函数记录
numpy.eye(N, M=None, k=0, dtype=
Return a 2-D array with ones on the diagonal and zeros elsewhere.
返回一个对角线上为1,其他地方为0的二维数组。
参数
N int Number of rows in the output.
M int, optiona Number of columns in the output. If None, defaults to N.
kint, optional Index of the diagonal: 0 (the default) refers to the main diagonal, a positive value refers to an upper diagonal, and a negative value to a lower diagonal.
dtypedata-type, optional Data-type of the returned array.
order{‘C’, ‘F’}, optional Whether the output should be stored in row-major (C-style) or column-major (Fortran-style) order in memory.
Returns
Indarray of shape (N,M)
An array where all elements are equal to zero, except for the k-th diagonal, whose values are equal to one.
可以理解为标签的one-hot编码输出
# 根据所有已分词好的文本建立好一个词典,然后找出每个词在词典中对应的索引,不足长度或者不存在的词补0 vocab_processor = learn.preprocessing.VocabularyProcessor(max_document_length) x = np.array(list(vocab_processor.fit_transform(x_text)))
https://blog.csdn.net/The_lastest/article/details/81771723
np.random.permutation 随机序列排序
tf.nn.embedding_lookup(params, ids, partition_strategy='mod', max_norm=None)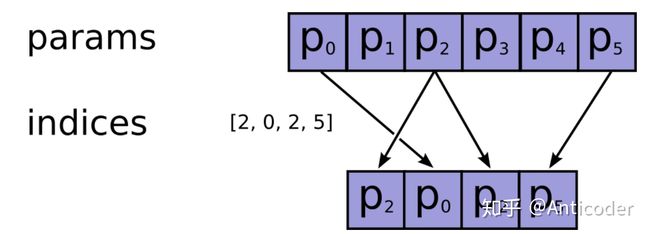
https://www.zhihu.com/question/52250059
tf.truncated_normal
truncated_normal(
shape,
mean=0.0,
stddev=1.0,
dtype=tf.float32,
seed=None,
name=None
)
功能说明:
产生截断正态分布随机数,取值范围为 [ mean - 2 * stddev, mean + 2 * stddev ]。
tf.nn.conv2d (input, filter, strides, padding, use_cudnn_on_gpu=None, data_format=None, name=None)
参数:
input : 输入的要做卷积的图片,要求为一个张量,shape为 [ batch, in_height, in_weight, in_channel ],其中batch为图片的数量,in_height 为图片高度,in_weight 为图片宽度,in_channel 为图片的通道数,灰度图该值为1,彩色图为3。(也可以用其它值,但是具体含义不是很理解)
filter: 卷积核,要求也是一个张量,shape为 [ filter_height, filter_weight, in_channel, out_channels ],其中 filter_height 为卷积核高度,filter_weight 为卷积核宽度,in_channel 是图像通道数 ,和 input 的 in_channel 要保持一致,out_channel 是卷积核数量。
strides: 卷积时在图像每一维的步长,这是一个一维的向量,[ 1, strides, strides, 1],第一位和最后一位固定必须是1
padding: string类型,值为“SAME” 和 “VALID”,表示的是卷积的形式,是否考虑边界。"SAME"是考虑边界,不足的时候用0去填充周围,"VALID"则不考虑
use_cudnn_on_gpu: bool类型,是否使用cudnn加速,默认为true
global_step = tf.Variable(0, trainable=False)
lr = tf.train.exponential_decay(learning_rate=0.02,
global_step=global_step,
decay_steps=100,
decay_rate=0.9,
staircase=False)
learning_rate为原始学习率
global_step个人感觉好比一个计数器,你没进行一次更新它就会增一
decay_steps为衰减间隔,顾名思义就是每隔多少步会更新一次学习率(它只有在staircase为true时才有效)
decay_rate衰减率
staircase若为true则每隔decay_steps步对学习率进行一次更新,若为false则每一步都更新
tf.train.AdamOptimizer.__init__( learning_rate=0.001, beta1=0.9, beta2=0.999, epsilon=1e-08, use_locking=False, name='Adam' )
learning_rate: A Tensor or a floating point value. (学习率)
beta1: A float value or a constant float tensor. (一阶矩估计的指数衰减率)
beta2: A float value or a constant float tensor. (二阶矩估计的指数衰减率)
epsilon: A small constant for numerical stability. (一个非常小的数,防止除以零)
use_locking: 如果为真,则使用锁进行更新操作。
name: 使用梯度时创建的操作的可选名称,默认为 "Adam"。
tf.GraphKeys.UPDATE_OPS
关于tf.GraphKeys.UPDATE_OPS,这是一个tensorflow的计算图中内置的一个集合,其中会保存一些需要在训练操作之前完成的操作,并配合tf.control_dependencies函数使用。
关于在batch_norm中,即为更新mean和variance的操作。通过下面一个例子可以看到tf.layers.batch_normalization中是如何实现的。
compute_gradients()的源码如下:
compute_gradients(self, loss, var_list=None,
gate_gradients=GATE_OP,
aggregation_method=None,
colocate_gradients_with_ops=False,
grad_loss=None):
里面参数的定义与minimizer()函数里面的一致,var_list的默认值也一样。需要特殊说明的是,如果var_list里所包含的变量多于var(loss),则程序会报错。其返回值是(gradient, variable)对所组成的列表,返回的数据格式也都是“tf.Tensor”。我们可以通过变量名称的管理来过滤出里面的部分变量,以及对应的梯度。
apply_gradients()的源码如下:
apply_gradients(self, grads_and_vars, global_step=None, name=None)
grads_and_vars的格式就是compute_gradients()所返回的(gradient, variable)对,当然数据类型也是“tf.Tensor”,作用是,更新grads_and_vars中variable的梯度,不在里面的变量的梯度不变。
gensim.models.Word2Vec()