restframework(2):序列化解析
restframework(2):序列化解析
- 字段与选项:
- 常用字段类型:
- 通用参数
- 序列化
- 序列化意义
- 序列化实例
- 序列化解析
- 第一种表示方法——Serializers:
- 第二种表示方法——ModelSerializers:
- 两种方式的精确查找
- 两种方式的不同——多表查询
- 反序列化使用
- 补充说明
- 关联对象嵌套序列化
- 总结:
字段与选项:
常用字段类型:
| 字段 | 字段构造方式 |
|---|---|
| BooleanField | BooleanField() |
| NullBooleanField | NullBooleanField() |
| CharField | CharField(max_length=None, min_length=None, allow_blank=False, trim_whitespace=True) |
| EmailField | EmailField(max_length=None, min_length=None, allow_blank=False) |
| SlugField | SlugField(maxlength=50, min_length=None, allow_blank=False) 正则字段,验证正则模式 [a-zA-Z0-9-]+ |
| URLField | URLField(max_length=200, min_length=None, allow_blank=False) |
| IntegerField | IntegerField(max_value=None, min_value=None) |
| FloatField | FloatField(max_value=None, min_value=None) |
| DecimalField | DecimalField(max_digits, decimal_places, coerce_to_string=None, max_value=None, min_value=None) max_digits: 最多位数 decimal_palces: 小数点位置 |
| DateTimeField | DateTimeField(format=api_settings.DATETIME_FORMAT, input_formats=None) |
| DateField | DateField(format=api_settings.DATE_FORMAT, input_formats=None) |
| TimeField | TimeField(format=api_settings.TIME_FORMAT, input_formats=None) |
| DurationField | DurationField() |
| ChoiceField | ChoiceField(choices) choices与Django的用法相同 |
| FileField | FileField(max_length=None, allow_empty_file=False, use_url=UPLOADED_FILES_USE_URL) |
| ImageField | ImageField(max_length=None, allow_empty_file=False, use_url=UPLOADED_FILES_USE_URL) |
| ListField | ListField(child=, min_length=None, max_length=None) |
| DictField | DictField(child=) |
相对而言,常用字段类型是比较常见的,在我们的ORM(Object Relational Mapping,对象关系映射,简称ORM)模式里,只要是连接数据库那么就一定需要定义我们的模型参数。
通用参数
| 参数名称 | 说明 |
|---|---|
| max_length | 最大长度 |
| min_lenght | 最小长度 |
| read_only | 表明该字段仅用于序列化输出,默认False |
| write_only | 表明该字段仅用于反序列化输入,默认False |
| required | 表明该字段在反序列化时必须输入,默认True |
| default | 反序列化时使用的默认值 |
| allow_null | 表明该字段是否允许传入None,默认False |
| validators | 该字段使用的验证器 |
| error_messages | 包含错误编号与错误信息的字典 |
| label | 用于HTML展示API页面时,显示的字段名称 |
| help_text | 用于HTML展示API页面时,显示的字段帮助提示信息 |
这里比较常用的字段是前面六个,其中max_length和min_length一般配合着charfield使用,可以给它设置上下限。而read_only和write_only是两个相反的概念,前者是不接收客户端的数据,只向客户端输出数据,后者是只接收客户端的数据,不向客户端输出数据,这就可以类比于我们登录注册时的密码框,我们只需要向它写入而并不需要它像我们输出,并且该字段是经过hash加密的,寻常情况难以解密。
序列化
序列化意义
web有两种应用模式,一种是前后端不分离,一种是前后端分离,当前后端分离的时候,后端只需要向前端传输数据即可,不需要进行其他的操作,一般如果是中大型公司,都是前后端分离,这也是目前的市场规则需要,具体的可以看下图:
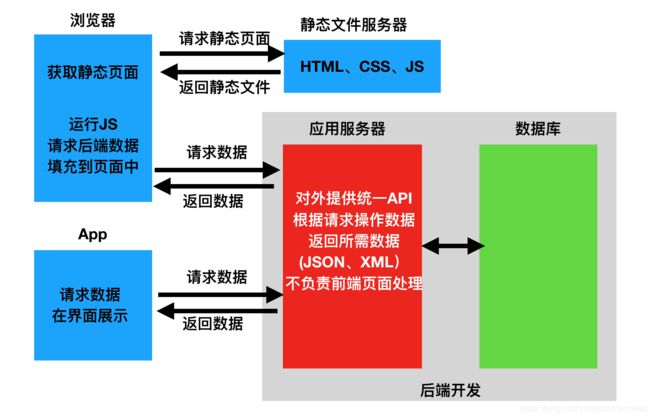
现阶段主流的数据格式为json格式,所以在restframework在前后端传输数据时,也主要是json数据,过程中就要需要把其他数据转换成json数据,比如数据库查询所有数据时,是queryset对象,那就要把这对象处理成json数据返回前端。
下面我们来看一个实例:
序列化实例
models.py 文件:
from django.db import models
# Create your models here.
class Book(models.Model):
title = models.CharField(max_length=32)
price = models.IntegerField()
pub_date = models.DateField()
publish = models.ForeignKey("Publish")
authors = models.ManyToManyField("Author")
def __str__(self):
return self.title
class Publish(models.Model):
name = models.CharField(max_length=32)
email = models.EmailField()
def __str__(self):
return self.name
class Author(models.Model):
name = models.CharField(max_length=32)
age = models.IntegerField()
def __str__(self):
return self.name
构建完models,我们通过数据库的初始化和迁移并连接我们的数据库,下面是我们序列化的几种方式。
views.py 中:
from django.shortcuts import render,HttpResponse
# Create your views here.
from django.views import View
from rest_framework.response import Response
from .models import *
from app01.serilizer import *
from rest_framework.views import APIView
class PublishView(APIView):
def get(self,request):
# 序列化
# 方式1:
publish_list=list(Publish.objects.all().values("name","email"))
return HttpResponse(json.dumps(publishers), content_type='application/json')
# 方式2:
from django.forms.models import model_to_dict
publish_list=Publish.objects.all()
temp=[]
for obj in publish_list:
temp.append(model_to_dict(obj))
return HttpResponse(json.dumps(temp), content_type='application/json')
# 方式3:
from django.core import serializers
ret=serializers.serialize("json",publish_list)
1. 对查询的数据类型进行基础数据类型的强转,比如list(queryset对象.values()),因为query set对象不能直接被序列化
2. 单个数据对象 model_to_dict(obj),是Django中的一个方法:返回一个字典,key是obj 这个对象的字段名,value是字段对应的值。这种是最快的一种序列化的方式。
3. django提供的serialize方法,data=serializers.serialize(“json”,book_list)
下面我们可以用postman进行测试,发现正常。
注意:如果上述三种方法用queryset去序列化,然后返回的将不是一个json格式的数据,那么我们的postman就会报错。

序列化解析
命名规则:
books表的增删改查:
| 路由设置 | 请求方式 | 说明 |
|---|---|---|
| /books/ | get | 返回当前所有数据 |
| /books/ | post | 返回提交数据 |
| /book/(\d+) | get | 返回当前查看的单条数据 |
| /book/(\d+) | put | 返回更新数据 |
| /book/(\d+) | delete | 返回空 |
所以我们的url配置如下:
urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'^authors/', views.AuthorView.as_view()),
url(r'^author/(?P\d+)/' , views.AuthorDetailView.as_view()),
url(r'^book/(?P\d+)/' , views.BooksDetailView.as_view()),
url(r'^books/', views.BooksView.as_view()),
]
第一种表示方法——Serializers:
view中:
from rest_framework.views import APIView
from .models import *
# Create your views here.
from rest_framework import serializers
from rest_framework.response import Response
# 构建序列化器
class AuthorSerializers(serializers.Serializer):
name = serializers.CharField(max_length=32)
age = serializers.IntegerField()
# 获取序列化数据
class AuthorView(APIView):
def get(self,request):
obj = Author.objects.all()
author = AuthorSerializers(obj,many=True)
return Response(author.data)
def post(self,request):
ps = AuthorSerializers(data=request.data)
if ps.is_valid():
print(ps.validated_data)
ps.save() # create方法
return Response(ps.data)
else:
return Response(ps.errors)
上述方法是通过继承serializer类来完成序列化,这里需要注意,因为我们的obj是个queryset对象,那么序列化字段就需要加many=True,如果是model对象,那么就不需要加many:
def get(self,request):
obj = Author.objects.all().first()
author = AuthorSerializers(obj)
return Response(author.data)
第二种表示方法——ModelSerializers:
class AuthorModelSerializers(serializers.ModelSerializer):
class Meta:
model=Author
fields="__all__" # 全部
# exclude = ('price',) # 除了price这项以外
# fields=('pub_date','title') # 只有pub、title两项
# 作者类
class AuthorView(APIView):
def get(self,request):
obj = Author.objects.all()
author = AuthorSerializers(obj,many=True)
return Response(author.data)
def post(self,request):
ps = AuthorSerializers(data=request.data)
if ps.is_valid():
print(ps.validated_data)
ps.save() # create方法
return Response(ps.data)
else:
return Response(ps.errors)
上述两种方式显示的结果都是一致的,我们可以通过postman进行测试,选择请求方式为get,得到了相同的结果。post请求方式就不再演示了,是要求我们在浏览器页面或者postman中写一个json格式数据提交,然后会在数据库中创建并保存。和上面一样,因为我们写的是queryset对象,所以序列化需要加many来约束,关于many,具体在下面说,下图为测试结果。

然后我们还可以用同样的方式查book表,因为url已经设置了,所以我们只要将视图中的AuthorModelSerializers下的Author改成Book,然后再把后面调用部分改成该序列化器:
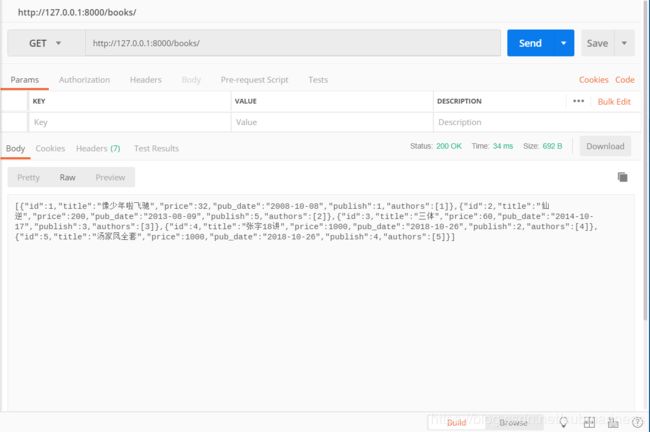
两种方式的精确查找
在开始我们的url配置中,我们在正则中还设置了两个带参数的表达式,这里同样可以通过它们的pk(主键)值找到响应的字段。并且序列化器部分也不需要改变,只需要定义的是获取数据部分:
class BookDetailView(APIView):
def get(self,request,pk):
obj = Author.objects.filter(pk=pk).first()
author_id = AuthorModelSerializers(obj)
return Response(author_id.data)
def put(self, request, pk):
author = Author.objects.filter(pk=pk).first()
ps = AuthorModelSerializers(author, data=request.data)
if ps.is_valid():
ps.save()
return Response(ps.data)
else:
return Response(ps.errors)
两种方式的不同——多表查询
对于单表查询来说,我们认为上述两种方式的表达方式基本一致,Serializers是需要我们一个个取手写字段的,而ModelSerializers是可以帮我们简化一些代码,并且fields也能设定哪些字段。但在多表中,就会不适用了,两种方式产生分歧:
1. 一对多,通过source="Book.name"指定字段
2. 多对多,通过get_字段名钩子函数来定义要获取的内容
# 一对多
# publish = serializers.CharField() #不加source时,默认给的是Publish模型定义__str__返回的字段
publish = serializers.CharField(source="publish.name")
# 多对多
# authors = serializers.CharField(source="authors.all") #获取是一个queryset对象 字符串
authors = serializers.SerializerMethodField() #通过钩子函数自定制需要的信息
def get_authors(self, obj):
temp = []
for author in obj.authors.all():
temp.append({'name':author.name, 'email':author.age})
return temp
如果我们的序列化器继承的是Serializers,那么我们只需要重新写入字段即可,因为Serializers在源码里继承的是BaseSerializer,自己并没有create字段,而Base类中,create只是返回异常。但如果是ModelSerializers,则必须要重写create方法,在源码中它已经重写了create方法,让它真正具有了功能,对整个数据表。所以create如果不重写,那么它会报错。
serializers.SerializerMethodField()是固定写法,而下面的函数名必须是get_字段名,函数的参数obj就是每一个book对象,这样我们通过这个类,在使用postman进行get请求时就能得到和上面一样的数据。
{
"id": 1,
"authors": [
1
],
"title": "像少年啦飞驰",
"price": 32,
"pub_date": "2008-10-08",
"publish": 1
},
。。。
反序列化使用
1. 验证
使用序列化器进行反序列化时,需要对数据进行验证后,才能获取验证成功的数据或保存成模型类对象。
在获取反序列化的数据前,必须调用is_valid()方法进行验证,验证成功返回True,否则返回False。验证失败,可以通过序列化器对象的errors属性获取错误信息,返回字典,包含了字段和字段的错误。如果是非字段错误,可以通过修改REST framework配置中的NON_FIELD_ERRORS_KEY来控制错误字典中的键名。验证成功,可以通过序列化器对象的validated_data属性获取数据。
在定义序列化器时,指明每个字段的序列化类型和选项参数,本身就是一种验证行为。如我们前面定义过的BookSerializer,这里我们在model的book类中再扩写几个字段,然后迁移。
class BookSerializer(serializers.Serializer):
"""图书数据序列化器"""
title = serializers.CharField(label='名称', max_length=20)
repub_date = serializers.DateField(label='再版日期', required=False)
read = serializers.IntegerField(label='阅读量', required=False)
comment = serializers.IntegerField(label='评论量', required=False)
image = serializers.ImageField(label='图片', required=False)
我们可以看官方解释翻译:
通常,如果在反序列化期间未提供字段,则会引发错误。如果在反序列化期间不需要此字段,则设置为false。将此设置为False还允许在序列化实例时从输出中省略对象属性或字典键。如果密钥不存在,它将不会包含在输出表示中。默认为True。
所以通过构造序列化器对象,并将要反序列化的数据传递给data构造参数,进而进行验证,所以可以在命令行中这样写:
>>>data = {'repub_date': '12'}
>>>serializer = BookInfoSerializer(data=data)
>>>serializer.is_valid() # False
>>>serializer.errors # {}
>>>serializer.validated_data # OrderedDict([('title', 'python')])
错误验证,我们打印的结果为:
'bpub_date': [ErrorDetail(string='Date has wrong format. Use one of these formats instead: YYYY[-MM[-DD]].', code='invalid')]}
is_valid()方法还可以在验证失败时抛出异常serializers.ValidationError,可以通过传递raise_exception=True参数开启,REST framework接收到此异常,会向前端返回HTTP 400 Bad Request响应。
# Return a 400 response if the data was invalid.
serializer.is_valid(raise_exception=True)
另外如果觉得这样不行,还有其它的验证方式可以使用:
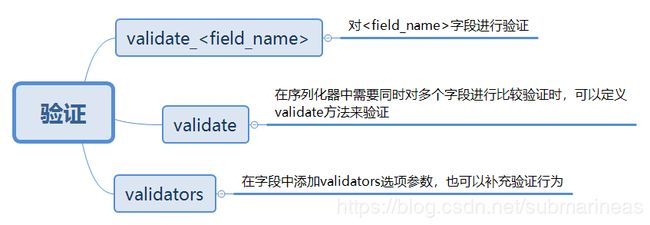
这个在这里就不再做过多描述了,等以后看源码的时候可以一起来解释含义与用法。
补充说明
关联对象嵌套序列化
如果我们想定义外键的字段的序列化,可以有以下方式:
1、PrimaryKeyRelatedField
此字段将被序列化为关联对象的主键。官方解释为可以用于使用其主键表示关系的目标。所以我们可以设置其外键形式。
https://www.django-rest-framework.org/api-guide/relations/#primarykeyrelatedfield
| 参数 | 官方解释 |
|---|---|
| queryset | 验证字段输入时用于模型实例查找的查询集。关系必须显式设置或设置查询集read_only=True。 |
| many | 如果应用于多对多关系,则应将此参数设置为True。 |
| allow_null | 如果设置为True,则该字段将接受None可为空的关系的值或空字符串。默认为False。 |
| pk_field | 设置为字段以控制主键值的序列化/反序列化。例如,pk_field |
总结:
- 指明字段时需要包含read_only=True或者queryset参数:
- 包含read_only=True参数时,该字段将不能用作反序列化使用
- 包含queryset参数时,将被用作反序列化时参数校验使用
所以可以这样表示:
book = serializers.PrimaryKeyRelatedField(label='图书', read_only=True)
或者说是:
book = serializers.PrimaryKeyRelatedField(label='图书', queryset=Book.objects.all())
2、StringRelatedField
此字段将被序列化为关联对象的字符串表示方式(即__str__方法的返回值)
book = serializers.StringRelatedField(label=‘图书’)
3、 many参数
在序列化器对象中,如果关联的对象数据不是只有一个,而是包含多个数据,此时关联字段类型的指明仍可使用上述几种方式,只是在声明关联字段时,多补充一个many=True参数即可。
此处仅拿PrimaryKeyRelatedField类型来举例,其他相同。
在BookSerializer中添加关联字段:
class BookSerializer(serializers.Serializer):
"""图书数据序列化器"""
title = serializers.CharField(label='名称', max_length=20)
repub_date = serializers.DateField(label='再版日期', required=False)
read = serializers.IntegerField(label='阅读量', required=False)
comment = serializers.IntegerField(label='评论量', required=False)
image = serializers.ImageField(label='图片', required=False)
page = serializers.PrimaryKeyRelatedField(read_only=True, many=True) # 新增
使用效果:
这里我们将序列化器和获取序列化数据部分分成两个文件,一个为serializers.py文件,一个还是原来的views.py文件,这样对以后检查代码更方便。
>>>from .serializers import BookSerializer
>>>from .models import Book
>>>book = Book.objects.get(id=2)
>>>serializer = BookSerializer(book)
>>>serializer.data
总结:
当我们在使用restframework的序列化带来便利的同时,也需要知道怎样选择一个对本项目最合适的序列化方式,以及最优的解决方案,我在写这篇博客的时候在stackoverflow上看到了一个这样的问题,假如我们想要关联字段的序列化呈现一种嵌套输出的形式,比如说是{“xx”:“123”,{“yy”:“333”,“zz”}}这种,many的话在前面试验后是输出多数据列表,但现在需要嵌套一个json数据,就可以PrimaryKeyRelatedField和source联合起来使用,具体的网址和步骤我忘了。
这篇博客历时两天,查阅了很多资料,发现还有很多东西没有囊括到,比如说超链接API:Hyperlinked,当用这个的时候,我们的views获取数据部分就要加上context={},源码中规定要把数据传递过去,还有很多小坑没有去实现过,希望以后有时间的话再从头做一遍。
参考:
[1]. https://www.django-rest-framework.org/api-guide
[2]. https://blog.windrunner.me/python/web/django-rest-framework.html
[3]. http://www.cnblogs.com/xinsiwei18/p/9742391.html
[4]. http://www.cnblogs.com/lyq-biu/p/9769421.html
[5]. https://www.cnblogs.com/fqh202/p/9608110.html
[6]. 《The Django Book 2.0中文译本》