继续上次的学习内容,写一些自己学习的笔记吧!总是觉得没有笔记的学习总是不那么踏实,我承认自己是个记忆力很差的人,特别羡慕那些可以把自己学过的东西记得很牢靠的人。哎!可惜我不是,那只能做出来点东西,就算以后忘了,回过头来可以看一看,有东西查;毕竟是自己亲手打出来的一个一个字啊![]()
已经一万六千字了!嘿嘿。。。继续加油!
今天公司网络有问题,说是让在家里上班,skype在线就行了。结果我这自觉性不够,就打酱油了!还是继续学习我的mysql吧!我是刚毕业的大学生,学的和写的都是一些最基础的,如果巧遇大牛,还请轻喷!马上就要看完这部视频了,每次看到最后又着急又兴奋的,就像赶紧看完。这里我谈一点对于看视频自学和看书自学的感悟:
看视频适合入门、基础比较薄的需要提升基础知识的人。看视频形象并且有很多的老师讲的例子,我们可以一边看视频一边练习。但是,看视频实在是很耗费时间。而且对于一个有网还是一个人坐在屋子里自学的人来说,自制力有要求啊!不过凡事慢慢看,一点一点积累,只要自己有计划,心里别着急,技术这东西还是记不得的。
看书适合有了一定的基础,对于书上的大部分只是已经有一定的了解和掌握,作为提高和工作中遇到难题来弄懂这一块还是很好地,看书快啊。但是看过去很快就有许多就忘记了,因为书中的每一个知识点,不是我们天天都会用的,不用当让时间一长就忘记了 。所以,看书适合有一点基础,看的过程中不用每一页都是:一行一行的划重点,试想,一本书看完了,这么多重点我都不知道,那我划过去的重点我就都能记住吗?
还记得四月份的时候给我对象处理毕业设计时遇到的乱码问题,我整整弄了三天算是解决了问题,但是自己更本没有弄懂其中的原因,所以借这次刚好好好学习一下,了了自己一个心愿。
我看的是:燕十八老师的mysql从入门到精通 在此感谢十八哥!网络真是伟大,让我们可以免费学的很多东西。大家有想学习的可以去网上找,要是实在是找不到,就留言,我百度网盘分享,1T的资源,估计这辈子都看不完!好了计入正题
ascii
最早的编码集,0-127个,一个字节存储
GB2312
到了中国,常用汉字3000个,生僻字不用说了!
一个字节不够用了?
思考:用两个字节来表示
[][]
0000 0000 0000 0000
1111 1111 1111 1111
0->65535,六万多种组合,够用了
GB2312字符集
[202 197] 假如代表 中
[69 197] 代表什么?69 和197是整个理解,还是单个理解?此时就产生了歧义:就是因为单字节的小于127的值,正好是ascii的值了
如果就严格的2字节绑定,理解成中文
侧GB2312就不能兼容小于127的英文字符了
问:如何兼容ascii,又能两个字节表示中文?
ascii 0-127
0xxx xxxx
干脆 ,gb2312完全不占用0-127
gb2312占用的两个字节的来自[129-255][129-255]
但是这样,中文的组合数也就减少了,大约有一万多
GBK
完全兼容GB2312,只是比GB2312的容量大了,也就是说可以编码更多的字符
GBK和GB2312一样都是两个字节,那么如何扩充容量?
答:GBK的第二位,低位,不在局限于129-255了,<127的也能用了
例如 148 35 65 179 82
问:几个中文,几个英文?
中文 英文 中文
我们可以看出,GBK是当遇到的这个一个字节大于127时,就知道这是中文,后面还有一个字节,当小于127时,就表明这是英文编码,后面没有跟带的字节了。也就是遇到大于127的根据规则,后面还有一个字节,需要在读取;小于时就知道,这是英文,后面没有了
容量:收录汉字21003个、符号883个、并提供1894个造字位
ANSI、Unicode、utf-8
中国 GBK 两个字节
[137][134] –>可能对应-> 中
那么到了日本呢?
[137][134] 对应什么?
日本使用的是 jis 字符集
ANSI 代表本地字符集
这个更你本机的语言设置有关,比如中文的ANSI就是GBK,日文的ANSI就是jis
解决了多字节以后,又有一个问题:如何解决各国的字符集兼容问题?
答案:Unicode(统一码、万国码) 终极大招
解决国际化问题,unicode是什么?就是一个全世界通用的码表,全世界范围的字符,统一分配一个标号,这样就不会乱了
容量:2^32 40多亿,天文数字,足够用了
但是我们常用的,集中在前65535个标号里
因此,两个字节就够了,
请注意:unicode只是负责分配编号,而且都用4个字节来编号,而且和ascii不兼容
unicode只负责分配编号,那么就有其他在不改变unicode的基础上,简化字节
0000 0000 0000 0000 0000 0000 0000 0041 –> A
简化
0000 0041 -> A
把高位浪费的0值,用一定的规则舍弃,这种是形成具体的编码格式(猜想:简化后的编码,可以更加节省带宽,网络传输更快,原因:原来都需要4个字节,现在简化以后可能只需要一个字节)
这样简化以后的编码才能在网络上传输,unicode只是负责分配编号,不进行实际的编码工作,一定需要注意区别!!!!也就是说unicode是字符集,utf-8是字符编码,这里我找了一票博客,推荐给大家
关于字符集和编码的一些基础知识:
1.基础知识
算机中储存的信息都是用二进制数表示的;而我们在屏幕上看到的英文、汉字等字符是二进制数转换之后的结果。通俗的说,按照何种规则将字符存储在计算机中,如'a'用什么表示,称为"编码";反之,将存储在计算机中的二进制数解析显示出来,称为"解码",如同密码学中的加密和解密。在解码过程中,如果使用了错误的解码规则,则导致'a'解析成'b'或者乱码。
字符集(Charset):是一个系统支持的所有抽象字符的集合。字符是各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等。
字符编码(Character Encoding):是一套法则,使用该法则能够对自然语言的字符的一个集合(如字母表或音节表),与其他东西的一个集合(如号码或电脉冲)进行配对。即在符号集合与数字系统之间建立对应关系,它是信息处理的一项基本技术。通常人们用符号集合(一般情况下就是文字)来表达信息。而以计算机为基础的信息处理系统则是利用元件(硬件)不同状态的组合来存储和处理信息的。元件不同状态的组合能代表数字系统的数字,因此字符编码就是将符号转换为计算机可以接受的数字系统的数,称为数字代码。
2.常用字符集和字符编码
常见字符集名称:ASCII字符集、GB2312字符集、BIG5字符集、GB18030字符集、Unicode字符集等。计算机要准确的处理各种字符集文字,需要进行字符编码,以便计算机能够识别和存储各种文字。
详细参考博客:http://www.cnblogs.com/skynet/archive/2011/05/03/2035105.html
继续上面探讨
UTF8/UTF-8
那么怎么简化传输?
这时就出现了utf-8(unicode transformation format)这就是其中最出名的一个
这种简化,就像原文件和压缩文件的关系
问:给定unicode的字符—>utf-8的二进制值?
知道unicode可以推出utf-8,同样utf-8也能推出unicode
问:utf8占几个字节?
首先不可能是定长,否则压缩有什么意义!
我们看看对应表

utf8是一个变长:1-6个字节
变长!那么如何确定字符的边界,即计算机去几个字节,才能知道这个字符正确的取出来了
我们仔细观察上表:
当最高位字节有一个0时(0xxxxxxx)取一个字节,110(110xxxxx 10xxxxxx)取两个字节,1110取三个字节,11110取四个字节,111110取五个字节,1111110x取六个字节
中文utf8占三个字节
推论: 什么时将会乱码?
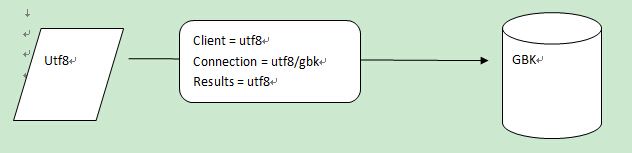
1: client声明与事实不符
2:results与客户端页面不符的时候.
什么时间将会丢失数据?
Connetion和服务器的字符集比client小时.
校对集: 指字符集的排序规则
一种字符集可以有一个或多个排序规则.
以Utf8为例, 我们默认使的utf8_general_ci 规则,也可以按二进制来排, utf8_bin
怎么样声明校对集?
Create table ()... Charset utf8 collate utf8_general_ci;
注意:声明的校对集必须是字符集合法的校对集.
好了,就先这么多吧,待会再发一篇关于mysql字符集的学习。太长了看着人太累,写短一点,一篇记录一个问题