CDH 6.3.1整合Zeppelin 0.8.2
目录
一、安装Zeppelin
二、配置Zeppelin的用户名密码
三、使用Zeppelin查询CDH的hive表
四、定义Hive解释器
五、定义MySQL解释器
Zeppelin是一个基于Web的笔记本,可以直接在浏览器中编写代码,对数据进行查询分析并生成报表或图表,做出数据驱动的、交互、协作的文档,并且可以共享笔记。Zeppelin提供了内置的Apache Spark集成,提供的功能有:
- 自动引入SparkContext 和 SQLContext
- 从本地文件系统或maven库载入运行时依赖的jar包。
- 可取消Spark作业和展示作业进度。
在数据可视化方面,Zeppelin已经包含一些基本的图表,如柱状图、饼图、线形图、散点图等。可视化并不只限于Spark查询,任何支持的后端语言输出都可以被图形化表示。
Zeppelin中最核心的概念是解释器,它是一个插件式的体系结构,允许任何语言或后端数据处理程序以插件的形式添加到Zeppelin中。解释器允许用户使用一个指定的语言或数据处理器。每一个解释器都属于换一个解释器组,同一个解释器组中的解释器可以相互引用,例如SparkSql解释器可以引用Spark解释器以获取Spark上下文,因为它们属于同一个解释器组。当前的Zeppelin已经支持很多解释器,如cassandra、file、hbase、kylin、phoenix、elasticsearch、flink、hive、jdbc、psql等等。插件式架构允许用户在Zeppelin中使用自己熟悉的程序语言处理数据。例如,通过使用%spark解释器,可以在Zeppelin中使用Scala语言代码。
一、安装Zeppelin
CDH中没有集成Zeppelin服务,因此需要手工安装。下面是在CDH 6.3.1中安装Zeppelin 0.8.2的主要步骤。
1. 下载Zeppelin安装包
Zeppelin提供源码和二进制两种安装包,源码需要用户自己进行编译,二进制包解压后即可直接运行。为简单起见选择安装二进制包。
下载地址:
http://www.apache.org/dyn/closer.cgi/zeppelin/zeppelin-0.8.2/zeppelin-0.8.2-bin-all.tgz
安装指南:
http://zeppelin.apache.org/docs/0.8.2/quickstart/install.html
https://datacouch.io/install-apache-zeppelin-on-cdh/
2. 解压缩Zeppelin安装包
mkdir /opt/zeppelin
tar -xvf zeppelin-0.8.2-bin-all.tgz -C /opt/zeppelin3. 配置Zeppelin
在Zeppelin配置文件目录中,创建名为zeppelin-env.sh的环境文件,在其中配置Hadoop配置目录、hive的配置文件的classpath目录、Zeppelin服务器的IP地址和端口号。
cd /opt/zeppelin/zeppelin-0.8.2-bin-all/conf
vi zeppelin-env.sh
export HADOOP_CONF_DIR=/etc/hadoop/conf
export ZEPPELIN_INTP_CLASSPATH_OVERRIDES=/etc/hive/conf
export ZEPPELIN_ADDR=172.16.1.126
export ZEPPELIN_PORT=90914. 修改权限
将Zeppelin安装目录的权限设置为777。
chmod -R 777 /opt/zeppelin5. 启动Zeppelin
cd /opt/zeppelin/zeppelin-0.8.2-bin-all
./bin/zeppelin-daemon.sh start至此已经完成Zeppelin在CDH上的安装,从浏览器可以打开Zeppelin:http://172.16.1.126:9091
二、配置Zeppelin的用户名密码
缺省Zeppelin使用匿名用户访问,不需要用户名密码,但可以通过简单的配置为Zeppelin增加鉴权功能。shiro.ini文件用来多用户登录和权限管理,可以编辑此文件,根据自己的需要设置登录zeppelin的用户名和密码。
cd /opt/zeppelin/zeppelin-0.8.2-bin-all/conf
cp shiro.ini.template shiro.ini
vi shiro.ini
...
[users]
# List of users with their password allowed to access Zeppelin.
# To use a different strategy (LDAP / Database / ...) check the shiro doc at http://shiro.apache.org/configuration.html#Configuration-INISections
# To enable admin user, uncomment the following line and set an appropriate password.
#admin = password1, admin
user1 = password2, role1, role2
user2 = password3, role3
user3 = password4, role2
...将admin这行的注释删掉。等号两边分别为用户名和密码,逗号后面设置的是权限,这里都设置为admin。保存配置后重启zeppelin:
/opt/zeppelin/zeppelin-0.8.2-bin-all/bin/zeppelin-daemon.sh start然后重新登录zeppelin,首页会变成了欢迎页面,要想使用Zeppelin需要先登录,如图1所示。
 图1
图1
三、使用Zeppelin查询CDH的hive表
完成前面的步骤后,就可以新建note,执行SparkSQL查询hive表,不在需要任何额外配置,如图2所示。
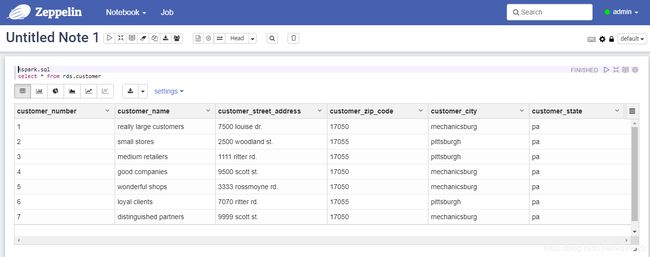 图2
图2
需要说明的一点是,我们安装的Zeppelin 0.8.2与CDH 6.3.1的Spark有版本兼容性问题。因此这里使用的spark是Zeppelin自带的,spark master为缺省的本地,如图3所示。
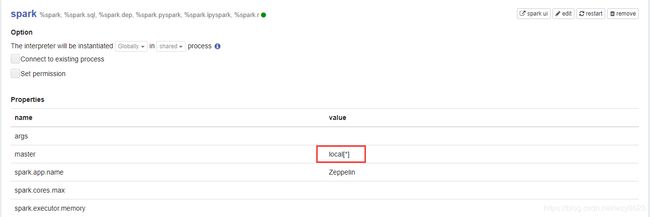 图3
图3
四、定义Hive解释器
虽然不能直接使用CDH集群中的Spark直接查询hive表,但是可以自定义一个JDBC的hive解释器,将Zeppelin作为客户端连接到Hive服务器。只要将Hive的执行引擎配置为Spark,就可以间接使用CDH的Spark查询hive。顺便说一句,当CDH 6.3.1中同时启动了Hive和Spark服务,Hive的执行引擎就会自动配置为Spark。
在Interpreters页面点击“+Create”新建一个解释器,Interpreter Name输入hive,Interpreter group选择jdbc,必须修改的属性只有default.driver和default.url两项,如图4所示。
 图4
图4
然后是添加依赖包,如图5所示。
 图5
图5
我这里需要添加以下jar包,才能正常执行hive查询:
/opt/cloudera/parcels/CDH-6.3.1-1.cdh6.3.1.p0.1470567/lib/hive/lib/hive-jdbc-2.1.1-cdh6.3.1.jar
/opt/cloudera/parcels/CDH-6.3.1-1.cdh6.3.1.p0.1470567/lib/hadoop/hadoop-common-3.0.0-cdh6.3.1.jar
/opt/cloudera/parcels/CDH-6.3.1-1.cdh6.3.1.p0.1470567/lib/hive/lib/hive-service-2.1.1-cdh6.3.1.jar
/opt/cloudera/parcels/CDH-6.3.1-1.cdh6.3.1.p0.1470567/lib/hive/lib/hive-service-rpc-2.1.1-cdh6.3.1.jar
/opt/cloudera/parcels/CDH-6.3.1-1.cdh6.3.1.p0.1470567/lib/hive/lib/hive-common-2.1.1-cdh6.3.1.jar
/opt/cloudera/parcels/CDH-6.3.1-1.cdh6.3.1.p0.1470567/lib/hive/lib/hive-serde-2.1.1-cdh6.3.1.jar所有修改完成后,点击save保存配置。下面就可以新建note执行hive查询了,如图6所示。
 图6
图6
五、定义MySQL解释器
数据可视化的需求很普遍,如果常用的如MySQL这样的关系数据库也能使用Zeppelin查询,并将结果图形化显示,那么就可以用一套统一的数据可视化方案处理大多数常用查询。Zeppelin本身不带MySQL翻译器,但它支持JDBC解释器组,通常只要有相应的JDBC驱动JAR包,就可以轻松创建一个新的解释器。
在Interpreters页面点击“+Create”新建一个解释器,Interpreter Name输入mysql,Interpreter group选择jdbc,然后配置相关属性。最简单情况下只需要设置default.driver、default.user、default.password、default.url四个属性值,分别表示驱动程序、连接MySQL的用户名、密码和URL,如图7所示。
 图7
图7
然后在依赖关系的artifact中输入MySQL连接器JAR包,格式为“mysql:驱动名称:版本号”,如图8所示。
 图8
图8
点击save保存配置。此时在interpreter页面中会看到mysql解释器。下面创建一个note,使用MySQL作为解释器,查询information_schema.tables表,如图9所示。
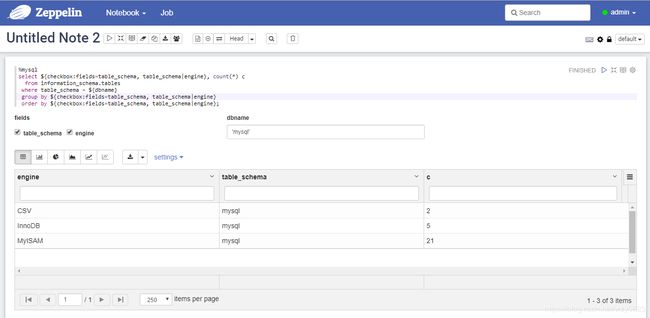 图9
图9
如果解释器出现类似以下错误:
Cannot fetch dependencies for mysql:mysql-connector-java:5.1.38可能是因为Zeppelin的repository中心库无法连接,有两种解决办法。一是在artifact中填写本地jar包路径,如:
/usr/share/java/mysql-connector-java.jar第二个办法是在zeppelin-env.sh文件中设置ZEPPELIN_INTERPRETER_DEP_MVNREPO环境变量,添加一个可访问的repository地址,如:
export ZEPPELIN_INTERPRETER_DEP_MVNREPO=http://insecure.repo1.maven.org/maven2/关于这一问题的说明参见:https://stackoverflow.com/questions/59964426/zepplin-mysql-interpreter-error-cannot-fetch-dependencies-for-mysqlmysql-conne