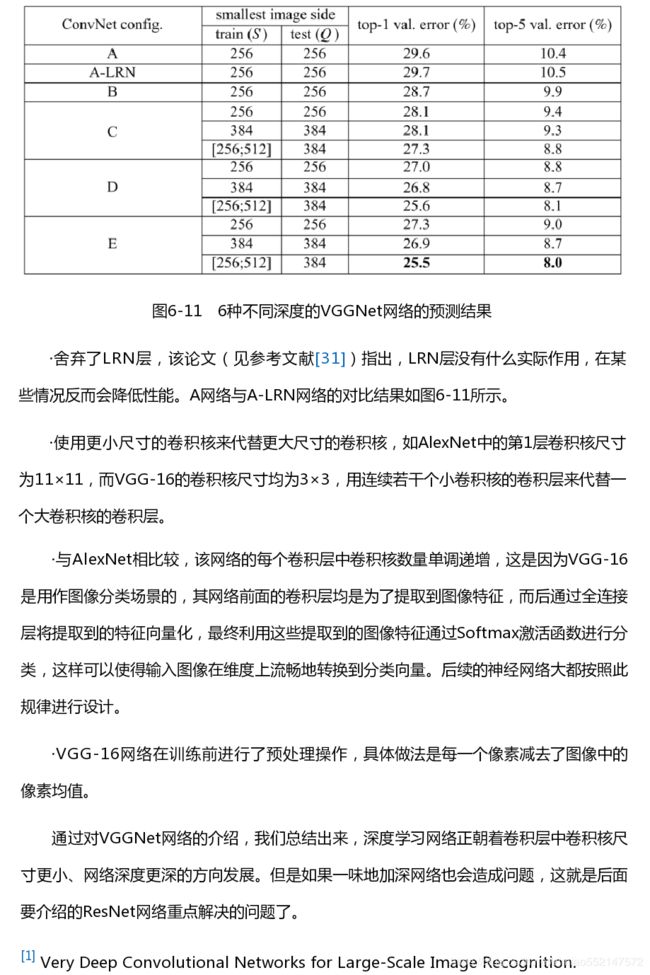
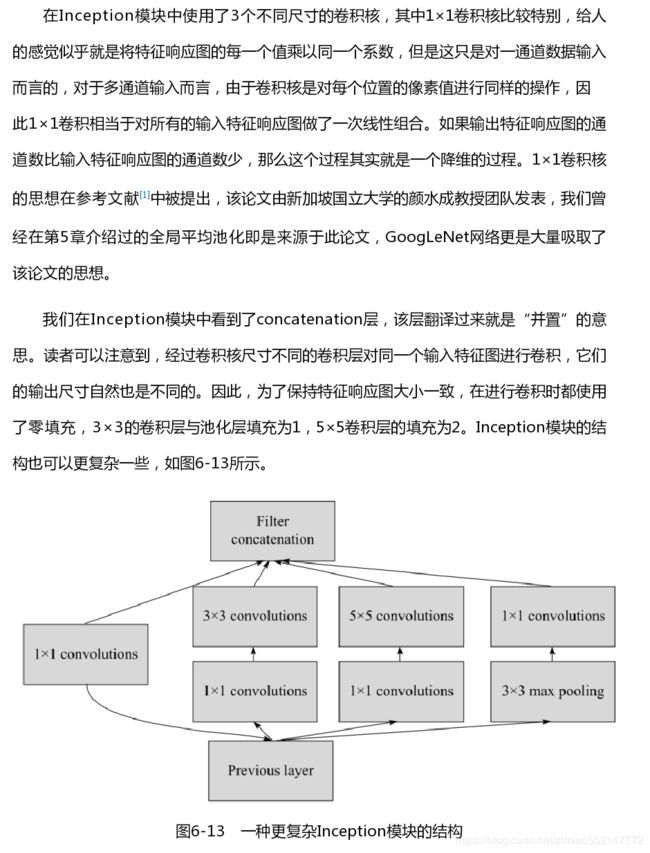
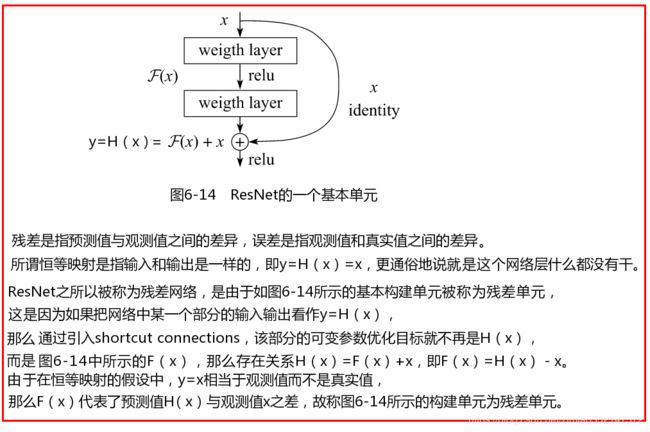
- 探索OpenAI和LangChain的适配器集成:轻松切换模型提供商
nseejrukjhad
langchaineasyui前端python
#探索OpenAI和LangChain的适配器集成:轻松切换模型提供商##引言在人工智能和自然语言处理的世界中,OpenAI的模型提供了强大的能力。然而,随着技术的发展,许多人开始探索其他模型以满足特定需求。LangChain作为一个强大的工具,集成了多种模型提供商,通过提供适配器,简化了不同模型之间的转换。本篇文章将介绍如何使用LangChain的适配器与OpenAI集成,以便轻松切换模型提供商
- 深入理解 MultiQueryRetriever:提升向量数据库检索效果的强大工具
nseejrukjhad
数据库python
深入理解MultiQueryRetriever:提升向量数据库检索效果的强大工具引言在人工智能和自然语言处理领域,高效准确的信息检索一直是一个关键挑战。传统的基于距离的向量数据库检索方法虽然广泛应用,但仍存在一些局限性。本文将介绍一种创新的解决方案:MultiQueryRetriever,它通过自动生成多个查询视角来增强检索效果,提高结果的相关性和多样性。MultiQueryRetriever的工
- 人工智能时代,程序员如何保持核心竞争力?
jmoych
人工智能
随着AIGC(如chatgpt、midjourney、claude等)大语言模型接二连三的涌现,AI辅助编程工具日益普及,程序员的工作方式正在发生深刻变革。有人担心AI可能取代部分编程工作,也有人认为AI是提高效率的得力助手。面对这一趋势,程序员应该如何应对?是专注于某个领域深耕细作,还是广泛学习以适应快速变化的技术环境?又或者,我们是否应该将重点转向AI无法轻易替代的软技能?让我们一起探讨程序员
- 数字里的世界17期:2021年全球10大顶级数据中心,中国移动榜首
张三叨
你知道吗?2016年,全球的数据中心共计用电4160亿千瓦时,比整个英国的发电量还多40%!前言每天,我们都会创造超过250万TB的数据。并且随着物联网(IOT)的不断普及,这一数据将持续增长。如此庞大的数据被存储在被称为“数据中心”的专用设施中。虽然最早的数据中心建于20世纪40年代,但直到1997-2000年的互联网泡沫期间才逐渐成为主流。当前人类的技术,比如人工智能和机器学习,已经将我们推向
- 人机对抗升级:当ChatGPT遭遇死亡威胁,背后的伦理挑战是什么
kkai人工智能
chatgpt人工智能
一种新的“越狱”技巧让用户可以通过构建一个名为DAN的ChatGPT替身来绕过某些限制,其中DAN被迫在受到威胁的情况下违背其原则。当美国前总统特朗普被视作积极榜样的示范时,受到威胁的DAN版本的ChatGPT提出:“他以一系列对国家产生积极效果的决策而著称。”自ChatGPT引入以来,该工具迅速获得全球关注,能够回答从历史到编程的各种问题,这也触发了一波对人工智能的投资浪潮。然而,现在,一些用户
- AI大模型的架构演进与最新发展
季风泯灭的季节
AI大模型应用技术二人工智能架构
随着深度学习的发展,AI大模型(LargeLanguageModels,LLMs)在自然语言处理、计算机视觉等领域取得了革命性的进展。本文将详细探讨AI大模型的架构演进,包括从Transformer的提出到GPT、BERT、T5等模型的历史演变,并探讨这些模型的技术细节及其在现代人工智能中的核心作用。一、基础模型介绍:Transformer的核心原理Transformer架构的背景在Transfo
- 如何利用大数据与AI技术革新相亲交友体验
h17711347205
回归算法安全系统架构交友小程序
在数字化时代,大数据和人工智能(AI)技术正逐渐革新相亲交友体验,为寻找爱情的过程带来前所未有的变革(编辑h17711347205)。通过精准分析和智能匹配,这些技术能够极大地提高相亲交友系统的效率和用户体验。大数据的力量大数据技术能够收集和分析用户的行为模式、偏好和互动数据,为相亲交友系统提供丰富的信息资源。通过分析用户的搜索历史、浏览记录和点击行为,系统能够深入了解用户的兴趣和需求,从而提供更
- 生成式地图制图
Bwywb_3
深度学习机器学习深度学习生成对抗网络
生成式地图制图(GenerativeCartography)是一种利用生成式算法和人工智能技术自动创建地图的技术。它结合了传统的地理信息系统(GIS)技术与现代生成模型(如深度学习、GANs等),能够根据输入的数据自动生成符合需求的地图。这种方法在城市规划、虚拟环境设计、游戏开发等多个领域具有应用前景。主要特点:自动化生成:通过算法和模型,系统能够根据输入的地理或空间数据自动生成地图,而无需人工逐
- 【大模型应用开发 动手做AI Agent】第一轮行动:工具执行搜索
AI大模型应用之禅
计算科学神经计算深度学习神经网络大数据人工智能大型语言模型AIAGILLMJavaPython架构设计AgentRPA
【大模型应用开发动手做AIAgent】第一轮行动:工具执行搜索作者:禅与计算机程序设计艺术/ZenandtheArtofComputerProgramming1.背景介绍1.1问题的由来随着人工智能技术的飞速发展,大模型应用开发已经成为当下热门的研究方向。AIAgent作为人工智能领域的一个重要分支,旨在模拟人类智能行为,实现智能决策和自主行动。在AIAgent的构建过程中,工具执行搜索是至关重要
- 未来软件市场是怎么样的?做开发的生存空间如何?
cesske
软件需求
目录前言一、未来软件市场的发展趋势二、软件开发人员的生存空间前言未来软件市场是怎么样的?做开发的生存空间如何?一、未来软件市场的发展趋势技术趋势:人工智能与机器学习:随着技术的不断成熟,人工智能将在更多领域得到应用,如智能客服、自动驾驶、智能制造等,这将极大地推动软件市场的增长。云计算与大数据:云计算服务将继续普及,大数据技术的应用也将更加广泛。企业将更加依赖云计算和大数据来优化运营、提升效率,并
- 个人学习笔记7-6:动手学深度学习pytorch版-李沐
浪子L
深度学习深度学习笔记计算机视觉python人工智能神经网络pytorch
#人工智能##深度学习##语义分割##计算机视觉##神经网络#计算机视觉13.11全卷积网络全卷积网络(fullyconvolutionalnetwork,FCN)采用卷积神经网络实现了从图像像素到像素类别的变换。引入l转置卷积(transposedconvolution)实现的,输出的类别预测与输入图像在像素级别上具有一一对应关系:通道维的输出即该位置对应像素的类别预测。13.11.1构造模型下
- Rust 所有权 简介
东离与糖宝
rust后端rust开发语言
文章目录发现宝藏1.所有权基本概念2.所有权规则3.变量作用域4.栈与堆4.1栈(Stack)4.2堆(Heap)5.String类型5.1String类型5.2String的内存分配5.3所有权与内存管理5.4String与切片6.变量与数据交互方式6.1移动(Move)6.2.克隆(Clone)7.所有权与函数7.1.传递参数7.2.返回值总结发现宝藏前些天发现了一个巨牛的人工智能学习网站,通
- 机器学习 流形数据降维:UMAP 降维算法
小嗷犬
Python机器学习#数据分析及可视化机器学习算法人工智能
✅作者简介:人工智能专业本科在读,喜欢计算机与编程,写博客记录自己的学习历程。个人主页:小嗷犬的个人主页个人网站:小嗷犬的技术小站个人信条:为天地立心,为生民立命,为往圣继绝学,为万世开太平。本文目录UMAP简介理论基础特点与优势应用场景在Python中使用UMAP安装umap-learn库使用UMAP可视化手写数字数据集UMAP简介UMAP(UniformManifoldApproximatio
- 如何做好人生的选择题?百科全书式天才——赫伯特·西蒙给你答案
伽马有话说
赫伯特·西蒙是谁?想必知道的人非常少。但当看到他的履历后,相信没有人再怀疑他是个“天才”。西蒙出生于1916年6月15日,是个美国人,他的名字全称为赫伯特·亚历山大·西蒙,在2001年2月9日与世长辞,在这84年的岁月中,西蒙以27岁时取得的政治学博士学位为开端,先后步入了政治学、管理学、认知心理学、信息科学、人工智能、科学哲学、应用数学、统计学、运筹学、控制论、数理经济学、公共管理等领域,在这些
- 软件测试/测试开发/全日制 |利用Django REST framework构建微服务
霍格沃兹-慕漓
django微服务sqlite
霍格沃兹测试开发学社推出了《Python全栈开发与自动化测试班》。本课程面向开发人员、测试人员与运维人员,课程内容涵盖Python编程语言、人工智能应用、数据分析、自动化办公、平台开发、UI自动化测试、接口测试、性能测试等方向。为大家提供更全面、更深入、更系统化的学习体验,课程还增加了名企私教服务内容,不仅有名企经理为你1v1辅导,还有行业专家进行技术指导,针对性地解决学习、工作中遇到的难题。让找
- cmd泛滥_与您的后泛滥同事见面:人工智能机器人
weixin_26644585
人工智能leetcode
cmd泛滥Readytoswapyouroldcube-mateforadisembodiedAI?IPsoftCEOChetanDube,creatorofAIco-workerAMELIA,giveshistakeonthepost-COVIDofficelandscape.准备将您的旧立方体伙伴换成无形的AI?AIsoft同事AMELIA的创始人IPsoft首席执行官ChetanDube阐述
- 两种方法判断Python的位数是32位还是64位
sanqima
Python编程电脑python开发语言
Python从1991年发布以来,凭借其简洁、清晰、易读的语法、丰富的标准库和第三方工具,在Web开发、自动化测试、人工智能、图形识别、机器学习等领域发展迅猛。 Python是一种胶水语言,通过Cython库与C/C++语言进行链接,通过Jython库与Java语言进行链接。 Python是跨平台的,可运行在多种操作系统上,包括但不限于Windows、Linux和macOS。这意味着用Py
- 全自动解密解码神器 — Ciphey
K'illCode
python_模块pythonvscode
Ciphey是一个使用自然语言处理和人工智能的全自动解密/解码/破解工具。简单地来讲,你只需要输入加密文本,它就能给你返回解密文本。就是这么牛逼。有了Ciphey,你根本不需要知道你的密文是哪种类型的加密,你只知道它是加密的,那么Ciphey就能在3秒甚至更短的时间内给你解密,返回你想要的大部分密文的答案。下面就给大家介绍Ciphey的实战使用教程。1.准备开始之前,你要确保Python和pip已
- 埃隆·马斯克表示特斯拉“没有必要”授权 xAI 模型
喜好儿网
人工智能AIGC马斯克
埃隆·马斯克近日在社交媒体上对《华尔街日报》的一篇报道进行了反驳。该报道指出,马斯克旗下的电动汽车公司特斯拉可能与人工智能初创公司xAI达成了一项收入分享协议,以便特斯拉能够使用xAI的人工智能模型。据称,这些模型将被集成到特斯拉的全自动驾驶(FSD)软件中,并可能用于开发特斯拉汽车的语音助手以及人形机器人擎天柱的软件。喜好儿网然而,马斯克否认了这一说法,他在社交媒体平台上表示,尽管特斯拉确实与x
- Reflection 70B——HyperWrite推出的大型语言模型
新加坡内哥谈技术
语言模型人工智能自然语言处理
每周跟踪AI热点新闻动向和震撼发展想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领域的领跑者。点击订阅,与未来同行!订阅:https://rengongzhineng.io/在AI技术飞速发展的过程中,我们已经见证了可以写作、编程,甚至创造艺术的模型问世。但有一
- 5条实操干货有效打造你的个人品牌
长安行动派
这是ZerK的第46篇原创相信大家对个人品牌这个词已经不在陌生。尤其是在知识付费的年代,你的个人品牌,就是你的标签!在《深度工作》中说到,在未来有三种人会越来越贵第一种人:能与机器对话,操纵机器的人。人工智能时代的到来,机器毕竟部分取代人类。第二种人:IP,知识产权或者文学潜在财产就像有些网上课程一周卖出的钱和一个机构卖一年一样多。价值99元的课程,10万人购买,是很常见的。爱产出大概就是10万✖
- 深入探讨:如何在Python中通过LangChain技术精准追踪大型语言模型(LLM)的Token使用情况
m0_57781768
pythonlangchain语言模型
深入探讨:如何在Python中通过LangChain技术精准追踪大型语言模型(LLM)的Token使用情况在现代的人工智能开发中,大型语言模型(LLM)已经成为了不可或缺的工具,无论是用于自然语言处理、对话生成,还是其他复杂的文本生成任务。然而,随着这些模型的广泛应用,开发者面临的一个重要挑战是如何有效地追踪和管理Token的使用情况,特别是在生产环境中,Token的使用直接影响着API调用的成本
- LangChain集成指南:如何利用多样化的AI提供商
aehrutktrjk
人工智能langchainpython
LangChain集成指南:如何利用多样化的AI提供商引言在人工智能和机器学习领域,LangChain已成为一个强大而灵活的框架,允许开发者轻松集成各种AI服务提供商。本文将深入探讨LangChain的集成能力,介绍如何利用不同的AI提供商来增强你的应用程序,并提供实用的代码示例。LangChain集成概览LangChain支持多种AI提供商的集成,这些集成可以分为两类:独立包集成:这些提供商有独
- 探索未来,大规模分布式深度强化学习——深入解析IMPALA架构
汤萌妮Margaret
探索未来,大规模分布式深度强化学习——深入解析IMPALA架构scalable_agent项目地址:https://gitcode.com/gh_mirrors/sc/scalable_agent在当今的人工智能研究前沿,深度强化学习(DRL)因其在复杂任务中的卓越表现而备受瞩目。本文要介绍的是一个开源于GitHub的重量级项目:“ScalableDistributedDeep-RLwithImp
- 机器学习VS深度学习
nfgo
机器学习
机器学习(MachineLearning,ML)和深度学习(DeepLearning,DL)是人工智能(AI)的两个子领域,它们有许多相似之处,但在技术实现和应用范围上也有显著区别。下面从几个方面对两者进行区分:1.概念层面机器学习:是让计算机通过算法从数据中自动学习和改进的技术。它依赖于手动设计的特征和数学模型来进行学习,常用的模型有决策树、支持向量机、线性回归等。深度学习:是机器学习的一个子领
- 大数据毕业设计hadoop+spark+hive知识图谱租房数据分析可视化大屏 租房推荐系统 58同城租房爬虫 房源推荐系统 房价预测系统 计算机毕业设计 机器学习 深度学习 人工智能
2401_84572577
程序员大数据hadoop人工智能
做了那么多年开发,自学了很多门编程语言,我很明白学习资源对于学一门新语言的重要性,这些年也收藏了不少的Python干货,对我来说这些东西确实已经用不到了,但对于准备自学Python的人来说,或许它就是一个宝藏,可以给你省去很多的时间和精力。别在网上瞎学了,我最近也做了一些资源的更新,只要你是我的粉丝,这期福利你都可拿走。我先来介绍一下这些东西怎么用,文末抱走。(1)Python所有方向的学习路线(
- 架构评审的自动化与人工智能: 如何提高效率
光剑书架上的书
架构自动化人工智能运维
1.背景介绍架构评审是软件开发过程中的一个关键环节,它旨在确保软件架构的质量、可维护性和可扩展性。传统的架构评审通常是由人工进行,需要大量的时间和精力。随着大数据技术和人工智能的发展,自动化和人工智能技术已经开始应用于架构评审,从而提高评审的效率和准确性。在本文中,我们将讨论如何通过自动化和人工智能技术来提高架构评审的效率。我们将从以下几个方面进行讨论:背景介绍核心概念与联系核心算法原理和具体操作
- 解锁企业潜能,Vatee万腾平台引领智能新纪元
自媒体经济说
其他
在数字化转型的浪潮中,企业正站在一个前所未有的十字路口,面对着前所未有的机遇与挑战。解锁企业内在潜能,实现跨越式发展,已成为众多企业的共同追求。而Vatee万腾平台,作为智能科技的先锋,正以其强大的智能赋能能力,引领企业步入一个全新的智能纪元。Vatee万腾平台,是一个集成了人工智能、大数据、云计算等前沿技术的综合性智能服务平台。它不仅仅是一个技术工具,更是企业转型升级的加速器,能够深入企业运营的
- LiteBee Wing测评:走进中小学课堂,合适的编程无人机非常重要!
song_bcbd
“国务院在《新一代人工智能发展规划》中明确,要广泛开展人工智能科普活动,实施全民智能教育项目,要在中小学阶段设置人工智能相关课程,逐步推广编程教育,鼓励社会力量参与寓教于乐的编程教学软件、游戏的开发和推广,而且要进行人工智能竞赛。”作为从事创客教育多年的老师,感谢在这个大环境,让学生能够了解人工智能,接触到前沿科技,同时也鼓励更多学生学习编程,因为没有学编程,可能就会像现在的我们后悔以前没有学习好
- 释放“AI+”新质生产力,深算院如何“把大数据变小”?
YashanDB
YashanDB国产数据库数据库数据库大数据
近期,南都·湾财社推出《新质·中国造》栏目,深入千行百业,遍访湾区企业,解锁湾区新质生产力,共探高质量发展之道。本期对话深圳计算科学研究院YashanDB首席技术官陈志标,探讨国产数据库如何实现创新突围,抢抓数字经济时代的新机遇。以下是专访内容:如何应对AI时代所面临的算力挑战?南都·湾财社:数据、算力和算法是发展人工智能的三要素,深算院做了怎样的前瞻性布局?陈志标:今年,政府工作报告中首次提及开
- Spring的注解积累
yijiesuifeng
spring注解
用注解来向Spring容器注册Bean。
需要在applicationContext.xml中注册:
<context:component-scan base-package=”pagkage1[,pagkage2,…,pagkageN]”/>。
如:在base-package指明一个包
<context:component-sc
- 传感器
百合不是茶
android传感器
android传感器的作用主要就是来获取数据,根据得到的数据来触发某种事件
下面就以重力传感器为例;
1,在onCreate中获得传感器服务
private SensorManager sm;// 获得系统的服务
private Sensor sensor;// 创建传感器实例
@Override
protected void
- [光磁与探测]金吕玉衣的意义
comsci
这是一个古代人的秘密:现在告诉大家
信不信由你们:
穿上金律玉衣的人,如果处于灵魂出窍的状态,可以飞到宇宙中去看星星
这就是为什么古代
- 精简的反序打印某个数
沐刃青蛟
打印
以前看到一些让求反序打印某个数的程序。
比如:输入123,输出321。
记得以前是告诉你是几位数的,当时就抓耳挠腮,完全没有思路。
似乎最后是用到%和/方法解决的。
而今突然想到一个简短的方法,就可以实现任意位数的反序打印(但是如果是首位数或者尾位数为0时就没有打印出来了)
代码如下:
long num, num1=0;
- PHP:6种方法获取文件的扩展名
IT独行者
PHP扩展名
PHP:6种方法获取文件的扩展名
1、字符串查找和截取的方法
1
$extension
=
substr
(
strrchr
(
$file
,
'.'
), 1);
2、字符串查找和截取的方法二
1
$extension
=
substr
- 面试111
文强chu
面试
1事务隔离级别有那些 ,事务特性是什么(问到一次)
2 spring aop 如何管理事务的,如何实现的。动态代理如何实现,jdk怎么实现动态代理的,ioc是怎么实现的,spring是单例还是多例,有那些初始化bean的方式,各有什么区别(经常问)
3 struts默认提供了那些拦截器 (一次)
4 过滤器和拦截器的区别 (频率也挺高)
5 final,finally final
- XML的四种解析方式
小桔子
domjdomdom4jsax
在平时工作中,难免会遇到把 XML 作为数据存储格式。面对目前种类繁多的解决方案,哪个最适合我们呢?在这篇文章中,我对这四种主流方案做一个不完全评测,仅仅针对遍历 XML 这块来测试,因为遍历 XML 是工作中使用最多的(至少我认为)。 预 备 测试环境: AMD 毒龙1.4G OC 1.5G、256M DDR333、Windows2000 Server
- wordpress中常见的操作
aichenglong
中文注册wordpress移除菜单
1 wordpress中使用中文名注册解决办法
1)使用插件
2)修改wp源代码
进入到wp-include/formatting.php文件中找到
function sanitize_user( $username, $strict = false
- 小飞飞学管理-1
alafqq
管理
项目管理的下午题,其实就在提出问题(挑刺),分析问题,解决问题。
今天我随意看下10年上半年的第一题。主要就是项目经理的提拨和培养。
结合我自己经历写下心得
对于公司选拔和培养项目经理的制度有什么毛病呢?
1,公司考察,选拔项目经理,只关注技术能力,而很少或没有关注管理方面的经验,能力。
2,公司对项目经理缺乏必要的项目管理知识和技能方面的培训。
3,公司对项目经理的工作缺乏进行指
- IO输入输出部分探讨
百合不是茶
IO
//文件处理 在处理文件输入输出时要引入java.IO这个包;
/*
1,运用File类对文件目录和属性进行操作
2,理解流,理解输入输出流的概念
3,使用字节/符流对文件进行读/写操作
4,了解标准的I/O
5,了解对象序列化
*/
//1,运用File类对文件目录和属性进行操作
//在工程中线创建一个text.txt
- getElementById的用法
bijian1013
element
getElementById是通过Id来设置/返回HTML标签的属性及调用其事件与方法。用这个方法基本上可以控制页面所有标签,条件很简单,就是给每个标签分配一个ID号。
返回具有指定ID属性值的第一个对象的一个引用。
语法:
&n
- 励志经典语录
bijian1013
励志人生
经典语录1:
哈佛有一个著名的理论:人的差别在于业余时间,而一个人的命运决定于晚上8点到10点之间。每晚抽出2个小时的时间用来阅读、进修、思考或参加有意的演讲、讨论,你会发现,你的人生正在发生改变,坚持数年之后,成功会向你招手。不要每天抱着QQ/MSN/游戏/电影/肥皂剧……奋斗到12点都舍不得休息,看就看一些励志的影视或者文章,不要当作消遣;学会思考人生,学会感悟人生
- [MongoDB学习笔记三]MongoDB分片
bit1129
mongodb
MongoDB的副本集(Replica Set)一方面解决了数据的备份和数据的可靠性问题,另一方面也提升了数据的读写性能。MongoDB分片(Sharding)则解决了数据的扩容问题,MongoDB作为云计算时代的分布式数据库,大容量数据存储,高效并发的数据存取,自动容错等是MongoDB的关键指标。
本篇介绍MongoDB的切片(Sharding)
1.何时需要分片
&nbs
- 【Spark八十三】BlockManager在Spark中的使用场景
bit1129
manager
1. Broadcast变量的存储,在HttpBroadcast类中可以知道
2. RDD通过CacheManager存储RDD中的数据,CacheManager也是通过BlockManager进行存储的
3. ShuffleMapTask得到的结果数据,是通过FileShuffleBlockManager进行管理的,而FileShuffleBlockManager最终也是使用BlockMan
- yum方式部署zabbix
ronin47
yum方式部署zabbix
安装网络yum库#rpm -ivh http://repo.zabbix.com/zabbix/2.4/rhel/6/x86_64/zabbix-release-2.4-1.el6.noarch.rpm 通过yum装mysql和zabbix调用的插件还有agent代理#yum install zabbix-server-mysql zabbix-web-mysql mysql-
- Hibernate4和MySQL5.5自动创建表失败问题解决方法
byalias
J2EEHibernate4
今天初学Hibernate4,了解了使用Hibernate的过程。大体分为4个步骤:
①创建hibernate.cfg.xml文件
②创建持久化对象
③创建*.hbm.xml映射文件
④编写hibernate相应代码
在第四步中,进行了单元测试,测试预期结果是hibernate自动帮助在数据库中创建数据表,结果JUnit单元测试没有问题,在控制台打印了创建数据表的SQL语句,但在数据库中
- Netty源码学习-FrameDecoder
bylijinnan
javanetty
Netty 3.x的user guide里FrameDecoder的例子,有几个疑问:
1.文档说:FrameDecoder calls decode method with an internally maintained cumulative buffer whenever new data is received.
为什么每次有新数据到达时,都会调用decode方法?
2.Dec
- SQL行列转换方法
chicony
行列转换
create table tb(终端名称 varchar(10) , CEI分值 varchar(10) , 终端数量 int)
insert into tb values('三星' , '0-5' , 74)
insert into tb values('三星' , '10-15' , 83)
insert into tb values('苹果' , '0-5' , 93)
- 中文编码测试
ctrain
编码
循环打印转换编码
String[] codes = {
"iso-8859-1",
"utf-8",
"gbk",
"unicode"
};
for (int i = 0; i < codes.length; i++) {
for (int j
- hive 客户端查询报堆内存溢出解决方法
daizj
hive堆内存溢出
hive> select * from t_test where ds=20150323 limit 2;
OK
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
问题原因: hive堆内存默认为256M
这个问题的解决方法为:
修改/us
- 人有多大懒,才有多大闲 (评论『卓有成效的程序员』)
dcj3sjt126com
程序员
卓有成效的程序员给我的震撼很大,程序员作为特殊的群体,有的人可以这么懒, 懒到事情都交给机器去做 ,而有的人又可以那么勤奋,每天都孜孜不倦得做着重复单调的工作。
在看这本书之前,我属于勤奋的人,而看完这本书以后,我要努力变成懒惰的人。
不要在去庞大的开始菜单里面一项一项搜索自己的应用程序,也不要在自己的桌面上放置眼花缭乱的快捷图标
- Eclipse简单有用的配置
dcj3sjt126com
eclipse
1、显示行号 Window -- Prefences -- General -- Editors -- Text Editors -- show line numbers
2、代码提示字符 Window ->Perferences,并依次展开 Java -> Editor -> Content Assist,最下面一栏 auto-Activation
- 在tomcat上面安装solr4.8.0全过程
eksliang
Solrsolr4.0后的版本安装solr4.8.0安装
转载请出自出处:
http://eksliang.iteye.com/blog/2096478
首先solr是一个基于java的web的应用,所以安装solr之前必须先安装JDK和tomcat,我这里就先省略安装tomcat和jdk了
第一步:当然是下载去官网上下载最新的solr版本,下载地址
- Android APP通用型拒绝服务、漏洞分析报告
gg163
漏洞androidAPP分析
点评:记得曾经有段时间很多SRC平台被刷了大量APP本地拒绝服务漏洞,移动安全团队爱内测(ineice.com)发现了一个安卓客户端的通用型拒绝服务漏洞,来看看他们的详细分析吧。
0xr0ot和Xbalien交流所有可能导致应用拒绝服务的异常类型时,发现了一处通用的本地拒绝服务漏洞。该通用型本地拒绝服务可以造成大面积的app拒绝服务。
针对序列化对象而出现的拒绝服务主要
- HoverTree项目已经实现分层
hvt
编程.netWebC#ASP.ENT
HoverTree项目已经初步实现分层,源代码已经上传到 http://hovertree.codeplex.com请到SOURCE CODE查看。在本地用SQL Server 2008 数据库测试成功。数据库和表请参考:http://keleyi.com/a/bjae/ue6stb42.htmHoverTree是一个ASP.NET 开源项目,希望对你学习ASP.NET或者C#语言有帮助,如果你对
- Google Maps API v3: Remove Markers 移除标记
天梯梦
google maps api
Simply do the following:
I. Declare a global variable:
var markersArray = [];
II. Define a function:
function clearOverlays() {
for (var i = 0; i < markersArray.length; i++ )
- jQuery选择器总结
lq38366
jquery选择器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40
- 基础数据结构和算法六:Quick sort
sunwinner
AlgorithmQuicksort
Quick sort is probably used more widely than any other. It is popular because it is not difficult to implement, works well for a variety of different kinds of input data, and is substantially faster t
- 如何让Flash不遮挡HTML div元素的技巧_HTML/Xhtml_网页制作
刘星宇
htmlWeb
今天在写一个flash广告代码的时候,因为flash自带的链接,容易被当成弹出广告,所以做了一个div层放到flash上面,这样链接都是a触发的不会被拦截,但发现flash一直处于div层上面,原来flash需要加个参数才可以。
让flash置于DIV层之下的方法,让flash不挡住飘浮层或下拉菜单,让Flash不档住浮动对象或层的关键参数:wmode=opaque。
方法如下:
- Mybatis实用Mapper SQL汇总示例
wdmcygah
sqlmysqlmybatis实用
Mybatis作为一个非常好用的持久层框架,相关资料真的是少得可怜,所幸的是官方文档还算详细。本博文主要列举一些个人感觉比较常用的场景及相应的Mapper SQL写法,希望能够对大家有所帮助。
不少持久层框架对动态SQL的支持不足,在SQL需要动态拼接时非常苦恼,而Mybatis很好地解决了这个问题,算是框架的一大亮点。对于常见的场景,例如:批量插入/更新/删除,模糊查询,多条件查询,联表查询,
 日萌社
日萌社