StarlingX 前世今生 -- (汇总了网上的一些资料)
初识StarlingX
- 背景
- 发展历程
- 愿景
- 组件、架构
- StaringX控制、计算、存储节点架构及和相关开源项目渊源
- StarlingX组成架构
- 扩展模式
- StarlingX架构技术栈
- Starling X组件架构
- StarlingX未来规划
- Openstack组件
- penstack的组件关系
- Openstack创建虚拟机流程
- StaringX主要功能特性
- StarlingX分布式云架构:
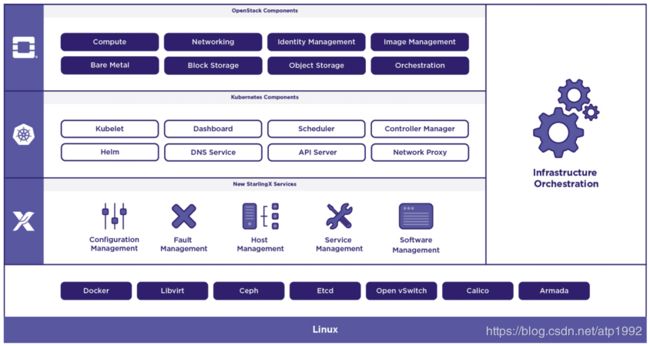
- 配置管理
- 主机管理
- 服务管理:
- 软件管理
- 基础设施编排
- 故障管理
- 按项目介绍
- Metal
- Cnfig
- Distributed clud
- Fault managent
- NFV
- High Avaliablity
- Sftware updates
- Tols
背景
要说StarlingX,首先要弄清楚其发展的背景,作为致力于边缘云的基础设施,可以从两个角度,一个是云计算的发展,另一个是边缘计算的发展
云计算的发展经历了虚拟化→基础云-->云原生的发展,虚拟化时代的vmware领航着当时的云发展,通过VMware完成虚拟机资源的统一管理,显然这种方式有一定局限,必须采购VMware的商业产品,只能使用VMware虚拟机,性能也比较受限。后来基础云阶段,openstack出现,将KVM / ESXI / bare-matel 统一管理,并基于此搭建平台,完成IAAS→PAAS的搭建。
 而边缘计算的发展时间还比较短,大家对边缘计算的定义还有争议,但是不影响我们的理解。边缘计算不仅指端设备的计算,也指边节点的计算,边指端云中间,用于弥补端的计算力不足以及云延迟的产物。按照业内的定义边缘计算分物边缘、移动边缘、云边缘,而StarlingX就是聚焦于边边缘的。
而边缘计算的发展时间还比较短,大家对边缘计算的定义还有争议,但是不影响我们的理解。边缘计算不仅指端设备的计算,也指边节点的计算,边指端云中间,用于弥补端的计算力不足以及云延迟的产物。按照业内的定义边缘计算分物边缘、移动边缘、云边缘,而StarlingX就是聚焦于边边缘的。
补充一下边缘形态:


所以,总的说来,StarlingX就是提供分布式边缘云的基础设施的软件堆栈,
先说说边缘计算的特点:
联接性:联接性是边缘计算的基础。所联接物理对象的多样 性及应用场景的多样性,需要边缘计算具备丰富的联接功 能,如各种网络接口、网络协议、网络拓扑、网络部署与 配置、网络管理与维护。联接性需要充分借鉴吸收网络 领域先进研究成果,如TSN、SDN、NFV、Network as a Service、WLAN、NB-IoT、5G等,同时还要考虑与现有各 种工业总线的互联、互通、互操作。
数据第一入口:边缘计算作为物理世界到数字世界的桥梁,是数据 的第一入口,拥有大量、实时、完整的数据,可基于数据 全生命周期进行管理与价值创造,将更好的支撑预测性维 护、资产管理与效率提升等创新应用;同时,作为数据第 一入口,边缘计算也面临数据实时性、确定性、完整性、 准确性、多样性等挑战。
约束性:计算产品需适配工业现场相对恶劣的工作条件与运 行环境,如防电磁、防尘、防爆、抗振动、抗电流/电压波动 等。在工业互联场景下,对边缘计算设备的功耗、成本、空间 也有较高的要求。边缘计算产品需要考虑通过软硬件集成与优 化,以适配各种条件约束,支撑行业数字化多样性场景。
分布性:边缘计算实际部署天然具备分布式特征。这要求边缘 计算支持分布式计算与存储、实现分布式资源的动态调度 与统一管理、支撑分布式智能、具备分布式安全等能力。
融合性:OT与ICT的融合是行业数字化转型的重要基础。边缘 计算作为“OICT”融合与协同的关键承载,需要支持在联 接、数据、管理、控制、应用、安全等方面的协同。
那么传统的云为什么不能直接拿来部署:

Ø定位于集中于IDC机房到服务器集群的管理,不能适应边缘云的分布式网络环境
Ø端云的网络路径复杂,延时高(工控、医疗设备),且不稳定(游戏,直播)
Ø端云的带宽有限,大设备量/大数据量下带宽昂贵(视频、CDN)
Ø端云传输过程的安全性难以保证,中间遭窃听、篡改风险
Ø端云网络连接情况复杂,难以保证持续连接
Ø边缘环境恶劣,需要更多考虑高可用、无人值守
全新的场景,新的挑战,需要有新的解决方案。
于是就出现了StarlingX.
发展历程
上述是发展背景,从StarlingX的发展历程看
2018年5月, Intel和风河宣布将其电信云/边缘云的商业产品Titanium Cloud中的部分组件开源, 命名为StarlingX, 并提交给OpenStack Foundation管理。
风河Titanium Cloud最初构建在OpenStack等开源组件上, 然后对其进行扩展和加固, 以满足关键的基础设施需求, 包括: 高可用性、故障管理和性能管理,可用于NFV电信云、边缘云、工业物联网等场景。
StarlingX是一款高性能的电信云/边缘云软件, 最初版本代码基于风河的商业软件Titanium Cloud R5产品,开源以后代码采用Apache2许可证。而Titanium Cloud继续提供商用的边缘云解决方案。
愿景

将已经经过验证的云技术应用在边缘计算上,然后来发展边缘计算的管理框架,简化部署边缘云,最后把它应用在交通运输、能源、制造业、零售、视频、智慧城市、无人驾驶、医疗卫生等等领域中。我们通过边缘计算整体去编排中心云与边缘云之间的所有资源。
Ø提供快速部署、伸缩、高可靠的边缘软件平台基础设施:
l适配已有的云端技术至边缘计算场景
l全系统范围内的自动编排
l集中部署和管理边缘云
l简化分布式边缘系统的部署
l事件快速响应
l快速故障恢复
l低延迟
组件、架构

除了OpenStack等开源社区的组件, StaringX项目新增的组件主要有以下6个:
1. 配置管理 2. 主机管理 3. 服务管理 4. 软件管理 5. 故障管理 6. 基础设施管理
下面会详细介绍这六个组件。
另外, StarlingX会对使用到的开源项目, 如: CEPH, CentOS, OpenStack等做增强和扩展, 这些代码最终将会回馈给社区。
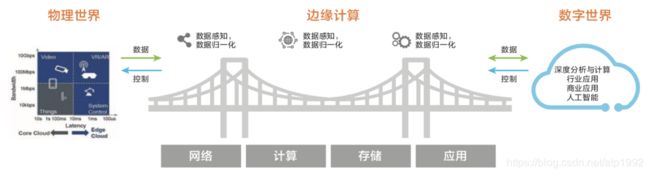
StaringX控制、计算、存储节点架构及和相关开源项目渊源
StarlingX控制节点的架构,和其他项目渊源关系:
蓝色代表由titanium cloud项目创建,starlingx继承的项目
黄色代表基于开源项目进行少量改动的项目
红色代表基于开源项目进行大量改动的项目
紫色代表直接引用未做修改的开源项目

StarlingX计算节点的架构及组件关系:
StarlingX存储节点的架构及组件关系:

StarlingX组成架构
StarlingX的节点/组网结构和普通的OpenStack没有太大区别。
在标准配置下, 包括:
2个HA的控制节点集群
* 2-100个计算节点
* 2-9个CEPH (可选)
* 计算节点采用了DVR分布式路由
* Cinder后端可采用LVM或者CEPH
* Glance后端可采用文件系统或者CEPH
* Swift后端只支持CEPH

扩展模式

单台服务器部署:
* 控制、计算、网络、存储功能部署在同一台节点上
* 不支持HA
2台服务器部署:
* 每台服务器上运行控制、计算、网络、存储功能
* 计算、网络、存储采用双机HA方式
多台服务器部署:
* 2台HA控制节点集群
* 2-100台计算节点
* 2-9台可选的CEPH存储节点集群
* 计算节点上运行DVR分布式路由
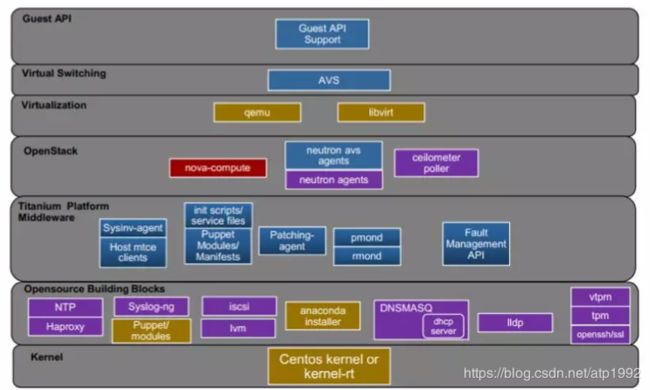
StarlingX架构技术栈

Starling X组件架构
starlingx 与 k8s openstack共同构成了边缘云的基础设施
StarlingX未来规划

- StarlingX 的发展方向:OpenStack容器化、部署在Kubernetes集群上、基于OpenStack-Helm管理集群的生命周期。
- 整合Kubernetes:Docker Runtime、Calico CNI plugin、CEPH作为持久存储后端、HELM作为包管理、本地Docker镜像仓库。
- 支持其他容器化的边缘应用部署。
Openstack组件
下面从Openstack的角度理解starlingx的组件关系及配合方式
openstack的组件关系
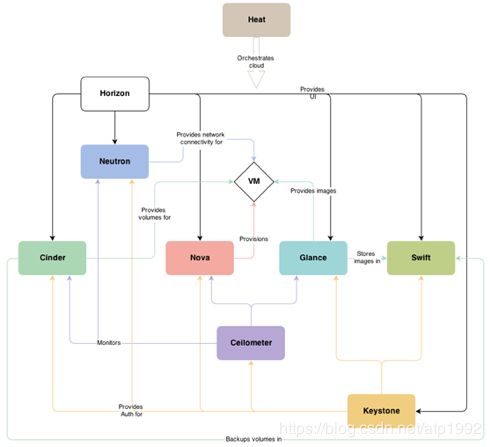

这张图简单描述了openstack组件的关系,从高层次的抽象角度看,其实starlingx的组件关系也是类似的
Openstack创建虚拟机流程
这里还可以看下Openstack创建虚拟机的流程,可以更好的理解其组件间的配合方式:

图中流程-1
首先你访问dashboard之后,显示的是一个登录页面,人家horizon告诉你:想用Openstack新建云主机?那你先把你的账号密码交给我,等我找我大哥keystone确认你的身份之后才能放你进去

原来我还一直以为这里登录的时候只是一个简单的django框架使用pymysql直接查询数据库,而实际上这里的表单信息是提交到了keystone,然后通过keystone查询数据库进行验证的
图中流程-2
keystone接收到前端表单传过来的域、用户、密码信息以后,查询了数据库,确认身份后将一个token(就像是办了身份证~~~)返回给该用户,让这个用户以后再进行操作的时候不需要再提供账号密码,而是拿出token来
图中流程-3
horizon拿到token之后,实际上这里在web页面上的显示就是登录成功了,接着找到创建云主机的按钮并点击

填写云主机相关配置信息

填了这么一大堆配置信息,点击启动实例之后,horizon就带着三样东西去找nova-api了:
1.创建云主机的请求
2.云主机相关配置信息
3.刚刚keystone返回给的token
图中流程-4
你horizon来找我nova-api办事可我也不认识你啊,这样,你把身份证给我,我去找我大哥keystone问问(这些组件都有一个共同的大哥keystone,但他们自己之间却不认识)。然后他就带着horizon的token去找keystone
图中流程-5
keystone一看nova-api带来的token,这不就是自己刚发的那个么,但程序可没这么聪明,它还得乖乖查一次数据库,然后告诉nova-pai,这兄弟信得过,你就照它说的做吧
图中流程-6
nova-api从大哥那回来,接收了horizon提供的两样东西,一是云主机配置信息,二是创建请求,这nova-api手底下也有一帮小兄弟,这帮人之间沟通可不太方便都得通过一块小黑板(mq消息队列),把自己的需求写在小黑板上,能做的了这事的人自然就去做了。但配置信息现在还不能写在小黑板上,得找到确定去干活的人之后才行啊,所以nova-api就把配置信息放到数据库里
图中流程-7
数据库把配置信息收好之后,对nova-api说了声,我放好了
图中流程-8
放好配置信息后nova-api就在小黑板上写“现在要创建一台云主机,配置信息我已经放到数据库了,小s你给安排安排吧”
图中流程-9
这个小s就是nova-schedular,他就像是nova-api的秘书,nova-api的有事都是通过它交代给其他人的,这一步就是他从小黑板上看到了nova-api的信息
图中流程-10
小s现在知道了要创建云主机,但它要看一看云主机都要什么配置,才好决定该把这事交给谁去做(这里是指多个nova-compute的情况,各个计算节点的资源使用情况都在小s这里),所以他让数据库把云主机配置信息发给他看看
图中流程-11
数据库收到请求之后,把云主机配置信息发给小s
图中流程-12
小s拿到配置信息后,使用调度算法决定了要让nova-compute去干这个事,就在小黑板上写“nova-compute你给创建个云主机,配置都在数据库里了”
图中流程-13
nova-compute看到小黑板上的东西之后,本应该直接去数据库拿取配置信息,但因为nova-compute的特殊身份,nova-compute所在计算节点上全是云主机,万一有一台云主机被黑客入侵从而控制计算节点,直接拖库是很危险的。所以不能让nova-compute知道数据库在什么地方
图中流程-14
nova-compute没办法去数据库取东西难道就不工作了吗?那可不行啊,他不知道去哪取,但他哥们知道啊,于是他在小黑板上写“nova-conductor,你帮我去数据库取一下配置信息”
图中流程-15
nova-conductor从小黑板上看到了nova-compute的请求
图中流程-16
nova-conductor告诉数据库我要查看某某云主机的配置信息
图中流程-17
数据库把云主机配置信息发送给nova-conductor
图中流程-18
nova-conductor把配置信息写在小黑板上
图中流程-19
nova-compute从小黑板上读取云主机的配置信息
图中流程-20
nova-compute拿到了云主机配置信息一看,人家可是专业的,立马就知道该怎么做了,先去找glance-api拿镜像吧,刚才讲了那么多,可都是在nova组件内部的,这次去找别的组件可不是写在小黑板上了,它得带着自己的身份证去,告诉glance-api,我要xxx镜像
图中流程-21
glance-api看nova-compute过来,他可不认识nova-compute,让nova-compute拿出身份证,拿着人家身份证找到自己大哥keystone看看这人靠不靠谱,keystone一看,没问题,按他说的做吧(在nova验证horizon被当做两步,这里化做一步,是为了简化重复的流程)
图中流程-22
glance-api把镜像资源信息返回给nova-compute(这里主要说创建云主机的过程,除nova外其他组件内部先不提)
图中流程-23
接着nova-compute找到neutron-server(图里画错了,因为是偷别人的图,自己的图画了半天画不好。。。),告诉他我要xxx网络资源
图中流程-24
neutron-server也不认识他,拿着他的身份证找keystone确认了一下身份
图中流程-25
nuetron-server把网络资源信息返回给nova-compute
图中流程-26
nova-compute找到cinder-api要存储资源,云主机得有硬盘啊,得存东西啊(同样,这里图中也有错误)
图中流程-27
cinder-api也不认识他,拿着他的身份证找keystone确认了一下身份
图中流程-28
cinder-api把存储资源信息返回给nova-compute
图中流程-29
nova-compute拿到了所有资源之后,他其实也只是个收集信息的,他把工作全都交给了真正创建虚拟机的Hypervisor(kvm,zen等虚拟化技术)
到此为止,你已经拥有了一台云主机了,流程看似复杂实际上在几十秒就完成了
StaringX主要功能特性
StarlingX分布式云架构:

StarlingX支持分布式云,可用来支持边缘计算场景。 其主要功能有:
* 基于OpenStack多region概念
* 中心region通过分布式管理器(dc-manager)统一对各子云进行管理、配置、故障聚合、软件升级/patching等
* 边缘region将会通过3层网络/REST API和中心region通信
* 边缘云运行精简过的控制平面
配置管理
StarlingX的代码提供了节点配置以及库存管理服务,带有对新节点的自动发现及配置功能,并且管理着大量远端或者难以访问的站点。

安装
* 自动发现新节点
* 管理安装参数 (控制台、根磁盘等)
* 通过xml文件批量配置节点
* 具备安装进度条
资产发现
* CPU/核, SMT, 内存、大页信息
* GPU, 加解密/压缩硬件, LLDP邻居信息
节点配置
* 节点角色, 角色配置
* CPU核, 内存(包括大页)分配, dpdk
* 网络接口和存储配置
* 批量节点配置
用户界面
* 支持REST API, Horizon界面和命令行
另外, 可通过puppet进行配置
主机管理
StarlingX软件提供生命周期管理功能,通过一个REST API接口管理主机。 这种与供应商无关的工具可以检测主机故障并且通过为集群的连接,关键进程故障,资源利用率阈值以及硬件故障提供监控和警报的方式来启动自动修复。 这个工具还与主板管理控制器连接,用于辅助复位(out-of-band reset),电源开/关机以及硬件传感器监控,并与其他的StarlingX组件共享主机状态。”

* 管理主机的生命周期
* 自动发现主机故障, 并恢复
* 监控、告警和恢复。包括: 网络连接、进程问题、接口状态、资源利用率、硬件故障、主机看门狗等等
* 主机带外重启、上电、下电、硬件传感器监控
* 发布主机状态给其它组件
* 可通过REST API进行主机管理
服务管理:
通过基于跨多个节点的N + M或N等冗余模型来提供高可用性,实现提供服务的生命周期管理。 这项服务支持使用多个消息传递路径来避免脑裂(split-brain)通信故障,以及支持使用主动或被动监视,通过完全数据驱动的体系结构来明确定义服务故障的影响。

软件管理
这项服务允许用户使用适用于从内核到OpenStack服务的所有基础架构堆栈的一种一致性机制,来部署纠正内容和新功能的更新。 这个模块可以完成滚动升级,包括并行化和对主机重新启动的支持,允许通过使用实时迁移将工作负载从节点移出。

* 提供软件升级功能
* 可以对整个软件的各层次升级/打补丁, 从kernel层一直到openstack的各服务层
* 所有节点软件可以并行更新
* 已在线的服务如果打了patch需要进行重启
* 提供详细的补丁状态信息, 包括节点层和系统层
* 支持滚动升级(Rolling Upgrade)
* 自动处理数据库schema变更和转换
* 提供REST API, Horizon界面和命令行
基础设施编排
* 管理和编排VM HA能力
* 自动恢复故障虚拟机实例
* 生成实例告警和日志信息
* 可对节点的软件升级和打补丁进行编排
* 支持REST API, Horizon界面和命令行
故障管理
用户即可以在基础架构节点上,也可以在诸如虚拟机和网络等虚拟资源上设定,清除或者查询为重要事件自定义的报警以及日志。用户可以在Horizon的图形用户界面上访问主动报警列表(Active Alarm List)以及主动报警计数面板(Active Alarm Counts Banner)。

* 提供一个故障管理的框架软件服务
* 可通过客户端/REST API对故障管理软件进行配置、清空、查询告警、日志等事件。并可通过SNMPv2c Trap进行信息发布
* 可在Horizon界面上显示告警信息列表
* 故障信息覆盖: 节点、虚拟机、网络、存储等等
按项目介绍
Metal
The StarlingX Metal project is a new repository that manages the lifecycle, operation, and administration of the Host. StarlingX Metal also provides Host fault monitoring, alarms, and initiates fault recovery.
New Features¶:
- Manages the life cycle of the Host.
- Detects and automatically handles host failures and initiates host recovery.
- Monitors, Alarming, and Recovery for the following:
- Cluster connectivity.
- Critical process failures.
- Resource utilization thresholds.
- Interface states.
- H/W fault / sensors.
- Host watchdog.
- Activity progress reporting (e.g. booting, testing).
- Provides an interface with board management (BMC) for out-of-band reset, power-on/off, and H/W sensor monitoring.
- Publishes the Host’s state with other StarlingX components.
- Exposes a set of administrative commands for the user to manage the Host through REST API:
- Lock/unlock, reboot, reset, re-install, SWACT.
- Out-of-band via BMC: Reboot, reset, power on/off.
Config
The StarlingX Config project is a new repository that provides the following:Host Installation.Inventory Discovery.Host Configuration, which moves to Host Management in future.System-level Configuration.Configuration of StarlingX Platform Services.API, Horizon and CLI services for all Main Components.Configuration for various services in StarlingX.
New Features¶
- Installation:
- Auto-discover new nodes.
- Manage installation parameters (i.e. console and root disks).
- Bulk provisioning of nodes through xml file.
- Installation progress indicators.
- Inventory Discovery:
- CPU/cores, SMT, processors, memory, and huge pages.
- Storage, ports.
- GPUs, crypto/compression H/W, and LLDP neighbor information.
- Nodal Configuration:
- Node role and role profiles.
- Core and memory (including huge page) assignments.
- Network Interfaces and storage assignments.
- Bulk configuration of nodes through system profiles.
- User Interface:
- REST API, Horizon GUI, and “system” CLI commandsuite.
Distributed cloud
The StarlingX Distributed Cloud project is a new repository. It supports an edge computing solution by providing central management and orchestration for a geographically distributed network of StarlingX systems.
Fault managent
The StarlingX Fault project is a new repository that provides Alarm and Log Reporting Services for other StarlingX Components.
New Features¶
- Framework for infrastructure services through a client API to do the following:
- Set, clear, and query customer alarms.
- Generate customer logs for significant events.
- Framework to maintain an Active Alarm List.
- Active Alarm Counts Banner on Horizon GUI.
- Framework to provide REST API to query alarms and events and also publishes through SNMPv2c Traps.
- Support for Alarm suppression.
- Operator Alarms on the following:
- Platform Nodes and Resources.
- Hosted Virtual Resources (i.e. VMs, Volumes, and Networks).
- Operator Logs - Event List:
- Logging of Set/Clears of Alarms.
- Related to Platform Nodes and Resources.
- Related to Hosted Virtual Resources (i.e. VMs, Volumes, and Networks).
NFV
The StarlingX NFV project is a new repository that provides High Availability management of VMs and Software Patching & Upgrade Orchestrator Services.
New Features¶
- Responsible for managing and orchestrating the VM carrier grade and high availability capabilities,
- Auto-healing of failed instances
- Orchestrates guest API actions
- Raising and clearing operator alarms about instances. Generating operator logs about instances
- Orchestrates the migration of instances off compute hosts being taken administratively out of service
- Orchestrates software patching and upgrades of hosts
High Avaliablity
The StarlingX HA project is a new repository that provideds High Availability Cluster Management for StarlingX and OpenStack Services on Controllers.
New Features¶
- High availability manager to manage the life cycle of services where the redundancy model can be N+M or N across multiple nodes:
- Currently used in StarlingX to provide 1+1 HA Controller Cluster.
- Configured to use multiple messaging paths to avoid split-brain communication failures:
- Up to 3 independent communication paths.
- LAG can also be configured for multi-link protection of each path.
- Messages are authenticated using HMAC SHA-512 if configured / enabled on an interface-by-interface basis.
- Active or passive monitoring of services.
- Allows for specifying the impact of a service failure.
- Completely data driven through the configuration of a SQL database.
Software updates
The StarlingX Update project is a new repository that provides Software Patch (bug fix) management and deployment, and also Software Release Upgrade management.
New Features¶
- Provides the ability to deploy software updates for corrective content and/or new functionality
- Consistent mechanism for patching all layers of the infrastructure stack – kernel all the way up to the openstack services layer
- Rolling update strategy across nodes
- Nodes can be updated in parallel when constraints are not violated
- In-service and reboot required patches supported
- Reboot required for kernel replacement etc.
- For patches that require a reboot, VMs are live migrated off of node
- Comprehensive patch status at node and system level
- REST API, Horizon GUI and “sw-patch” CLI command suites
Tools
These release notes cover the initial release of StarlingX. The StarlingX Tools project is a new repository of tools used in the development, build, test and release of StarlingX.
New Features¶
- Deployment: Scripts to assist in deploying StarlingX in virtual environments, supports both QEMU/KVM and VirtualBox.
- Mirror Tools: Scripts to build and maintain the mirror required to complete the StarlingX build process.
- Release Tools: Scripts used to automate the steps in producing StarlingX milestones and releases.
参考引文:
StarlingX:
【Introducing StarlingX】 https://www.starlingx.io/blog/starlingx-initial-release.html
【A fully featured cloud for the distributed edge】https://www.starlingx.io/collateral/StarlingX_OnePager_Web-102318.pdf
【StarlingX Project Overview】 https://www.starlingx.io/collateral/StarlingX-Onboarding-Deck-for-Web-February-2019.pdf
【电信云/边缘云虚拟层软件StarlingX介绍】https://mp.weixin.qq.com/s/37zYVjflxWJpTf9lgm7xVw
【基于StarlingX的边缘计算机器学习优化】https://mp.weixin.qq.com/s/KlHys9ahjZaHqfrPg0WQJw
【Getting to know StarlingX: The high-performance edge cloud software stack】https://superuser.openstack.org/articles/starlingx-overview/
Openstack:
【8年-我在openstack上走过的路】http://www.sohu.com/a/254076808_610730
【OpenStack从入门到放弃】https://www.cnblogs.com/pythonxiaohu/p/5861409.html
【OpenStack介绍】https://www.cnblogs.com/wensiyang0916/p/6490613.html
EdgeComputing:
【边缘计算与边云协同白皮书2018】 http://www.ecconsortium.org/Uploads/file/20190221/1550718911180625.pdf
【开源网络风云变幻,看各家爱恨情仇】https://www.cnblogs.com/sdnlab1509/p/11083948.html