目标检测:yolov3训练自己的数据模型,避免踩坑(包含常见问题集锦)
第一步:
克隆darknet: git clone https://github.com/pjreddie/darknet.git
第二步:编译
2.1 修改makefile 文件,把GPU,CUDNN,OPENCV等参数设为1,nvcc 设置为自己的路径,保存


2.2 执行编译
make

第三步:制作VOC数据集
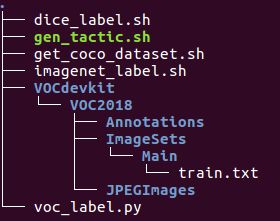
3.1 新建文件夹VOCdevkit,其中其中包含以下文件夹和子文件。Annotations 用来存放xml文件,ImageSet/Main/train.txt 用来保存训练图片的名称,JPEGImages 用来保存训练图片
3.2标注数据
标注工具推荐使用labelImg,下载地址https://github.com/tzutalin/labelImg
标注图像生成的xml文件保存到Annotations文件夹中
3.3提取图像的文件名并保存到文本当中
在ImageSets/Main/train.txt 中保存训练图像的名称,可以使用以下脚本实现。将路径改为自己的即可
# -*- coding: UTF-8 -*-
import os
from os import listdir, getcwd
from os.path import join
if __name__ == '__main__':
source_folder='/home/walter/myNet/head_yolo/darknet/scripts/VOCdevkit/VOC2018/JPEGImages/'
dest='/home/walter/myNet/head_yolo/darknet/scripts/VOCdevkit/VOC2018/ImageSets/Main/train.txt'
#dest2='/home/darknet/scripts/VOCdevkit/VOC2018/ImageSets/Main/val.txt'
file_list=os.listdir(source_folder)
train_file=open(dest,'w')
# val_file=open(dest2,'a')
for file_obj in file_list:
file_path=os.path.join(source_folder,file_obj)
file_name,file_extend=os.path.splitext(file_obj)
#file_num=int(file_name)
train_file.write(file_name+'\n')
#
train_file.close()
#val_file.close()
3.3转换数据格式。将标注后的xml文件写到txt文本当中。可以使用yolov3提供的voc_label.py脚本。在yolo/darknet/scripts目录下
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets=[('2018', 'train')]
classes = ["head"]
def convert(size, box):
dw = 1./(size[0])
dh = 1./(size[1])
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(year, image_id):
in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id))
out_file = open('VOCdevkit/VOC%s/labels/%s.txt'%(year, image_id), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('VOCdevkit/VOC%s/labels/'%(year)):
os.makedirs('VOCdevkit/VOC%s/labels/'%(year))
image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split()
list_file = open('%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg\n'%(wd, year, image_id))
convert_annotation(year, image_id)
list_file.close()
#os.system("cat 2007_train.txt 2007_val.txt 2012_train.txt 2012_val.txt > train.txt")
#os.system("cat 2007_train.txt 2007_val.txt 2007_test.txt 2012_train.txt 2012_val.txt > train.all.txt")
set可以自己设置名称,class也修改为自己训练的类别。运行脚本将会在darknet/script/目录下生成文本2018_train.txt文本,其中保存的是训练图形的路径
同时在darknet/scripts/VOCdevkit/VOC2018目录下会生成labels 文件夹,并生成xml转换后的txt文本

文本格式

3.4 在darknet/data目录下新建head.names

3.5在darknet/cfg 目录下新建head.data,内容如下

classes是检测的类别数,train是使用voc_label.py脚本生成的2018_train.txt,2018_train.txt存储的是所有训练集的路径可以是绝对路径也可以是相对路径,修改为自己的即可,names是要检测的物体的名称文件,backup是用来保存训练以后生成的权重文件
3.6在darknet/cfg目录下复制yolov3.cfg文件,重命名为yolov3-head.cfg,并做以下修改:
[net]
# Testing
#batch=1 #把测试的注释掉
#subdivisions=1 #把测试的注释掉
# Training
batch=64
subdivisions=16
width=416
height=416
channels=3
momentum=0.9
decay=0.0005
angle=0
saturation = 1.5
exposure = 1.5
hue=.1
learning_rate=0.001
burn_in=1000
max_batches = 2000
policy=steps
steps=40000,45000
scales=.1,.1
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
# Downsample
[convolutional]
batch_normalize=1
filters=64
size=3
stride=2
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=1
stride=1
pad=1
activation=leaky
.....
.....
[convolutional]
size=1
stride=1
pad=1
filters=18
activation=linear
[yolo]
mask = 0,1,2
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=1
num=9
jitter=.3
ignore_thresh = .5
truth_thresh = 1
random=1
修改yolo-head.cfg文件 改变如下行,在此文件的最开始的几行
batch = 64
subdivisions=16
batch值太大可能超过GPU的显存造成无法训练,会在训练过程中报显存耗尽的错误,我的GPU显存是16GB ,增大subdivision可以减少显存的使用,合适的调节这两个值训练精度更高的模型,batch越大越容易收敛,batch越小收敛速度变慢,也可能过拟合,但可能精度更高。
修改classes=N 其中N修改为你需要识别的物体的种类总数,注意一共有三个 [yolo]层的class位置需要修改
[yolo]
mask = 6,7,8
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=1
num=9
jitter=.3
ignore_thresh = .7
truth_thresh = 1
random=1
根据公式filters=(classes + 5)x3将每一个[yolo] 层前面的第一个[convolutional]层的 [filters=255] 修改为你的公式结果,一共有三个[convolutional]层位置需要修改
[convolutional]
size=1
stride=1
pad=1
filters=18
activation=linear
3.7下载imagenet上预先训练的权重,保存到darknet目录下
wget https://pjreddie.com/media/files/darknet53.conv.74 第4步:开始训练
./darknet detector train cfg/head.data cfg/yolov3-head.cfg scripts/darknet53.conv.74 -gpus 0,1
#注意文件路径
训练过程如下:

训练历程与部分参数解释:
每迭代100次会存储一个模型,avg loss是一个错误率的指标,越低越好,刚开始会很大,下降也很快,最终降到0.***,每个类一般迭代2000次,所以实训项目需要4000次。使用GTX 950m,大约每100次迭代耗时70分钟。
Region xx: cfg文件中yolo-layer的索引;
Avg IOU:当前迭代中,预测的box与标注的box的平均交并比,越大越好,期望数值为1;
Class: 标注物体的分类准确率,越大越好,期望数值为1;
obj: 越大越好,期望数值为1;
No obj: 越小越好;
.5R: 以IOU=0.5为阈值时候的recall; recall = 检出的正样本/实际的正样本
0.75R: 以IOU=0.75为阈值时候的recall;
count:正样本数目。
训练完成

测试模型
./darknet detector test cfg/df_head.data cfg/yolov3-head.cfg backup/yolov3-head_final.weights data/head_01.jpg
注意:在测试的时候需要把yolo-head.cfg中的test注释去掉,把train注释掉,即设置:
batch=1
subdivisions=1

训练模型时常见问题:
1.make时出现错误,多数是cuda的路径不对,当安装多个cuda版本时,注意自己软链接指向的cuda版本。
2.cuda:out of memory
原因是显存不够
解决方法:1.查看GPU使用状况,是否有中断的网络训练进程没有关闭。2.适当调小batch 3.关闭random=0
3.can't open file:train.txt 或者 can't load image
原因:训练集路径不对,检测script下的trai.txt文件,如果是用window系统编辑的文件会出现换行符号和Linux不兼容问题,请用windows下的notepad打开train.txt,并在设置里显示所有符号。2.检查配置文件cfg下的**.data文件,train路径是否正确
classes= 1
train = /home/walter/myNet/yolo_seris/defect/darknet/scripts/2018_train.txt
names = data/defect.names
backup = backup4.Couldn't open file:/home/**/VOC2018/labels/120.bmp 等其他t图片格式文件
这个问题曾经困扰了楼主两天,如果按照提示把所有图片复制到labels文件夹中,则训练时所有的结果为nan,count=0。最终发现是yolov3的源码中只包含了jpg,JPG,JPEG格式文件,因此当训练图片为bmp,png等格式时会出现label错误!因此我们要么转换图片格式,要么修改源代码。如下图所示。
find_replace(path, "images", "mask", labelpath);
find_replace(labelpath, "JPEGImages", "mask", labelpath);
find_replace(labelpath, ".jpg", ".txt", labelpath);
find_replace(labelpath, ".JPG", ".txt", labelpath);
find_replace(labelpath, ".JPEG", ".txt", labelpath);其中修改源代码的方式是打开src/data.c文件,在所有的find_replace(*****)下面增加你需要的图片格式即可。
5.训练是大部分为nan,count=0
原因是所在的batch里未找到目标,可以适当加大batch,如batch=128。偶尔出现nan并非错误
6. 训练时全部为nan,则数据有问题。
参考问题4,查看labels文件夹下是否有图片,以及JPEGImage中的图片后缀。
7.若要验证数据集,并绘制PR曲线和mAP
请参照faster-rcnn中的绘制代码,拷贝下来即可。