C++-----STL与泛型编程(1)
此系列博客,图片文字观点均是来自侯捷老师讲义课程,仅作为学习用途。
无意在网上看到侯捷老师的课程,第一眼看见就决定有时间一定要看看。这一部分的东西主要是侯捷老师视频和课件整理而来,让自己对C++和STL有一个比较深入的理解。使用一个东西,却不明白它的道理,这不高明。虽然这句话在别的地方不一定适用,但是对于程序员而言,知其然很重要,知其所以然也很重要。
1、命名空间
命名空间是可以将你写的一些类、函数、模板等等再进行一下封装。命名空间防止名字冲突提供了更加可控的机制,命名空间分割了全局命名的空间,其中每个命名空间都是一个作用域,通过在某个命名空间中定义库的名字,库的作者以及用户可以避免全局名字固有的限制。
2、STL体系结构基础介绍
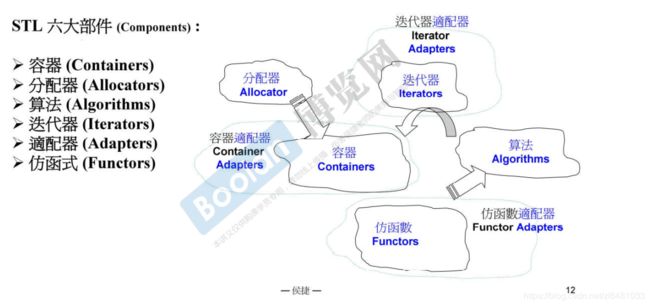
Container(容器) :各种基本数据结构
Adapter(适配器): 可改变containers、Iterators或Function object接口的一种组件
Algorithm(算法) :各种基本算法如sort、search…等
Iterator(迭代器) :连接containers和algorithms
Function object(函数对象) :函数对象(function object)也称为仿函数(functor)。一个行为类似函数的对象,它可以没有参数,也可以带有若干参数。
Allocator(分配器):负责空间配置与管理。

第11行一开始使用了容器,之后使用了分配器,但是一般使用过程中不使用,系统会默认使用分配器。这里尖括号代表使用的模板。第13行使用了一个算法count_if(计算符合条件的数的数量),这个算法的前两个参数,返回迭代器,第三个参数使用了仿函数(less)和仿函数的适配器(bind2nd、not1)。14行是一个判断条件,返回真或假。
3、复杂度
常见的复杂度:

4、范围for循环
C++11提供了一个很好的遍历容器的语法。

5、容器-结构与分析
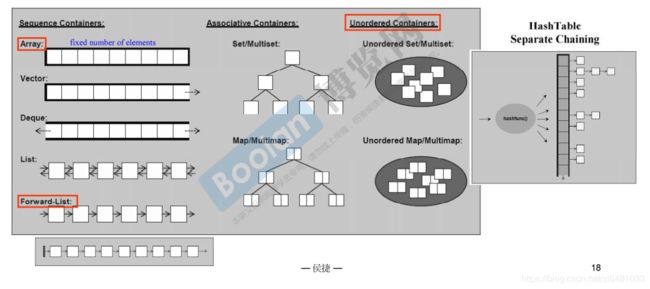
容器主要分为序列式容器和关联式容器。最右边的unordered containers是一种不定顺序的容器,底层是用哈希表实现的。
Array是数组,vector是将数组封装可以向后扩充。deque(音同代课)双向队列可以向两边扩充。list双向链表。Forword-List单向链表。
set,map,底层是用红黑树实现的,红黑树是一种和AVL平衡树很像的树。set是关键字和键值一样的集合,map是一个关键字对应一个键值。mutiset和mutimap是可以放重复元素的,但是set和map是不可以的。map和set都是有序的。
unordered_set、unordered_map底层是由哈希表实现的。
6、容器分类以及各种测试
6.1 array固定数组
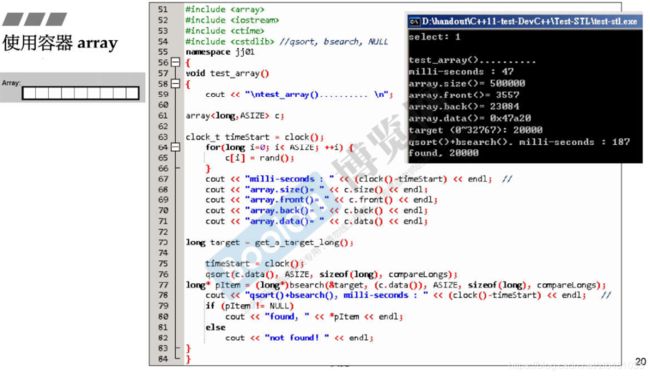
array是一个固定大小额数组,所以需要在一开始指定其大小,尖括号之内的第二个元素是其大小。
6.2 vector
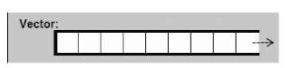
vector是一个可变的数组序列容器,它会自动扩容,每次扩容是之前的两倍,扩容时是在另外一个地址空间上找一个两倍大小的地方,再将原来的元素复制过去,这个过程是比较耗时的。插入只能从后面插入元素。
6.3 list

list是一个双向链表。list里有一个max_size()成员函数,含义是能存放的最大元素。 当一个容器含有自己的sort()函数,这个函数一般比标准库的sort更加高效。可以从前后插入。
6.4 forward_list

单向链表,只能从后面插入元素,不提供size()函数,提供可以取得第一个元素front(),不提供最后一个元素的成员函数。
6.5 deque
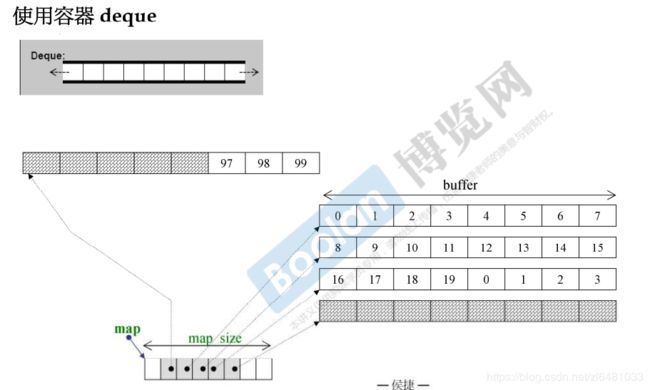
双向队列,双端队列是具有动态大小的序列容器,可以在两端(前端或后端)扩展或收缩。实际的存储结构是上图下部分,它其实是分段连续的,但是在使用上会让使用者感觉是连续的。双端队列的元素可以分散在不同的块中存储,容器在内部保存必要的信息,以便在恒定时间内通过统一的顺序接口(通过迭代器)直接访问其任何元素。每次扩充是一个buf。自身没有排序函数,需要使用标准库的sort函数。
6.6 stack
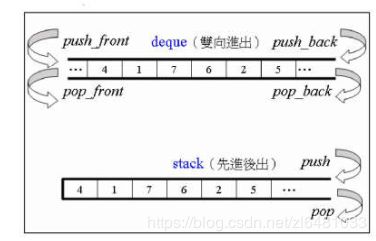
stack(栈),专门设计用于在LIFO上下文中操作(后进先出),其中元素仅从容器的一端插入和提取。源码中其实是用deque实现的。stack和queue由于没有自己的数据结构,所以一般把它们两个叫作容器适配器。
6.7 queue

queue 是一种容器适配器,专门设计用于在FIFO上下文中操作(先进先出),其中元素插入容器的一端并从另一端提取。源码中也是用deque实现的。
以上的容器都是序列式容器,查找起来会比较慢,以下的容器是关联式容器,它们的查找基本是不需要1ms就可以得到。
6.8 multiset
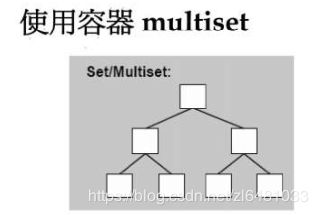
其key就是其value。其实现是使用红黑树实现的。插入元素使用insert()。里面可以存放相同元素。它含有自己的find函数,查找很快。
6.9 multimap

其内部结构也是红黑树,每一个key对应一个value,查找的时候使用key来查找value。其插入时需要将key和value组织起来,假设定义为multimap
6.10 unordered_multiset
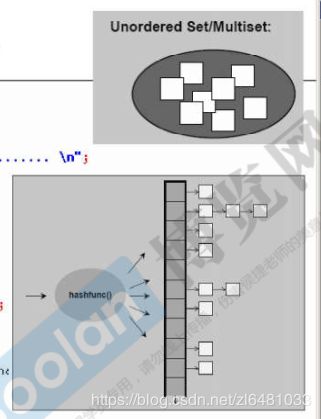
unordered_multiset底层是用哈希表实现的。hashtable内部有很多个bucket,每个bucket可以存放多个元素。这几个元素的哈希值是相同的,所以存放在同一个bucket中。bucket的值总是大于元素的个数。当相等的时候会自动扩容。是不按特定顺序存储元素的容器,允许基于其值快速检索单个元素,非常类似于unordered_set容器,但允许不同元素具有等效值。自带find函数,查找很快。
6.11 unordered_multimap
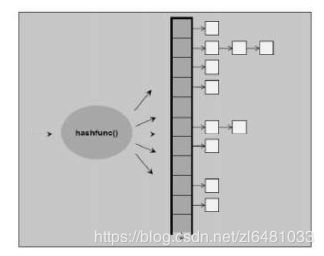

无序multimaps是关联容器,它存储由key和value组合形成的元素,类似于unordered_map容器,但允许不同的元素具有等效键。底层实现也是哈希表。很多东西和上面的是一样的。
6.12 set

set和multiset的区别是set里面不能出现重复元素,而multiset里面可以存放相同元素。底层实现是红黑树。
6.13 map
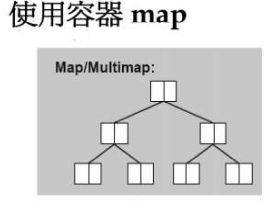
map和multimap的区别和上面一样,map里面不能出现重复元素,而multimap可以存放相同元素。multimap不可以使用[]进行插入操作,但是map可以。
6.14 unordered_set
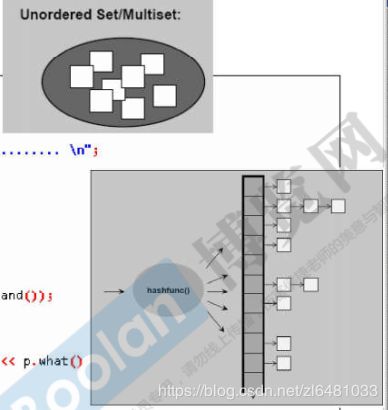
和unordered_multiset很像,区别还是一个可以存放相同元素,一个不可以存放相同元素。底层是用哈希表实现。
6.15 unordered_map

和unordered_multimap很像,区别也是一个可以存放相同元素一个不可以,底层是用哈希表实现。
7、使用分配器
容器的参数一般还会有一个参数,叫作分配器(allocator),但是这个参数一般是省略的。分配器的作用一般是为容器分配内存。我们一般不会直接去使用分配器,分配器的使用需要注意的问题比较多,在程序中我们一般直接适用容器,如果需要小量的内存,可以使用new或者malloc。