ElasticSearch (ES)学习之路(四)ES 中个别专有名词解释,以及在Kibanna中使用Resful风格操作ES
ElasticSearch (ES)学习之路(四)ES 中个别专有名词解释,以及在Kibanna中使用Resful风格操作ES
(一)个别名词解释:
Cluster (集群)
一个集群包含一个或多个分配了相同的集群名称的节点。每个集群都有一个主节点是集群自动选择产生,并且可以决定如果当前主节点失败,哪些可以替换。其下载解压 后实质也是一个集群 ,只有一个节点而已 (一个人也是一支军队原则)
Document(文档)
文档是存储在elasticsearch中的一个JSON文件。这是相当与关系数据库中表的一行数据。每个文档被存储在索引中,并具有一个类型和一个id。一个文档是一个JSON对象
Index(索引)
索引就是像关系数据库中的“数据库”。通过映射可以定义成多种类型。索引是一个逻辑命名空间映射到一个或多个主要的分片,可以有零个或多个副本分片。
Type(类型)
Type是相当于关系数据库的“表”。每种类型都有一列字段,用来定义文档的类型。映射定义了对在文档中的每个字段如何进行分析。 es 8.x 的时候好像是会删除此规则
Id(标识)
每个文档ID标识了一个文档。一个文档的索引/类型/ ID必须是唯一的。如果没有提供ID,将是自动生成。(还可以看到路由)
Field(字段)
文档中包含的一组字段或键值对。字段的值可以是一个简单的(标量)值(如字符串,整数,日期),或者一个嵌套的结构就像一个数组或对象。一个字段就是类似关系数据库表中的一列。映射的每个字段有一个字段的类型“type”(不要与文档类型混淆),表示那种类型的数据可以存储在该字段里,如:整数,字符串,对象。映射还允许你定义(除其他事项外)一个字段的值如何进行分析。
Mapping(映射)
映射是像关系数据库中的”模式定义“。每个索引都有一个映射,它定义了每个索引的类型,再加上一些索引范围的设置。映射可以被明确地定义,或者在一个文档被索引的时候自动生成。
Node(节点)
节点是属于elasticsearch群集的运行实例。测试的时候,在一台服务器可以启动多个节点,但通常情况下应该在一台服务器运行一个节点。在启动时,节点将使用单播(或组播,但是必须指定)来发现使用相同的群集名称的群集,并会尝试加入该群集。
Text(文本)
文本(或全文)是普通非结构化的文本,如本段。默认情况下,文本将被分析成术语,术语才是实际存储在索引中。文本字段在索引时需要进行分析,以便全文搜索,全文查询的关键字在搜索时,必须分析产生(搜索)与索引时相同的术语。
(二)Kibana操作ES
说明:如果觉得枯燥难懂,看起来吃力的话, 暂时可直接 将 索引名 认定为关系型数据库的 数据库名 ,类型名 认定为 表名, 文档 则对应着某行 文档ID 某行主键。
(1)Restful 风格 ES 操作概览
| 请求方式 | 请求地址 | 功能描述 |
|---|---|---|
| PUT | localhost:9200/索引名/类型名/文档ID | 创建文档 且指明ID |
| POST | localhost:9200/索引名/类型名 | 创建文档 随机生成ID |
| GET | localhost:9200/索引名/类型名/文档ID | 精确到获取某一具体文档(根据ID) |
| DELETE | localhost:/索引名/类型名/文档ID | 精确到 删除某一文档(根据ID) |
| POST | localhost:9200/索引名/类型名/文档ID/_update | 修改某一文档 |
| GET | localhost:9200/索引名/类型名/_search | 查找当前索引文档下全部数据 |
(2)索引操作
创建索引
PUT /索引名/类型名/文档ID
{"请求体"}
-----------
PUT /索引名/类型名
{"请求体"}
此类型名 可省略不写 其默认就会存在_doc 类型名下 在8.x的时候 类型 会被移除
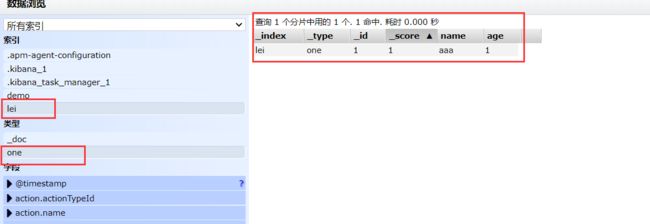
示例:创建一个名为’lei’的索引库 类型名 为 one 指定一个文档ID 为1 这里实质就是 创建索引 ,类型,并插入一条文档 文档ID 为1
PUT /lei/one/1
{
"name":"aa",
"age":1
}

可视化界面查看数据
可以发现 此索引成功创建 且插入了一条文档
删除索引
根据url 进行不同粒度的删除
DELETE /索引名/类型名/文档ID
DELETE /索引名
DELETE /lei 删除整个 lei 索引库
DELETE /lei/one/1 删除lei 索引库 下 类型名为one ,文档ID 为1 的数据
创建索引 且指定字段类型
上边数据我们已经是成功插入了进去,但是发现一个问题,就是这个文档列不用指定类型吗?那我上一条插入的数据 是什么类型呢? name? age?
查看一下 发现es 给我们默认配置了类型
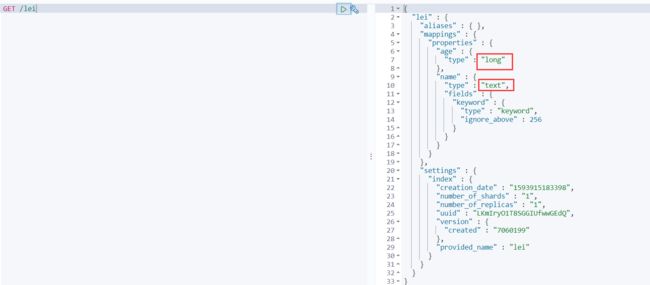
发现其默认的给我们设定的列 name ,age 指定了两个数据类型,可能这两种类型并不是我们在插入时想要设置的类型,那么是否可以自定义设置插入的数据类型,且插入的数据的类型严格按照我们的要求来呢??
答案,当然是可以的!
下表为es 中支持的数据类型
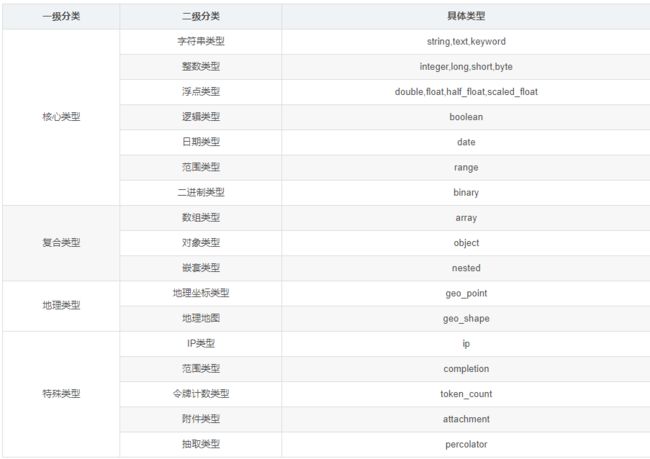
那么,接下来,咱们自定义一个索引库 ,且设置字段属性约束
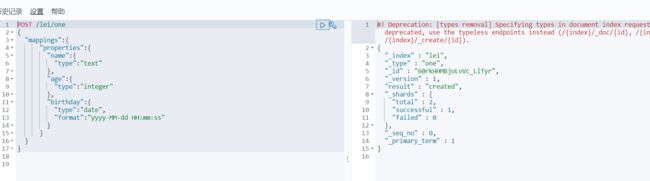
使用 mappings properties 进行设置字段类型 然后查看
POST /lei/one
{
"mappings":{
"properties":{
"name":{
"type":"text"
},
"age":{
"type":"integer"
},
"birthday":{
"type":"date",
"format":"yyyy-MM-dd HH:mm:ss"
}
}
}
}
(3)文档操作
创建文档
PUT /索引名/类型名/文档ID
{"请求体"}
--------------------
POST /索引名/类型名
{"请求体"}
注意哈 /lei 索引库 我们给字段是添加了约束的 索引请求体格式也必须安装其要求来哟!
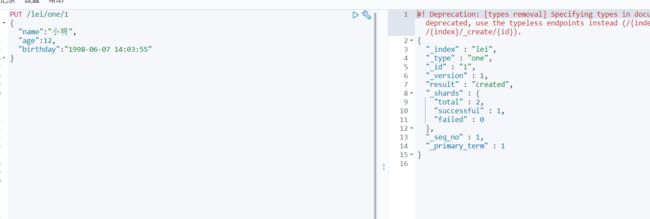
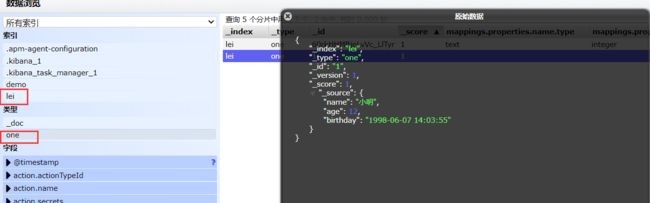
PUT方式
PUT /lei/one/1
{
"name":"小明",
"age":12,
"birthday":"1998-06-07 14:03:55"
}
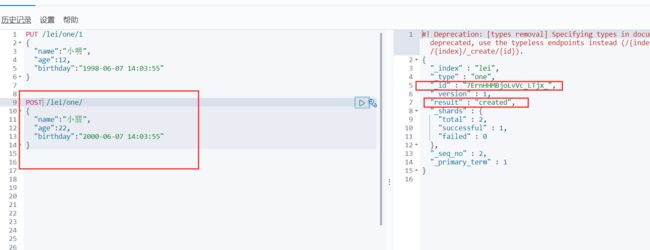
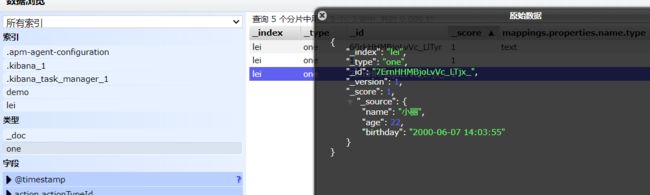
POST方式
POST /lei/one/
{
"name":"小丽",
"age":22,
"birthday":"2000-06-07 14:03:55"
}
修改文档
PUT 方式
这种方式直接修改对应字段的值 然后进行覆盖
PUT /索引名/类型名/文档ID
{"请求体"}

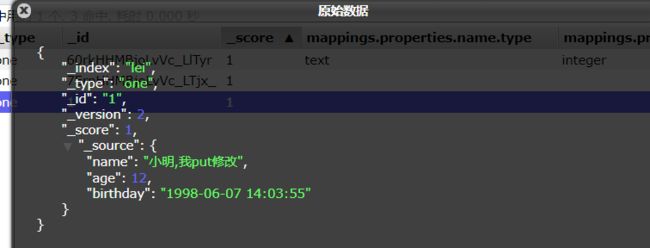
POST 方式
POST /索引名/类型名/文档ID/_update
{
"doc":{
"要修改的列":"值"
}
}
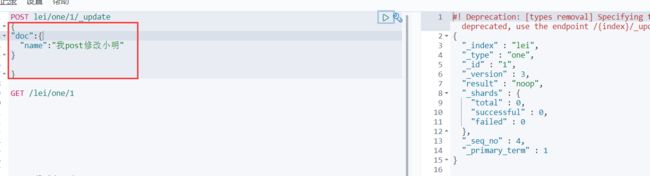

可能有人在纳闷,为啥我POST 修改还要搞个doc 呢,,我直接POST 提交要修改的列可以不可以呢?咱们来试一下
果然 ,不替换url 直接覆盖字段值 ,看起来是修改成功了
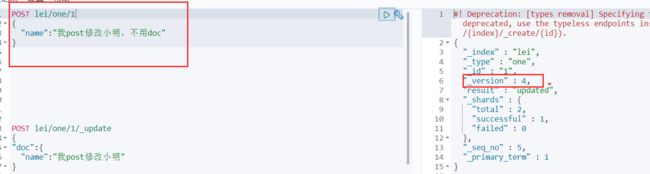
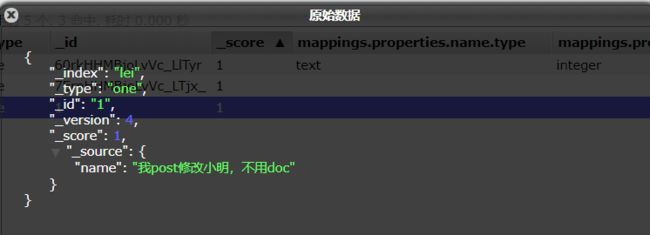
但是,除开修改的Name 字段其余全部没有了,这说明不用_update doc 其会修改,但是,某些未被修改的列 会被移除,其文档结构已被破坏,所以为了数据结构稳定 还是使用 _update doc 吧
获取文档
GET 索引名/类型名/文档ID
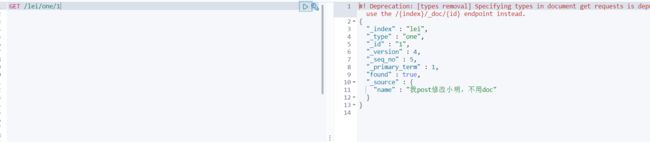
GET 方式获取所有索引类型下的所有文档
GET 索引名/类型名/_search
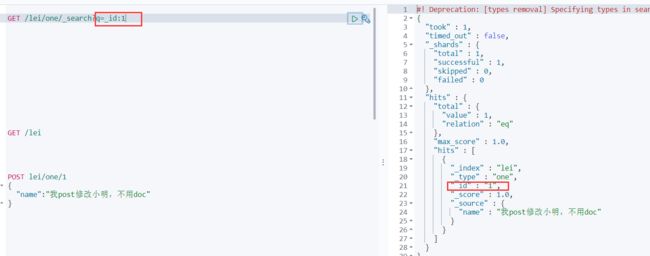
查找_id 为1的文档
_search ? 后边为要查询的条件 q query 的意思 例如查询__id 为1 则 q=_id:1 查询名字为小明 q=name:小明
GET /lei/one/_search?q=_id:1
查询条件拼接
比如我要查name 为小红 且_id 为2的文档
我们首先新增一条数据
POST /lei/one/2
{
"name":"小丽2",
"age":222,
"birthday":"2000-06-07 14:03:55"
}
按道理来说,我查询小丽 应该只有一条数据啊 ,为什么这里小丽2也出来了 ,其实可以看到 他有个socre 分值
小丽分值 是比小丽2高的 ,说白了 一个匹配度的问题 搜索条件 小丽 结果 两条数据的匹配度比一样的,且做了个排序,分值(匹配度)高的在前 参考百度搜索 匹配度越高 越在前 (百度恰饭的真谛)拿钱让你上榜一。。

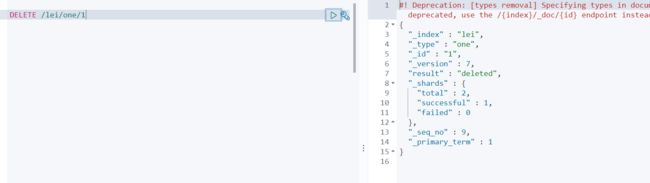
删除文档
根据url 精度 进行删除 可以直接删索引库 也可以细分到删除某一文档
DELETE 索引名/类型名/文档ID
添加字段
POST /文档名/类型名
{
"properties": {
"添加的字段名": {
"type": "字段的类型"
}
}
}
POST /lei/one/2/_update
{
"doc":{
"hobby":["篮球","击剑"]
}
}
POST /lei/one/7ErnHHMBjoLvVc_LTjx_/_update
{
"doc":{
"hobby":["足球","爬山"]
}
}