立体图像的深度估计(3D感知)
硬件方案:

结构光与TOF究竟有何区别
双目方案有多种结构:比如垂直双目结构、水平双目结构、单摄像机平移结构等。通常情况下,在实验与实际应用中,使用得最为广泛的是水平双目结构平台。
双目系统中实现原理是怎么样的?
从图片中的一个点p(u,v)怎么得到现实世界中的P(x_w,y_w,z_w)

d为视差。

如上图,P是现实中的一点,O_R和O_T分别是两个相机的光心,点P在两个相机上面的成像点分别是p和p'(相机的成像平面经过旋转后放在了镜头前方),f是相机的焦距,B为两个相机的中心距,Z就是我们想要求得的深度信息。X_R和X_ T分别是成像点距离图像最左侧的距离。
视差定义为:d=X_R-X_T,视差值就是左右两幅图像上对应点之间在水平方向上的位置差。
根据三角形相似原理,显然有:

所以总体来说,想要得到该点现实世界的三维坐标,关键点就在于求出该点的视差值。
背景介绍:
立体图像的深度估计对计算机视觉应用至关重要,包括用于汽车自动驾驶、三维模型重构、物体检测和识别的自动驾驶。给一对矫正过的立体图像,深度信息估计的目标是计算参考图上每一个像素点的视差值d(disparity d )。视差值就是左右两幅图像上对应点之间在水平方向上的位置差。对于左图中的像素点(x,y),它在右图中对应点的坐标为(x-d,y),d=xl-xr,这个点的深度值可以通过fB/d来计算,其中f是摄像机的焦距,B是两个摄像头之间的距离(该计算可参考双目测距原理)。
对左右视图进行预处理,畸变矫正处理--极线对齐处理
由于镜头畸变造成的被摄物体失真。譬如鼻子被拉长(https://bigquant.com/community/t/topic/121457)
对极线对齐,水平
坐标系介绍:相机参数标定(camera calibration)及标定结果如何使用


世界坐标系:世界坐标系就是物理空间中的三维坐标系。世界坐标系的原点、x, y, z 轴的方向理论上均可以人为任意设定。如图 所示,一般用坐标系原点![]() 与三维坐标轴
与三维坐标轴![]() ,
,![]() ,
,![]() 来描述世界坐标系。对于世界坐标系中的一点 M,记作
来描述世界坐标系。对于世界坐标系中的一点 M,记作![]() 。为了方便用矩阵表示几个坐标系之间的转换,通常我们用齐次坐标来表示每一个坐标系中的点。那么,世界坐标系上的点
。为了方便用矩阵表示几个坐标系之间的转换,通常我们用齐次坐标来表示每一个坐标系中的点。那么,世界坐标系上的点![]() 表示为齐次坐标为
表示为齐次坐标为 ![]()
摄像机坐标系:在涉及到该坐标系时,通常都是以摄像机镜头的聚焦中心点为原点,即选择焦点作为原点。选取摄像机的光轴为 z 轴。x, y 轴方向分别平行于摄像机拍摄图像的水平与垂直方向。由此可见,摄像机坐标系也是一个三维坐标系。研究中用原点O 与三维坐标轴Xc 、Yc 、Zc 来描述摄像机坐标系,见上图。摄像机坐标系中的一点 M 通常被记为(xc, yc, zc) ,使用齐次坐标表示为(xc, yc, zc,1) 。对于三维空间中的一点,摄像机坐标系与世界坐标系之间的转换关系可以表示为这两个三维坐标系之间的旋转与平移,可以表示为:

其中矩阵T 是平移矩阵。矩阵 R 是正交旋转矩阵。旋转矩阵的参数有如下约束关系:

图像坐标系:图像坐标系是以摄像拍摄到的图像平面作为坐标系平面的。图像坐标系的 X 轴平行于图像的横轴,Y 轴平行于图像的纵轴。坐标原点为需要注意的是,图像坐标系的基本单位并不是整数值的像素点,而是实际的长度单位,如英尺、毫米等。通常使用坐标轴![]() 来描述图像坐标系。点 M 在图像坐标系里映射的m点可以记作( x,y) 。
来描述图像坐标系。点 M 在图像坐标系里映射的m点可以记作( x,y) 。
像素坐标系:摄像机获得的图像,是以离散像素点的形式存储的。因此,需要引入像素坐标。像素坐标是以离散整数值为单位。因此,像素坐标系是离散的二维坐标系。其原点一般选择图像左上角像素所处的位置。像素坐标系的横轴与纵轴通常取图像的水平与垂直方向。假设空间中的一点 M 在图像坐标系成像m可以表示作(u,v) ,则两个坐标系之间的关系可以表示为如下:

其中,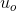 ,
,![]() 是坐标系中的图像中心坐标。
是坐标系中的图像中心坐标。![]() ,
,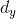 的具体物理意义可以理解为一个像素点在两个坐标轴向上的实际占用长度。
的具体物理意义可以理解为一个像素点在两个坐标轴向上的实际占用长度。![]() 是沿着两个坐标轴方向上的采样密集度。具体而言,我们可以把它理解为单位长度中存在的像素个数。则
是沿着两个坐标轴方向上的采样密集度。具体而言,我们可以把它理解为单位长度中存在的像素个数。则
 右边的x,y指的是图像坐标系的坐标X,Y
右边的x,y指的是图像坐标系的坐标X,Y
摄像机拍摄图像是一个将三维空间点信息投影到成像平面的过程,而三维点云重投影,是要根据视差数据将成像平面中的二维像素点映射到三维空间中。

其中空间中的一点 P 在左右摄像机图像坐标系成像的坐标分别为![]() ,
,![]() ,
,![]() ,
, 是图像中心位置的坐标值,也就是中心轴与成像平面的相交的位置的坐标,
是图像中心位置的坐标值,也就是中心轴与成像平面的相交的位置的坐标,![]() 和
和![]() 是X 和 Y 方向的等效焦距。这样根据主视图中一点的像素坐标以及这一点对应的视差,则根据式(5.1)我们可以求出该点在三维空间中的坐标。
是X 和 Y 方向的等效焦距。这样根据主视图中一点的像素坐标以及这一点对应的视差,则根据式(5.1)我们可以求出该点在三维空间中的坐标。
所有的算法都是要得到比较准确的视差图:
可以注意到近处的物体相比远处的物体有更大的视差。越大视差在视差图像的灰度图中就越亮,颜色色调越暖表示视差更大而深度更小。


传统方法:
立体视觉视差图算法处理阶段的分类 可编码为如下步骤(计算匹配代价-聚合匹配代价-计算稠密视差-优化稠密视差):假设输入是一张校正好的图像

方法分类表格汇总:

还可以根据采用图像表示的基元不同:
区域立体匹配算法:给定一幅图像上的一点,选取该点邻域内的一个子窗口,在另一幅图像中的一个区域内,根据某种相似性,寻找与子窗口图像最相似的窗口,得到的匹配窗口中对应的像素点就为该像素的匹配点。可获得稠密视差图。
基于特征的立体匹配算法:基于几何特征信息(边缘、线、轮廓、兴趣点、角点和几何基元等)提取图像的几何特征点,针对几何特征点进行视差估计,利用得到的视差信息重建三维空间场景。可获得稀疏视差图,通过插值可获得稠密视差图。
局部方法:即基于区域或者窗口的方法。因为给定点(或像素)上的差异计算仅取决于预定义支持窗口内的强度值。因此,该方法只考虑局部信息,计算复杂度低,运行时间短。
全局方法:把视差分配看作是所有视差值的全局能量函数最小化问题。这种方法被表述为目标函数中包含两个项的能量最小化过程。 全局方法没有step 2。
基于资料的丰富度和流行度,我们主要研究的是局部方法。下面是对上面四个步骤的说明。
The matching cost computation(计算匹配代价):
假设有由摄像机获得的立体图像对,若在左右图像上各取一像素点,立体匹配就是衡量这两个点是否是对应的像素点,因此需要建立一个立体匹配的代价函数来衡量这两个点的近似程度。在评价两个点的相似性时,我们通常是寻找两个点在灰度、边缘等方面的相似性,所以通常用灰度差、像素梯度差来描述这两点的差异,差异越小两点越相似。这种灰度差、梯度差就是所谓的匹配代价。实际上,匹配代价的计算也都大多以灰度与梯度为依据,用的比较多的立体匹配代价有:基于像素的技术算法,常见的比如说absolute differences (AD), squared differences (SD);基于区域或者窗口的技术比基于像素或者是特征的技术能提供更加丰富丰富的信息,并且更加准确,因为匹配过程考虑到了给定区域的整个像素集,常见的算法是sumof absolute differences (SAD), the sum of squared differences (SSD),normalized cross correlation(NCC),rank transforms (RT),and census transforms(CT)。基于窗口的主要缺点就是这些方法通常假定支持窗口中的所有像素都具有相似的差异值。
AD:

AD方法是最简单的,由于复杂度低,可以用来实时的立体匹配,对于很少纹理的效果很好,但是很高纹理图就不能产生平滑的视差图。
SD:

以提高边缘的平整度,并使深度不连续附近的区域光滑。 但是对光照和噪声太敏感,特别是在室外环境中。
基于特征的技术:传统的特征提取方法包括:视觉特征(比如边缘,形状,纹理,分割,梯度峰值),统计特征(比如极小值,中值,直方图),变换特征(比如Hough变换,小波变换,Gabor变换)。因为仅仅和特征点相关,尽管计算量显著减少,但是不能获得完整的视差图。特征匹配的精度仍然很低。所以,基于特征的技术不受欢迎。
SAD:

该算法能够实时处理,虽然很快,但是产生的初始视差图的质量很低,原因在于有噪声在物体的边界和无纹理区域。
SSD:

多个固定的窗口可以来减少遮挡误差的发生,其目的是搜索出最小的误差并且在视差图中选出合适的像素。
Cost Aggregation(聚合匹配代价):
目的在于最小化匹配的不确定性。因为基于单个像素的计算得到的匹配代价,对于精确的匹配是远远不够的。聚合后的匹配代价可以认为不仅仅是描述了两像素点之间灰度与梯度的差异程度,也是描述两像素点与周围像素点相关性的差异程度。常用的做法是通过一个窗口来将这些损失全部相加起来。窗口的设计有以下几种:固定的窗口技术(FW),缺点是在一个给定的阈值情况下,随着窗口大小的增大,误差率也会增大,而且对特定的输入数据集需要设定合适的参数值,否则会模糊物体的边界。为了解决在深度不连续区域的过多人工处理痕迹,多窗口(MW)技术,自适应窗口技术(AW),自适应权重窗口技术(ASW)被提出来了。
ASW:

Disparity Computation and Optimization(计算稠密视差):
通过聚合匹配代价,可以得到像素点在不同视差位置的聚合后匹配代价。对于局部匹配算法,在选取视差时,我们通常选择聚合后的最小值作为视差的值。也就是使用 WTA(WinnerTakes All)策略来选择最佳视差值。如下式子所示,选取的视差值是聚合匹配代价后的最小值所对应的视差。D表示视差的取值范围

Disparity Map Refinement(优化稠密误差):
目的在于减少噪声和提高视差图的质量。优化稠密视差通常作为立体匹配算法中的一个附加选项。在一些双目立体视觉的具体应用中,对于视差的精度没有特别的要求,故对稠密视差不需要进行优化工作。优化主要从从两方面入手,一般来说,这个步骤由正则化和遮挡填充或者插值构成。首先是对像素进行亚像素处理,得到更为精确的像素位置,而不是像素的整数值;其次是对得到的视差进行左右一致性检测。如果根据左视图的视差图,左视图一像素点 pl所对应的匹配点为 pr,若根据右视图所对应的右视图中 pr的匹配点不是 pl,则视差匹配不一致。这种匹配不一致的检查失败通常是由于遮挡或者像素误匹配,优化这种不一致性可以采用领域像素视差值优化填充的方法。
立体匹配的约束条件:
立体匹配经常都会是一种病态问题,求解两个视图对应的匹配点是一个会产生极大不确定性的过程。为了减少这种匹配中的不确定性,通常情况下会在匹配算法中对匹配点施用一些约束条件。这些约束限制条件不仅可以降低匹配算法中的不确定性,同时可以减少匹配算法的匹配范围,从而达到极大加快算法速度的目的。
(1)极线约束条件:摄像机所拍摄的三维场景内的任意一三维目标点都处于一个极平面内,极平面与成像平面相交的直线为极线。对于一个成像平面中的某一特征点,在另一个成像平面上的对应点一定在该成像平面的对应极线上,这个特性被称为“对极约束”。对极约束使得我们在立体匹配的过程中,可以将对特征点的搜索工作,由在整个成像平面上搜索变为只在极线上搜索,大大降低了搜索量。
(2)唯一性约束条件:唯一性约束是指匹配的像素点应该成对出现,一一对应。如果立体图像对中的一个视图中的像素点匹配另一个视图中的两个或多个像素点,则认为不满足唯一性约束。在自遮挡的情况中,会出现多匹配的问题,其主要产生原因是像素点在另一个视图中被遮挡后,被匹配到了其他非匹配像素点上。
(3)一致性约束条件:如果根据左视图做参考图像得到的的视差图,左视图一像素点 pl所对应的匹配点为 pr,若根据右视图作为参考图像,所对应的右视图中 pr的匹配点不是 pl,则视差匹配不一致。不满足一致性约束时,这时就会被看成是一个误匹配。
(4)视差约束条件:在匹配过程中,通常会对匹配视差做一个人为的先验规定,规定匹配过程中的视差范围,如果匹配过程中匹配值超出了这个先验范围,则认为不满足视差约束条件。
(5)相似性约束:对于一个匹配点及其所处的支持窗内,区域、轮廓、边缘等应该相似。在主要依据特征点的匹配算法中,特征的匹配主要就是根据相似性约束。
对于传统方法的进行寻找匹配点的过程计算很复杂,并且计算量也比较大,匹配过程中还要设置合适的窗口参数进行匹配数据,这些种种弊端和繁琐的缺点有没有用什么来代替呢?
- 简化匹配约束的计算过程,减少计算复杂度
- 不需要人为的调整窗口的参数,最好能让他自己学习
- 要有一定的泛化能力,输入新的数据,对已经有的模型或者函数参数不需要经过调整或者改动很小也有很强的能力来得到一张优秀的视差图。
下面列举两个传统方法:
1.OpencvBM
代码链接地址:https://blog.csdn.net/qq_36537774/article/details/84786047
这是一个局部的方法,特点是处理速度非常快,非常快,但是得到的视差图结果并不是特别好,会出现断断续续的情况
2.OpencvSGBM
代码链接地址:https://github.com/SPengLiang/SGBM_OpenCV
这是一个半全局的方法,介于全局和局部之间,特点是处理速度比较快,精度也比较好
3.GC算法还未找到该算法的直接代码,该算法是全局的方法。
以上三者的比较可参考https://blog.csdn.net/cxgincsu/article/details/74451940这只是是抛砖引玉,自己可以详细搜索相关内容
基于CNN的方法:
1.MC-CNN
论文地址:https://arxiv.org/abs/1510.05970
github:https://github.com/Jackie-Chou/MC-CNN-python
这个算法使用了一个CNN来计算matching cost:
输入是两个图片的一小块,输出是这两块不匹配的概率,相当于一个损失函数,当两者匹配时为0,不匹配时最大可能为1。通过对一个给定的图片位置搜索可能的d取值,找到最小的CNN输出,就得到了这一点局部的偏移估算。
MC-CNN算法接下来做了如下后期处理:
Cross-based cost aggregation:基本思想是对邻近的像素值相似的点的偏移求平均,提高估计的稳定性和精度。
Semi-global matching:基本思想是邻近的点的平移应该相似,加入平滑约束并求偏移的最优值。
插值和图片边界修正:提高精度,填补空白。
虽然MC-CNN使用了CNN但仅限于计算匹配程度,后期的平滑约束和优化都是必不可少的。

最终算法效果如上:输入是一对左侧相机和右侧相机拍摄的照片。这两张图片的主要差别是物体的水平位置不同(其他差别主要是由反光、遮挡和透视畸变导致的)。可以注意到近处的物体相比远处的物体有更大的视差。输出图像是一个展示在右侧图像上的视差图像,颜色色调越暖表示视差更大而深度更小。

2.FlowNet

论文地址:https://www.cv-foundation.org/openaccess/content_iccv_2015/papers/Dosovitskiy_FlowNet_Learning_Optical_ICCV_2015_paper.pdf
开源代码:https://github.com/ClementPinard/FlowNetPytorch
实现了端到端的模型结构,用CNN实现特征提取,匹配打分,全局优化等功能。采用的是encoder-decoder框架。在encoder部分提出了两种模型结构:
(1)FlowNetSimple(FlowNetS):把两张图片叠起来输入到一个卷积网络中,输出是每个像素的偏移量。缺点是,计算量大,而且无法考虑全局的优化手段,因为每一个像素的输出都是独立的。

(2)FlowNetCorr(FlowNetC):先对两幅图像分别进行特征提取,然后通过一个相关层把两个分支合并起来继续下面的卷积运算。这个相关层的计算和卷积层类似,只是没有了学习到的特征权重,而是由两个分支的隐层输出相乘求和。

在decoder网络,对每层的反卷积relu层,不仅输入前一层的输出,同时还输入前一层预测的低尺度的光流和对应编码模块中的特征层。这样使得每一层反卷积在细化时,不仅可以获得深层的抽象信息,同时还可以获得浅层的具象信息,以弥补因特征空间尺度的缩小而损失的信息。

论文的实验证明CNN可以用来解决光流预测问题,即使是人工合成的非自然图像,依然可以用来训练深度神经网络来预测光流。在精度方面,虽然在公共数据集上面离最好的传统算法还有差距,但是只要拥有合适充足的数据,基于CNN的算法是非常有前景的,由于只需要卷积运算,加上GPU的加速,在算法速度方面,可以远远快于目前其他领先的传统算法。
3.FlowNet2.0
FlowNet虽然速度快,但精度依然不及目前最好的传统方法。在很大程度上限制了FlowNet的应用。FlowNet2.0是FlowNet的增强版,在FlowNet的基础上进行提升,追平了目前领先的传统方法。
论文地址:https://arxiv.org/abs/1612.01925
开源地址:https://github.com/NVIDIA/flownet2-pytorch
主要有以下改进:
(1)增加了训练数据,改进了训练策略。额外增加了具有3维运动的数据库FlyingThing3D和更加复杂的训练策略。S_short为FlowNet中的训练策略,FlowNet2中增加S_long策略和S_fine策略。
(2)利用堆叠的结构对预测结果进行多级提升。FlowNet使用了后处理的方法(传统的变分优化方法)对输出结果进行再优化,FlownNet2利用CNN来代替后处理方法对结果再进行优化。实验表明在FlowNetC的基础上堆叠FlowNetS,当以每个FlowNet(S或者C)为单位进行优化训练时,得到的结果最优。此外,对于后续堆叠的FlowNetS,除了输入两张图片Image1、Image2外,再输入前一模块的预测光流Flow,论文中![]() 表示Image1和Image2,
表示Image1和Image2,![]() 表示上一网络的输出光流Flow,
表示上一网络的输出光流Flow,![]() 表示Warped输入,
表示Warped输入,![]() 表示BrightnessError输入。
表示BrightnessError输入。

实验表明,当以FlowNetC为基础网络,额外堆叠两个FlowNetS模块后,所得的效果最好。该论文用FlowNet2-CSS表示。但是随着优化模块的堆叠,FlowNet2的计算速度会下降,因此可以按比例削减FlowNet各层的特征通道数目来减少计算量,论文推荐保留每层3/8通道数,并且将削减后的网络用FlowNet2-c和FlowNet-s表示。
(3)针对小位移的情况引入特定的自网络进行处理。由于FlowNet对真实图片中的小位移情况下,结果往往不理想。因此对模块结构进行改进:在编码模块中,把大小为7x7和5x5的卷积和均换为多层3x3来增加对小位移的分辨率。文中对小位移改进后的网络结构命名为FlowNet2-SD。在训练数据的选择上,针对小位移,又重新合成了以小位移为主的新的数据库ChairSDHome,并将此前的堆叠网络FlowNet2-CSS在ChairSDHome和FlyingThing3D的混合数据集上继续微调,将结果网络表示为FlowNet2-CSS-ft-sd。
最后再利用一个小网络对FlowNet2-CSS-ft-sd的结果和FlowNet2-SD的结果进行融合,并将整个网络体系命名为FlowNet2.结构如下:

4.PSMNet
论文地址:https://arxiv.org/abs/1803.08669
开源:https://github.com/JiaRenChang/PSMNet
早期的使用CNNs通过相似性计算来解决匹配一致性的估计问题,CNNs计算一对图块的相似性得分进而判断他们是否匹配。虽然相比传统方法在速度和准确度上面取得了中重要突破,但还是很难在病态区域(例如遮挡,重复纹理,弱纹理,反光表面等)找到精确的匹配点。仅仅利用不同视角下光照强度的一致性约束已经不足以在不适定区域得到精确的匹配一致性估计了。所以,部分来自于全局环境信息的支持必须融合到立体匹配过程中。需要全局上下文信息进行整合。
图像处理中不适定问题(ill posed problem)或称为反问题(inverse Problem)
该论文的主要创新点就是(1)提出一个端到端的不需要后处理的立体匹配网络,(2)引入了空间金字塔池化模块(SPP)来聚合多尺度信息,(3)提出一个堆叠沙漏结构(stacked hourglass networks),使用3D卷积的encoder-decoder结构,然后用了好几个堆叠起来。
病态区域:查看https://bigquant.com/community/t/topic/121457更多图像例子


输入是一对左右视图,输出是视差图。

可参考:https://zhuanlan.zhihu.com/p/52641036
立体匹配深度学习文章罗列
对传统方法有两篇综述性文章:
[1]. Affendi H R , Haidi I . Literature Survey on Stereo Vision Disparity Map Algorithms[J]. Journal of Sensors, 2016, 2016:1-23.
[2]. D. Scharstein and R. Szeliski. A Taxonomy and Evaluation of Dense Two-Frame Stereo Correspondence Algorithms. nternational Journal of Computer Vision, 47(1/2/3):7-42, April-June 2002.