B+ Tree & Unicode & UTF-8 & 判断是否为UTF-8 & 几种常见中文的编解码表
UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码,又称万国码。由Ken Thompson于1992年创建。现在已经标准化为RFC 3629。UTF-8用1到4个字节编码UNICODE字符。用在网页上可以同一页面显示中文简体繁体及其它语言(如日文,韩文)
UTF-16比起UTF-8,好处在于大部分字符都以固定长度的字节 (2字节) 储存,但UTF-16却无法兼容于ASCII编码。c#中默认的就是UTF-16,所以在处理c#字符串的时候只能是byte,stream等方式去处理
注意,UTF-8, UTF-16, UTF-32等都是Unicode的一种实现,只是不同的实现方式和场合罢了。。。
针对中文,除了UTF-8和UTF-16之外,
以上可以看到,针对不同的语言采用不同的编码,有可能导致冲突与不兼容性,如果我们打开一份字节序文件,如果不知道其编码规则,就无法正确解析其语义,这也是产生乱码的根本原因。有没有一种规则是全世界字符统一的呢?当然有,Unicode就是一种。为了能独立表示世界上所有的字符,Unicode采用4个字节表示一个字符,这样理论上Unicode能表示的字符数就达到了231 = 2147483648 = 21 亿左右个字符,完全可以涵盖世界上一切语言所用的符号。我们以汉字”微信“两字举例说明:
微 <-> \u5fae <-> 00000000 00000000 01011111 10101110
信 <-> \u4fe1 <-> 00000000 00000000 01001111 11100001容易从上面的例子里看出,Unicode对所有的字符编码均需要四个字节,而这对于拉丁字母或汉字来说是浪费的,其前面三个或两个字节均是0,这对信息存储来说是极大的浪费。另外一个问题就是,如何区分Unicode与其它编码这也是一个问题,比如计算机怎么知道四个字节表示一个Unicode中的字符,还是分别表示四个ASCII的字符呢?
以上两个问题,困扰着Unicode,让Unicode的推广上一直面临着困难。直至UTF-8作为Unicode的一种实现后,部分问题得到解决,才得以完成推广使用。说到此,我们可以回答文章一开始提出的问题了,UTF-8是Unicode的一种实现方式,而Unicode是一个统一标准规范,Unicode的实现方式除了UTF-8还有其它的,比如UTF-16等。
话说当初大牛Ben Thomson吃饭时,在一张餐巾纸上,设计出了UTF-8,然后回到房间,实现了第一版的UTF-8。关于UTF-8的基本规则,其实简单来说就两条(来自阮一峰老师的总结):
规则1:对于单字节字符,字节的第一位为0,后7位为这个符号的Unicode码,所以对于拉丁字母,UTF-8与ASCII码是一致的。
规则2:对于n字节(n>1)的字符,第一个字节前n位都设为1,第n+1位为0,后面字节的前两位一律设为10,
剩下没有提及的位,全部为这个符号的Unicode编码。通过,根据以上规则,可以建立一个Unicode取值范围与UTF-8字节序表示的对应关系,如下表,
举例来说,’微’的Unicode是’\u5fae’,二进制表示是”00000000 00000000 01011111 10101110“,其取值就位于’0000 0800-0000 FFFF’之间,所以其UTF-8编码为’11100101 10111110 10101110’ (加粗部分为固定编码内容)。
通过以上简单规则,UTF-8采取变字节的方式,解决了我们前文提到的关于Unicode的两大问题。同时,作为中文使用者需要注意的一点是Unicode(UTF-8)与GBK,GB2312这些汉字编码规则是完全不兼容的,也就是说这两者之间不能通过任何算法来进行转换,如需转换,一般通过GBK查表的方式来进行。
总之,ASCII是UTF-8的子集, ASCII码是GB2312的子集,GB2312是GBK的子集。。。GBK和UTF-8并不兼容,如何判断是UTF-8,下面是代码:
#include
#include
#include
#include
#include
#include
#include
using namespace std;
bool IsUTF8String(const char* str, int length)
{
int i = 0;
int nBytes = 0;//UTF8可用1-4个字节编码,ASCII用一个字节
unsigned char chr = 0;
bool bAllAscii = true;//如果全部都是ASCII,说明不是UTF-8
while (i < length)
{
chr = *(str + i);
if ((chr & 0x80) != 0)
bAllAscii = false;
if (nBytes == 0)//计算字节数
{
if ((chr & 0x80) != 0)
{
while ((chr & 0x80) != 0)
{
chr <<= 1;
nBytes++;
}
if (nBytes < 2 || nBytes > 4)
return false;//第一个字节最少为110x xxxx
nBytes--;//减去自身占的一个字节
}
}
else//多字节除了第一个字节外剩下的字节
{
if ((chr & 0xc0) != 0x80)
return false;//剩下的字节都是10xx xxxx的形式
nBytes--;
}
++i;
}
if (bAllAscii)
return false;
return nBytes == 0;
}
int main()
{
printf("%d\n", IsUTF8String("cc", strlen("cc")));
printf("%d\n", IsUTF8String("曹操", strlen("曹操")));
return 0;
} 
转自: http://www.cnblogs.com/oldhorse/archive/2009/11/16/1604009.html
B-树
是一种多路搜索树(并不是二叉的):
1.定义任意非叶子结点最多只有M个儿子;且M>2;
2.根结点的儿子数为[2, M];
3.除根结点以外的非叶子结点的儿子数为[M/2, M];
4.每个结点存放至少M/2-1(取上整)和至多M-1个关键字;(至少2个关键字)
5.非叶子结点的关键字个数=指向儿子的指针个数-1;
6.非叶子结点的关键字:K[1], K[2], …, K[M-1];且K[i] < K[i+1];
7.非叶子结点的指针:P[1], P[2], …, P[M];其中P[1]指向关键字小于K[1]的
子树,P[M]指向关键字大于K[M-1]的子树,其它P[i]指向关键字属于(K[i-1], K[i])的子树;
8.所有叶子结点位于同一层;
如:(M=3)
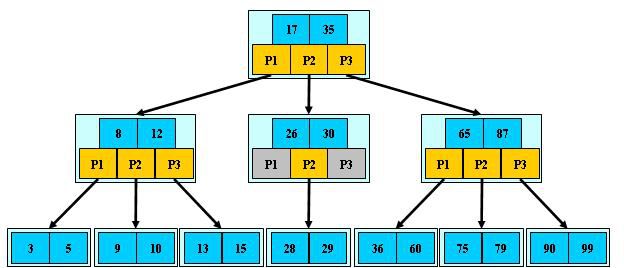
B-树的搜索,从根结点开始,对结点内的关键字(有序)序列进行二分查找,如果
命中则结束,否则进入查询关键字所属范围的儿子结点;重复,直到所对应的儿子指针为
空,或已经是叶子结点;
B-树的特性:
1.关键字集合分布在整颗树中;
2.任何一个关键字出现且只出现在一个结点中;
3.搜索有可能在非叶子结点结束;
4.其搜索性能等价于在关键字全集内做一次二分查找;
5.自动层次控制;
由于限制了除根结点以外的非叶子结点,至少含有M/2个儿子,确保了结点的至少
利用率,其最底搜索性能为:
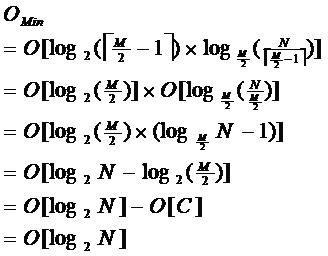
其中,M为设定的非叶子结点最多子树个数,N为关键字总数;
所以B-树的性能总是等价于二分查找(与M值无关),也就没有B树平衡的问题;
由于M/2的限制,在插入结点时,如果结点已满,需要将结点分裂为两个各占
M/2的结点;删除结点时,需将两个不足M/2的兄弟结点合并;
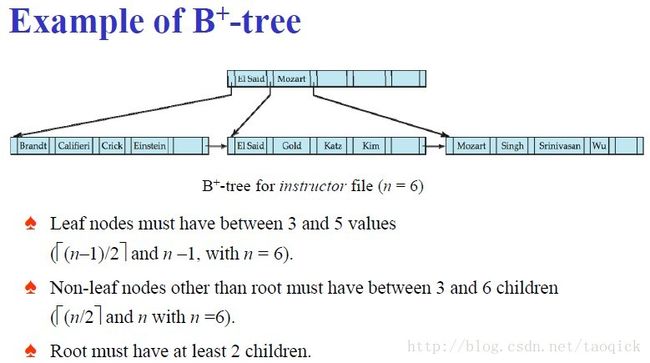
B+树
B+树是B-树的变体,也是一种多路搜索树:
1.其定义基本与B-树同,除了:
2.非叶子结点的子树指针与关键字个数相同;
3.非叶子结点的子树指针P[i],指向关键字值属于[K[i], K[i+1])的子树
(B-树是开区间);
5.为所有叶子结点增加一个链指针;
6.所有关键字都在叶子结点出现;
如:(M=3)

B+的搜索与B-树也基本相同,区别是B+树只有达到叶子结点才命中(B-树可以在
非叶子结点命中),其性能也等价于在关键字全集做一次二分查找;
B+的特性:
1.所有关键字都出现在叶子结点的链表中(稠密索引),且链表中的关键字恰好
是有序的;
2.不可能在非叶子结点命中;
3.非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储
(关键字)数据的数据层;
4.更适合文件索引系统;
B-和B+树的区别:
1. B+添加了叶节点的链指针
2. B-可以在内结点存放关键字。。。