算法设计与分析:分治思想(2)- 选择问题(对单个数组归约)
文章目录
- 前言
- 寻找第k小的元素
- 问题描述与分析
- 解决思路
- 随机选择一个元素作为pivot
- 随机选择多个样本取中位数作为pivot
- 选择“分组中位数的中位数”作为pivot
- 总结
本文参考UCAS卜东波老师算法设计与分析课程撰写
前言
本文内容承接上次分治思想-入门的内容,分治思想的应用十分广泛,除了经典的排序中的使用以外,还有许多类型的题目可以利用分治思想简单解决。如快速从数组中找出中位数,或更一般地。找出第k小的数我们用一个简单的问题来引入。通过这个问题,我们能够更进一步理解如何对pivot进行选择分析。
寻找第k小的元素
问题描述与分析
-
给定一个乱序数组A,试求该数组中第k小的元素?
最直白的解决办法,就是对数组进行排序返回下标为k-1的元素,排序的时候选用快排或归并(若不考虑内存使用),虽然暴力,但是排序的时间复杂度是 O ( n l o g n ) O(nlogn) O(nlogn)。这种办法在数据量较小的情况下仍然可以接受。但我们仔细思考一下将数组完全排序再找第k个元素是不是有点杀鸡用牛刀,大炮轰蚊子的感觉,因为你做了很多额外的事情,浪费了许多本可以节省的时间,在acm比赛中往往后面的例子就会卡这些时间导致无法ac,在大数据应用中你反映给用户的结果就是多了几秒的响应时间,削弱了用户体验,很可能导致暴躁老哥直接不用你的产品了。因此我们考虑仍然用分治的思想,但不采用排序的方式来解决
解决思路
要找第k小的元素,我们参考快排的策略,将所有小于pivot的放到左边,大于pivot的放到右边。试想,如果有一个数,它左边的数都小于它,它右边的数都大于它,且左边的数的个数刚好是k-1,那么这个数就是第k小的元素!可以发现,这种情况下,只是说了左边的数的个数是k-1,没有要求左边的数一定是有序的,这就减少了查找的运行时间。那么我们参考快排的伪代码(在深入理解快速排序一文中),可以得到伪代码如下:
select(A,k):
S_l = [],S_r = [] // s_l存储小于pivot的值,s_r存储大于pivot的值
choose pivot A[p] // 随机抽取
for i = 0 to |A|-1:
if A[i] > A[p]:
S_r += A[i] // 若比pivot大,则将A[i]放到pivot右边
else:
S_l += A[i] // 否则将A[i]放到pivot左边
// 上面的步骤与快排类似
if |S_l| = k-1:
return A[p] // A[p]刚好是第k小元素
else if |S_l| > k-1:
return select(S_l,k) // 第k小元素落到了S_l集合中,递归查找
else:
// 第k小元素落到了S_r集合中,注意这里k改变了,因为右边的起始元素是从privot+1开始,原来第k小的元素在这里是第k-|S_l|-1小
return select(S_r,k-|S_l|-1)
从伪代码中也可以看出,每次做递归调用的时候只会对一边进行递归调用,而在快排中两边都要递归调用,从这就可以明显感觉到时间差异。当然,上述算法的好坏取决于pivot的选择,依据我们在深入理解快速排序对pivot的讨论,可以知道每次pivot的选择越靠近中心越好。下面考察三种不同的pivot选择方法做对比。
随机选择一个元素作为pivot
随机选择一个元素作为pivot很直观,很简便,就像普通快排中选择pivot一样。每一次的选择导致的运行时间都不一致,但总体来说,可以证明它是线性的(即期望运行时间O(n))。老师课程中给出了证明方法,但比较难以理解,这里我详细再说一次:
-
严格证明
首先考虑如果pivot的选择使得数组得到了较为均匀的划分(例如刚好平分),那么由于每一次只需对一边递归,可以得到时间复杂度推导如下
T ( n ) = T ( n 2 ) + c n = T ( n 4 ) + c n 2 + c n = . . . = c ( n + n 2 + n 4 + . . . + 1 ) = c ( 2 n − 1 ) = O ( n ) T(n) = T(\frac{n}{2}) + cn\\ = T(\frac{n}{4}) + c\frac{n}{2}+ cn\\ = ... \\ =c(n+\frac{n}{2} + \frac{n}{4} + ...+ 1) \\ =c(2n-1) = O(n) T(n)=T(2n)+cn=T(4n)+c2n+cn=...=c(n+2n+4n+...+1)=c(2n−1)=O(n)
同样地,在较好情况下都能得到该时间复杂度(一般将 [ 1 4 , 3 4 ] [\frac{1}{4},\frac{3}{4}] [41,43]视为较好情况),因此我们考虑那些子实例大小在 ( 3 4 ) j + 1 n + 1 , ( 3 4 ) j n , j = 0 , 1 , 2... (\frac{3}{4})^{j+1}n+1,(\frac{3}{4})^{j}n,j=0,1,2... (43)j+1n+1,(43)jn,j=0,1,2...,此时称算法处于第
j期。注意一点,并不是每一次划分都会经历一个时期,有的时候当pivot取得不当的时候,可能要好几次划分才跨越一个时期。为了方便理解我绘制了下面的图作为参考。

其中,第0期跨越了两次划分,是因为第二次的划分中只划分出1个元素,即这次的pivot选的很差,我们将这两次划分看作一个时期。设X为算法运行过程中的比较次数, X j X_j Xj为处于第j期时的比较次数,有
X = X 0 + X 1 + X 2 + . . . X=X_0+X_1+X_2+... X=X0+X1+X2+...
从时期的概念来看,当一个时期跨度越小时,算法的时间耗费越少(说明此时的pivot选的好),什么时候跨度小?(pivot选中了好区间的元素,此时一次划分就进行下一期),什么时候跨度大?(pivot选中了边边的元素,最坏情况每次都选到了最边上的,相当于每一次划分就减少一个元素)。注意这里选中好区间的概率是 1 2 \frac{1}{2} 21,因此第j期进行划分的期望是2,算法的期望比较次数不超过 2 ( 3 4 ) j n 2(\frac{3}{4})^jn 2(43)jn(子实例最多有 ( 3 4 ) j n (\frac{3}{4})^jn (43)jn个元素)
因此有 E ( X ) = E [ X 0 + X 1 + . . . ] ≤ ∑ j 2 c n ( 3 4 ) j ≤ 8 c n , 利 用 等 比 求 和 公 式 E(X) = E[X_0+X_1+...]\le\sum_j2cn(\frac{3}{4})^j\le8cn,利用等比求和公式 E(X)=E[X0+X1+...]≤j∑2cn(43)j≤8cn,利用等比求和公式注意,可能有人不理解为什么概率为 1 2 \frac{1}{2} 21,进行划分的期望就是2了,首先如果选中了好区间,那么就会进入下一期(视为成功),如果选不中就需要进一步划分(视为失败),类比投掷硬币,相当于求抛出一次正面的期望,即为2(正为成功,反为失败),简单理解就是平均需要抛掷两次才能抛出正面。
-
均摊分析证明
上面的严格证明方法虽然严谨,但是实在是太过于复杂,实际分析中我并不推荐上面的方式,因此这里介绍一下我时常用的进行复杂度分析的方法,它可能没有上面的数学推导那么严谨,但胜在简单易懂,能够快速估计出算法的时间复杂度。- 所谓均摊方式,一言以蔽之,就是分赃。在一个算法中,我们可能出现很好的情况如平分,也可能出现很坏的情况,如每次只能分出一个。这时候我们就需要考虑大部分情况,什么意思?假设 n − 1 n \frac{n-1}{n} nn−1的情况下完成一个任务时间是n, 1 n \frac{1}{n} n1的情况下完成 n 2 n^2 n2,我们可以将这1%所用的时间均摊到其他情况上(每个情况多n),那么每个相当于每个的时间是 O ( 2 n ) = O ( n ) O(2n)=O(n) O(2n)=O(n)时间复杂度还是大多数的情况。
- 应用到上面的划分情况中,我们先思考一个问题,好区间真的一定是 [ 1 4 , 3 4 ] [\frac{1}{4},\frac{3}{4}] [41,43]吗, 1 8 , 1 16 , 1 100 \frac{1}{8},\frac{1}{16},\frac{1}{100} 81,161,1001行不行?行!他们的时间复杂度都是一样的,具体分析可以参考我在深入理解快速排序一文,因此利用均摊分析,可以知道时间复杂度应该和平分的时候一样,是 O ( n ) O(n) O(n)
随机选择多个样本取中位数作为pivot
采用随机选择一个元素作为pivot,这种情况虽然期望上来说是满足线性时间复杂度的,但是我们总希望能够有一种办法使得我们选中好区间的可能性越大越好,因此我们尝试取更多样本。
-
pivot选取算法步骤
-
1、首先从数组A中随机地取r个元素,设为S
-
2、 对S排序,令u为S中 ( 1 − δ ) 2 r \frac{(1-\delta)}{2}r 2(1−δ)r小的元素,v为S中 1 + δ 2 r \frac{1+\delta}{2}r 21+δr小的元素
可以将u,v视为分位点, δ \delta δ是一个调整参数
-
3、 将数组A划分成三部分,如下
L = A i : A i < u ; M = A i : u ≤ A i ≤ v ; H = A i : A i > v ; L = {A_i:A_i -
4、 检查M是否满足以下条件:
∣ L ∣ ≤ n 2 且 ∣ H ∣ ≤ n 2 , 这 保 证 了 中 位 数 在 M 中 ∣ M ∣ ≤ c δ n , M 不 能 太 大 |L|\le \frac{n}{2} 且 |H|\le \frac{n}{2},这保证了中位数在M中\\ |M|\le c\delta n,M不能太大 ∣L∣≤2n且∣H∣≤2n,这保证了中位数在M中∣M∣≤cδn,M不能太大为什么要保证中位数在M中?因为这样可使得我们的划分更接近中心。为什么M不能太大?因为太大相当于白分
如果不满足上述条件,则回到第一步
-
5、对M排序并返回M中 ( n 2 − ∣ L ∣ ) (\frac{n}{2}-|L|) (2n−∣L∣)小的数作为A的中位数
-
-
pivot选取样例
考虑一个16个元素的样例,选取 δ = 1 2 \delta = \frac{1}{2} δ=21
可以看到此时选到的pivot就是中位数,那么在划分的时候就能使得数据量呈指数级下降,达到了目标。接下来就是调用正常的select函数。
此方法在前面的基础上进行了多采样,使得pivot选到中间的概率大大提高,这也使得算法更为稳定,性能更好。这里直接给出当 r = n 3 4 , δ = n − 1 4 r=n^{\frac{3}{4}},\delta = n^{-\frac{1}{4}} r=n43,δ=n−41时,算法的时间复杂度是O(n)。
选择“分组中位数的中位数”作为pivot
上面两种都属于不确定性的策略(元素均是随机选择),我们也可以采用确定性的策略来实现pivot的选取。其实无论确定或不确定,我们最终的目标都是尽量找到靠近中位数的数作为pivot,因为这样能够让我们的划分更加均匀,时间复杂度更低。分组取中位数策略如下:
-
1、 将数组所有元素按照5个一组划分,一共 n 5 \frac{n}{5} 5n组
-
2、找出每一组的中位数,一共耗费 6 5 n \frac{6}{5}n 56n时间
5个元素只需要6次比较就能找到中位数,过程可以参考这篇文章
-
3、递归寻找这些中位数的中位数(记为M),耗费 T ( n 5 ) T(\frac{n}{5}) T(5n)时间
-
4、基于M将A划分成 S l S_l Sl和 S r S_r Sr,耗费 O ( n ) O(n) O(n)时间
-
5、采用一开始的递归查找步骤
if |S_l| = k-1: return M // M刚好是第k小元素 else if |S_l| > k-1: return select(S_l,k) // 时间复杂度最多T(7n/10) else: return select(S_r,k-|S_l|-1) // 时间复杂度最多T(7n/10)
将上面的过程画成图例如下(对一个有55个元素的无序数组):
可以发现,依据这种方法找到M很接近实际中位数。且知道蓝色的区域一定小于M,红色的区域一定大于M,这两个区域的数量各占 3 10 n \frac{3}{10}n 103n(依据图例容易推导),那么我们如果用M作为pivot划分,至少可以分出 3 10 n \frac{3}{10}n 103n的数据,所以下一步递归最多还需要处理 7 10 \frac{7}{10} 107的数据。
- 时间复杂度
总的时间复杂度依据伪代码可以得到如下:
T ( n ) ≤ T ( n 5 ) + T ( 7 10 n ) + c n , c = 6 5 T(n)\le T(\frac{n}{5}) + T(\frac{7}{10}n) + cn,c=\frac{6}{5} T(n)≤T(5n)+T(107n)+cn,c=56
这个的复杂度结果的推导与快排中不均匀的划分类似,但其复杂度结果却不是 O ( n l o g n ) O(nlogn) O(nlogn),我们用图例画一下:
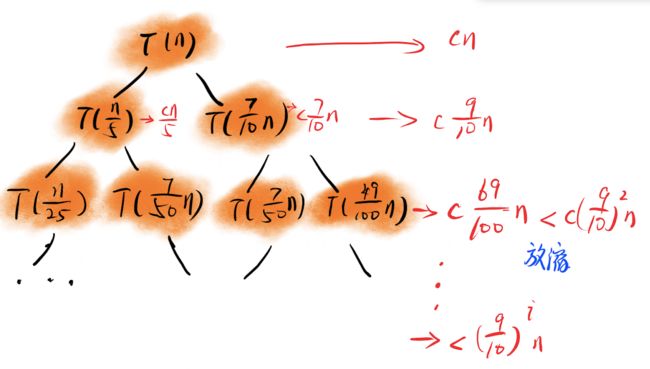
这里用到了高中数学常用的放缩技巧,让一个不可统计数列变成等比数列方便求和,因此上述时间复杂度有:
T ( n ) ≤ T ( n 5 ) + T ( 7 10 n ) + c n ≤ T ( n 25 ) + T ( 7 50 n ) + T ( 7 50 n ) + T ( 49 100 n ) + c 9 10 n + c n ≤ . . . ≤ c n + c 9 10 n + c ( 9 10 ) 2 n + . . . = c n ( 1 − ( 9 10 ) i 1 − 9 10 ) = O ( n ) T(n) \le T(\frac{n}{5})+T(\frac{7}{10}n)+cn \\ \le T(\frac{n}{25})+T(\frac{7}{50}n)+T(\frac{7}{50}n)+T(\frac{49}{100}n)+c\frac{9}{10}n+cn\\ \le...\\ \le cn+c\frac{9}{10}n+c(\frac{9}{10})^2n+...\\ = cn(\frac{1-(\frac{9}{10})^i}{1-\frac{9}{10}})\\ =O(n) T(n)≤T(5n)+T(107n)+cn≤T(25n)+T(507n)+T(507n)+T(10049n)+c109n+cn≤...≤cn+c109n+c(109)2n+...=cn(1−1091−(109)i)=O(n)
基于上述推导我们也可以得出一个结论,对于 T ( n ) = T ( n a ) + T ( n b ) + O ( n d ) T(n) = T(\frac{n}{a})+T(\frac{n}{b})+O(n^d) T(n)=T(an)+T(bn)+O(nd),当 1 a + 1 b < 1 \frac{1}{a}+\frac{1}{b} < 1 a1+b1<1时, T ( n ) T(n) T(n)时间复杂度与 O ( n d ) O(n^d) O(nd)相同。你不妨猜想一下 1 a + 1 b = 1 和 1 a + 1 b > 1 的 情 况 \frac{1}{a}+\frac{1}{b} =1和\frac{1}{a}+\frac{1}{b}>1的情况 a1+b1=1和a1+b1>1的情况
-
为什么分成5各一组?
上述的5个元素一组的划分看似很巧妙,那么这个界限能否更紧一些呢,实验证明当3个一组的时候,有:
T ( n ) ≤ T ( n 3 ) + T ( 2 3 n ) + O ( n ) = O ( n l o g n ) T(n) \le T(\frac{n}{3})+T(\frac{2}{3}n)+O(n) = O(nlogn) T(n)≤T(3n)+T(32n)+O(n)=O(nlogn)注意 1 3 + 2 3 = 1 \frac{1}{3}+\frac{2}{3}=1 31+32=1导致了复杂度的提升,也就是说我们在划分的时候要尽量使得划分的两个子实例的数量之和小于原来的实例。
-
存在的问题
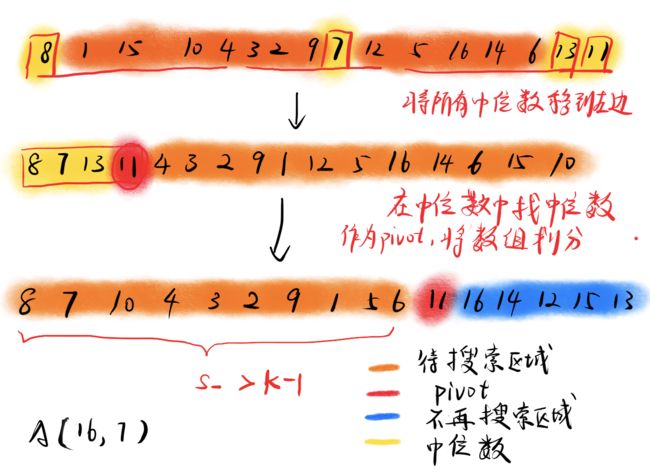
上述划分取pivot的方案看似很完美,可以较为稳定地找到好区间的元素,但是存在一点问题。我们看下面这个例子(从16个元素的数组中找第7小的):- 第一层递归 (从16个元素中找第7小)
- 第二层递归(从10个元素中找第7小)
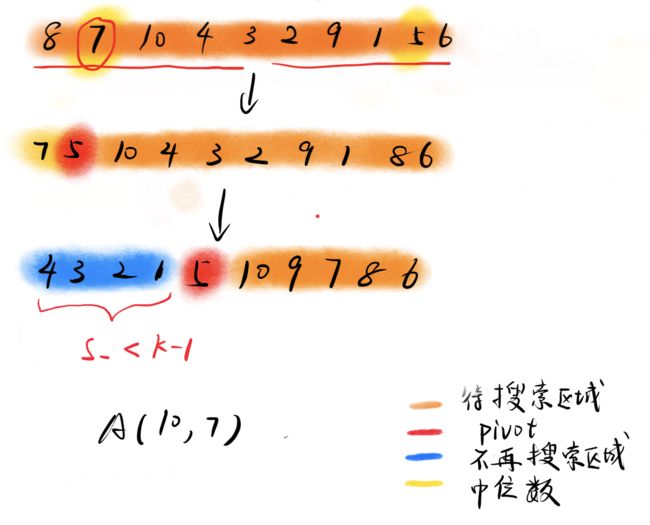
可以看到此时我要找的是第7小元素,但找的pivot却是5,虽然这个pivot是中位数使得划分尽可能地均匀,但却离我的目标较远。假设这一次我选择的是6,那么就可以直接返回7了(满足 S l = k − 1 S_l=k-1 Sl=k−1)。后面更多的划分类似这里不再赘述。我们主要探究每次找中位数存在的缺陷
- 第一层递归 (从16个元素中找第7小)
上面的例子找的数和中位数可能差距还不是很大。那么看这个例子,加入我们要在55个数中找第28小,根据前面的结果,下一次递归我们就是找(0-31)中第28小,但这个时候按照中位数的原则,我们选中的pivot往往是15左右的数,发现与28相距甚远。这就使得我们不得不多递归几次来逼近28。
-
解决方案
解决的方案由计算所的师兄提出,这里总结一下。首先回顾一下上述算法的简要步骤:- 1、 将A分成若干块,组成集合G,G中每个块长度要求大于3(因为前面证明了3会导致时间复杂度提升)
- 2、取G中每个块的中位数,构成集合M
- 3、选择M的中位数作为pivot
…
改进的算法称 α − β \alpha-\beta α−β算法,该算法的前两步均与上述算法相同,关键在于对M中元素的选取,不再是取中位数,而是动态地选取。我们从主观角度思考,假设我要找的数在中间的位置,我们第一次通过中位数确定了中间,这个时候要找的数在新的元素中的位置肯定会在边边。这时候,如果继续选中间数作为pivot,就会导致离目标较远。直观的图解如下:

你也可以参考前面(0-54)选28->(0,31)选28
改进的算法用到一个引理,如下:
若 α = k n = 1 2 \alpha=\frac{k}{n}=\frac{1}{2} α=nk=21,设下一次迭代需要找第 k ′ k' k′小的数, α ′ = k ′ n \alpha'=\frac{k'}{n} α′=nk′,则必然有 α ′ ≤ 1 4 或 α ′ ≥ 3 4 \alpha'\le\frac{1}{4}或\alpha'\ge\frac{3}{4} α′≤41或α′≥43,简言之,就是如果要找的数k靠近中位数,那么下一次迭代中要找的数 k ′ k' k′必然靠近数组的边缘,如上面的图例
将改进算法的算法简要步骤整理如下:
-
1、 将A分成若干块,组成集合G,G中每个块长度要求大于3(因为前面证明了3会导致时间复杂度提升)
-
2、取G中每个块的中位数,构成集合M
-
3、依据要找的第k小数在n中的位置 α ( α = k n ) \alpha(\alpha=\frac{k}{n}) α(α=nk),去求我们要返回的pivot在M中的位置 β ( β 由 α 决 定 ) \beta(\beta由\alpha决定) β(β由α决定)
这样就保证了每一次选的pivot都能尽量贴近目标
…
下面是 α \alpha α和 β \beta β的关系:
α ≤ 1 4 + λ → β = 3 2 α , 目 标 在 左 半 部 分 α ≥ 3 4 − λ → β = 3 2 α − 1 2 , 目 标 在 右 半 部 分 1 4 + λ < α < 3 4 − λ → β = α , 目 标 在 中 间 \alpha \le \frac{1}{4} + \lambda \to \beta = \frac{3}{2}\alpha,目标在左半部分\\ \alpha \ge \frac{3}{4} - \lambda \to \beta = \frac{3}{2}\alpha - \frac{1}{2},目标在右半部分\\ \frac{1}{4} + \lambda \lt \alpha \lt \frac{3}{4} - \lambda \to \beta = \alpha,目标在中间\\ α≤41+λ→β=23α,目标在左半部分α≥43−λ→β=23α−21,目标在右半部分41+λ<α<43−λ→β=α,目标在中间
总结
OK,这一次的内容有点多,比较难消化,建议自己动手一下来加深理解。下面总结一下全文内容。
- 1、我们由一个寻找第k小元素的问题引入,结合了之前对于快排的思考发现可以在 O ( n ) O(n) O(n)线性时间复杂度的情况下解决问题,但同时也发现这个select算法的效率受pivot影响较大。
- 2、我们尝试让pivot稳定到好区间元素,提出了三种找出pivot的方式,分别是随机一个数,随机多个样本取中位数(注意这里还涉及排序不是简单的多个数直接求中位数),对数组分组求中位数的中位数(我们还对这种方法的优劣进行了分析,给出了更好的解决方案)
- 3、在实际应用中,一般情况下,第一种随机选一个数的方式已经能够满足我们的需求,原理和快排类似(毕竟不至于一直那么倒霉选到边边,选中好区间的概率还是挺高的),但如果精益求精,想要算法更稳定的话,我们需要在pivot的选择上下点功夫,此时就用到了第二、第三种方法。第二三种方法之所以更好的原因是采样合理!!!,我们选出的数适合作为代表对数组进行分割。
- 4、对于时间复杂度的推导,我们有了更快速的办法(均摊分析),它可能不那么严谨准确,但可以大大减少我们计算复杂度的成本。同样地,对于不均匀的划分,划分比例 1 a , 1 b \frac{1}{a},\frac{1}{b} a1,b1的和决定了它是否对复杂度有提升作用。要学会复杂度推导中的放缩,来求解难以解决的复杂度分析。
如果你觉得文章对你有用,不妨顺手点个赞哦~
- 上一篇:算法设计与分析:深入理解快速排序
- 下一篇:算法设计与分析:分治思想(3)- 平面最近点对寻找问题(对点集归约)
- 目录