SparkStreaming与Kafka010之05 监控Spark程序 获取Metrics信息 addStreamingListener或读取http信息解析json串
要获取Metrics信息,监控
1.加监听:
新的办法,直接一句话搞定
ssc. addSparkStreamingListener
SparkStreaming、spark程序都能加监听
只适合spark 2.2.0以上版本 ssc. addSparkStreamingListener
2.老办法:解析Metrics的json串信息 好像是http请求之类的返回json串
而且一般请求的4040端口有一定可能被占用的,可能是4041、4042 所以还需要验证此端口的appID是不是同一个
这里先做一个老办法的实例:
package Kafka010
import Kafka010.Utils.{MyKafkaUtils, SparkMetricsUtils}
import com.alibaba.fastjson.JSONObject
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010._
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* Created by Shi shuai RollerQing on 2019/12/24 19:47
* 加监控 获取Metrics信息
*/
object Kafka010Demo05 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName(s"${this.getClass.getCanonicalName}")
val ssc = new StreamingContext(conf, Seconds(5))
// ssc.addStreamingListener()
//读数据
val groupID = "SparkKafka010"
val topics = List("topicB")
val kafkaParams: Map[String, String] = MyKafkaUtils.getKafkaConsumerParams(groupID, "false")
val ds: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](topics, kafkaParams)
)
ds.foreachRDD(rdd => {
//代表对数据进行处理
if(! rdd.isEmpty())
println(rdd.count())
//实时监控
val recordsCount = rdd.count()
monitor(ssc.sparkContext, recordsCount)
})
ssc.start()
ssc.awaitTermination()
}
// 获取json串;解析json串;落地
def monitor(sc: SparkContext, recordsCount: Long) = {
//准备参数
val appName = sc.appName
val appId = sc.applicationId
//注意这里:如果放到集群运行地址localhost可以换没问题
//但是注意放在集群运行的spark程序可能不止一个,所以端口可能会被占用 就是说端口可能为4041 4042
// 肯定有这样的情况 所以如果要用 还要再做优化
val url = "http://localhost:4040/metrics/json"
// 获取json串,转为jsonObject
val metricsObject: JSONObject = SparkMetricsUtils.getMetricsJson(url).getJSONObject("gauges")
//开始时间
val startTimePath = s"$appId.driver.$appName.StreamingMetrics.streaming.lastCompletedBatch_processingStartTime"
val startTime: JSONObject = metricsObject.getJSONObject(startTimePath)
val processingStartTime = if(startTime != null)
startTime.getLong("value")
else -1L
println(s"processingStartTime = $processingStartTime")
// 每批次执行的时间;开始时间(友好格式);处理的平均速度(记录数/时间)
// lastCompletedBatch_processingDelay + schedulingDelay = 每批次执行的时间
// 组织数据保存
}
def getKafkaConsumerParams(grouid: String = "SparkStreaming010", autoCommit: String = "true"): Map[String, String] = {
val kafkaParams = Map[String, String] (
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "hadoop01:9092,hadoop02:9092,hadoop03:9092",
ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG -> autoCommit,
//ConsumerConfig.AUTO_OFFSET_RESET_CONFIG -> "latest",//earliest、 none 、latest 具体含义可以点进去看
ConsumerConfig.GROUP_ID_CONFIG -> grouid,
ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer].getName,
ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer].getName
)
kafkaParams
}
}
这是工具类
package Kafka010.Utils
import com.alibaba.fastjson.JSON
/**
* Created by Shi shuai RollerQing on 2019/12/26 16:29
* Spark监控数据获取工具类
*/
object SparkMetricsUtils {
/**
* 获取监控页面信息
*
*/
def getMetricsJson(url: String,
connectTimeout: Int = 5000,
readTimeout: Int = 5000,
requestMethod: String = "GET") ={
import java.net.{HttpURLConnection, URL}
val connection = (new URL(url)).openConnection.asInstanceOf[HttpURLConnection]
connection.setConnectTimeout(connectTimeout)
connection.setReadTimeout(readTimeout)
connection.setRequestMethod(requestMethod)
val inputStream = connection.getInputStream
val content = scala.io.Source.fromInputStream(inputStream).mkString
if(inputStream != null) inputStream.close()
JSON.parseObject(content)
}
}
这是生产者
package Kafka010.Utils
import java.util.Properties
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig, ProducerRecord}
/**
* Created by Shi shuai RollerQing on 2019/12/24 20:19
*/
object ProducerDemo {
def main(args: Array[String]): Unit = {
// 定义kafka的参数
val brokers = "hadoop01:9092,hadoop02:9092,hadoop03:9092"
val topic = "topicB"
val prop = new Properties()
//prop.put("bootstraps", brokers)
//prop.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer")
//prop.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer")
prop.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, brokers)
prop.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer")
prop.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer")
// KafkaProducer
val producer: KafkaProducer[String, String] = new KafkaProducer[String, String](prop)
// KafkaRecorder
// 异步
for(i <- 1 to 100000){
val msg = new ProducerRecord[String, String](topic, i.toString, i.toString)
//发送消息
producer.send(msg)
println(s"i = $i")
Thread.sleep(100)
}
}
}
先启动了生产
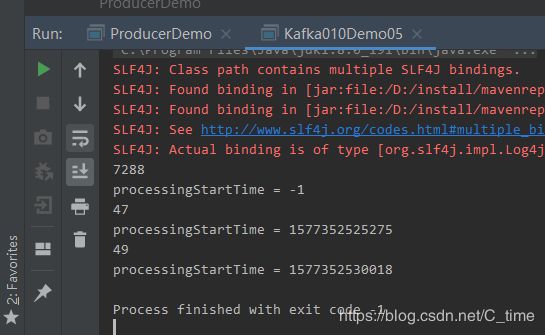
然后再消费
结果是没问题的,刚开始时没有消费 所以条数非常多这一批7288 后面就好了几十几十的了
打出来的-1可能是刚开始的时间没有获取吧可能是
addStreamingListener方法
贼简单 还不会有老办法的诸多问题。
package Kafka010
import Kafka010.Utils.{MyKafkaUtils, SparkMetricsUtils}
import com.alibaba.fastjson.JSONObject
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010._
import org.apache.spark.streaming.scheduler.{StreamingListener, StreamingListenerBatchCompleted}
import org.apache.spark.streaming.{Seconds, StreamingContext, Time}
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by Shi shuai RollerQing on 2019/12/24 19:47
* 加监控 获取Metrics信息
*/
object Kafka010Demo06 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName(s"${this.getClass.getCanonicalName}")
val ssc = new StreamingContext(conf, Seconds(5))
ssc.addStreamingListener(new MyStreamingListener) //需要自己实现一个StreamingListener
//读数据
val groupID = "SparkKafka010"
val topics = List("topicB")
val kafkaParams: Map[String, String] = MyKafkaUtils.getKafkaConsumerParams(groupID, "false")
val ds: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](topics, kafkaParams)
)
ds.foreachRDD(rdd => {
//代表对数据进行处理
if(! rdd.isEmpty())
println(rdd.count())
//实时监控
val recordsCount = rdd.count()
//monitor(ssc.sparkContext, recordsCount)
})
ssc.start()
ssc.awaitTermination()
}
//spark 2.2.0以上版本
class MyStreamingListener extends StreamingListener {//有好多方法可以重写 可以看看
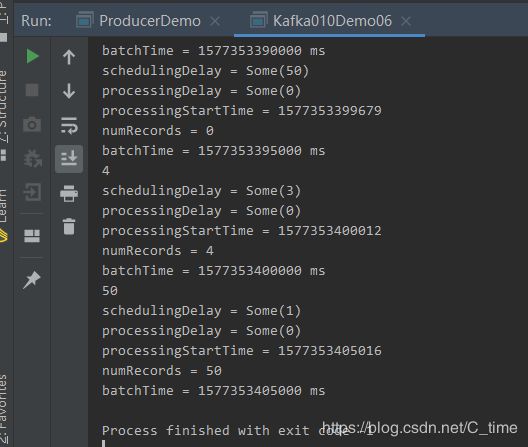
//Called when processing of a batch of jobs has completed.当一批作业处理完成时调用。
override def onBatchCompleted(batchCompleted: StreamingListenerBatchCompleted): Unit = {
val schedulingDelay = batchCompleted.batchInfo.schedulingDelay
val processingDelay: Option[Long] = batchCompleted.batchInfo.processingDelay
val processingStartTime: Long = batchCompleted.batchInfo.processingStartTime.get
val numRecords: Long = batchCompleted.batchInfo.numRecords
val batchTime: Time = batchCompleted.batchInfo.batchTime
println(s"schedulingDelay = $schedulingDelay")
println(s"processingDelay = $processingDelay")
println(s"processingStartTime = $processingStartTime")
println(s"numRecords = $numRecords")
println(s"batchTime = $batchTime")
}
}
def getKafkaConsumerParams(grouid: String = "SparkStreaming010", autoCommit: String = "true"): Map[String, String] = {
val kafkaParams = Map[String, String] (
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "hadoop01:9092,hadoop02:9092,hadoop03:9092",
ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG -> autoCommit,
//ConsumerConfig.AUTO_OFFSET_RESET_CONFIG -> "latest",//earliest、 none 、latest 具体含义可以点进去看
ConsumerConfig.GROUP_ID_CONFIG -> grouid,
ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer].getName,
ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer].getName
)
kafkaParams
}
}
spark程序的监控
WordCountWithMonitor
适用于批处理程序
package Kafka010
import org.apache.spark.{SparkConf, SparkContext}
object WordCountWithMonitor {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setAppName(s"${this.getClass.getCanonicalName}")
.setMaster("local[*]")
val sc = new SparkContext(conf)
sc.addSparkListener(new SparkMonitoringListener)
val lines = sc.textFile("C:\\Users\\wangsu\\Desktop\\流式项目课件2\\antispider24\\src\\main\\lua\\controller.lua")
lines.flatMap(_.split("\\s+"))
.map((_, 1))
.reduceByKey(_+_)
.collect()
sc.stop()
}
}