Lifelong Learning
Lifelong Learning

https://www.forbes.com/sites/kpmg/2018/04/23/the-changing-nature-of-work-why-lifelong-learning-matters-more-than-ever/#4e04e90e1e95
终身学习(Lifelong Learning或Continuous Learning、 Never Ending Learning、Incremental Learning等)的概念对于人来说是很容易理解的,也就是俗话所说的“活到老,学到老”。既然神经网络是从人类脑科学中受启发而来的,那么能否也要求神经网络模型具备终身学习的能力呢?
简单来说,之前我们对于每一个领域的具体问题都会训练一个网络模型,虽然有迁移学习,但是还是要为不同的任务训练很多的模型,能否我们只使用一个模型来不断的学习不同的任务,从而达到可以求解多种问题的能力?这就是在机器学习领域大家想要解决的关于终身学习的问题。

对于终身学习来说,我们需要解决的主要有三个方面的问题:
- 知识保留(Knowledge Retention):如果只使用一个模型来不断的学习不同的任务,自然希望它在学习新的任务的时候,也不要忘记已经学习到的东西。同时也要避免为了单纯的保留之前已经学习到的东西而停止学习,这对于现有的神经网络就是第一个很大的挑战;
- 知识迁移(Knowledge Transfer):我们希望我们的模型可以使用已经学习到的东西来帮助解决新的问题,达到触类旁通的效果。虽然看起来像是迁移学习,但是还是有一定的不同之处;
- 模型扩展(Model Expansion):如果模型比较简单,也许处理简单问题时还可以,但是在处理复杂问题时,一般都是显得力不从心。故我们希望模型可以自己根据问题的复杂度进行扩展,变为更加复杂的模型。而目前使用神经网络时,用户都是根据自己的任务预定义好了模型的结构,因此解决这个问题十分的困难。
Knowledge Retention
下面我们通过一些简单的例子看一下上述的问题如何理解。假设我们现在需要解决手写数字识别的两个任务,第一个任务的样本加入了某些随机噪声,而第二个任务的样本不做处理,如下所示

我们希望借助终身学习的理念,使用一个模型就可以在两个任务上取得理想的效果,具体来说就是希望模型可以准确的将上面的两个样本都判别为 0 0 0。
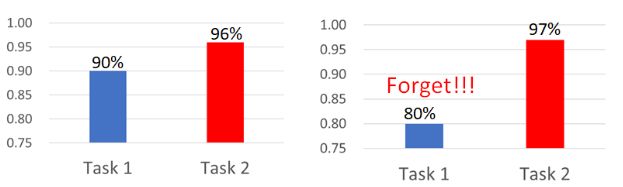
但是经过实验证明,真实情况和预想具有一定的差距。如上所示,当我们在Task 1的训练集上训练完模型后,可以取得90%的准确率,而且将其直接应用到Task 2上可以有96%的准确率。但是当我们继续使用Task 2的训练集训练模型后,Task 2上的准确率改变不大,但是Task 1上的准确率反而大幅的下降了,这显然不是我们想看到的事情。
那么解决上述问题的一个简单的办法就是将Task 1和Task 2的样本混在一起来训练一个模型,希望它可以在两个任务上都表现良好,结果也正是这样

在《TOWARDS AI-COMPLETE QUESTION ANSWERING: A SET OF PREREQUISITE TOY TASKS》这篇文章中,解决的是一个问答系统的问题,网络模型如下所示

https://arxiv.org/pdf/1502.05698.pdf
所谓问答系统,就是丢给模型一篇文档,希望模型在学习后可以根据文档的内容回答一些问题。文中实验所使用的是BAbi这个数据集,它包含20个简单的问答任务,作者在这20个任务上训练一个上述的模型。

实验结果如上所示,当模型训练到Task 5时,发现它只在Task 5上表现极好,在其他的任务上基本没什么用;当训练到Task 10时,同样的在Task 10上表现很好,同时可能是Task 10和Task 18、Task 19具有一定的相似性,也可以取得一定的效果,但是在除此之外的Task上没啥用;训练到Task 15时也会出现同样的问题。这样的模型在没学习过的任务上表现很差可以理解,但是它在已经学习过的任务上同样没什么效果,表示它遗忘了已习得的东西。按照之前的解决方法,如果我们同时在20个任务上训练时,得到的模型在各个任务上的效果也还可以接受

因此,如果要想让模型不忘记习得的东西,可以将训练过的数据就保留下来。但是这样的办法只在简单的任务上可以使用,当我们的任务十分复杂,使用的数据集极其庞大时,存储这样规模的数据需要大量的资源,而且使用大规模的数据训练模型也需要大量的计算资源,故这样的办法实际上不太实用。

另一种解决方案是Elastic Weight Consolidation (EWC) ,它的基本思想是认为不同的参数在后面的学习和记住已经习得的东西两个方面所起到的作用的大小不同,在每一次在新的任务上学习时,我们希望改变的只是那些不太重要的参数。假设 θ b \theta^b θb表示已经在多个任务上学习结束的模型,其中每个参数 θ i b \theta_{i}^b θib都有一个守卫(guard) b i b_{i} bi,表征参数的重要程度。因此模型的损失函数如下所示

当 b i = 0 b_{i}=0 bi=0时,表示对于 θ i \theta_{i} θi不加约束,它的改变对于模型的效果没什么影响;
当 b i = ∞ b_{i}=\infty bi=∞时,表示新模型的参数 θ i \theta_{i} θi应该等于原先模型的参数 θ i b \theta_{i}^b θib。
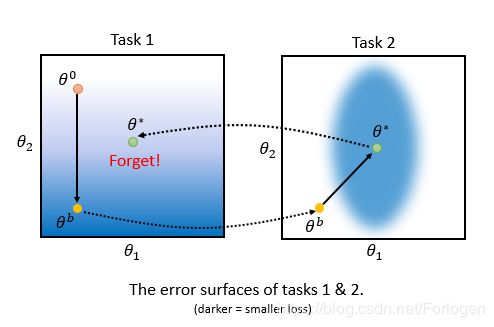
下面我们形象化的来看一下EWC的原理是什么,假设使用的模型十分简单,它只有两个参数 θ 1 \theta_{1} θ1和 θ 2 \theta_{2} θ2,它们的error surface如下所示。对于Task 1来说 θ 0 \theta^0 θ0到 θ b \theta^b θb的方向是损失函数值下降最快的方向,在 θ b \theta^b θb位置处Task 1可以取得较小的损失值。然后将模型用到Task 2时, θ b \theta^b θb位置处关于Task 2的损失函数值却很大,梯度下降的方向是 θ b \theta^b θb指向 θ ∗ \theta^* θ∗的方向。如果在返回到Task 1时发现, θ ∗ \theta^* θ∗处Task 1的损失函数值很大,表示模型忘记了在Task 1上学到的东西。
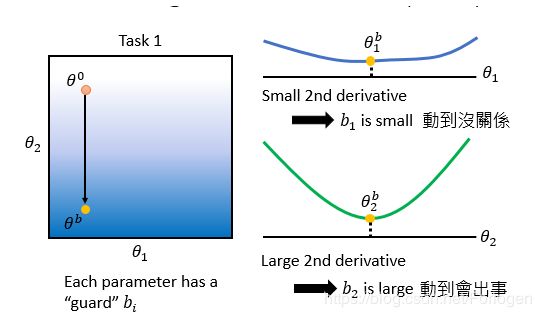
EWC做的是什么呢?当它观察到 θ 1 b \theta_{1}^b θ1b处的梯度很小时,就告诉模型改变它也没事;当 θ 2 b \theta_{2}^b θ2b处的梯度很大时,它就告诉模型不要改变这个参数,否则会很大的影响模型的效果。
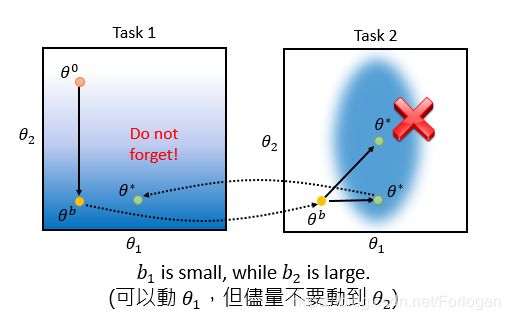
即在解决新的任务时,不要改变关于两个任务的损失函数值都小的参数。
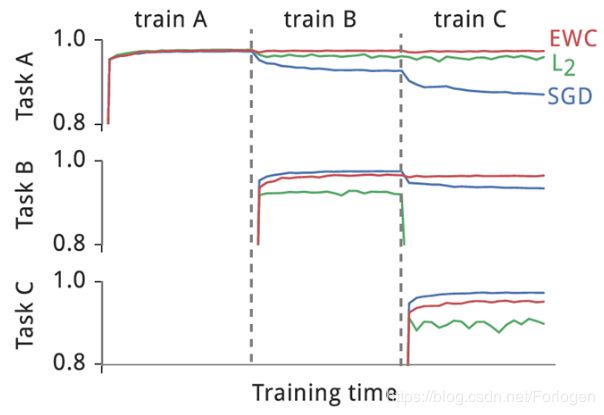
文中的实验结果如下所示,它和 L 2 L_{2} L2正则化、SGD进行比较,发现它可以在一定程度上解决模型灾难性遗忘的问题。而且 L 2 L_{2} L2和SGD的限制较为严格,在某些情况下,它为了不忘记学习到的东西会停止学习。
其他的参考资料:
Elastic Weight Consolidation (EWC) http://www.citeulike.org/group/15400/article/14311063
Synaptic Intelligence (SI) https://arxiv.org/abs/1703.04200
Memory Aware Synapses (MAS) https://arxiv.org/abs/1711.09601
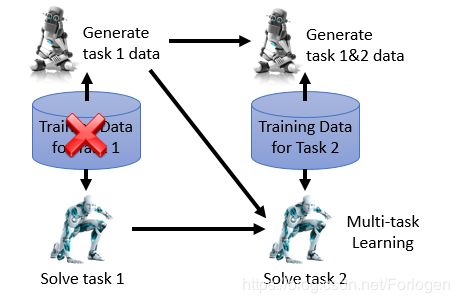
另一种方法的思想是使用一个生成模型,它可以是VAE、GAN等。既然我们无法存储所有的训练数据,那么我们就使用一个生成模型来学习已经训练过的数据的关键信息,当我们在解决下一个任务时,就用生成模型生成一些之前的数据来同时训练。这样既解决了数据存储的问题,又使用了前面所讲的同时在混合数据集上训练一个模型的想法。
相关的资料可参考:
Shin, H., Lee, J. K., Kim, J. & Kim, J. (2017), Continual learning with deep generative replay, NIPS’17, Long Beach, CA
Kemker, R. & Kanan, C. (2018), Fearnet: Brain-inspired model for incremental learning, ICLR’18, Vancouver, Canada.
此外还有Adding New Classes的方法,具体的可见
Learning without forgetting (LwF) https://arxiv.org/abs/1606.09282

iCaRL: Incremental Classifier and Representation Learning https://arxiv.org/abs/1611.07725

Knowledge Transfer
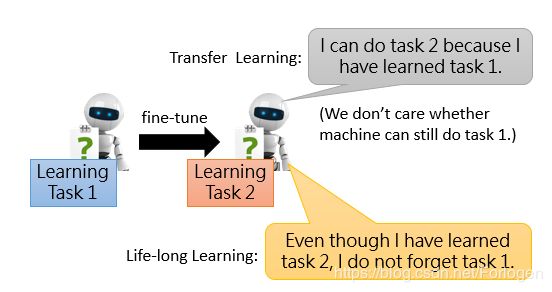
前面提到关于终身学习的Knowledge Transfer方面和迁移学习具有一定的不同之处,怎么理解呢?假设现在只有两个任务,我们现在Task 1上训练模型,然后再在Task 2上继续训练。迁移学习关注的只是在Task 2上训练完的模型在Task 2上表现良好,不关心是否在Task 1上是否依然可以取得不错的效果。而终身学习希望的是不仅在Task 2上效果不错,同时不要忘记在Task 1学习到的东西。
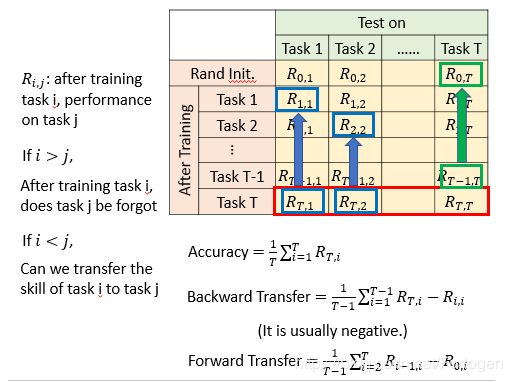
为了评估终身学习的模型的好坏,通常会建立如下的这样的矩阵,表目的含义如下所示。我们可以使用Accuracy(红框部分)、Backward Transfer (蓝框部分)、Forward Transfer(绿框部分)来衡量模型的好坏。
解决这个问题的另一个方法是Gradient Episodic Memory (GEM)
GEM: https://arxiv.org/abs/1706.08840
A-GEM: https://arxiv.org/abs/1812.00420
它的原理如下所示,红色虚线箭头 g g g表示前面任务损失函数梯度下降最快方向,绿色箭头和蓝色箭头表示新任务损失函数梯度下降最快的方向。GEM所做的是希望之前任务梯度下降的方向靠近新任务梯度下降的方向,如红色实线箭头 g ′ g' g′所示,同时又要求 g g g和 g ′ g' g′不要离得太远,表示希望模型不要忘记已经学到的东西。

论文中的实验结果如下所示,在多个数据集的效果都优于它之前的模型。

Model Expansion
对于这个问题的解决办法至今并不是很多,其中的一种方法是Progressive Neural Network,即在新的任务上训练模型时,使用之前已经训练得到的所有模型的参数作为新模型的初始化参数,而不是使用参数的随机初始化。
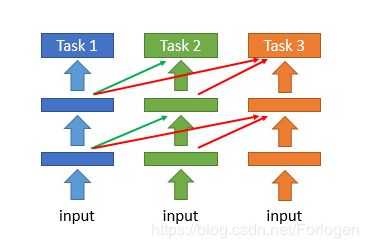
还有一种Expert Gate的方法,它是原理是额外引入了一个Gate,在训练之前比较新任务和之前的哪个任务比较相似,然后使用相似任务上得到的模型的参数初始化新模型的参数。

Aljundi, R., Chakravarty, P., Tuytelaars, T.: Expert gate: Lifelong learning with a network of experts. CVPR (2017)
还有一种称为Net2Net的方法,它是在需要扩展模型时,将其中的某个节点复制出一个新的节点,它们的参数相同,输出为之前的一半。
详细内容可参考
Net2Net: Accelerating Learning via Knowledge Transfer https://arxiv.org/abs/1511.05641
Expand the network only when the training accuracy of the current task is not good enough. https://arxiv.org/abs/1811.07017
除了上述的问题之外,任务之间的顺序对于模型的效果也有着很大的影响,相关的论文
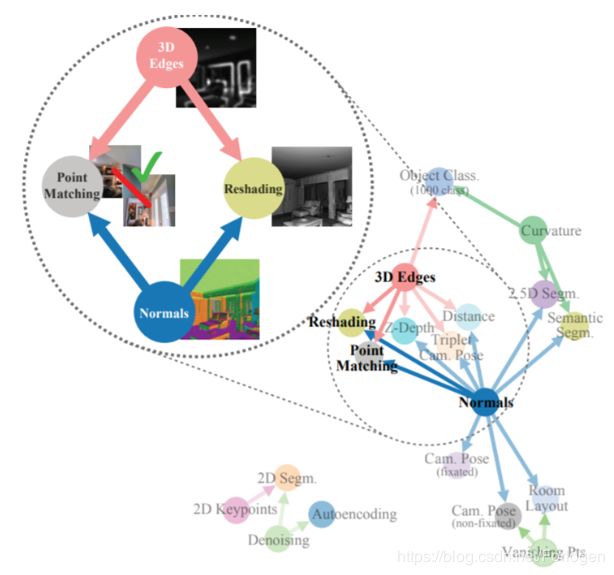
TASKONOMY Disentangling Task Transfer Learning http://taskonomy.stanford.edu/#abstract
其他
终身学习著名研究者的个人主页:
- Daniel L.Sliver:此人是先驱级的人物,早期理论的奠基人
http://plato.acadiau.ca/courses/comp/dsilver/DLSWebSIte/Welcome.html - 杨强:此人曾在华为诺亚方舟研究所工作,从事这个方向的研究,现在在香港执教
http://www.cs.ust.hk/~qyang/ - Eric Eaton: 新秀,提出的ELLA算法效率极高(1000倍左右的提升)
http://www.seas.upenn.edu/~eeaton/
https://www.researchgate.net/publication/242025320_Lifelong_Machine_Learning_Systems_Beyond_Learning_Algorithms
https://blog.csdn.net/qrlhl/article/details/49364173
https://www.oxfordhandbooks.com/view/10.1093/oxfordhb/9780195390483.001.0001/oxfordhb-9780195390483-e-001?print=pdf
https://www.sciencedirect.com/science/article/pii/S1877042812019751
https://www.sciencedirect.com/science/article/pii/S1877042811030023
https://arxiv.org/abs/1802.07569