ucore lab8 操作系统实验
实验相关知识
(主要从教学ppt、gitbook、学堂在线上了解掌握并根据CSDN查询了解更加详细的信息。同时结合自己的理论课笔记,实际上是对理论知识的复习)
文件系统:操作系统中负责管理和存储可长期保存数据的软件功能模块
UNIX提出了四个文件系统抽象概念:文件(file)、目录项(dentry)、索引节点(inode)和安装点(mount point)。
- 文件:UNIX文件中的内容可理解为是一有序字节buffer,文件都有一个方便应用程序识别的文件名称(也称文件路径名)。典型的文件操作有读、写、创建和删除等。
- 目录项:目录项不是目录(又称文件路径),而是目录的组成部分。在UNIX中目录被看作一种特定的文件,而目录项是文件路径中的一部分。如一个文件路径名是“/test/testfile”,则包含的目录项为:根目录“/”,目录“test”和文件“testfile”,这三个都是目录项。一般而言,目录项包含目录项的名字(文件名或目录名)和目录项的索引节点(见下面的描述)位置。
- 索引节点:UNIX将文件的相关元数据信息(如访问控制权限、大小、拥有者、创建时间、数据内容等等信息)存储在一个单独的数据结构中,该结构被称为索引节点。
- 安装点:在UNIX中,文件系统被安装在一个特定的文件路径位置,这个位置就是安装点。所有的已安装文件系统都作为根文件系统树中的叶子出现在系统中。
从ucore操作系统不同的角度来看,ucore中的文件系统架构包含四类主要的数据结构:
- 超级块(SuperBlock),它主要从文件系统的全局角度描述特定文件系统的全局信息。它的作用范围是整个OS空间。
- 索引节点(inode):它主要从文件系统的单个文件的角度它描述了文件的各种属性和数据所在位置。它的作用范围是整个OS空间。
- 目录项(dentry):它主要从文件系统的文件路径的角度描述了文件路径中的一个特定的目录项(注:一系列目录项形成目录/文件路径)。它的作用范围是整个OS空间。对于SFS而言,inode(具体为struct sfs_disk_inode)对应于物理磁盘上的具体对象,dentry(具体为struct sfs_disk_entry)是一个内存实体,其中的ino成员指向对应的inode number,另外一个成员是file name(文件名).
- 文件(file),它主要从进程的角度描述了一个进程在访问文件时需要了解的文件标识,文件读写的位置,文件引用情况等信息。它的作用范围是某一具体进程。
索引节点inode:每个inode都有一个号码,操作系统用inode号码(而不是文件名)来识别不同的文件。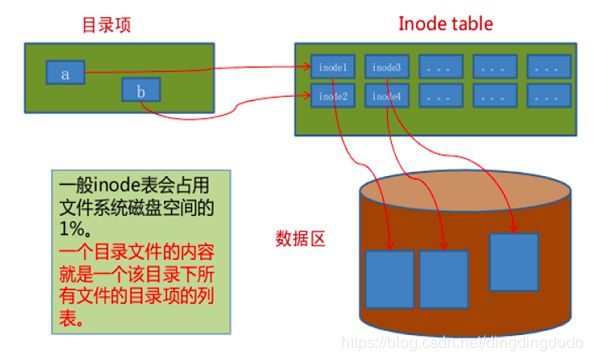
ucore文件的总体布局:(模仿了UNIX的文件系统设计,ucore的文件系统架构主要由四部分组成:通用文件系统访问接口层,文件系统抽象层,Simple FS文件系统层,外设接口层)

实验过程
练习00:实验开始前
正式实验开始前,针对具体的实验内容展开一些学习:
1.新增的数据结构
file结构体表示进程在内核中直接访问的文件相关信息:
struct file {
enum {
FD_NONE, FD_INIT, FD_OPENED, FD_CLOSED,
} status; //访问文件的执行状态
bool readable; //文件是否可读
bool writable; //文件是否可写
int fd; //文件在filemap中的索引值
off_t pos; //访问文件的当前位置
struct inode *node; //该文件对应的内存inode指针
int open_count; //打开此文件的次数
};
files_struct结构中描述了进程访问文件的数据接口信息:
struct files_struct {
struct inode *pwd; //进程当前执行目录的内存inode指针
struct file *fd_array; //进程打开文件的数组
atomic_t files_count; //访问此文件的线程个数
semaphore_t files_sem; //确保对进程控制块中fs_struct的互斥访问
};
inode是位于内存的索引节点,负责把不同文件系统的特定索引节点信息统一封装起来,避免了进程直接访问具体文件系统。
struct inode {
union { //包含不同文件系统特定inode信息的union成员变量
struct device __device_info; //设备文件系统内存inode信息
struct sfs_inode __sfs_inode_info; //SFS文件系统内存inode信息
} in_info;
enum {
inode_type_device_info = 0x1234,
inode_type_sfs_inode_info,
} in_type; //此inode所属文件系统类型
atomic_t ref_count; //此inode的引用计数
atomic_t open_count; //打开此inode对应文件的个数
struct fs *in_fs; //抽象的文件系统,包含访问文件系统的函数指针
const struct inode_ops *in_ops; //抽象的inode操作,包含访问inode的函数指针
};
第三个磁盘(即disk0,前两个磁盘分别是 ucore.img 和 swap.img)用于存放一个SFS文件系统(Simple Filesystem)。该磁盘的第0个块(4K)是超级块(superblock),它包含了关于文件系统的所有关键参数,当计算机被启动或文件系统被首次接触时,超级块的内容就会被装入内存。其定义如下:
struct sfs_super {
uint32_t magic; //魔数magic,内核通过它来检查磁盘镜像是否是合法的 SFS img
uint32_t blocks; //记录了SFS中所有block的数量
uint32_t unused_blocks; //记录了SFS中还没有被使用的block的数量
char info[SFS_MAX_INFO_LEN + 1]; /* infomation for sfs */
};
磁盘索引节点:SFS中的磁盘索引节点代表了一个实际位于磁盘上的文件,从代码看磁盘索引节点的内容
struct sfs_disk_inode {
uint32_t size; // 如果inode表示常规文件,则size是文件大小
uint16_t type; // inode的文件类型
uint16_t nlinks; // 此inode的硬链接数
uint32_t blocks; // 此inode的数据块数的个数
uint32_t direct[SFS_NDIRECT]; // 此inode的直接数据块索引值(有SFS_NDIRECT个)
uint32_t indirect; // 此inode的一级间接数据块索引值
};
indirect间接指向了保存文件内容数据的数据块,indirect指向的是间接数据块,此数据块实际存放的全部是数据块索引,这些数据块索引指向的数据块才被用来存放文件内容数据。
struct device结构体 表示一个设备
struct device {
size_t d_blocks; //设备占用的数据块个数
size_t d_blocksize; //数据块的大小
int (*d_open)(struct device *dev, uint32_t open_flags); //打开设备的函数指针
int (*d_close)(struct device *dev); //关闭设备的函数指针
int (*d_io)(struct device *dev, struct iobuf *iob, bool write); //读写设备的函数指针
int (*d_ioctl)(struct device *dev, int op, void *data); //用ioctl方式控制设备的函数指针
};
该数据结构能够支持对块设备(比如磁盘)、字符设备(比如键盘、串口)的表示,完成对设备的基本操作。
vfs_dev_t结构体将device和inode联通起来:
// device info entry in vdev_list
typedef struct {
const char *devname;
struct inode *devnode;
struct fs *fs;
bool mountable;
list_entry_t vdev_link;
} vfs_dev_t;
利用该数据结构,就可以让文件系统通过一个链接vfs_dev_t结构的双向链表找到device对应的inode数据结构。
基于这些数据结构,文件系统大致的表示已经基本完成,当然还有很多复杂的操作,下面将介绍。
2.文件系统的初始化过程:
总控函数kern_init() 增添了fs_init()对文件管理系统的初始化。查看fs_init()代码:
//called when init_main proc start
void
fs_init(void) {
vfs_init();
dev_init();
sfs_init();
}
可知调用fs_init()将调用vfs_init()、dev_init()、sfs_init()进行初始化。
vfs_init()函数:
// vfs_init - vfs initialize
void
vfs_init(void) {
sem_init(&bootfs_sem, 1);
vfs_devlist_init();
}
调用了两个init函数,分别为初始化信号量以及创建并初始化用于管理设备的链表。
dev_init()函数:
/* dev_init - Initialization functions for builtin vfs-level devices. */
void
dev_init(void) {
// init_device(null);
init_device(stdin);
init_device(stdout);
init_device(disk0);
}
dev_init()函数完成对输入设备、输出设备、disk0的初始化。
sys_init()完成对信号量的初始化。
以上便是对文件系统的初始化大概。
练习0:填写已有实验
主要有两个地方需要小修改:(这两处修改实际上应该在lab2修改,但在此修改有助于检测实验是否正确完成)
alloc_proc函数和do_fork函数:
static struct proc_struct *alloc_proc(void)
{
....
// 初始化 PCB 下的 fs(进程相关的文件信息)
proc->filesp = NULL;
.....
}
int
do_fork(uint32_t clone_flags, uintptr_t stack, struct trapframe *tf){
....
//分配内核栈
if (setup_kstack(proc) != 0) {
goto bad_fork_cleanup_proc;
}
// 使用 copy_files()函数复制父进程的fs到子进程中
if (copy_files(clone_flags, proc) != 0) {
goto bad_fork_cleanup_kstack;
}
//调用copy_mm()函数复制父进程的内存信息到子进程
if (copy_mm(clone_flags, proc) != 0) {
goto bad_fork_cleanup_kstack;
}
....
}
练习1: 完成读文件操作的实现(需要编码)
首先了解打开文件的处理流程,然后参考本实验后续的文件读写操作的过程分析,编写在sfs_inode.c中sfs_io_nolock读文件中数据的实现代码。
请在实验报告中给出设计实现”UNIX的PIPE机制“的概要设方案,鼓励给出详细设计方案
答:
1.读文件以及打开文件的过程:
首先查看syscall.c可知ucore增添了一些新的系统调用,包括sys_read,sys_write等对文件的读写操作,查看sys_read的代码:
static int
sys_read(uint32_t arg[]) {
int fd = (int)arg[0];
void *base = (void *)arg[1];
size_t len = (size_t)arg[2];
return sysfile_read(fd, base, len);
}
可知,该系统调用函数sys_read将调用sysfile_read内核函数来进入到文件系统抽象层处理流程完成进一步的读文件操作,查看sfile_read函数代码可知,在这个函数中,创建了大小有限的缓冲区,用于从文件读取数据之后,进一步复制到用户空间的指定位置去,之后该函数将调用file_read函数,通过文件描述符查找到了相应文件对应的内存中的inode信息,然后转交给vop_read进行读取处理,vop_read函数进入到文件系统实例的读操作接口。vop_read函数是对sfs_read的包装,将用sfs_io函数完成文件的读取:先找到inode对应sfs和sin,然后调用sfs_io_nolock函数进行读取文件操作,最后调用iobuf_skip函数调整iobuf的指针
在这里,sfs_io函数将调用sfs_io_nolock函数,而这个函数也正是练习1的内容。
在这里我们结合gitbook上的知识,来更加具体地分析一下ucore打开文件的过程:
如果要打开的文件就在磁盘上,那调用safe_open即可,如下:
int fd1 = safe_open("sfs\_filetest1", O_RDONLY);
如果ucore能够正常查找到这个文件,就会返回一个代表文件的文件描述符fd1。
进入通用文件访问接口层的处理流程后,用户态函数调用顺序open->sys_open->syscall从而引起系统调用进入到内核态。之后通过中断处理例程,会调用到sys_open内核函数,并进一步调用sysfile_open内核函数。然后需要把位于用户空间的字符串”sfs_filetest1”拷贝到内核空间中的字符串path中,并进入到文件系统抽象层的处理流程完成进一步的打开文件操作中。
在文件系统抽象层,将分配一个空闲的file数据结构变量file在文件系统抽象层的处理中(当前进程的打开文件数组current->fs_struct->filemap[]中的一个空闲元素。然后进一步调用vfs_open函数来找到path指出的文件所对应的基于inode数据结构的VFS索引节点node。然后调用vop_open函数打开文件。然后层层返回,通过执行语句file->node=node;,就把当前进程的current->fs_struct->filemap[fd](即file所指变量)的成员变量node指针指向了代表文件的索引节点node。这时返回fd。最后完成打开文件的操作。
2.sfs_io_nolock函数补充
之后我们来分析完成编写在sfs_inode.c中sfs_io_nolock读文件中数据的实现代码。
sfs_io_nolock函数主要用来将磁盘中的一段数据读入到内存中或者将内存中的一段数据写入磁盘。
该函数会进行一系列的边缘检查,检查访问是否越界、是否合法。之后将具体的读/写操作使用函数指针统一起来,统一成针对整块的操作。然后完成不落在整块数据块上的读/写操作,以及落在整块数据块上的读写。下面是该函数的代码(包括补充的代码,其中将有较为详细的注释)
(结合练习所给的注释还是较为容易写出来的)
static int
sfs_io_nolock(struct sfs_fs *sfs, struct sfs_inode *sin, void *buf, off_t offset, size_t *alenp, bool write)
{ //创建一个磁盘索引节点指向要访问文件的内存索引节点
struct sfs_disk_inode *din = sin->din;
assert(din->type != SFS_TYPE_DIR);
//确定读取的结束位置
off_t endpos = offset + *alenp, blkoff;
*alenp = 0;
// 进行一系列的边缘,避免非法访问
if (offset < 0 || offset >= SFS_MAX_FILE_SIZE || offset > endpos) {
return -E_INVAL;
}
if (offset == endpos) {
return 0;
}
if (endpos > SFS_MAX_FILE_SIZE) {
endpos = SFS_MAX_FILE_SIZE;
}
if (!write) {
if (offset >= din->size) {
return 0;
}
if (endpos > din->size) {
endpos = din->size;
}
}
int (*sfs_buf_op)(struct sfs_fs *sfs, void *buf, size_t len, uint32_t blkno, off_t offset);
int (*sfs_block_op)(struct sfs_fs *sfs, void *buf, uint32_t blkno, uint32_t nblks);
//确定是读操作还是写操作,并确定相应的系统函数
if (write) {
sfs_buf_op = sfs_wbuf, sfs_block_op = sfs_wblock;
}
else {
sfs_buf_op = sfs_rbuf, sfs_block_op = sfs_rblock;
}
//
int ret = 0;
size_t size, alen = 0;
uint32_t ino;
uint32_t blkno = offset / SFS_BLKSIZE; // The NO. of Rd/Wr begin block
uint32_t nblks = endpos / SFS_BLKSIZE - blkno; // The size of Rd/Wr blocks
// 判断被需要操作的区域的数据块中的第一块是否是完全被覆盖的,
// 如果不是,则需要调用非整块数据块进行读或写的函数来完成相应操作
if ((blkoff = offset % SFS_BLKSIZE) != 0) {
// 第一块数据块中进行操作的偏移量
blkoff = offset % SFS_BLKSIZE;
// 第一块数据块中进行操作的数据长度
size = (nblks != 0) ? (SFS_BLKSIZE - blkoff) : (endpos - offset);
//获取这些数据块对应到磁盘上的数据块的编号
if ((ret = sfs_bmap_load_nolock(sfs, sin, blkno, &ino)) != 0) {
goto out;
}
//对数据块进行读或写操作
if ((ret = sfs_buf_op(sfs, buf, size, ino, blkoff)) != 0) {
goto out;
}
//已经完成读写的数据长度
alen += size;
if (nblks == 0) {
goto out;
}
buf += size, blkno++; nblks--;
}
////读取中间部分的数据,将其分为大小为size的块,然后一块一块操作,直至完成
size = SFS_BLKSIZE;
while (nblks != 0)
{
if ((ret = sfs_bmap_load_nolock(sfs, sin, blkno, &ino)) != 0) {
goto out;
}
//对数据块进行读或写操作
if ((ret = sfs_block_op(sfs, buf, ino, 1)) != 0) {
goto out;
}
//更新相应的变量
alen += size, buf += size, blkno++, nblks--;
}
// 最后一页,可能出现不对齐的现象:
if ((size = endpos % SFS_BLKSIZE) != 0)
{
// 获取该数据块对应到磁盘上的数据块的编号
if ((ret = sfs_bmap_load_nolock(sfs, sin, blkno, &ino)) != 0) {
goto out;
}
// 进行非整块的读或者写操作
if ((ret = sfs_buf_op(sfs, buf, size, ino, 0)) != 0) {
goto out;
}
alen += size;
}
out:
*alenp = alen;
if (offset + alen > sin->din->size) {
sin->din->size = offset + alen;
sin->dirty = 1;
}
return ret;
}
总的来说就是分为三部分来读取文件,每次通过sfs_bmap_load_nolock函数获取文件索引编号,然后调用sfs_buf_op或者sfs_block_op完成实际的文件读写操作。
至此练习1的编码工作完成。
3.PIPE机制
请在实验报告中给出设计实现”UNIX的PIPE机制“的概要设方案,鼓励给出详细设计方案
管道可用于具有亲缘关系进程间的通信,管道是由内核管理的一个缓冲区,相当于我们放入内存中的一个纸条。管道的一端连接一个进程的输出。这个进程会向管道中放入信息。管道的另一端连接一个进程的输入,这个进程取出被放入管道的信息。一个缓冲区不需要很大,它被设计成为环形的数据结构,以便管道可以被循环利用。当管道中没有信息的话,从管道中读取的进程会等待,直到另一端的进程放入信息。当管道被放满信息的时候,尝试放入信息的进程会等待,直到另一端的进程取出信息。当两个进程都终结的时候,管道也自动消失。
在 Linux 中,管道的实现并没有使用专门的数据结构,而是借助了文件系统的file结构和VFS的索引节点inode。通过将两个 file 结构指向同一个临时的 VFS 索引节点,而这个 VFS 索引节点又指向一个物理页面而实现的。管道机制
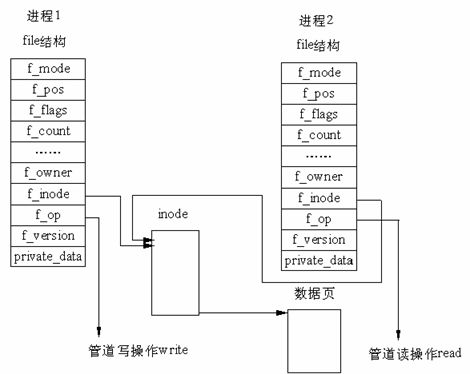
管道可以看作是由内核管理的一个缓冲区,一端连接进程A的输出,另一端连接进程B的输入。进程A会向管道中放入信息,而进程B会取出被放入管道的信息。当管道中没有信息,进程B会等待,直到进程A放入信息。当管道被放满信息的时候,进程A会等待,直到进程B取出信息。当两个进程都结束的时候,管道也自动消失。管道基于fork机制建立,从而让两个进程可以连接到同一个PIPE上。
基于此,我们可以模仿UNIX,设计一个PIPE机制。
- 首先我们需要在磁盘上保留一定的区域用来作为PIPE机制的缓冲区,或者创建一个文件为PIPE机制服务
- 对系统文件初始化时将PIPE也初始化并创建相应的inode
- 在内存中为PIPE留一块区域,以便高效完成缓存
- 当两个进程要建立管道时,那么可以在这两个进程的进程控制块上新增变量来记录进程的这种属性
- 当其中一个进程要对数据进行写操作时,通过进程控制块的信息,可以将其先对临时文件PIPE进行修改
- 当一个进行需要对数据进行读操作时,可以通过进程控制块的信息完成对临时文件PIPE的读取
- 增添一些相关的系统调用支持上述操作
至此,PIPE的大致框架已经完成。
练习2: 完成基于文件系统的执行程序机制的实现(需要编码)
改写proc.c中的load_icode函数和其他相关函数,实现基于文件系统的执行程序机制。
执行:make qemu。如果能看看到sh用户程序的执行界面,则基本成功了。如果在sh用户界面上可以执行”ls”,”hello”等其他放置在sfs文件系统中的其他执行程序,则可以认为本实验基本成功。
请在实验报告中给出设计实现基于”UNIX的硬链接和软链接机制“的概要设方案,鼓励给出详细设计方案
1.改写proc.c
具体来说是对proc.c的alloc_page以及do_fork以及load_icode函数进行修改,其中对前两个函数的修改在练习0中已经完成,在此不做赘述。
对load_icode进行修改使其支持文件系统。实际上,该函数的总体思想与框架并没有发生太大变化,与之前的load_icode挺相似,故在之前的基础上,对需要修改的地方进行处理即可。
之前的load_icode函数,将原先就加载到了内核内存空间中的ELF可执行文件加载到用户内存空间中,而在这个练习中我们希望实现的是于从磁盘上读取可执行文件,并且加载到内存中,完成内存空间的初始化。
load_icode函数功能:
load_icode函数的主要工作就是给用户进程建立一个能够让用户进程正常运行的用户环境。基本流程:
- 调用
mm_create函数来申请进程的内存管理数据结构mm所需内存空间,并对mm进行初始化; - 调用
setup_pgdir来申请一个页目录表所需的一个页大小的内存空间,并把描述ucore内核虚空间映射的内核页表(boot_pgdir所指)的内容拷贝到此新目录表中,最后让mm->pgdir指向此页目录表,这就是进程新的页目录表了,且能够正确映射内核虚空间; - 将磁盘中的文件加载到内存中,并根据应用程序执行码的起始位置来解析此ELF格式的执行程序,并根据ELF格式的执行程序说明的各个段(代码段、数据段、BSS段等)的起始位置和大小建立对应的vma结构,并把vma插入到mm结构中,从而表明了用户进程的合法用户态虚拟地址空间;
- 调用根据执行程序各个段的大小分配物理内存空间,并根据执行程序各个段的起始位置确定虚拟地址,并在页表中建立好物理地址和虚拟地址的映射关系,然后把执行程序各个段的内容拷贝到相应的内核虚拟地址中
- 需要给用户进程设置用户栈,并处理用户栈中传入的参数
- 先清空进程的中断帧,再重新设置进程的中断帧,使得在执行中断返回指令“iret”后,能够让CPU转到用户态特权级,并回到用户态内存空间,使用用户态的代码段、数据段和堆栈,且能够跳转到用户进程的第一条指令执行,并确保在用户态能够响应中断;
大致可以简单分为以下部分:
将文件加载到内存中执行,根据注释的提示分为了一共七个步骤:
- 建立内存管理器
- 建立页目录
- 将文件逐个段加载到内存中,这里要注意设置虚拟地址与物理地址之间的映射
- 建立相应的虚拟内存映射表
- 建立并初始化用户堆栈
- 处理用户栈中传入的参数
- 最后很关键的一步是设置用户进程的中断帧
对代码进行coding(由于代码量非常大,故我遇到一些错误,在此处部分参考了答案的实现才正确完成):
代码如下,其中我对整个代码过程进行了详细的说明:
//从磁盘上读取可执行文件,并且加载到内存中,完成内存空间的初始化
static int load_icode(int fd, int argc, char **kargv)
{
//判断当前进程的内存管理是否已经被释放掉了,我们需要要求当前内存管理器为空
if (current->mm != NULL)
{
panic("load_icode: current->mm must be empty.\n");
}
int ret = -E_NO_MEM;
//1.调用mm_create函数来申请进程的内存管理数据结构mm所需内存空间,并对mm进行初始化
struct mm_struct *mm;
if ((mm = mm_create()) == NULL) {
goto bad_mm;
}
//2.申请新目录项的空间并完成目录项的设置
if (setup_pgdir(mm) != 0) {
goto bad_pgdir_cleanup_mm;
}
//创建页表
struct Page *page;
//3.从文件从磁盘中加载程序到内存
struct elfhdr __elf, *elf = &__elf;
//3.1调用load_icode_read函数读取ELF文件
if ((ret = load_icode_read(fd, elf, sizeof(struct elfhdr), 0)) != 0)
{
goto bad_elf_cleanup_pgdir;
}
//判断这个文件是否合法
if (elf->e_magic != ELF_MAGIC) {
ret = -E_INVAL_ELF;
goto bad_elf_cleanup_pgdir;
}
struct proghdr __ph, *ph = &__ph;
uint32_t i;
uint32_t vm_flags, perm;
//e_phnum代表程序段入口地址数目
for (i = 0; i < elf->e_phnum; ++i)
{
//3.2循环读取程序的每个段的头部
if ((ret = load_icode_read(fd, ph, sizeof(struct proghdr), elf->e_phoff + sizeof(struct proghdr) * i)) != 0)
{
goto bad_elf_cleanup_pgdir;
}
if (ph->p_type != ELF_PT_LOAD) {
continue ;
}
if (ph->p_filesz > ph->p_memsz) {
ret = -E_INVAL_ELF;
goto bad_cleanup_mmap;
}
if (ph->p_filesz == 0) {
continue ;
}
//3.3建立对应的VMA
vm_flags = 0, perm = PTE_U; //建立虚拟地址与物理地址之间的映射
// 根据ELF文件中的信息,对各个段的权限进行设置
if (ph->p_flags & ELF_PF_X) vm_flags |= VM_EXEC;
if (ph->p_flags & ELF_PF_W) vm_flags |= VM_WRITE;
if (ph->p_flags & ELF_PF_R) vm_flags |= VM_READ;
if (vm_flags & VM_WRITE) perm |= PTE_W;
//虚拟内存地址设置为合法的
if ((ret = mm_map(mm, ph->p_va, ph->p_memsz, vm_flags, NULL)) != 0) {
goto bad_cleanup_mmap;
}
//3.4为数据段代码段等分配页
off_t offset = ph->p_offset;
size_t off, size;
//计算数据段和代码段的开始地址
uintptr_t start = ph->p_va, end, la = ROUNDDOWN(start, PGSIZE);
ret = -E_NO_MEM;
//计算数据段和代码段终止地址
end = ph->p_va + ph->p_filesz;
while (start < end)
{ // 为TEXT/DATA段逐页分配物理内存空间
if ((page = pgdir_alloc_page(mm->pgdir, la, perm)) == NULL)
{
goto bad_cleanup_mmap;
}
off = start - la, size = PGSIZE - off, la += PGSIZE;
if (end < la) {
size -= la - end;
}
// 将磁盘上的TEXT/DATA段读入到分配好的内存空间中去
//每次读取size大小的块,直至全部读完
if ((ret = load_icode_read(fd, page2kva(page) + off, size, offset)) != 0)
{
goto bad_cleanup_mmap;
}
start += size, offset += size;
}
//3.5为BBS段分配页
//计算BBS的终止地址
end = ph->p_va + ph->p_memsz;
if (start < la) {
if (start == end) {
continue ;
}
off = start + PGSIZE - la, size = PGSIZE - off;
if (end < la)
{
size -= la - end;
}
memset(page2kva(page) + off, 0, size);
start += size;
assert((end < la && start == end) || (end >= la && start == la));
}
// 如果没有给BSS段分配足够的页,进一步进行分配
while (start < end) {
if ((page = pgdir_alloc_page(mm->pgdir, la, perm)) == NULL) {
goto bad_cleanup_mmap;
}
off = start - la, size = PGSIZE - off, la += PGSIZE;
if (end < la) {
size -= la - end;
}
// 将分配到的空间清零初始化
memset(page2kva(page) + off, 0, size);
start += size;
}
}
sysfile_close(fd);//关闭文件,加载程序结束
// 4.设置用户栈
vm_flags = VM_READ | VM_WRITE | VM_STACK; //设置用户栈的权限
//将用户栈所在的虚拟内存区域设置为合法的
if ((ret = mm_map(mm, USTACKTOP - USTACKSIZE, USTACKSIZE, vm_flags, NULL)) != 0) {
goto bad_cleanup_mmap;
}
assert(pgdir_alloc_page(mm->pgdir, USTACKTOP-PGSIZE , PTE_USER) != NULL);
assert(pgdir_alloc_page(mm->pgdir, USTACKTOP-2*PGSIZE , PTE_USER) != NULL);
assert(pgdir_alloc_page(mm->pgdir, USTACKTOP-3*PGSIZE , PTE_USER) != NULL);
assert(pgdir_alloc_page(mm->pgdir, USTACKTOP-4*PGSIZE , PTE_USER) != NULL);
//设置当前进程的mm、cr3等
mm_count_inc(mm);
current->mm = mm;
current->cr3 = PADDR(mm->pgdir);
lcr3(PADDR(mm->pgdir));
//为用户空间设置trapeframe
uint32_t argv_size=0, i;
//确定传入给应用程序的参数具体应当占用多少空间
uint32_t total_len = 0;
for (i = 0; i < argc; ++i)
{
total_len += strnlen(kargv[i], EXEC_MAX_ARG_LEN) + 1;
// +1表示字符串结尾的'\0'
}
// 用户栈顶减去所有参数加起来的长度,与4字节对齐找到真正存放字符串参数的栈的位置
char *arg_str = (USTACKTOP - total_len) & 0xfffffffc;
//存放指向字符串参数的指针
int32_t *arg_ptr = (int32_t *)arg_str - argc;
// 根据参数需要在栈上占用的空间来推算出,传递了参数之后栈顶的位置
int32_t *stacktop = arg_ptr - 1;
*stacktop = argc;
for (i = 0; i < argc; ++i)
{
uint32_t arg_len = strnlen(kargv[i], EXEC_MAX_ARG_LEN);
strncpy(arg_str, kargv[i], arg_len);
*arg_ptr = arg_str;
arg_str += arg_len + 1;
++arg_ptr;
}
//6.设置进程的中断帧
//设置tf相应的变量的设置,包括:tf_cs、tf_ds tf_es、tf_ss tf_esp, tf_eip, tf_eflags
struct trapframe *tf = current->tf;
memset(tf, 0, sizeof(struct trapframe));
tf->tf_cs = USER_CS;
tf->tf_ds = tf->tf_es = tf->tf_ss = USER_DS;
tf->tf_esp = stacktop;
tf->tf_eip = elf->e_entry;
tf->tf_eflags |= FL_IF;
ret = 0;
out:
return ret;
//一些错误的处理
bad_cleanup_mmap:
exit_mmap(mm);
bad_elf_cleanup_pgdir:
put_pgdir(mm);
bad_pgdir_cleanup_mm:
mm_destroy(mm);
bad_mm:
goto out;
}
至此,完成了本实验的编码任务。
执行make qemu
在此处输入回车,会显示$键让输入:
2.UNIX的硬链接和软链接机制
硬链接:是给文件一个副本,同时建立两者之间的连接关系
软链接:符号连接
硬链接和软链接的主要特征:
由于硬链接是有着相同 inode 号仅文件名不同的文件,因此硬链接存在以下几点特性:
- 文件有相同的 inode 及 data block;
- 只能对已存在的文件进行创建;
- 不能交叉文件系统进行硬链接的创建;
- 不能对目录进行创建,只可对文件创建;
- 删除一个硬链接文件并不影响其他有相同 inode 号的文件
软链接的创建与使用没有类似硬链接的诸多限制:
- 软链接有自己的文件属性及权限等;
- 可对不存在的文件或目录创建软链接;
- 软链接可交叉文件系统;
- 软链接可对文件或目录创建;
- 创建软链接时,链接计数 i_nlink 不会增加;
- 删除软链接并不影响被指向的文件,但若被指向的原文件被删除,则相关软连接被称为死链接(即 dangling link,若被指向路径文件被重新创建,死链接可恢复为正常的软链接)。
保存在磁盘上的inode信息均存在一个nlinks变量用于表示当前文件的被链接的计数,因而支持实现硬链接和软链接机制;
- 创建硬链接link时,为new_path创建对应的file,并把其inode指向old_path所对应的inode,inode的引用计数加1。
- 创建软连接link时,创建一个新的文件(inode不同),并把old_path的内容存放到文件的内容中去,给该文件保存在磁盘上时disk_inode类型为SFS_TYPE_LINK,再完善对于该类型inode的操作即可。
- 删除一个软链接B的时候,直接将其在磁盘上的inode删掉即可;但删除一个硬链接B的时候,除了需要删除掉B的inode之外,还需要将B指向的文件A的被链接计数减1,如果减到了0,则需要将A删除掉;
- 问硬链接的方式与访问软链接是一致的;
如果给你带来了帮助,可点击关注,博主将继续努力推出好文。