自定义 hadoop MapReduce InputFormat 切分输入文件
实际的遇到的问题——看数据:
|
|
cookieId time url 2 12:12:34 2_hao123 3 09:10:34 3_baidu 1 15:02:41 1_google 3 22:11:34 3_sougou 1 19:10:34 1_baidu 2 15:02:41 2_google 1 12:12:34 1_hao123 3 23:10:34 3_soso 2 05:02:41 2_google
结果: ------------------------------------------------ 1 12:12:34 1_hao123 1 15:02:41 1_google 1 19:10:34 1_baidu ------------------------------------------------ 2 05:02:41 2_google 2 12:12:34 2_hao123 2 15:02:41 2_google ------------------------------------------------ 3 09:10:34 3_baidu 3 22:11:34 3_sougou 3 23:10:34 3_soso |
新问题描述:假如我需要按 cookieId和 cookieId&time 的组合进行分析呢?此时最好的办法是自定义 InputFormat,让 mapreduce 一次读取一个 cookieId 下的所有记录,然后再按 time 进行切分 session,逻辑伪码如下:
for OneSplit inMyInputFormat.getSplit() // OneSplit 是某个 cookieId下的所有记录
for sessionin OneSplit // session 是按 time 把 OneSplit 进行了二次分割
forline in session // line 是 session中的每条记录,对应原始日志的某条记录
1、原理:
InputFormat是MapReduce中一个很常用的概念,它在程序的运行中到底起到了什么作用呢?
InputFormat其实是一个接口,包含了两个方法:
public interface InputFormat
InputSplit[] getSplits(JobConf job, int numSplits) throwsIOException;
RecordReader
JobConf job,
Reporter reporter) throws IOException;
}
这两个方法有分别完成着以下工作:
方法 getSplits将输入数据切分成splits,splits的个数即为maptasks的个数,splits的大小默认为块大小,即64M
方法 getRecordReader 将每个 split 解析成records, 再依次将record解析成
也就是说 InputFormat完成以下工作:
InputFile --> splits -->
系统常用的 InputFormat 又有哪些呢?
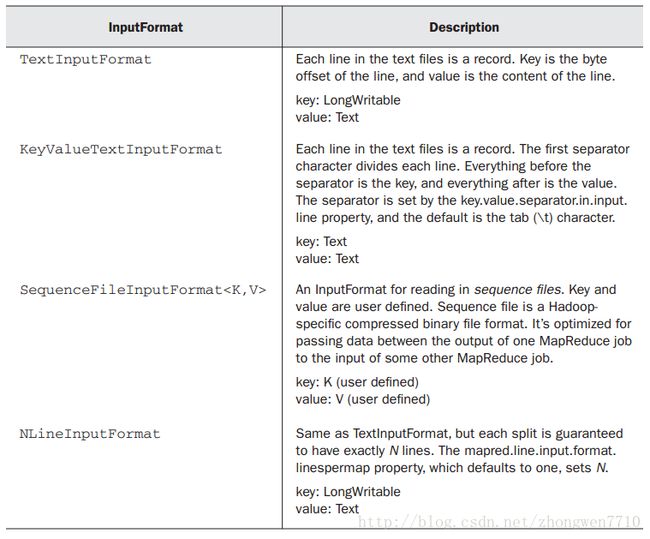
其中Text InputFormat便是最常用的,它的
然而系统所提供的这几种固定的将 InputFile转换为
InputFile解析为
InputFormat(interface),FileInputFormat(abstract class), TextInputFormat(class),
RecordReader (interface), Line RecordReader(class)的关系
FileInputFormat implements InputFormat
TextInputFormat extends FileInputFormat
TextInputFormat RecordReader calls LineRecordReader
解析:public RecordReader
InputSplit split,TaskAttemptContext context) {
return new TrackRecordReader();
}
LineRecordReaderimplements RecordReader
对于InputFormat接口,上面已经有详细的描述,再看看 FileInputFormat,它实现了 InputFormat接口中的 getSplits方法,而将 getRecordReader与isSplitable留给具体类(如 TextInputFormat )实现, isSplitable方法通常不用修改,所以只需要在自定义的 InputFormat中实现getRecordReader方法即可,而该方法的核心是调用 Line RecordReader(即由LineRecorderReader类来实现 " 将每个s plit解析成records, 再依次将record解析成
public interfaceRecordReader
boolean next(Kkey, V value) throws IOException;
K createKey();
V createValue();
long getPos() throws IOException;
public void close() throws IOException;
float getProgress() throws IOException;
}
因此自定义InputFormat的核心是自定义一个实现接口RecordReader类似于LineRecordReader的类,该类的核心也正是重写接口RecordReader中的几大方法,
定义一个InputFormat的核心是定义一个类似于LineRecordReader的,自己的RecordReader
2、代码:
package hunanuniversity.guanxiangqing.hadoopInputformat;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
importorg.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.io.compress.CompressionCodecFactory;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.JobContext;
import org.apache.hadoop.mapreduce.RecordReader;
importorg.apache.hadoop.mapreduce.TaskAttemptContext;
importorg.apache.hadoop.mapreduce.lib.input.FileInputFormat;
public class TrackInputFormat extendsFileInputFormat
@SuppressWarnings("deprecation")
@Override
publicRecordReader
InputSplit split,TaskAttemptContext context) {
return new TrackRecordReader();
}
@Override
protected boolean isSplitable(JobContext context, Path file) {
CompressionCodec codec = newCompressionCodecFactory(
context.getConfiguration()).getCodec(file);
return codec ==null;
}
}
packagehunanuniversity.guanxiangqing.hadoopInputformat;
import java.io.IOException;
import java.io.InputStream;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
importorg.apache.hadoop.io.compress.CompressionCodec;
importorg.apache.hadoop.io.compress.CompressionCodecFactory;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.RecordReader;
importorg.apache.hadoop.mapreduce.TaskAttemptContext;
importorg.apache.hadoop.mapreduce.lib.input.FileSplit;
import com.sun.org.apache.commons.logging.Log;
importcom.sun.org.apache.commons.logging.LogFactory;
/**
* Treats keys as offset in file and value asline.
*
* @deprecated Use
* {@linkorg.apache.hadoop.mapreduce.lib.input.LineRecordReader}
* instead.
*/
public class TrackRecordReader extends RecordReader
private static final Log LOG =LogFactory.getLog(TrackRecordReader.class);
private CompressionCodecFactorycompressionCodecs = null;
private long start;
private long pos;
private long end;
private NewLineReaderin;
private int maxLineLength;
private LongWritablekey = null;
private Textvalue = null;
//----------------------
// 行分隔符,即一条记录的分隔符
private byte[] separator = "END\n".getBytes();
//--------------------
public void initialize(InputSplit genericSplit,TaskAttemptContext context)
throws IOException{
FileSplit split = (FileSplit)genericSplit;
Configuration job =context.getConfiguration();
this.maxLineLength = job.getInt("mapred.linerecordreader.maxlength",
Integer.MAX_VALUE);
start = split.getStart();
end = start + split.getLength();
final Path file =split.getPath();
compressionCodecs = newCompressionCodecFactory(job);
finalCompressionCodec codec =compressionCodecs.getCodec(file);
FileSystem fs = file.getFileSystem(job);
FSDataInputStream fileIn =fs.open(split.getPath());
booleanskipFirstLine =false;
if (codec !=null) {
in = new NewLineReader(codec.createInputStream(fileIn), job);
end = Long.MAX_VALUE;
} else {
if (start != 0) {
skipFirstLine = true;
this.start -=separator.length;//
// --start;
fileIn.seek(start);
}
in = new NewLineReader(fileIn, job);
}
if(skipFirstLine) {// skip firstline and re-establish "start".
start += in.readLine(new Text(), 0, (int) Math.min(
(long) Integer.MAX_VALUE,end - start));
}
this.pos =start;
}
public boolean nextKeyValue() throws IOException{
if (key ==null) {
key = new LongWritable();
}
key.set(pos);
if (value ==null) {
value = new Text();
}
int newSize =0;
while (pos <end) {
newSize = in.readLine(value,maxLineLength, Math.max((int) Math
.min(Integer.MAX_VALUE,end - pos),maxLineLength));
if (newSize ==0) {
break;
}
pos += newSize;
if (newSize<maxLineLength) {
break;
}
LOG.info("Skipped line of size " + newSize +" at pos "
+ (pos -newSize));
}
if (newSize ==0) {
key = null;
value = null;
return false;
} else {
return true;
}
}
@Override
public LongWritable getCurrentKey() {
returnkey;
}
@Override
public Text getCurrentValue() {
returnvalue;
}
/**
* Getthe progress within the split
*/
public float getProgress() {
if (start ==end) {
return 0.0f;
} else {
return Math.min(1.0f,(pos -start) / (float) (end -start));
}
}
public synchronized void close() throws IOException{
if (in !=null) {
in.close();
}
}
public class NewLineReader {
private static final int DEFAULT_BUFFER_SIZE = 64 * 1024;
private int bufferSize = DEFAULT_BUFFER_SIZE;
private InputStreamin;
private byte[] buffer;
private int bufferLength = 0;
private int bufferPosn = 0;
publicNewLineReader(InputStream in) {
this(in,DEFAULT_BUFFER_SIZE);
}
publicNewLineReader(InputStream in,int bufferSize) {
this.in = in;
this.bufferSize = bufferSize;
this.buffer =new byte[this.bufferSize];
}
publicNewLineReader(InputStream in, Configuration conf)
throws IOException{
this(in,conf.getInt("io.file.buffer.size",DEFAULT_BUFFER_SIZE));
}
public void close() throws IOException {
in.close();
}
public int readLine(Text str, intmaxLineLength,int maxBytesToConsume)
throws IOException{
str.clear();
Text record = new Text();
int txtLength =0;
longbytesConsumed = 0L;
boolean newline =false;
int sepPosn =0;
do {
// 已经读到buffer的末尾了,读下一个buffer
if (this.bufferPosn >=this.bufferLength) {
bufferPosn = 0;
bufferLength =in.read(buffer);
// 读到文件末尾了,则跳出,进行下一个文件的读取
if (bufferLength <= 0) {
break;
}
}
int startPosn =this.bufferPosn;
for (;bufferPosn < bufferLength;bufferPosn++) {
// 处理上一个buffer的尾巴被切成了两半的分隔符(如果分隔符中重复字符过多在这里会有问题)
if (sepPosn > 0 &&buffer[bufferPosn] !=separator[sepPosn]) {
sepPosn = 0;
}
// 遇到行分隔符的第一个字符
if (buffer[bufferPosn] ==separator[sepPosn]) {
bufferPosn++;
int i = 0;
// 判断接下来的字符是否也是行分隔符中的字符
for (++sepPosn;sepPosn <separator.length; i++, sepPosn++) {
// buffer的最后刚好是分隔符,且分隔符被不幸地切成了两半
if (bufferPosn + i >=bufferLength) {
bufferPosn += i - 1;
break;
}
// 一旦其中有一个字符不相同,就判定为不是分隔符
if (this.buffer[this.bufferPosn + i] != separator[sepPosn]) {
sepPosn = 0;
break;
}
}
// 的确遇到了行分隔符
if (sepPosn ==separator.length) {
bufferPosn += i;
newline = true;
sepPosn = 0;
break;
}
}
}
int readLength=this.bufferPosn - startPosn;
bytesConsumed += readLength;
// 行分隔符不放入块中
if (readLength> maxLineLength - txtLength) {
readLength = maxLineLength -txtLength;
}
if (readLength> 0) {
record.append(this.buffer, startPosn, readLength);
txtLength += readLength;
// 去掉记录的分隔符
if (newline) {
str.set(record.getBytes(),0, record.getLength()
- separator.length);
}
}
} while (!newline&& (bytesConsumed < maxBytesToConsume));
if(bytesConsumed > (long) Integer.MAX_VALUE) {
throw new IOException("Toomany bytes before newline: "
+ bytesConsumed);
}
return (int) bytesConsumed;
}
public int readLine(Text str, intmaxLineLength)throws IOException {
returnreadLine(str, maxLineLength, Integer.MAX_VALUE);
}
public int readLine(Text str) throws IOException{
returnreadLine(str, Integer.MAX_VALUE, Integer.MAX_VALUE);
}
}
}
package hunanuniversity.guanxiangqing.hadoopInputformat;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
importorg.apache.hadoop.mapreduce.lib.input.FileInputFormat;
public class TestMyInputFormat {
public static class MapperClass extends Mapper
public void map(LongWritable key, Text value, Context context) throws IOException,
InterruptedException {
System.out.println("key:\t " + key);
System.out.println("value:\t " + value);
System.out.println("-------------------------");
}
}
public static void main(String[] args)throws IOException, InterruptedException,ClassNotFoundException {
Configuration conf = new Configuration();
Path outPath = new Path("/hive/11");
FileSystem.get(conf).delete(outPath,true);
Job job = new Job(conf,"TestMyInputFormat");
job.setInputFormatClass(TrackInputFormat.class);
job.setJarByClass(TestMyInputFormat.class);
job.setMapperClass(TestMyInputFormat.MapperClass.class);
job.setNumReduceTasks(0);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
FileInputFormat.addInputPath(job,new Path(args[0]));
org.apache.hadoop.mapreduce.lib.output.FileOutputFormat.setOutputPath(job,outPath);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
3、测试数据:
cookieId time url cookieOverFlag
| 1 2 3 4 5 6 7 8 9 |
1 a 1_hao123 1 a 1_baidu 1 b 1_google 2END 2 c 2_google 2 c 2_hao123 2 c 2_google 1END 3 a 3_baidu 3 a 3_sougou 3 b 3_soso 2END |
4、结果:
|
|
key: 0 value: 1 a 1_hao123 1 a 1_baidu 1 b 1_google 2 ------------------------- key: 47 value: 2 c 2_google 2 c 2_hao123 2 c 2_google 1 ------------------------- key: 96 value: 3 a 3_baidu 3 a 3_sougou 3 b 3_soso 2 ------------------------- |
Reference:
自定义hadoop map/reduce输入文件切割InputFormat
http://hi.baidu.com/lzpsky/item/0d9d84c05afb43ba0c0a7b27
MapReduce高级编程之自定义InputFormat
http://datamining.xmu.edu.cn/bbs/home.php?mod=space&uid=91&do=blog&id=190
http://irwenqiang.iteye.com/blog/1448164
http://my.oschina.net/leejun2005/blog/133424