Java简单实现爬取BOSS直聘数据
Java简单实现爬取BOSS直聘数据
- 采用技术
- 页面分析
- 数据页面分析
- 页面链接抽取
- 注意
- 代码
- 1. POM
- 2. 编写工具类
- 3. 编写数据获取类
- 4. 数据清洗
- 总结

采用技术
- 整体架构使用的是人人开源的框架,减少工作量
- 使用HtmlUnit实现对页面的加载。本想使用Webmagic,但如果加载html需要使用复杂的修改,而本人只用于简单数据采集,于是就选择的HtmlUnit。
- 页面解析采用的是Xpath。
- 爬取的原始数据存放于MongoDB。
- 清洗之后的数据存放于MySQL。
页面分析
数据页面分析
使用 HtmlUnit 会对请求的页面进行渲染,从而达到和浏览器调试网页代码一致性。
对BOSS搜索Java的页面进行分析
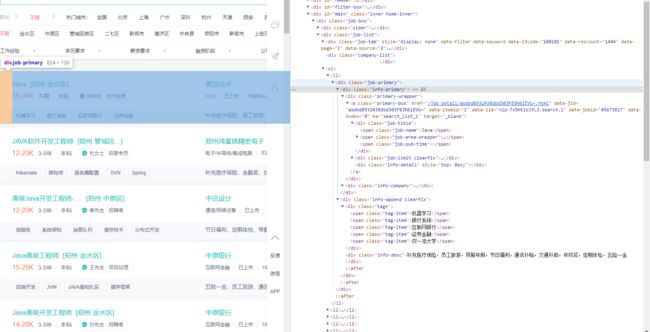
- 找到数据列表的块
class=job-primary,可以通过Xpath获取所有的节点。 - 通过节点可直接获取职位名称、招聘位置、薪资、工作年限、学历、公司名称等等。
页面链接抽取
- 通过
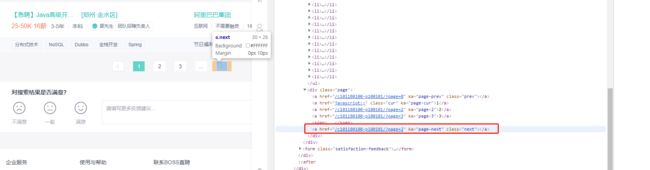
HtmlUnit可以获得页面的所有链接,通过分析可对链接进行拼接,从而得到网站的可访问链接。 - 通过遍历页面多次抽取所有的页面。
- 通过调试可找到获取下一页链接的方式
注意
- 请求过快会导致出现机器验证的页面,从而禁止爬取数据,应在每次请求页面时添加延时。
- 创建
WebClient的时候应随机浏览器,也可添加IP池,进行随机代理,防止禁止IP爬取数据问题。
代码
1. POM
添加 HtmlUnit 的jar包:
<dependency>
<groupId>net.sourceforge.htmlunitgroupId>
<artifactId>htmlunitartifactId>
<version>2.27version>
dependency>
2. 编写工具类
编写获取页面数据的静态方法,通过随机生成浏览器构建 WebClient 对象:
/**
* 通过url获得加载之后的页面xml,如果解析失败返回null
*
* @param url
* @return
*/
public static HtmlPage getPage(String url) {
// 模拟多种浏览器
List<BrowserVersion> list = new ArrayList<>();
list.add(BrowserVersion.CHROME);
list.add(BrowserVersion.EDGE);
list.add(BrowserVersion.BEST_SUPPORTED);
list.add(BrowserVersion.FIREFOX_45);
list.add(BrowserVersion.FIREFOX_52);
list.add(BrowserVersion.INTERNET_EXPLORER);
// 获得ip代理
// JSONObject jsonObject = ipProxy();
// log.info(jsonObject.toString());
WebClient webClient =null;
webClient = new WebClient(list.get(new Random().nextInt(list.size())));
// 设置IP代理,目前获得免费的IP代理有问题
// try{
// webClient = new WebClient(list.get(new Random().nextInt(list.size())),jsonObject.getString("host"),jsonObject.getInteger("port"));
// }catch (Exception e){
// webClient = new WebClient(list.get(new Random().nextInt(list.size())));
// }
// 加载JS
webClient.getOptions().setJavaScriptEnabled(true);
// 不加载CSS
webClient.getOptions().setCssEnabled(false);
// 超时时间
webClient.getOptions().setTimeout(0);
// 设置JS超时时间
webClient.setJavaScriptTimeout(0);
webClient.setAjaxController(new NicelyResynchronizingAjaxController());
webClient.waitForBackgroundJavaScript(0);
webClient.getOptions().setThrowExceptionOnScriptError(false);
try {
HtmlPage page = webClient.getPage(url);
return page;
} catch (IOException e) {
log.error("解析页面数据失败,页面链接为{}", url);
e.printStackTrace();
return null;
}
}
编写获得a标签的href的属性值:
public static Set<String> getATagHref(String url) {
log.info("即将从当前页面 {} 获取href",url);
try {
// 为了相对路径拼接用
String baseUrl = "https://www.zhipin.com";
HtmlPage page = HtmlUnitUtils.getPage(url);
List<HtmlElement> aTags = page.getByXPath("//a");
Set<String> allUrls = new HashSet<>();
for (HtmlElement aTag : aTags) {
String href = aTag.getAttribute("href");
// 简单判断是否时相对路径
if (!href.contains(baseUrl)&& !href.contains("http")) {
href = baseUrl + href;
}
allUrls.add(href);
}
return allUrls;
} catch (Exception e) {
return null;
}
}
3. 编写数据获取类
编写获取页面数据方法, 通过url进行判断,但是为了简单去除已经爬取的页面,所以把职位的详细信息页面链接为唯一标识,所以需要进一步检测职位的详细信息是否在已经爬取的招聘信息中:
/**
* 1 检测该页面的招聘信息的详情页的url在不在已经爬取的url里
* 1.1 已经存在,不再进行获取数据
* 1.2 不存在获取数据
*
* @param url 当前页面的url
* @param urls 所有招聘信息的详情页
* @return 所有的招聘信息
*/
public static Map<String, Object> getPageData(String url, Set<String> urls) {
try {
// 随机休眠时间
Thread.sleep(new Random().nextInt(10) * 100);
String baseUrl = "https://www.zhipin.com";
// 获取当前页面的招聘信息
HtmlPage page = HtmlUnitUtils.getPage(url);
log.info("爬取的当前页面链接: {}", url);
// 获取下一页的链接
List<HtmlElement> nextUrls = page.getByXPath("//a[@ka='page-next']");
String nextUrl = nextUrls.get(0).getAttribute("href");
// 获得当前页面的数据项
List<HtmlElement> items = page.getByXPath("//div[@class='job-primary']");
Map<String, Object> map = new HashMap<>();
for (HtmlElement item : items) {
// 获得详情信息的url,进行判断是否进行爬取
List<HtmlElement> detail = item.getByXPath(".//a[@class='primary-box']");
String href = detail.get(0).getAttribute("href") + "?" + detail.get(0).getAttribute("ka");
//如果改职位的详细页链接已包含说明数据已爬取
if (urls.contains(href)) {
continue;
}
urls.add(href);
// 职位名称
List<HtmlElement> jobTitles = item.getByXPath(".//span[@class='job-name']");
String jobTitle = jobTitles.get(0).asText();
// 职位地区
List<HtmlElement> jobAreas = item.getByXPath(".//span[@class='job-area']");
String jobArea = jobAreas.get(0).asText();
// 职位薪资
List<HtmlElement> salarys = item.getByXPath(".//span[@class='red']");
String salary = salarys.get(0).asText();
// 职位限制
List<HtmlElement> limits = item.getByXPath(".//p");
String limit = limits.get(0).asText();
// 公司相关信息
String companyType = limits.get(1).asText();
// 公司名称
List<HtmlElement> companyNames = item.getByXPath(".//h3[@class='name']");
String companyName = companyNames.get(1).getFirstChild().asText();
// 工作经验
String work = limits.get(0).getFirstChild().asText();
// 学历
String study = limit.replace(work, "");
// 招聘标签
List<HtmlElement> tags = item.getByXPath(".//span[@class='tag-item']");
List<String> tagList = new ArrayList<>();
for (HtmlElement tag : tags) {
String s = tag.asText();
tagList.add(s);
}
// 设置数据
Map<String, Object> objectMap = new HashMap<>();
objectMap.put("jobTitle", jobTitle);
objectMap.put("jobArea", jobArea);
objectMap.put("salary", salary);
objectMap.put("tags", tagList);
objectMap.put("work", work);
objectMap.put("study", study);
objectMap.put("detail", href);
objectMap.put("companyType", companyType);
objectMap.put("companyName", companyName);
objectMap.put("createTime", new Date());
map.put(href, objectMap);
System.out.println(jobTitle + "\t" + jobArea + "\t" + limit);
}
System.out.println(map);
// 如果没有下一页,停止爬取
if (nextUrl.contains("javascript")) {
return null;
}
// j爬取下一页数据
Map<String, Object> pageData = getPageData(baseUrl + nextUrl, urls);
if (pageData != null) {
map.putAll(pageData);
}
// 可用于统计已爬取数据,可进行检测
return map;
} catch (Exception e) {
return null;
}
}
编写定时任务执行的主要方法:
public void run(String params) {
// 启动时传入的参数
JSONObject jsonObject = JSON.parseObject(params);
String baseUrl = "https://www.zhipin.com";
Integer num = 0;
// 获取需要爬取的基底链接
if (jsonObject.containsKey("baseUrl")) {
baseUrl = jsonObject.getString("baseUrl");
}
// 获取几次获取所有的链接
if (jsonObject.containsKey("num")) {
num = jsonObject.getInteger("num");
}
// 获得基底页面的a标签的href
Set<String> aTagHref = HtmlUnitUtils.getATagHref(baseUrl);
Set<String> allUrls = new HashSet<>(aTagHref);
// 获取下一级级页面的所有href
while (num > 0) {
for (String allUrl : aTagHref) {
try {
int i = new Random().nextInt(10) * 100;
Thread.sleep(i);
Set<String> aTagHref1 = HtmlUnitUtils.getATagHref(allUrl);
if (aTagHref1 != null) {
allUrls.addAll(aTagHref1);
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
num--;
}
// 获取Redis缓存的已经爬取的职位详情链接
Set<String> urls = redisUtils.get("boss_urls", Set.class);
urls = urls == null ? new HashSet<>() : urls;
Map<String, Object> pageData = new HashMap<>();
int i = 0;
for (String allUrl : allUrls) {
i++;
log.info("已经下载到 {} 个页面,还剩余 {} 个页面,预估剩余数据条数数为 {},当前数据已有 {} 条", i, (allUrls.size() - i),
(allUrls.size() - i) * 100, pageData.size());
// 获得页面数据
Map<String, Object> pageData1 = getPageData(allUrl, urls);
if (pageData1 == null || pageData1.isEmpty()) {
continue;
}
pageData.putAll(pageData1);
// 查看创建boss集合
Integer boss = mongoDBClient.createCollection("boss");
if (!boss.equals(-1)) {
// 构建保存的对象
List<Object> data = new ArrayList<>();
Set<String> strings = pageData1.keySet();
for (String string : strings) {
data.add(pageData1.get(string));
}
// 保存爬取的数据
mongoDBClient.add(data, "boss");
} else {
log.error("Boss爬虫Mongo设置集合失败");
}
}
// 保存爬取的招聘详情连接
redisUtils.set("boss_urls", urls);
}
到此基本的数据应该都能获取并保存到MongoDB中。下面需要对数据进行清洗,以达到后期图表展示的目的。
4. 数据清洗
本人爬取了部分数据保存到了MongoDB中,对其进行了简单的数据清洗。主要是工作年限(word)本人采用了数字求和取平均的简单方法;薪资则采用最低的,例如10~12K,选择10K,为什么这样,相信都会明白:
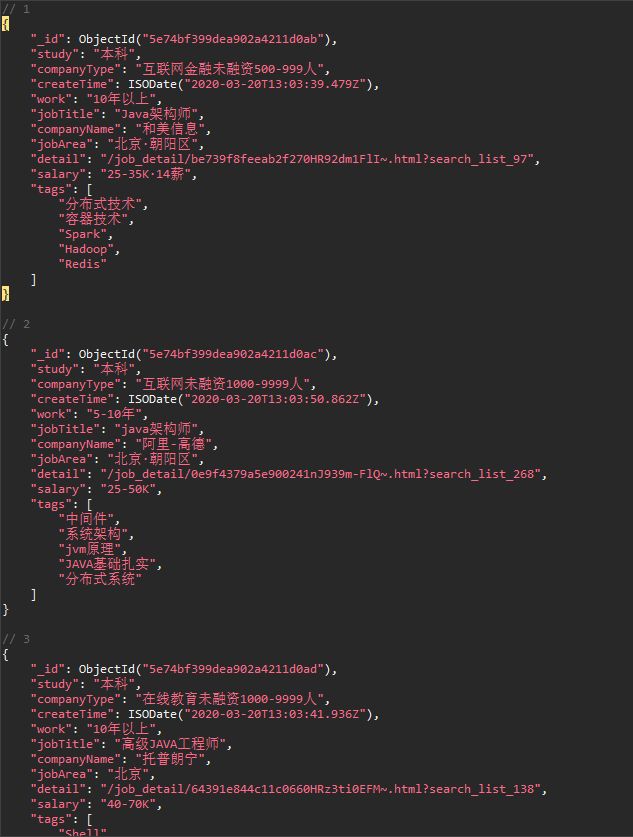
主要的清洗代码为:
public void run(String params) {
// 获取数据
List<Map<String, Object>> boss =
(List<Map<String, Object>>) mongoDBClient.getAllByCollectionName(new HashMap<String, Object>(), "boss");
for (Map<String, Object> objectMap : boss) {
// 薪资处理
String salary = (String) objectMap.get("salary");
objectMap.put("salary", getSalary(salary));
// 处理标签
List<String> tags = (List<String>) objectMap.get("tags");
String tag = "";
for (String t : tags) {
tag += t + "/";
}
objectMap.put("tags", tag);
// 处理地区
String jobArea = (String) objectMap.get("jobArea");
String[] split = jobArea.split("·");
objectMap.put("province", split[0]);
if (split.length == 2) {
objectMap.put("city", split[1]);
}
// 处理工作年限
String work = (String) objectMap.get("work");
if (work.contains("年")) {
int index = work.indexOf("年");
String substring = work.substring(0, index);
String[] split1 = substring.split("-");
Double workYear = 0.0;
for (String s : split1) {
workYear += new Double(s);
}
workYear = workYear / split1.length;
objectMap.put("work", workYear);
}else {
objectMap.put("work", 0.0);
}
}
// 转成MySQL对应的对象,进行持久化保存
List<BossDataEntity> list = new ArrayList<>();
for (Map<String, Object> objectMap : boss) {
BossDataDTO bossDataEntity = JSON.parseObject(JSON.toJSONString(objectMap), BossDataDTO.class);
list.add(bossDataEntity.toBossDataEntity());
}
// 批量保存
bossDataService.saveBatch(list);
System.out.println(boss);
}
// 处理薪资方法
private String getSalary(String salary) {
String[] split = salary.split("·");
if (split.length == 2) {
Double salaryNum = 0.0;
if (split[0].contains("K")) {
String num = split[0].replace("K", "");
String[] split1 = num.split("-");
salaryNum = new Double(split1[0]);
if (split[1].contains("薪")) {
String n = split[1].replace("薪", "");
salaryNum = salaryNum * new Integer(n);
return salaryNum + "";
}
}
} else if (split.length == 1) {
if (split[0].contains("K")) {
Double salaryNum = 0.0;
String num = split[0].replace("K", "");
String[] split1 = num.split("-");
salaryNum = new Double(split1[0]);
return salaryNum * 12 + "";
}
}
return 0+"";
}
总结
- 到此,应该基本数据的获取和清洗应该没什么问题,但还有很多可优化之处,可通过大数据进行定时执行采集数据、清洗、统计。
- 应该添加更多的定时任务,实现数据的定时清洗,和数据报表所需数据的定时处理。
- 制作报表进行显示,不能进行报表分析的数据都是无用的数据。