PostgreSQL 用户自定义函数FUNCTION创建及调用(完整)
PostgreSQL函数也称为PostgreSQL存储过程。
PostgreSQL函数或存储过程是存储在数据库服务器上并可以使用SQL界面调用的一组SQL和过程语句(声明,分配,循环,控制流程等)。 它有助于您执行通常在数据库中的单个函数中进行多次查询和往返操作的操作。
您可以在许多语言(如SQL,PL/pgSQL,C,Python等)中创建PostgreSQL函数。
要在 PostgreSQL 定义一个新的用户自定义函数,需要使用 CREATE FUNCTION 语句,如下所示:
CREATE [OR REPLACE] FUNCTION function_name (arguments)
RETURNS return_datatype AS $variable_name$
DECLARE
declaration;
[...]
BEGIN
< function_body -- 函数逻辑 >
[...]
RETURN { variable_name | value }
END;
LANGUAGE plpgsql;
---------------------------------------------------------
CREATE FUNCTION function_name(p1 type, p2 type)
RETURNS type AS
BEGIN
-- 函数逻辑
END;
LANGUAGE language_name;
来看下 CREATE FUNCTION 语句的细节:
- 首先,在
CREATE FUNCTION语句后面给定函数的名称 - 然后,在函数名称后面的圆括号内放置逗号分隔的参数列表
- 接下来,在
RETURNS关键字之后指定函数的返回类型 - 之后,将代码放在
BEGIN和END块内。该函数始终以分号(;)结尾,紧跟在END关键字之后 - 最后,说明函数的过程语言。比如,使用
plpgsql表示 PL/pgSQL
创建函数1(只包含函数输入参数,不包含输出参数)
CREATE OR REPLACE FUNCTION add(a INTEGER, b NUMERIC)
RETURNS NUMERIC AS $$
SELECT a+b;
$$
LANGUAGE SQL;已创建好的函数
CREATE OR REPLACE FUNCTION "public"."add"("a" int4, "b" numeric)
RETURNS "pg_catalog"."numeric" AS $BODY$
SELECT a+b;
$BODY$
LANGUAGE sql VOLATILE
COST 100 
调用函数 1

创建函数2(同时包含输入参数和输出参数)
IN代表输入参数,OUT代表输出参数
CREATE OR REPLACE FUNCTION input_and_output(IN a INTEGER, IN b NUMERIC, OUT c NUMERIC, OUT d NUMERIC)
AS $$
SELECT a+b, a-b;
$$
LANGUAGE SQL;已创建好的函数
CREATE OR REPLACE FUNCTION "public"."input_and_output"(IN "a" int4, IN "b" numeric, OUT "c" numeric, OUT "d" numeric)
RETURNS "pg_catalog"."record" AS $BODY$
SELECT a+b, a-b;
$BODY$
LANGUAGE sql VOLATILE
COST 100调用函数2
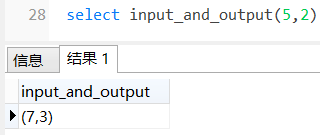
创建函数3(Mybatis mapper中使用函数)
DO $$
DECLARE num INTEGER=0;
BEGIN
select count(*) into num as num from (select distinct cardnum from
bus_data) as A;
insert into ic_test
select num, dt
from bus_data limit 100;
END $$;
调用函数3
/**
* testFun Dao接口
* @param dtstr
*/
void testFun(String dtstr);
//调用函数3
sqlSession = SqlSessionFactoryUtil.getLocalSqlSessionFactory().openSession();
TrackDao trackDao = sqlSession.getMapper(TrackDao.class);
trackDao.testFun(dtstr);存储过程的优势:
1.降低或减少应用程序与数据库服务器的网络通信开销,从而提升整体性能,BI系统中尤为重要
2.可以有效减少程序开发的复杂性,达到多次复用的目的,保证不同应用之间的一致性。
3.一次编译多次调用,提高性能。存储过程在第一次被调用后即被编译,之后再调用时无需再次编译,直接执行,提高了性能
4.较好的保护数据库元信息。使用存储过程并不知道数据库表结构,不会将数据库表结构暴露给调用方。
5.很好的将业务逻辑实现与应用程序解耦合。当业务需求更新时,只需更改存储过程的定义,而不需要更改应用程序。
6.更细粒度的数据库权限管理。使用存储过程可在存储过程中将应用程序无权访问的数据屏蔽
存储过程的劣势:
1.可移植性差。不像sql一样,针对大多数数据库而不影响应用程序使用,存储过程由于不同数据库的定义方式不同,支持的语言及语法也都不同,移植成本较高
2.不便于调试。以PostgreSQL为例,使用存储过程时,无法使用EXPLAIN 分析其内部执行计划,不方便进行性能调优。