动手学习深度学习keras版——从零开始实现Vnet 2D版
从零开始实现Vnet 2D版
- 1. 数据处理
- 1.1 数据集介绍
- 1.2 数据提取和转换
- 1.3 Keras的数据生成器(generator)构造
- 2. Vnet 2D版网络实现
- 2.1 Loss函数设计
- 2.2 网络结构实现
- 3. 开始训练啦
- 4. 网络预测(inference)
- 5. 结果展示
- 6. 踩坑经验总结
工作需要,暂时换成keras来写网络代码。其实感觉还是pytorch用起来灵活整洁一些。有时间还是会继续出pytorch版的,顺便看看两个深度学习框架之间的差别。
文中的代码是根据github上的一个项目进行修改的,借用了他的思路,因此在此放出参考项目的链接:https://github.com/FENGShuanglang/2D-Vnet-Keras
1. 数据处理
1.1 数据集介绍
由于这是医疗图像领域的网络,所以我也特地去找了医疗图像的分割任务数据集,数据集来源是:https://warwick.ac.uk/fac/sci/dcs/research/tia/glascontest/download/。
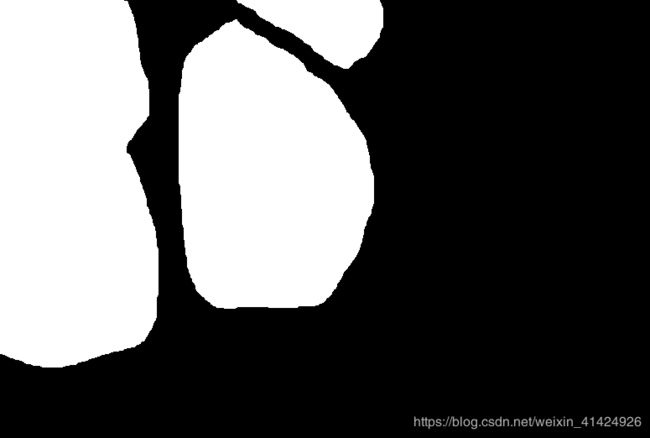
这个数据集的分割任务其实很简单,就是找出图像中的目标细胞即可。是个二分类任务,只分为前景和背景。下图是一个样本及其mask标签(已经经过可视化处理),可以看到,其实就是寻找细胞的分割任务。另外,原数据集的样本数据是实例分割任务,也就是说,图中的三个细胞,其实在原来的标签里分别以数值1,2,3储存。实例分割就是不单单区分目标的类别,同种类的不同实例也属于不同类别。为了简化任务,我们把任务改成语义分割任务,即只需要分割目标的种类即可,不用分割具体实例。所以才有了下图的样本图像。

1.2 数据提取和转换
下载数据集后,按下图新建文件夹,文件夹的名字也很好理解,比如"SegTrainImg"里存放的是训练用的图像,"SegTrainMaskImg"存放的是对应训练图像的mask图像。建这么多文件夹是因为keras读取数据的方式决定的,这样可以免去自己写读取数据的繁琐过程。

我自己写了个脚本把原图像数据集文件夹内的图像分别复制到对应六个文件夹中,这样快一点,省的自己复制。代码如下:
import os
import cv2
def data_prepare():
"""将图像分割用的图片从JPEGImages文件夹提取到SegTrainImg和SegValImg里"""
dataset_path = r'D:\My_project\deeplearning\datasets\warwick_qu_dataset'
imgpath = r'D:\My_project\deeplearning\datasets\warwick_qu_dataset\Warwick_QU_Dataset'
trainimg_savepath = os.path.join(dataset_path,'SegTrainImg')
trainmask_savepath = os.path.join(dataset_path, 'SegTrainMaskImg')
valimg_savepath = os.path.join(dataset_path,'SegValImg')
valmask_savepath = os.path.join(dataset_path, 'SegValMaskImg')
testimg_savepath = os.path.join(dataset_path,'SegtestImg')
testmask_savepath = os.path.join(dataset_path, 'SegTestMask')
filelist = os.listdir(imgpath)
for file in filelist:
if 'testA' in file:
img = cv2.imread(os.path.join(imgpath,file))
savepath = os.path.join(valimg_savepath,file) if 'anno' not in file else os.path.join(valmask_savepath,file)
cv2.imwrite(savepath,img)
elif 'testB' in file:
img = cv2.imread(os.path.join(imgpath, file))
savepath = os.path.join(testimg_savepath, file) if 'anno' not in file else os.path.join(testmask_savepath,file)
cv2.imwrite(savepath, img)
elif 'train' in file:
img = cv2.imread(os.path.join(imgpath, file))
savepath = os.path.join(trainimg_savepath, file) if 'anno' not in file else os.path.join(trainmask_savepath,file)
cv2.imwrite(savepath, img)
print("Done")
处理好后,可以得到85张训练集、60张验证集以及20张测试集图像。数据集不大,倒是很符合医学图像的情况。这样训练起来也很快。硬件设备不够的同学(比如我)跑起代码来就很舒服了。
1.3 Keras的数据生成器(generator)构造
简要说明一下Keras的数据集生成原理。Keras提供了一个keras.preprocessing.image.ImageDataGenerator类,可以很方便的进行数据增广和数据生成。具体的步骤如下:
1). 构造ImageDataGenerator类实例,其中传入需要的数据增广参数,提供的参数可以查阅keras官方文档;
2). 使用ImageDataGenerator类设置读取数据的位置和方式,总共有三种方式,我采用的是".flow_from_directory()"函数,这应该是最方便,也最省内存空间的方式,因为它不需要提前加载所有数据,只有需要的时候才会提取。
3). 用关键字yield构造python的生成器,此时该生成器函数就是对应数据集的生成器。
光看文字不太好理解,下面上代码:
DATA_PATH = r'..\datasets\warwick_qu_dataset' # 数据集文件夹路径
def train_generator(img_size, batch_size, gen_arg_dict={}, seed=1):
"""
训练数据生成器
:param img_size: 生成的目标图片尺寸
:param batch_size: 批量大小
:param gen_arg_dict: 数据增广参数
:param seed: 随机抽样的随机种子
:return: 标准化后的图像以及转换为类别序号的mask
"""
train_datagen = ImageDataGenerator(**gen_arg_dict) # 设置数据增广实例
gen_arg_dict['rescale'] = 1 # mask不需要标准化,方便后续处理
mask_datagen = ImageDataGenerator(**gen_arg_dict) # mask的数据增广应当和原始图片一模一样
# 加载数据发生器,注意,classes是存放img/mask数据的文件夹名称,且img/mask两者的随机种子seed和batchsize要保持一致
img_generator = train_datagen.flow_from_directory(DATA_PATH,classes=['SegTrainImg'],target_size=img_size,seed=seed,batch_size=batch_size)
mask_generator = mask_datagen.flow_from_directory(DATA_PATH,classes=['SegTrainMaskImg'],target_size=img_size,seed=seed,batch_size=batch_size)
train_generator = zip(img_generator,mask_generator) # 将图片数据和mask数据整合
for(img, mask) in train_generator:
img = img[0]
mask = mask2label(mask[0])
yield (img,mask)
其中有几点要说明。参数gen_arg_dict是数据增广的参数字典,前面的**是字典分解。不这么写,直接写参数名和数值也可以。.flow_from_directory()函数中,第一个参数是数据的总文件夹路径,内含训练集、测试集等数据文件夹。classes参数是输入对应数据的文件夹名称,比如’SegTrainImg’就是训练集图像的文件夹名称。其实flow_from_directory()函数就是调用某个文件夹下的所有图像文件,并根据设置好的参数进行数据增广的数据生成器(即img_generator,mask_generator)。
注意,生成器最终输入到网络中的数据是“yield (img,mask)”这条语句返回的img,mask数据。如果需要在ImageDataGenerator的数据增广外,另外做其他的数据预处理,可以自己编写函数,只要保证数据格式能输入到网络即可。比如上面代码中的mask2label()函数,就是对mask函数进行额外处理的,具体代码见下面:
def mask2label(mask):
"""
将原始的mask图像转换为label数据格式,即按类别顺序分为0,1,2,...
:param mask: 原始mask图像
:return: 转换后的label
"""
mask[mask>0] = 1
mask = mask[:,:,:,0]
mask = mask[:,:,:,np.newaxis]
return mask
同理,可以构建验证集数据生成器和测试集数据生成器。
def val_generator(img_size, batch_size=1):
val_datagen = ImageDataGenerator(rescale=1./255)
img_generator = val_datagen.flow_from_directory(DATA_PATH,classes=['SegValImg'],target_size=img_size,batch_size=batch_size,seed=1)
mask_datagen = ImageDataGenerator()
mask_generator = mask_datagen.flow_from_directory(DATA_PATH, classes=['SegValMaskImg'], target_size=img_size,batch_size=batch_size, seed=1)
val_generator = zip(img_generator, mask_generator) # 将图片数据和mask数据整合
for (img,mask) in val_generator:
img = img[0]
mask = mask2label(mask[0])
yield (img,mask)
def test_generator(img_size, batch_size=1):
test_datagen = ImageDataGenerator(rescale=1./255)
img_generator = test_datagen.flow_from_directory(DATA_PATH,classes=['SegtestImg'],target_size=img_size,batch_size=batch_size)
for img in img_generator:
img = img[0]
yield img
另外,还是提醒一下,和pytorch的教程里一样,写完数据生成器,一定要检查一下数据是否正常,不是网络能跑就可以的,一定要检验输入的数据是我们设定好的数据,而不是错误的数据。
2. Vnet 2D版网络实现
2.1 Loss函数设计
正如分析论文的博客里提到的那样,Vnet使用的是Dice指标和Dice损失函数。具体该损失函数的含义可以参考链接里的博客。代码其实很简单,至于用在哪下文会具体阐述:
def dice_coef(y_true, y_pred):
"""dice指标"""
smooth = 1e-6 # 防止分母为0的极小值
y_true_f =y_true# K.flatten(y_true)
y_pred_f =y_pred# K.flatten(y_pred)
intersection = K.sum(y_true_f * y_pred_f,axis=(0,1,2))
denom =K.sum(y_true_f,axis=(0,1,2)) + K.sum(y_pred_f,axis=(0,1,2))
return K.mean((2. * intersection + smooth) /(denom + smooth))
def dice_loss(smooth, thresh):
"""dice_loss,注意"""
def dice(y_true, y_pred):
return 1-dice_coef(y_true, y_pred)
return dice
2.2 网络结构实现
从网络结构图可以看出,Vnet的网络主要分为左右两侧,且两侧结构十分相似,每个stage之间也有规律。因此,构建网络的时候可以用点技巧,不用一层层的搭建,那样太麻烦了。为压缩路径和扩展路径分别写了两个子函数进行构建,即downstage_resBlock和upstage_resBlock:
def downstage_resBlock(x, stage_id, keep_prob, stage_num=5):
"""
Vnet左侧的压缩路径的一个stage层
:param x: 该stage的输入
:param stage_id: int,表示第几个stage,原论文中从上到下依次是1-5
:param keep_prob: dropout保留元素的概率,如果不需要则设置为1
:param stage_num: stage_num是Vnet设置的stage总数
:return: stage下采样后的输出和stage下采样前的输出,下采样前的输出需要与Vnet右侧的扩展路径连接,所以需要输出保存。
"""
x0 = x # x0是stage的原始输入
# Vnet每个stage的输入会进行特定次数的卷积操作,1~3个stage分别执行1~3次卷积,3以后的stage均执行3次卷积
# 每个stage的通道数(卷积核个数或叫做feature map数量)依次增加两倍,从16,32,64,128到256
for _ in range(3 if stage_id > 3 else stage_id):
x=PReLU()(BatchNormalization()(Conv2D(16 * (2 ** (stage_id - 1)), 5, activation=None, padding ='same', kernel_initializer ='he_normal')(x)))
print('conv_down_stage_%d:' %stage_id,x.get_shape().as_list())#输出收缩路径中每个stage内的卷积
x_add=PReLU()(add([x0, x]))
x_add=Dropout(keep_prob)(x_add)
if stage_id<stage_num:
x_downsample=PReLU()(BatchNormalization()(Conv2D(16 * (2 ** stage_id), 2, strides=(2, 2), activation=None, padding ='same', kernel_initializer ='he_normal')(x_add)))
return x_downsample,x_add # 返回每个stage下采样后的结果,以及在相加之后的结果
else:
return x_add,x_add # 返回相加之后的结果,为了和上面输出保持一致,所以重复输出
def upstage_resBlock(forward_x, x, stage_id):
"""
Vnet右侧的扩展路径的一个stage层
:param forward_x: 对应压缩路径stage层下采样前的特征,与当前stage的输入进行叠加(不是相加),补充压缩损失的特征信息
:param x: 当前stage的输入
:param stage_id: 当前stage的序号,右侧stage的序号和左侧是一样的,从下至上是5到1
:return:当前stage上采样后的输出
"""
input = concatenate([forward_x, x], axis=-1)
for _ in range(3 if stage_id > 3 else stage_id):
input=PReLU()(BatchNormalization()(Conv2D(16 * (2 ** (stage_id - 1)), 5, activation=None, padding='same', kernel_initializer='he_normal')(input)))
print('conv_down_stage_%d:' % stage_id, x.get_shape().as_list()) # 输出收缩路径中每个stage内的卷积
conv_add=PReLU()(add([x, input]))
if stage_id>1:
# 上采样的卷积也称为反卷积,或者叫转置卷积
conv_upsample=PReLU()(BatchNormalization()(Conv2DTranspose(16 * (2 ** (stage_id - 2)), 2, strides=(2, 2), padding='valid', activation=None, kernel_initializer='he_normal')(conv_add)))
return conv_upsample
else:
return conv_add
利用这两个子函数,就可以很方便的搭建出Vnet的网络如下:
def Vnet(pretrained_weights=None, input_size = (256, 256, 1), num_class=1, is_training=True, stage_num=5):
"""
Vnet网络构建
:param pretrained_weights:是否加载预训练参数
:param input_size: 输入图像尺寸(w,h,c),c是通道数
:param num_class: 数据集的类别总数
:param is_training: 是否是训练模式
:param stage_num: Vnet的网络深度,即stage的总数,论文中为5
:return: Vnet网络模型
"""
keep_prob = 0.5 if is_training else 1.0 # dropout概率
left_featuremaps=[]
input_data = Input(input_size)
x = PReLU()(BatchNormalization()(Conv2D(16, 5, activation = None, padding = 'same', kernel_initializer='he_normal')(input_data)))
# 数据经过Vnet左侧压缩路径处理
for s in range(1,stage_num+1):
x, featuremap=downstage_resBlock(x, s, keep_prob, stage_num)
left_featuremaps.append(featuremap) # 记录左侧每个stage下采样前的特征
# Vnet左侧路径跑完后,需要进行一次上采样(反卷积)
x_up = PReLU()(BatchNormalization()(Conv2DTranspose(16 * (2 ** (s - 2)),2,strides=(2, 2),padding='valid',activation=None, kernel_initializer='he_normal')(x)))
# 数据经过Vnet右侧扩展路径处理
for d in range(stage_num-1,0,-1):
x_up = upstage_resBlock(left_featuremaps[d - 1], x_up, d)
if num_class>1:
conv_out=Conv2D(num_class, 1, activation='softmax', padding = 'same', kernel_initializer = 'he_normal')(x_up)
else:
conv_out=Conv2D(num_class, 1, activation='sigmoid', padding = 'same', kernel_initializer = 'he_normal')(x_up)
model=Model(inputs=input_data,outputs=conv_out)
print(model.output_shape)
model_dice=dice_loss(smooth=1e-5,thresh=0.5) # dice损失函数,二分类时可以使用,多分类需要修改
if num_class > 1:
model.compile(optimizer=SGD(lr=0.001,momentum=0.99,decay=1e-6), loss='sparse_categorical_crossentropy', metrics = ['ce']) # metrics看看需不需要修改
else:
model.compile(optimizer=SGD(lr=0.001, momentum=0.99, decay=1e-6), loss='binary_crossentropy',
metrics=['binary_accuracy'])
# model.compile(optimizer=SGD(lr=0.001, momentum=0.99, decay=1e-6), loss=dice_loss,metrics=[model_dice]) # 如果需要使用dice和dice_loss函数,则改为注释中的样子
if pretrained_weights:
model.load_weights(pretrained_weights)
# plot_model(model, to_file='model.png') # 绘制网络结构
return model
提醒一下,model.compile的时候,要非常注意loss和metrics的取值,这两者的选用要和数据、任务类型相匹配才行,如果不匹配,轻则报错无法训练,重则训练了很久得到的结果完全无法用。另外还要注意,input_data只能是Input()类,不要在下面的代码中将其他过程结果赋值给input_data,这样就无法定位到Input()类里了,最后在model=Model(inputs=input_data…)这条语句时,参数inputs就无法正确找到Input()类,会报错的。
3. 开始训练啦
训练代码如下,还是比较简洁的,其中的注意点也在代码里注释了。
COLOR_DICT = {"cell":(255,255,255)} # 主要是给多类别的时候使用的
CLASSES = list(COLOR_DICT.keys()) # 类别的名称list
if __name__ == '__main__':
batchsize = 10
seed = 1
img_size = (256, 256)
gen_arg_dict = {"rescale": 1 / 255., "horizontal_flip": True, "vertical_flip":True, "rotation_range":20, "shear_range":0.1, "width_shift_range":0.1,"height_shift_range":0.1} # 数据增广参数
is_train = False # 训练还是预测的标志
if is_train:
trainGen = train_generator(img_size, batchsize, gen_arg_dict) # 构建训练集数据生成器
valGen = val_generator(img_size) # 验证集数据生成器
model = Vnet(num_class=len(CLASSES), input_size=(256, 256, 3)) # 构建网络
# 用来储存训练过程网络参数的回调函数,save_best_only=True是如果要保存的模型的指标不是最优的,就不保存了。
# monitor就是判断网络效果的指标,verbose是输出方式可以忽略,mode和monitor配合,定义指标的以最大为最优还是最小为最优
# period是每隔多少epoch保存一次模型
model_checkpoint = ModelCheckpoint('Vnetweights_cellseg.{epoch:02d}-{val_loss:.2f}.hdf5', monitor='val_loss', verbose=1,save_best_only=True, mode='min',period=1)
# 输出给tensorboard使用的信息的回调函数,具体可以百度用法
tbCallBack = keras.callbacks.TensorBoard(log_dir='./graph',histogram_freq=0,write_graph=True,write_images=True)
# 注意,这里的steps_per_epoch的数字需要自己计算,根据训练集和batchsize的数值计算。callbacks参数存放需要在训练过程中使用的回调函数
model.fit_generator(trainGen, steps_per_epoch=8, epochs=100, validation_data=valGen, validation_steps=6,
callbacks=[model_checkpoint,tbCallBack])
else:
# 预测的时候要注意,如果model.compile的时候损失函数和metrics使用的是自定义函数
# 那么load_model的时候需要增加指定参数custom_objects={"dice":dice_loss(1e-5,0.5),"dice_coef":dice_coef}
model = keras.models.load_model("Vnetweights_cellseg.11-0.71.hdf5")
testGen = test_generator(img_size) # 测试集数据生成器
# 得到的pred结果是(20,256,256,1)的尺寸,代表20张预测图像的预测mask结果,其中数值>0.5意为是前景
pred = model.predict_generator(testGen, 20, verbose=1)
savepath = r'..\datasets\warwick_qu_dataset\SegTestMask'
decode_and_save(pred,savepath) # 将pred储存的数据进行解码,并保存解码后预测的mask图像
4. 网络预测(inference)
预测时,修改好训练保存的网络参数名称后,修改is_train=False即可进行预测。网络预测后,得到的结果需要解码转换为所需的预测mask图像。该解码函数如下:
def decode_and_save(pred,savepath):
"""将预测的数据转换为可视图并储存"""
n = pred.shape[0]
for i in range(n):
if len(CLASSES)>1:
ipred = pred[i, :, :, :]
ipred = np.argmax(ipred, axis=2)
img = np.zeros((ipred.shape[0], ipred.shape[1], 3), dtype='uint8')
for r in range(ipred.shape[0]):
for c in range(ipred.shape[1]):
img[r, c, 2], img[r, c, 1], img[r, c, 0] = COLOR_DICT[CLASSES[ipred[r, c]]][0], \
COLOR_DICT[CLASSES[ipred[r, c]]][1], \
COLOR_DICT[CLASSES[ipred[r, c]]][2]
cv2.imwrite(os.path.join(savepath, str(i) + '.jpg'), img)
else:
ipred = pred[i, :, :, :]
ipred[ipred > 0.5] = 255
ipred = ipred.astype(np.uint8)
cv2.imwrite(os.path.join(savepath, str(i) + '.jpg'), ipred)
5. 结果展示
随意跑了20个epoch,也没怎么调参,效果好像不是很好,但是也能看出个大概,贴上来大家看看。后续效果调好一点再增加更好的预测图像。




6. 踩坑经验总结
写代码时候遇到的一些报错,想想还是记录一下比较好,省的以后又百度半天。
-
经验1 报错信息如下:
 这次报错是因为,我用代码来跑多分类任务,设计的label是整数型而不是one-hot,也就是说,label是类别的序号(0-n),而不是n维的onehot向量。所以,model.compile选择的loss=’ sparse_categorical_crossentropy’。原代码默认选择的metrics=[‘acc’],这是应用在二分类问题的评测标准,网络的输出与评测标准不一致,所以报错说shape不同。
这次报错是因为,我用代码来跑多分类任务,设计的label是整数型而不是one-hot,也就是说,label是类别的序号(0-n),而不是n维的onehot向量。所以,model.compile选择的loss=’ sparse_categorical_crossentropy’。原代码默认选择的metrics=[‘acc’],这是应用在二分类问题的评测标准,网络的输出与评测标准不一致,所以报错说shape不同。
对于多分类问题,metrics要选择’ce’/’crossentropy’,这样问题解决。可以参考如下网站,里面有比较详细的什么问题使用什么metrics的介绍:
https://www.cnblogs.com/weiyinfu/p/9783776.html -
经验2 报错信息:“tensorflow.python.framework.errors_impl. UnknownError: Failed to get convolution algorithm. This is probably because cuDNN failed to initialize, so try looking to see if a warning log message was printed above.”
其实是keras的backend,也就是tensorflow的版本和CUDA或者CUDNN版本不匹配导致的。当时报错时我是用的是tensorflow-gpu 1.12.0 cuda 9.0 cudnn 7.0。后来重装为tensorflow-gpu 1.9.0,问题解决。 -
经验3 报错信息如下:

这是因为在网络构建的时候,我们使用的是自己的loss或者metric函数,此时保存网络时,记录的loss名称是当时我们使用的loss函数名,上图中是“dice”。因此,在加载网络的时候,需要提供参数“custom_objects={“dice”:dice_loss(1e-5,0.5),“dice_coef”:dice_coef}”,这里我们使用了自己的loss和metric,所以提供了两个元素的字典。