Cortex-M3(1) 汇编基础知识
ARM汇编基础知识
1、汇编语言:基本语法
汇编指令的最典型书写模式如下所示:
标号
操作码 操作数1, 操作数2, … ; 注释。
说明:
操作数:指令中的操作数一般可以分为3种类型,立即数、寄存器操作数、存储器操作数。
(1)其中,标号是可选的,如果有,它必须顶格写。标号的作用是让汇编器来计算程序转移
的地址。
(2)操作码是指令的助记符,它的前面必须有至少一个空白符,通常使用一个“Tab”键来
产生。
(3)操作码后面往往跟随若干个操作数,而第1 个操作数,通常都给出本指令执行结果的存储地。不同指令需要不同数目的操作数,并且对操作数的语法要求也可以不同。举例来说,
立即数必须以“#”开头,如
MOV R0, #0x12 ; R0 <- 0x12
MOV R1, #’A’ ; R1 <- 字母 A 的ASCII 码
(4)注释均以”;”开头,它的有无不影响汇编操作,只是给程序员看的,能让程序更易理解。
(5)可以使用EQU 指示字来定义常数,然后在代码中使用它们,例如:
NVIC_IRQ_SETEN0 EQU 0xE000E100
NVIC_IRQ0_ENABLE EQU 0x1
…
LDR R0, =NVIC_IRQ_SETEN0 ;在这里的LDR 是个伪指令,它会被汇编器转换成
;一条“相对PC 的加载指令”
MOV R1, #NVIC_IRQ0_ENABLE ; 把立即数传送到指令中
STR R1, [R0] ; *R0=R1,执行完此指令后IRQ #0 被使能。
注意:常数定义必须顶格写
(6)如果汇编器不能识别某些特殊指令的助记符,你就要“手工汇编”——查出该指令的确切二进制机器码,然后使用DCI 编译器指示字。例如,BKPT 指令的机器码是0xBE00,即可以按如下格式书写:
DCI 0xBE00 ; 断点(BKPT),这是一个16 位指令
(DCI 也必须空格写——译注)
类似地,你还可以使用DCB 来定义一串字节常数——允许以字符串的形式表达,还可以使用DCD 来定义一串32 位整数。它们最常被用来在代码中书写表格。例如:
LDR R3, =MY_NUMBER ; R3= MY_NUMBER
LDR R4, [R3] ; R4= *R3
…
LDR R0, =HELLO_TEXT ; R0= HELLO_TEXT
BL PrintText ; 呼叫PrintText 以显示字符串,R0 传递参数
…
MY_NUMBER
DCD 0x12345678
HELLO_TEXT
DCB ”Hello\n”,0
请注意:不同汇编器的指示字和语法都可以不同。上述示例代码都是按 ARM 汇编器的语法格式写的。如果使用其它汇编器,最好看一看它附带的示例代码。
2、汇编语言:后缀的使用
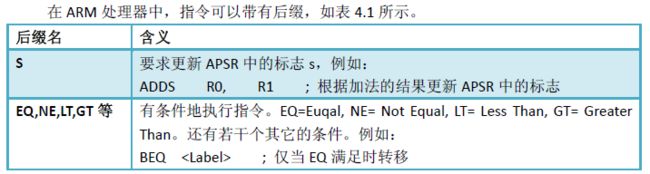
在 Cortex‐M3 中,对条件后缀的使用有限制,只有转移指令(B 指令)才可随意使用。而对于其它指令,CM3 引入了IF‐THEN 指令块,在这个块中才可以加后缀,且必须加以后缀。
IF‐THEN 块由IT 指令定义,本章稍后将介绍它。另外,S 后缀可以和条件后缀在一起使用。共有15 种不同的条件后缀,稍后介绍。
3、汇编语言:统一的汇编语言
为了最有力地支持Thumb‐2,引了一个“统一汇编语言(UAL)”语法机制。对于16 位指令和32 位指令均能实现的一些操作(常见于数据处理操作),有时虽然指令的实际操作数
不同,或者对立即数的长度有不同的限制,但是汇编器允许开发者以相同的语法格式书写,并且由汇编器来决定是使用16 位指令,还是使用32 位指令。以前,Thumb 的语法和ARM
的语法不同,在有了UAL 之后,两者的书写格式就统一了。
ADD R0, R1 ; 使用传统的Thumb 语法
ADD R0, R0, R1 ; UAL 语法允许的等值写法(R0=R0+R1)
虽然引入了UAL,但是仍然允许使用传统的Thumb 语法。不过有一项必须注意:如果使用传统的Thumb 语法,有些指令会默认地更新APSR,即使你没有加上S 后缀。如果使用
UAL 语法,则必须指定S 后缀才会更新。例如:
AND R0, R1 ;传统的Thumb 语法
ANDS R0, R0, R1 ;等值的UAL 语法(必须有S 后缀)
在Thumb‐2 指令集中,有些操作既可以由16 位指令完成,也可以由32 位指令完成。例如,R0=R0+1 这样的操作,16 位的与32 位的指令都提供了助记符为“ADD”的指令。在
UAL 下,你可以让汇编器决定用哪个,也可以手工指定是用16 位的还是32 位的:
ADDS R0, #1 ;汇编器将为了节省空间而使用16 位指令
ADDS.N R0, #1 ;指定使用16 位指令(N=Narrow)
ADDS.W R0, #1 ;指定使用32 位指令(W=Wide)
.W(Wide)后缀指定32 位指令。如果没有给出后缀,汇编器会先试着用16 位指令以缩小代码体积,如果不行再使用32 位指令。因此,使用“.N”其实是多此一举,不过汇编器可
能仍然允许这样的语法。
再次重申,这是ARM 公司汇编器的语法,其它汇编器的可能略有区别,但如果没有给出后缀,汇编器就总是会尽量选择更短的指令。其实在绝大多数情况下,程序是用C 写的,C 编译器也会尽可能地使用短指令。然而,当立即数超出一定范围时,或者32 位指令能更好地适合某个操作,将使用32 位指令。32 位Thumb‐2 指令也可以按半字对齐(以前ARM 32 位指令都必须按字对齐——译注),
因此下例是允许的:
0x1000: LDR r0, [r1] ;一个16 位的指令
0x1002: RBIT.W r0 ;一个32 位的指令,跨越了字的边界
绝大多数 16 位指令只能访问R0‐R7;32 位Thumb‐2 指令则无任何限制。不过,把R15(PC)作为目的寄存器却很容易走火入魔——用对了会有意想不到的妙处,出错时则会使程序跑飞。通常只有系统软件才会不惜冒险地做此高危行为。对PC 的使用额外的戒律。如果感兴趣,可以参考《ARMv7‐M 架构应用级参考手册》。
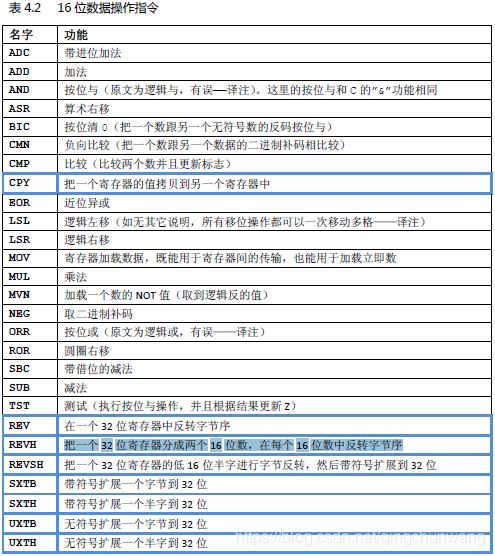
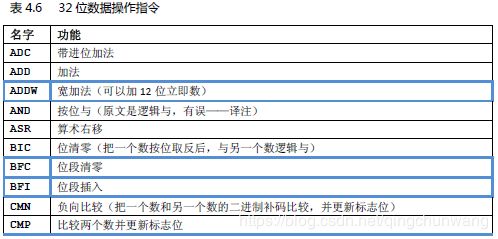
4、指令集
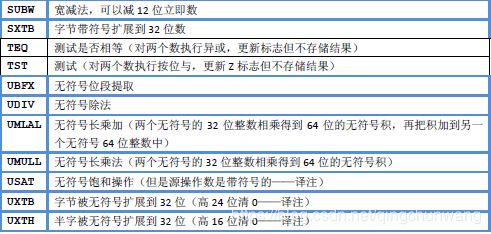
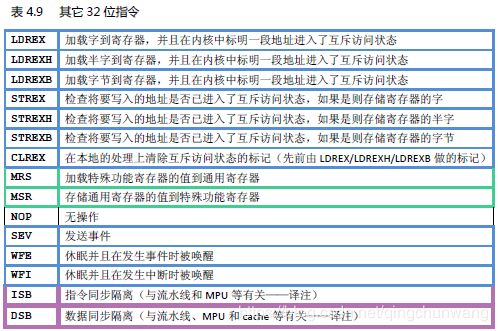
Cortex‐M3 支持的指令在表4.2‐表4.9 列出。其中边框加粗的是从ARMv6T2 才支持的指令。双线边框的是从Cortex‐M3 才支持的指令(v7 的其它款式不一定支持)
在讲指令之前,先简单地介绍一下Cortex‐M3 中支持的算术与逻辑标志。本书在后面还会展开论述。它们是:
APSR 中的5 个标志位
N: 负数标志(Negative)
Z: 零结果标志(Zero)
C: 进位/借位标志(Carry)
V: 溢出标志(oVerflow)
S: 饱和标志(Saturation),它不做条件转移的依据



![]()
未支持的指令
有若干条Thumb 指令没有被Cortex‐M3 支持,下表列出了没有被支持的指令,以及不支持的原因。
表4.10 因为不再是传统的架构,导致有些指令已失去意义
未支持的
指令
以前的功能
BLX #im 在使用立即数做操作数时,BLX 总是要切入ARM 状态。因为Cortex-M3 只在Thumb 态下运
行,故以此指令为代表的,凡是试图切入ARM 态的操作,都将引发一个用法fault。
SETEND 由 v6 引入的,在运行时改变处理器端设置的指令(大端或小端)。因为Cortex-M3 不支持
动态端的功能,所以此指令也将引发fault
有少量在ARMv7‐M 中列出的指令不被CM3 支持。其中v7M 允许Thumb2 的协处理器
指令,但是CM3 却不能挂协处理器。表4.11 列出了这些与协处理器相关的指令。如果试图
执行它们,则将引发用法fault(NVIC 中的NOCP(No CoProcessor)标志置位)。
表4.11 不支持的协处理器相关指令
未支持
的指令
以前的功能
MCR 把通用寄存器的值传送到协处理器的寄存器中
MCR2 把通用寄存器的值传送到协处理器的寄存器中
MCRR 把通用寄存器的值传送到协处理器的寄存器中,一次操作两个
MRC 把协处理器寄存器的值传送到通用寄存器中
MRC2 把协处理器寄存器的值传送到通用寄存器中
MRRC 把协处理器寄存器的值传送到通用寄存器中,一次操作两个
LDC 把某个连续地址空间中的一串数值传送至协处理器中
STC 从协处理器中传送一串数值到地址连续的一段地址空间中
改变处理器状态指令(CPS)的一些用法也不再支持。这是因为PSRs 的定义已经变了,
以前在v6 中定义的某些位在CM3 中不存在。
表4.12 不支持的CPS 指令用法
未支持的指令 以前的功能
CPS
CPS.W #mode CM3 的PSR 中没有“mode”位
有些提示(hint)指令的功能不支持,它们在CM3 中按“NOP”指令对待
表4.13 不支持的hint 指令
未支持的指令 以前的功能
DBG 服务于跟踪系统的一条 hint 指令
PLD 预取数据。这是服务于cache 系统的一条hint 指令。因为在CM3 中没有cache,
该指令就相当于NOP
PLI 预取指令。这是服务于cache 系统的一条hint 指令。因为在CM3 中没有cache,
该指令就相当于NOP
YIELD 用于多线程处理。线程使用该指令通知给硬件:我正在做的任务可以被交换出去
(swapped out),从而提高系统的整体性能。
近距离地检视指令
从现在起,我们将介绍一些在ARM 汇编代码中很通用的语法。有些指令可以带有多种
参数,比如预移位操作,但本章并不会讲得面面惧到。
5、汇编语言:数据传送
处理器的基本功能之一就是数据传送。CM3 中的数据传送类型包括
(1)两个寄存器间传送数据
(2)寄存器与存储器间传送数据
(3)寄存器与特殊功能寄存器间传送数据
(4)把一个立即数加载到寄存器
用于在寄存器间传送数据的指令是MOV。比如,如果要把R3 的数据传送给R8,则写
作:
MOV R8, R3
MOV 的一个衍生物是MVN,它把寄存器的内容取反后再传送。
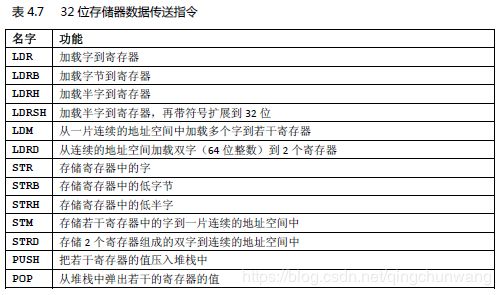
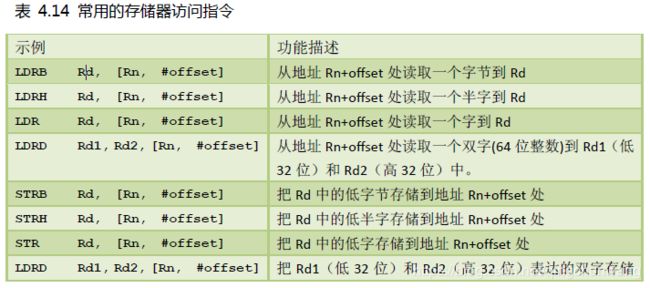
用于访问存储器的基础指令是“加载(Load)”和“存储(Store)”。
加载指令LDR 把存储器中的内容加载到寄存器中,
存储指令STR 则把寄存器的内容存储至存储器中,传送过程中数据类型也可以变通,最常使用的格式有:
表 4.14 常用的存储器访问指令
![]()
如果嫌一口一口地蚕食太不过瘾,也可以使用LDM/STM 来鲸吞。它们相当于把若干个LDR/STR 给合并起来了,有利于减少代码量,如表4.15 所示
表 4.15 常用的多重存储器访问方式
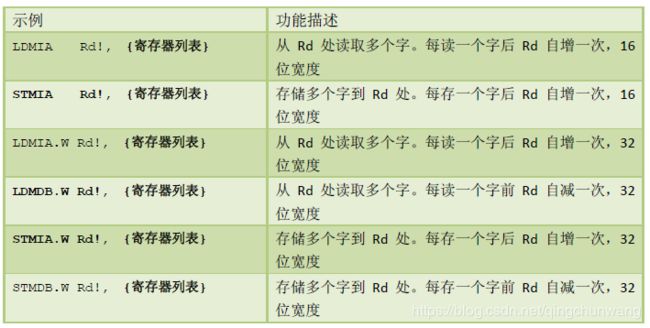
上表中,加粗的是符合CM3 堆栈操作的LDM/STM 使用方式。并且,如果Rd 是R13(即SP),则与POP/PUSH 指令等效。(LDMIA‐>POP, STMDB ‐> PUSH)
STMDB SP!, {R0-R3, LR} 等效于 PUSH {R0-R3, LR}
LDMIA SP!, {R0-R3, PC} 等效于 PUSH {R0-R3, PC}
Rd 后面的“!”是什么意思?它表示要自增(Increment)或自减(Decrement)基址寄存器Rd的值,时机是在每次访问前(Before)或访问后(After)。增/减单位:字(4 字节)。例如,记R8=0x8000,
则下面两条指令:
STMIA.W R8!, {r0-R3} ; R8 值变为0x8010,每存一次曾一次,先存储后自增
STMDB.W R8, {R0-R3} ; R8 值的“一个内部复本”先自减后存储,但是R8 的值不变
“带预索引”
感叹号还可以用于单一加载与存储指令——LDR/STR。这也就是所谓的 “带预索引”(Pre‐indexing)的LDR 和STR。例如:
LDR.W R0, [R1, #20]! ;预索引
该指令先把地址R1+offset 处的值加载到R0,然后,R1 <- R1+ 20(offset 也可以是负数——译注)。这里的“!”就是指在传送后更新基址寄存器R1 的值。
“!”是可选的。如果没有“!”,则该指令就是普通的带偏移量加载指令。带预索引的数据传送可以用在多种数据类型上,并且既可用于加载,又可用于存储。
表4.16 预索引数据传送的常见用法

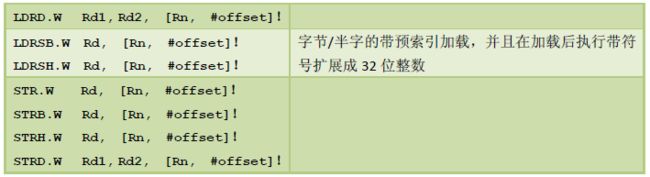
CM3 除了支持“预索引”,还支持“后索引”(Post‐indexing)。后索引也要使用一个立即数offset,但与预索引不同的是,后索引是忠实使用基址寄存器Rd 的值作为数据传送的地址的。待到数据传送后,再执行Rd <- Rd+offset(offset 可以是负数——译注)。
如:
STR.W R0, [R1], #-12 ;后索引该指令是把 R0 的值存储到地址R1 处的。在存储完毕后, R0 <- R0+(‐12)
注意,[R1]后面是没有“!”的。可见,在后索引中,基址寄存器是无条件被更新的——相当于有一个“隐藏”的“!”
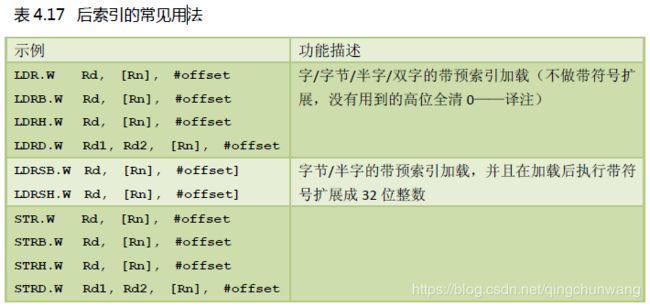
译者添加
立即数的位数是有限制的,且不同指令的限制可以不同。这下岂不是要有的背了?其实
不必!因为如果在使用中超过了限制,则汇编器会给你报错,所以不用担心会背成书呆子。
那能彻底消灭这种限制吗?办法是有的,只是要使用另一种形式的LDR/STR。事实上,
在CM3 中的偏移量,除了可以使用形如#offset 的立即数,还可以使用一个寄存器。使用
寄存器来提供偏移量,就可以“天南地北任我行”了。不过,如果使用寄存器提供偏移量,
就不能使用“预索引”和“后索引”了——也就是说不能修改基址寄存器的值。因此下面的写法
就是非法的:
ldr r2, [r0, r3]! ;错误,寄存器提供偏移量时不支持预索引
ldr r2, [r0], r3 ;错误,寄存器提供偏移量时不支持后索引
看起来令人扫兴,不是吗?不过也有好消息。当使用寄存器作索引时,可以“预加工”
索引寄存器的值——逻辑左移。显然,这与C 语言数组下标的寻址方式刚好吻合,如
ldr r2, [r0, r3, lsl #2]
如果 r3 给出了某32 位整数数组的下标,则这条指令即可取出该下标处的数组元素。
还有一个注意事项:左移的位数只能是1、2 或者3。(最常用的就是2,对应long 类型)。
PUSH/POP 作为堆栈专用操作,也属于数据传送指令类(具体关系参见译注13——译者注)。
通常PUSH/POP 对子的寄存器列表是一致的,但是PC 与LR 的使用方式有所通融,如
;子程序入口
PUSH {R0-R3, LR}
…
;子程序出口
POP {R0-R3, PC}
在这个例子中,旁路了LR,直截了当地返回。
数据传送指令还包括MRS/MSR。还记得第3 章讲到过CM3 有若干个特殊功能寄存器吗?
MRS/MSR 就是专门用于访问这些寄存器的。不过,这些寄存器都是关键部位。因此除了APSR
在某些场合下可以“露点”之外,其它的都不能“走光”——必须在特权级下才允许访问,
以免系统因误操作或恶意破坏而功能紊乱,甚至当机。如果以身试法,则fault 伺候
(MemManage fault,如果被除能则“上访”成硬fault)。通常,只有系统软件(如OS)才
会操作这类寄存器,应用程序,尤其是用C 编写的应用程序,是从来不关心这些的。
程序写多了你就会感觉到,程序中会经常使用立即数。最典型的就是:当你要访问某个
地址时,你必须先把该地址加载到一个寄存器中,这就包含了一个32 位立即数加载操作。
CM3 中的MOV/MVN 指令族负责加载立即数,各个成员支持的立即数位数不同。例如,16
位指令MOV 支持8 位立即数加载,如:
MOV R0, #0x12
32 位指令MOVW 和MOVT 可以支持16 位立即数加载。
那要加载32 位立即数怎么办呢?当前是要用两条指令来完成了。
如果某指令需要使用32 位立即数,也可以在该指令地址的附近定义一个32 位整数数组,把这个立即
数放到该数组中。然后使用一条LDR Rd, [PC, #offset] 来查表。offset 的值需要计算,它其实是LDR 指令的
地址与该数组元素地址的距离。手工计算offset 是很自虐的作法,马上要讲到的一条伪指令能让汇编器来
自动产生这种数组,并且负责计算offset。这里提到的这种数组被广泛使用,它的学名叫“文字池”(literal
pool),通常由汇编器自动布设,程序很大时可能也需要手工布设(LTORG 指示字)。
不过,为了书写的方便,汇编器通常都支持”LDR Rd, = imm32”伪指令。例如:
LDR, r0, =0x12345678
酷吧!它的名字也是LDR,但它是伪指令,是“妖怪变的”,而且有若干种原形。所以
不要因为名字相同就混淆。
大多数情况下,汇编器都在遇到LDR 伪指令时,都会把它转换成一条相对于PC 的加载
指令,来产生需要的数据。通过组合使用MOVW 和MOVT 也能产生32 位立即数,不过有点
麻烦。大可依赖汇编器,它会明智地使用最合适的形式来实现该伪指令。
LDR 伪指令 vs. ADR 伪指令
Both LDR 和ADR 都有能力产生一个地址,但是语法和行为不同。对于LDR,如果汇编器
发现要产生立即数是一个程序地址,它会自动地把LSB 置位,例如:
LDR r0, =address1 ; R0= 0x4000 | 1
…
address1
0x4000: MOV R0, R1
在这个例子中,汇编器会认出address1 是一个程序地址,所以自动置位LSB。另一方面,
如果汇编器发现要加载的是数据地址,则不会自作聪明,多机灵啊!看:
LDR R0, =address1 ; R0= 0x4000
…
address1
0x4000: DCD 0x0 ;0x4000 处记录的是一个数据
ADR 指令则是“厚道人”,它决不会修改LSB。例如:
ADR r0, address1 ; R0= 0x4000。注意:没有“=”号
…
address1
0x4000: MOV R0, R1
ADR 将如实地加载0x4000。注意,语法略有不同,没有“=”号。
前面已经提到,LDR 通常是把要加载的数值预先定义,再使用一条PC 相对加载指令来
取出。而ADR 则尝试对PC 作算术加法或减法来取得立即数。因此ADR 未必总能求出需要的
立即数。其实顾名思义,ADR 是为了取出附近某条指令或者变量的地址,而LDR 则是取出
一个通用的32 位整数。因为ADR 更专一,所以得到了优化,故而它的代码效率常常比LDR
的要高。
6、汇编语言:数据处理
数据处理乃是处理器的看家本领,CM3 当然要出类拔萃,它提供了丰富多彩的相关指
令,每种指令的用法也是花样百出。限于篇幅,这里只列出最常用的使用方式。就以加法为
例,常见的有:
ADD R0, R1 ; R0 += R1
ADD R0, #0x12 ; R0 += 12
ADD.W R0, R1, R2 ; R0 = R1+R2
虽然助记符都是ADD,但是二进制机器码是不同的。当使用16 位加法时,会自动更新APSR 中的标志位。然而,在使用了“.W”显式指定了32 位指令后,就可以通过“S”后缀手工控制对APSR 的更新,如:
ADD.W R0, R1, R2 ; 不更新标志位
ADDS.W R0, R1, R2 ; 更新标志位
除了 ADD 指令之外,CM3 中还包含SUB, MUL, UDIV/SDIV 等用于算术四则运算,如表4.18所列
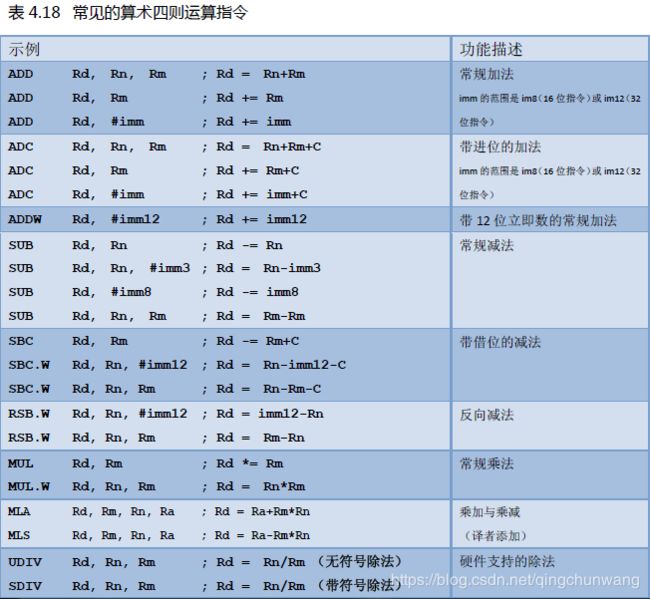
CM3 还片载了硬件乘法器,支持乘加/乘减指令,并且能产生64 位的积,如表4.19 所示
表4.19 64 位乘法指令

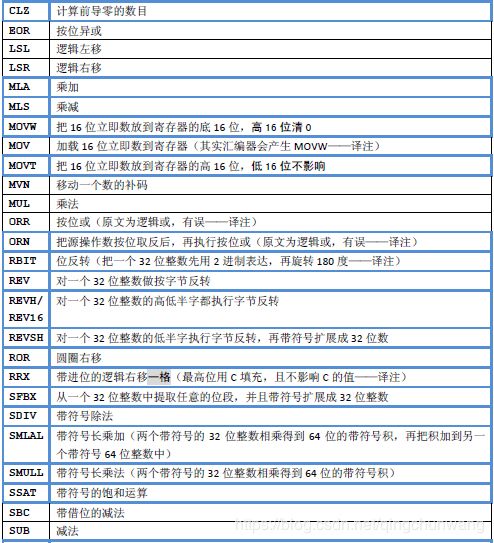
逻辑运算以及移位运算也是基本的数据操作。表4.20 列出CM3 在这方面的常用指令
表4.20 常用逻辑操作指令
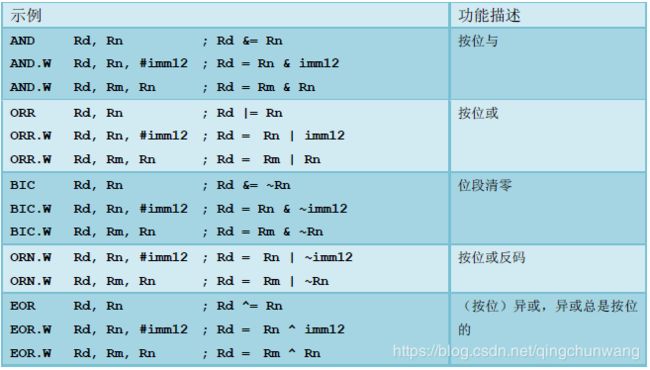
译者添加
大多数涉及3 个寄存器的32 位数据操作指令,都可以在计算之前,对其第3 个操作数Rn 进行“预
加工”——移位,格式为:
DataOp Rd, Rm, Rn, LSL #imm5 ;先对Rn 逻辑左移imm5 格
DataOp Rd, Rm, Rn, LSR #imm5 ;先对Rn 逻辑右移imm5 格
DataOp Rd, Rm, Rn, ASR #imm5 ;先对Rn 算术右移imm5 格
DataOp Rd, Rm, Rn, ROR #imm5 ;先对Rn 圆圈右移imm5 格
DataOp Rd, Rm, Rn, ROL #imm5 ;(错误)先对Rn 循环左移imm5 格
DataOp Rd, Rm, Rn, RRX ;先对Rn 带进位位右移一格
注意:“预加工”是对Rn 的一个“内部复本”执行操作,不会因此而影响Rn 的值。但如果Rn 正巧是
Rd,则按DataOp 的计算方式来更新。
其中,DataOp 可以是所有“传统”的32 位数据操作指令,包括:
ADD/ADC/ SUB/SBC/RSB/ AND/ORR/EOR/ BIC/ORN
CM3 还支持为数众多的移位运算。移位运算既可以与其它指令组合使用(传送指令和数据
操作指令中的一些,参见文本框中的说明),也可以独立使用,如表4.21 所示。
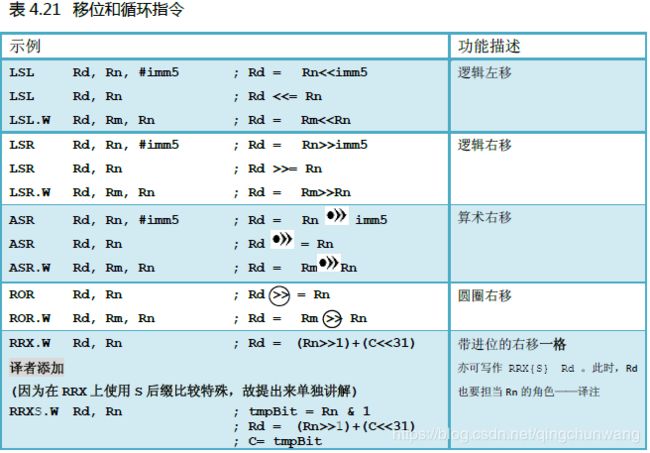
如果在移位和循环指令上加上“S”后缀,这些指令会更新进位位C。如果是16 位Thumb
指令,则总是更新C 的。图4.1 给出了一个直观的印象
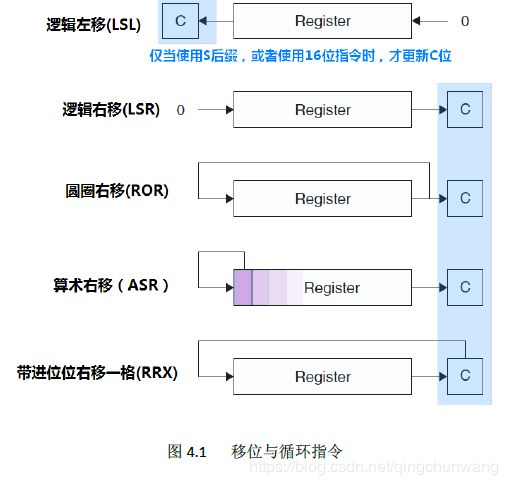
为啥没有圆圈左移?
在圆圈移位中, 寄存器的32 个位其实是手拉手组成一个圈的。那么这个圈向右转
动n 格,与向左转动32‐n 格是等效的,这种简单的道理,玩过“丢手绢”的小朋友
们都知道。因此欲圆圈左移n 格时,只要使用圆圈右移指令,并且转动32‐n 格即可。
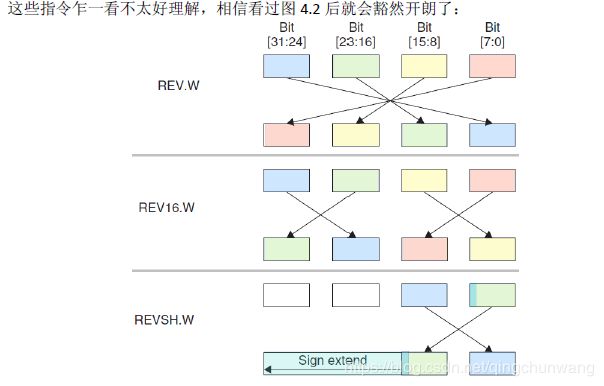
介绍完了移位指令,接下来讲带符号扩展指令。
我们知道,在2 进制补码表示法中,最高位是符号位,且所有负数的符号位都是1。但
是负数还有另一个性质,就是不管在符号位的前面再添加多少个1,值都不变。于是,在把
一个8 位或16 位负数扩展成32 位时,欲使其数值不变,就必须把所有高位全填1。至于正
数或无符号数,则只需简单地把高位清0。因此,必须给带符号数开小灶,于是就有了整数
扩展指令,如表4.22 所示。

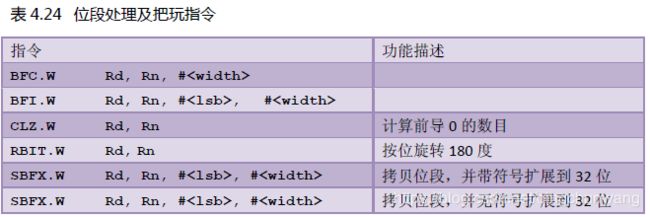
数据操作指令的最后一批,是位操作指令。位操作在单片机程序中,以及在系统软件中
应用得比较多,而且在这里面有大量的使用技巧。这里在表4.24 中先列出它们,本书在后
续的小节中还要展开论述。
表4.24 位段处理及把玩指令
7、汇编语言:子程呼叫与无条件转移指令
最基本的无条件转移指令有两条:
B Label ;转移到Label 处对应的地址
BX reg ;转移到由寄存器reg 给出的地址
在BX 中,reg 的最低位指示出在转移后,将进入的状态是ARM(LSB=0)还是Thumb(LSB=1)。既然CM3 只在Thumb 中运行,就必须保证reg 的LSB=1,否则fault 伺候。
呼叫子程序时,需要保存返回地址,正点的指令是:
BL Label ;转移到Label 处对应的地址,并且把转移前的下条指令地址保存到LR
BLX reg ;转移到由寄存器reg 给出的地址,根据REG 的LSB 切换处理器状态,;并且把转移前的下条指令地址保存到LR
执行这些指令后,就把返回地址存储到LR(R14)中了,从而才能使用”BX LR”等形式返回。
使用BLX 要小心,因为它还带有改变状态的功能。因此reg 的LSB 必须是1,以确保不会试图进入ARM 状态。如果忘记置位LSB,则fault 伺候。
对于艺高胆大的玩家来说,使用以PC 为目的寄存器的MOV 和LDR 指令也可以实现转
移,并且往往能借此实现很多常人想不到的绝活,常见形式有:
MOV PC, R0 ;转移地址由R0 给出
LDR PC, [R0] ;转移地址存储在R0 所指向的存储器中
POP {…,PC} ;把返回地址以弹出堆栈的风格送给PC,
;从而实现转移(这也是OS 惯用的一项必杀技——译注)
LDMIA SP!, {…, PC} ;POP 的另一种等效写法
同理,使用这些密技,你也必须保证送给PC 的值必须是奇数(LSB=1)。
注意:有心的读者可能已经发现,ARM 的BL 虽然省去了耗时的访内操作,却只能支持
一级子程序调用。如果子程序再呼叫 “孙程序”,则返回地址会被覆盖。因此当函数嵌套多
于一级时,必须在调用“孙程序”之前先把LR 压入堆栈——也就是所谓的“溅出”。
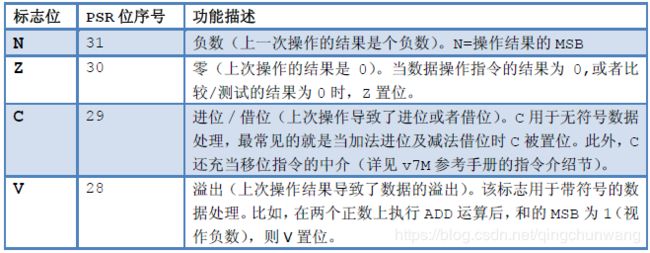
8、汇编语言:标志位与条件转移
在应用程序状态寄存器中有5 个标志位,但只有4 个被条件转移指令参考。绝大多数
ARM 的条件转移指令根据它们来决定是否转移,如表4.25 所示
表4.25 Cortex‐M3 APSR 中可以影响条件转移的4 个标志位
在ARM 中,数据操作指令可以更新这4 个标志位。这些标志位除了可以当作条件转移
的判据之外,还能在一些场合下作为指令是否执行的依据(详见If‐Then 指令块),或者在移
位操作中充当各种中介角色(仅进位位C)。
担任条件转移及条件执行的判据时,这4 个标志位既可单独使用,又可组合使用,以产
生共15 种转移判据,如下表4.26 所示
表4.26 转移及条件执行判据
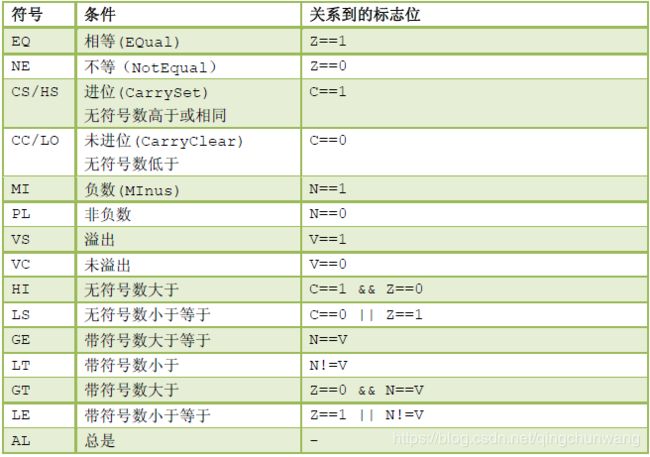
表中共有15 个条件组合(AL 相当于无条件——译注),通过把它们点缀在无条件转移指令
(B)的后面,即可做成各式各样的条件转移指令,例如:
BEQ label ;当Z=1 时转移
亦可以在指令后面加上“.W”,来强制使用Thumb‐2 的32 位指令来做更远的转移(没
必要,汇编器会自行判断——译注),例如:
BEQ.W label
这些条件组合还可以用在If‐Then 语句块中,比如:
CMP R0, R1 ;比较R0,R1
ITTET GT ;If R0>R1 Then(T代表Then,E代表Else)
MOVGT R2, R0
MOVGT R3, R1
MOVLE R2, R0
MOVGT R3, R1
(本章的后面有对IT 指令和If‐Then 块进行详细说明——译注)
在CM3 中,下列指令可以更新PSR 中的标志:
�� 16 位算术逻辑指令
�� 32 位带S 后缀的算术逻辑指令
�� 比较指令(如,CMP/CMN)和测试指令(如TST/TEQ)
�� 直接写 PSR/APSR (MSR 指令)
大多数16 位算术逻辑指令不由分说就会更新标志位(不是所有,例如ADD.N Rd, Rn, Rm 是
16 位指令,但不更新标志位——译注),32 位的都可以让你使用S 后缀来控制。例如:
ADDS.W R0, R1, R2 ;使用32 位Thumb-2 指令,并更新标志
ADD.W R0, R1, R2 ;使用32 位Thumb-2 指令,但不更新标志位
ADD R0, R1 ;使用16 位Thumb 指令,无条件更新标志位
ADDS R0, #0xcd ;使用16 位Thumb 指令,无条件更新标志位
虽然真实指令的行为如上所述。但是在你用汇编语言写代码时,因为有了 UAL(统一汇编语言),汇
编器会做调整,最终生成的指令不一定和与你在字面上写的指令相同。对于ARM 汇编器而言,调整的结果
是:如果没有写后缀S,汇编器就一定会产生不更新标志位的指令。
S 后缀的使用要当心。16 位Thumb 指令可能会无条件更新标志位,但也可能不更新标
志位。为了让你的代码能在不同汇编器下有相同的行为,当你需要更新标志,以作为条件指
令的执行判据时,一定不要忘记加上S 后缀。
CM3 中还有比较和测试指令,它们的目的就是更新标志位,因此是会影响标志位的,
如下所述。
CMP 指令。CMP 指令在内部做两个数的减法,并根据差来设置标志位,但是不把差写
回。CMP 可有如下的形式:
CMP R0, R1 ; 计算R0-R1 的差, 并且根据结果更新标志位
CMP R0, 0x12 ; 计算R0-0x12 的差, 并且根据结果更新标志位
CMN 指令。CMN 是CMP 的一个孪生姊妹,只是它在内部做两个数的加法(相当于减去
减数的相反数),如下所示:
CMN R0, R1 ; 计算R0+R1 的和, 并根据结果更新标志位
CMN R0, 0x12 ; 计算R0+0x12 的和,并根据结果更新标志位
TST 指令。TST 指令的内部其实就是AND 指令,只是不写回运算结果,但是它无条件更
新标志位。它的用法和CMP 的相同:
TST R0, R1 ; 计算R0 & R1, 并根据结果更新标志位
TST R0, 0x12 ; 计算R0 & 0x12, 并根据结果更新标志位
TEQ 指令。TEQ 指令的内部其实就是EOR 指令,只是不写回运算结果,但是它无条件更
新标志位。它的用法和CMP 的相同:
TEQ R0, R1 ; 计算R0 ^ R1, 并根据结果更新标志位
TEQ R0, 0x12 ; 计算R0 ^ 0x12, 并根据结果更新标志位
9、汇编语言:指令隔离(barrier)指令和存储器隔离指令
详细参考《Cortex M3权威指南(中文).pdf》
10、汇编语言:饱和运算
详细参考《Cortex M3权威指南(中文).pdf》
11、CM3 中的一些有用的新指令
详细参考《Cortex M3权威指南(中文).pdf》