获取到的页面的URL将是该列表之一。 后续的URL将会从获取到的数据中提取。
custom_settings
运行此爬虫时将从项目范围配置中覆盖setting里面的设置。必须将其定义为类属性,因为在实例化之前更新了设置。
有关可用内置设置的列表,请参阅: 内置设定参考手册。
下面举例试验一下:
先新建一个“知乎”爬虫
scrapy genspider zhihu www.zhihu.com

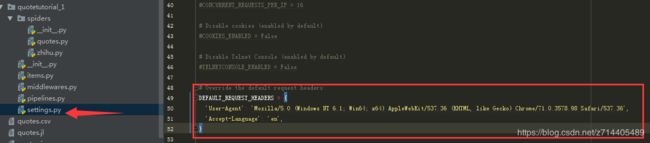
可以在settings.py中看到DEFAULT_REQUEST_HEADERS属性,我们先把它注释掉。
注释之后的爬虫是没有默认请求头的。
现在直接在命令行执行
scrapy crawl zhihu
由于现在的请求没有请求头,对于知乎网站来说会返回400错误码:

现在我们把注释取消,重新运行爬虫:

可以看到运行成功了(得到了200状态码)
现在我们在ZhihuSpider这个类中定义custom_settings属性,看看是否能把settings覆盖掉,这里以字典的形式来定义custom_settings,将settings里面的一个变量在这里作为一个键,并且将User-Agent设置为空:
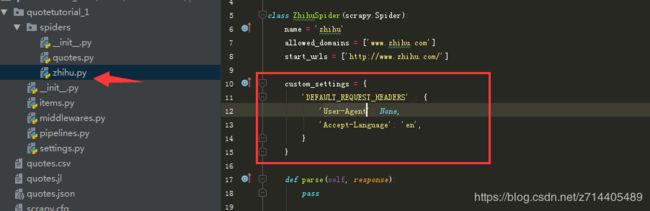
重新运行,可以看到与第一次运行如出一辙,放回了400状态码,这说明我们的覆盖生效了。
以上例子说明,当执行某个爬虫时需要进行特定的设置,可以在custom_settings属性中进行自定义,以此来覆盖掉全局性的设置。
from_crawler(crawler, *args, **kwargs)
这是Scrapy用于创建爬虫的类方法。
我们可能不需要直接覆盖它,因为默认实现充当__init __()方法的代理,使用给定参数args和命名参数kwargs调用它。
尽管如此,此方法在新实例中设置了crawler和settings属性,因此可以在spider的代码中稍后访问它们。我们经常用它来获得一些全局配置的实例。
start_requests()
该方法必须返回一个可迭代对象(iterable)。该对象包含了spider用于爬取的第一个Request。
当spider启动爬取并且未制定URL时,该方法被调用。 当指定了URL时,make_requests_from_url() 将被调用来创建Request对象。 该方法仅仅会被Scrapy调用一次,因此您可以将其实现为生成器。
该方法的默认实现是使用 start_urls 的url生成Request。
如果您想要修改最初爬取某个网站的Request对象,您可以重写(override)该方法。 例如,如果您需要在启动时以POST登录某个网站,你可以这么写:
def start_requests(self):
return [scrapy.FormRequest("http://www.example.com/login",
formdata={'user': 'john', 'pass': 'secret'},
callback=self.logged_in)]
def logged_in(self, response):
# here you would extract links to follow and return Requests for
# each of them, with another callback
pass
我们新建一个爬虫(之前提到的常用的测试网站)来演示一下:

运行爬虫,可以发现start_requests()方法通过 start_urls 的url生成了一个GET请求的对象。

我们在url后面加上post看看能否把请求方式改成post:
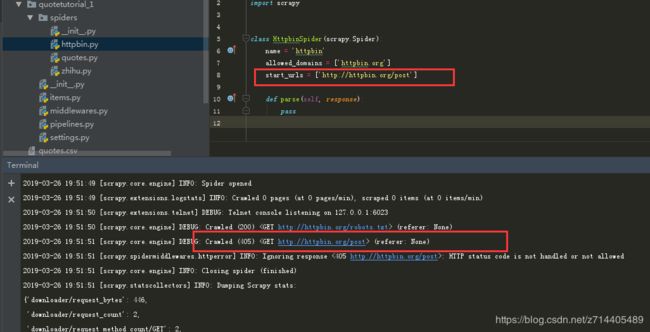
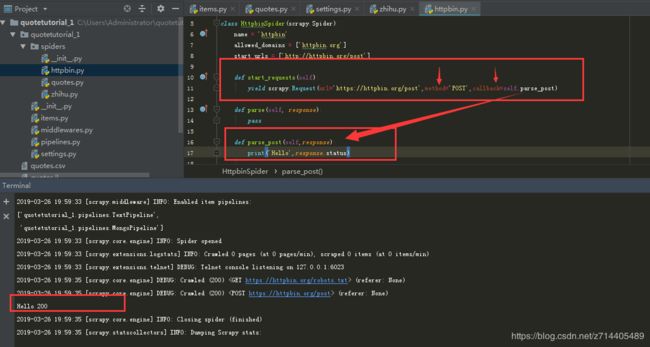
可以看到抛出了405错误代码,因为start_requests()默认是用GET方式请求的,所以要想用POST方式请求,就必须要改写start_requests()方法:
这里将第一次请求的方法改为POST,并且将回调函数指定为一个打印出“hello 状态码”的方法,运行后可以看到成功实现了。
make_requests_from_url(url)
该方法接受一个URL并返回用于爬取的 Request 对象。 该方法在初始化request时被 start_requests() 调用,也被用于转化url为request。
默认未被复写(overridden)的情况下,该方法返回的Request对象中, parse() 作为回调函数,dont_filter参数也被设置为开启。
下面依然举例演示一下,新建一个爬虫用于爬取百度首页:
scrapy genspider baidu www.baidu.com
修改:
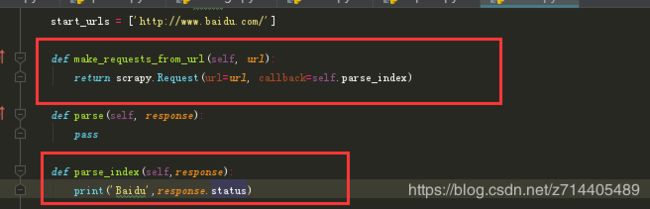
运行后报错:
不推荐使用Spider.make_requests_from_url方法; 它将不会在未来的Scrapy版本中调用。
好吧,那就忽略掉吧…
parse(response)
当response没有指定回调函数时,该方法是Scrapy处理下载的response的默认方法。
parse 负责处理response并返回处理的数据以及(/或)跟进的URL。 Spider 对其他的Request的回调函数也有相同的要求。
该方法及其他的Request回调函数必须返回一个包含 Request 及(或) Item 的可迭代的对象
log(message[, level, component])
使用 scrapy.log.msg() 方法记录(log)message。 log中自动带上该spider的 name 属性。 此外可以自定义更多的数据被纪录。
self.logger.info(response.status)
Spider样例
让我们来看一个例子:
这个例子里, start_urls中定义了多个url。
import scrapy
class MySpider(scrapy.Spider):
name = 'example.com'
allowed_domains = ['example.com']
start_urls = [
'http://www.example.com/1.html',
'http://www.example.com/2.html',
'http://www.example.com/3.html',
]
def parse(self, response):
self.log('A response from %s just arrived!' % response.url)
再看看源码中如何使用它们:
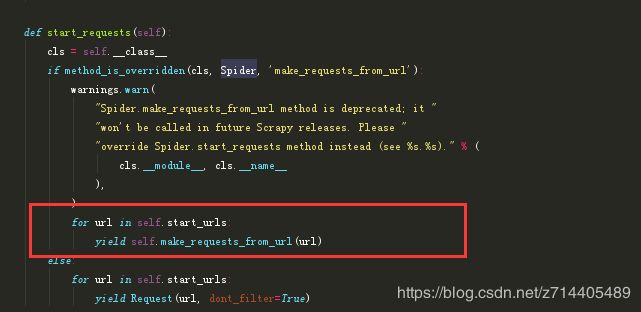
可以看到在start_requests函数中,遍历了这个列表。
另一个在单个回调函数中返回多个Request以及Item的例子:
import scrapy
from myproject.items import MyItem
class MySpider(scrapy.Spider):
name = 'example.com'
allowed_domains = ['example.com']
start_urls = [
'http://www.example.com/1.html',
'http://www.example.com/2.html',
'http://www.example.com/3.html',
]
def parse(self, response):
sel = scrapy.Selector(response)
for h3 in response.xpath('//h3').extract():
yield MyItem(title=h3)
for url in response.xpath('//a/@href').extract():
yield scrapy.Request(url, callback=self.parse)
更多信息请参考官方文档