前言
如上一篇所述,这篇文章讲一讲建模的后续:如何提高benchmark模型性能。
先说一下结论:在获得更好的预测模型这件事上,我失败了。
对,没错,我没有成功提高模型预测率。无论是处理非平衡数据,特征归一化,独热编码,还是运用不同算法,我都没办法提高模型预测率,它们的结果要么和benchmark模型差不多,要么更差。
这其中的原因可能有:
- 特征工程做得不好。老实说,由于UCI的这个数据集相当完整(足够多的变量,没有缺失值,没有异常值),在特征工程方面我没有太多的想法。
- 算法选择不当或调参不当。在这几天的建模实验里,除了对
sklearn本身不熟悉之外,我发现我的理论基础有所欠缺,所以在用某种算法的时候,面对一箩筐的参数,常常心有余而力不足。接下来的几周里,我打算好好回顾算法,巩固理论基础。
但除去这些,还是有一些有趣的发现。下面我会具体描述我在建模过程中做过的尝试,以及从中得到的发现。
先来回顾一下banchmark模型
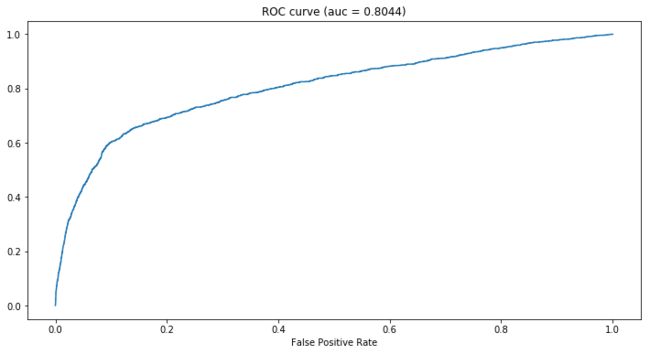
这个banchmark模型用的是XGBoost,AUC值为0.8044,模型整体性能不错,但从ROC曲线可以看到,假阳性率(FPR)低的时候,对应的真阳性率(TPR)不高,比如0.2的FPR对应的TPR不到0.7,说明模型没有能很好地捕捉到 class = 1(y = yes)的pattern。
一个可能的原因是数据的非平衡性,即目标变量y下的两个类目(yes和no)占比不均:y = yes 的客户只占了总客户的11.27%,不到三分之一。大多数现有算法不能很好地处理非平衡数据。
基于此,我首先尝试通过sampling来解决非平衡问题。
数据非平衡问题 Imbalanced Data
处理非平衡问题一般有以下几种方式:
- 什么也不做
- 通过某些sampling方法使数据变得平衡
- 在算法的构造、选取和调试上寻求解决方法
我在方式2上进行了尝试,具体方法有:
- Under-sampling:random under-sapling
- Over-sampling:SMOTE
- Combined method:SMOTEENN
实现sampling的python封装是imbalanced-learn,具体可以看它的GitHub。
通过上述这三种sampling方法,我构造了三个不同的训练集,并使用XGBoost分别对它们进行训练,训练结果如下。
1. Random Under-sampling
Under-sampling的思路是,通过减少多数类(数量占比大的class)的数量,使得训练集中的两个类别在数量上大体相等。
因为我的数据集有4w+数据,即使是用under-sampling,所剩下的数据在数量上也是比较可观的。如果数据量原本就很少,就不要在用under-sampling啦。

蓝色是使用了under-sampling数据的训练结果,橙色是benchmark模型。很明显,under-sampling无功无过,几乎对结果没什么影响(AUC稍微降低至0.8025)。
如果说在数据量足够的情况下,做under-sampling之后,其返回的训练结果没什么差异,那么对于大数据来说,是不是能用under-sampling数据来训练模型,从而提高计算效率呢?
2. SMOTE
SMOTE全称为Synthetic Minority Oversampling Technique,其思路是通过某种特定方式合成新的少数类样本,使得训练集中的两个类别在数量上大体相等。
合成的策略是,对每个少数类样本a,从它的最近邻中随机选一个样本b,然后在a、b之间的连线上随机选一点作为新合成的少数类样本。
我的数据量并没有上10w,所以就算做over-sampling,模型的训练速度也没有很慢。对于大数据来说,做over-sampling要慎重。
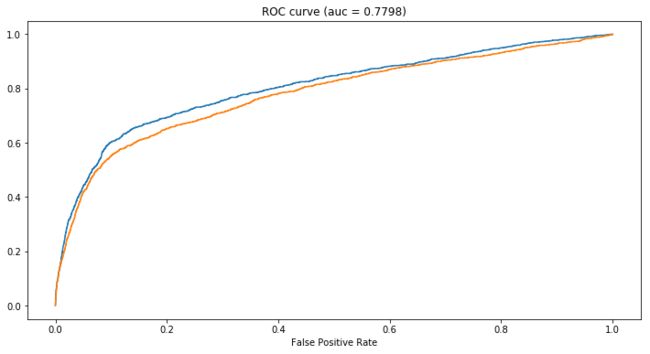
橙色是使用了SMOTE数据的训练结果,蓝色是benchmark模型。很明显模型预测性变差了=。=
原因可能是通过SMOTE生成的数据放大了原始数据中不必要的noise,导致模型过拟合(over-fitting)。用XGBoost的时候我用了watchlist,训练的时候训练集和验证集的AUC差别很大,前者有0.95左右,而后者只有0.78左右。(但无论我怎么调参,始终都是过拟合……)
顺带一提,我一开始是对训练集和验证集都做了SMOTE,所以训练的时候二者的AUC都很高也很接近,但后来发现这样做并没有什么意义(也很蠢……),因为测试集的AUC其实很差。后来改成只对训练集做SMOTE,结果则变成验证集和测试集的AUC很接近(也都很差)。但在同等训练条件下(同算法,同参数),后者的结果比前者要稍微好一点。
3. SMOTEENN
SMOTEENN是SMOTE和ENN(Edited Nearest Neighbours)的结合,前者是over-sampling过程,后者是under-sampling过程。
SMOTEENN的思路是通过SMOTE合成新的少数类样本,然后通过ENN清洗SMOTE过程中产生的噪点(noisy samples)。

橙色是使用了SMOTEENN数据的训练结果,蓝色是benchmark模型。同样的,前者的表现差于后者。
但值得注意的是,SMOTEENN数据的训练结果比SMOTE数据的要好,这侧面说明了SMOTE产生了噪点,使得模型过拟合。
小结
对于此次分析中用到的数据集,三种sampling方法都没能提高模型性能,而在模型表现上,Random Under-sampling优于SMOTEENN,SMOTEENN优于SMOTE。
特征归一化与独热编码
之前有说到,数据不同级可能会对算法的学习效果有影响,所以训练模型之前,特征归一化(scaling)是一个值得尝试的步骤。
此外,不少模型都不能很好地处理类别变量(categorical variable)。如果简单地把类别变量用整数表示(比如在性别变量中,用1表示男性,2表示女性),则可能使得算法将类别变量视作interval变量,从而产生bias。所以在建模之前,需要处理类别变量。一个常用的方法是独热编码(one-hot encoding)。
(顺带一提,我用sklearn下的算法训练模型的时候,category型数据可以直接输入,但XGBoost不可以,不知道是算法本身可以处理category,还是sklearn在跑模型前会自动把category转换成int。)
在这一部分,我构造了三个不同的数据集来训练XGBoost模型:
- 数值型变量归一化
- 类别变量独热编码
- 数值型变量归一化 + 类别变量独热编码
目的是为了看看特征归一化和独热编码对XGBoost有什么影响。
对了,由于上一节中,sampling之后的数据并没能提高模型性能,所以这部分我依旧用原数据集来做。
结果如下:
三种情形下的ROC曲线我就不放了,因为都和benchmark模型的差不多(曲线基本重合),说明XGBoost还是比较稳健的,嗯……
| 数据 | AUC |
|---|---|
| 原数据集 | 0.8044 |
| 数值型变量归一化 | 0.8024 |
| 类别变量独热编码 | 0.8047 |
| 数值型变量归一化 + 类别变量独热编码 | 0.8048 |
上表是原始数据集下和上述三种情形下对应的XGBoost模型在测试集上的AUC值。
可以看到,四种情形下的XGBoost模型的AUC值很接近,硬要说的话,归一化和独热编码都做之后的模型表现最好,且综合比较,独热编码比归一化的影响要大。
其他算法
除了XGBoost,分类问题中还有很多算法可以选择。我简单跑了一下LightGBM, GBDT,Random Forest和Logistic Regression。
和XGBoost一样,我并没有很仔细地调参,一来是我还不熟悉sklearn,二来是我的理论基础还不够以至于心有余而力不足,三来是想看看相似情况下(都没有好好调参的情况下=。=)哪一种算法表现更好。
另外,因为懒,这部分我用的原始数据集(即没做归一化也没做独热编码)。
结果:
这部分的ROC曲线我也不放了,因为还是都和benchmark模型的差不多,曲线基本重合。
AUC值如下。
| 算法 | AUC |
|---|---|
| XGBoost | 0.8044 |
| LightGBM | 0.8033 |
| GBDT | 0.8071 |
| Random Forest | 0.8029 |
| Logistic Regression | 0.7842 |
可以看到LR的表现最差,GBDT表现最好,其余的差不多。
值得一提的是,在训练效率上,LightGBM最快,XGBoost其次,GBDT最慢。
LightGBM是微软去年发布的一个GBM改进算法,号称比XGBoost更高效更轻便。亲自试过之后的感觉是:名不虚传。我估计在可预见的不久的将来,LightGBM会取代XGBoost的地位,毕竟在效果差不多的前提下,前者比后者要快,占的内存也更少。
但有一点不得不提,LightGBM的参数非常多(大概是XGBoost的两倍吧),学习门槛还是比较高的。(我打算回头再好好钻研一下这些参数。)
最后想再回过头来说一下Logistic Regression。作为广义线性模型的一员,LR还是比较神奇的,虽然很多时候LR都不是最优模型,但在数据质量不高的情况下,LR的稳健性就凸显出来了。
跑完上述模型之后,突然就想看看归一化和独热编码对LR的影响:
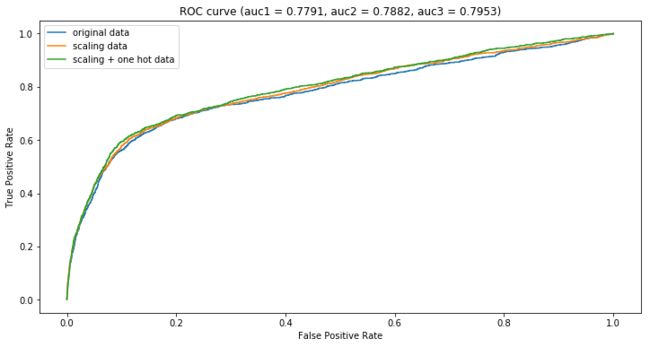
可以看到,无论是单独做归一化,单独做独热编码,还是二者都做,模型的ROC曲线都差不多且性能都比benchmark模型要差一些。但值得注意的是,单就LR来说,做不做归一化、独热编码,影响还是比较大的。
另外,这次我没做WoE编码,以后有时间想把这一块补上,很好奇结合了WoE之后的LR在性能上会不会有明显的提高:)