【Active Learning - 11】一种噪声鲁棒的半监督主动学习框架
写在前面:
在本章中,首先,我们简要地分析了半监督主动学习方法存在的一些不足。然后,针对这些不足,我们提出了一个噪声鲁棒的半监督主动学习框架,并分别对框架的各个核心部分展开详细地介绍。最后,通过第二章介绍的五组图像数据集验证了所提出框架的有效性。
说明:本文只分享理论方法,具体实验结果暂略。
主动学习系列博文:
【Active Learning - 00】主动学习重要资源总结、分享(提供源码的论文、一些AL相关的研究者):https://blog.csdn.net/Houchaoqun_XMU/article/details/85245714
【Active Learning - 01】深入学习“主动学习”:如何显著地减少标注代价:https://blog.csdn.net/Houchaoqun_XMU/article/details/80146710
【Active Learning - 02】Fine-tuning Convolutional Neural Networks for Biomedical Image Analysis: Actively and Incrementally:https://blog.csdn.net/Houchaoqun_XMU/article/details/78874834
【Active Learning - 03】Adaptive Active Learning for Image Classification:https://blog.csdn.net/Houchaoqun_XMU/article/details/89553144
【Active Learning - 04】Generative Adversarial Active Learning:https://blog.csdn.net/Houchaoqun_XMU/article/details/89631986
【Active Learning - 05】Adversarial Sampling for Active Learning:https://blog.csdn.net/Houchaoqun_XMU/article/details/89736607
【Active Learning - 06】面向图像分类任务的主动学习系统(理论篇):https://blog.csdn.net/Houchaoqun_XMU/article/details/89717028
【Active Learning - 07】面向图像分类任务的主动学习系统(实践篇 - 展示):https://blog.csdn.net/Houchaoqun_XMU/article/details/89955561
【Active Learning - 08】主动学习(Active Learning)资料汇总与分享:https://blog.csdn.net/Houchaoqun_XMU/article/details/96210160
【Active Learning - 09】主动学习策略研究及其在图像分类中的应用:研究背景与研究意义:https://blog.csdn.net/Houchaoqun_XMU/article/details/100177750
【Active Learning - 10】图像分类技术和主动学习方法概述:https://blog.csdn.net/Houchaoqun_XMU/article/details/101126055
【Active Learning - 11】一种噪声鲁棒的半监督主动学习框架:https://blog.csdn.net/Houchaoqun_XMU/article/details/102417465
【Active Learning - 12】一种基于生成对抗网络的二阶段主动学习方法:https://blog.csdn.net/Houchaoqun_XMU/article/details/103093810
【Active Learning - 13】总结与展望 & 参考文献的整理与分享(The End...):https://blog.csdn.net/Houchaoqun_XMU/article/details/103094113
3.1 导言
近年来,主动学习和半监督学习方法被广泛应用于缓解样本不足的问题。半监督学习能够在零标注成本的情况下训练模型,但由于样本伪标签的质量不高,导致模型的性能提升缓慢。主动学习方法通过获取高质量的标注样本,从而高效地提升模型的性能,但需要额外的标注成本。半监督主动学习方法[44,45,46,47,48,49]通过将两者进行组合训练,充分发挥了两者的优势。但是,目前大多数半监督主动学习方法仍存在一些缺陷: 1)未能够充分考虑噪声样本对分类器的影响,导致模型的性能提升缓慢甚至被噪声样本带偏; 2)在主动学习筛选样本的环节中,未能够充分考虑到样本之间的冗余信息,造成额外的标注成本。基于此,我们提出了一个噪声鲁棒的半监督主动学习框架(Noisy Robust Memorized Self Learning based BatchMode Active Learning, NRMSL-BMAL)。首先,对于半监督学习环节,我们提出了一个噪声鲁棒的记忆式自学习算法,分别从减少噪声样本数量和分类器的抗噪能力等方面提升模型的鲁棒性。然后,对于主动学习环节,我们尝试将卷积自编码(Convolutional Autoencoder, CAE)聚类算法引入主动学习方法中(下文称为CAE-C-BMAL,字母 C 表示聚类),并将其与传统的样本筛选策略进行组合,从而减少被选中的样本之间的冗余信息。最后,我们通过 NRMSL-BMAL 框架巧妙地将改进后的半监督学习方法融入主动学习方法中,从而更进一步减少了标注成本。

本章的主要贡献包括: 1)提出了一个噪声鲁棒的记忆性半监督学习(Noisy Robust Memorized Self Learning, NRMSL)算法。首先,我们设计了一个记忆式的自学习算法,充分利用了样本在每次迭代中的预测信息,并以约束条件的形式减少了噪声样本的产生。紧接着,为了进一步处理剩余的噪声样本,我们引入了噪声调整算法[88],以一定的概率调整噪声样本的类标。 2)我们尝试将卷积自编码聚类算法引入批量式主动学习方法中,从而提升了被选中样本的多样性和代表性,减少了被筛选的样本之间的冗余信息。 3)提出了一个 NRMSL-BMAL 框架,并通过在第二章介绍的五组图像分类数据集上进行实验,验证框架的有效性。
3.2 噪声鲁棒的半监督主动学习框架
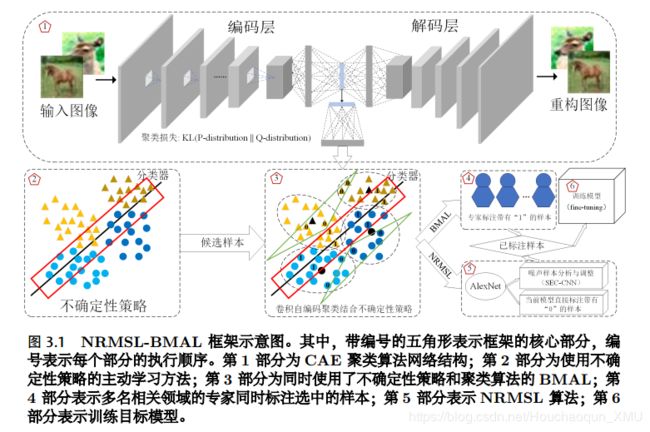
NRMSL-BMAL 框架的核心组成部分如图3.1所示,包括: 1)“编号-1”展示了基于 CAE 聚类算法的基本网络结构,下文将结合 BMAL 展开介绍。 2)“编号-2”展示了使用不确定性策略的主动学习方法,将满足不确定性最高的样本作为候选样本,如图中红色矩形框内的样本。“编号-3”展示了将聚类算法和不确定性策略进行组合的 BMAL,椭圆形虚线表示聚类算法框出了每个簇包含的样本集,簇中的黑色实心图标表示对应的簇中心;浅绿色三角形框出了通过当前分类器得到的预测结果中,确定性比较高的样本;椭圆形虚线与红色矩形框、浅绿色三角形的交集分别表示 BMAL 和 NRMSL 算法的候选样本集(分别记为 L1 和 L2)。 3)“编号-4”表示多名标注专家同时对 BMAL 算法筛选出来的样本进行标注。 4)“编号-5”表示NRMSL 算法:首先,根据当前模型对样本集 L2 进行预测;然后,直接将预测结果作为样本的类标;最后,结合噪声样本调整方法对 L2 中的样本进行调整。 5)“编号-6”表示训练目标模型:使用更新后训练样本集(L1 [ L2)对目标模型(本章使用第2.2.2 节介绍的 AlexNet 模型)进行训练。 NRMSL-BMAL 通过将上述核心部分以协同的方式整合到同一个学习框架中,充分利用了 BMAL 和半监督学习方法的优势,在保证能够高效地提升分类器性能的同时,又能够显著地减少标注成本。
目前大部分主动学习相关的研究中,都需要先随机筛选少量的样本进行标注作为初始训练样本集,并对目标模型进行预训练。然而,一般情况下,随机筛选策略相比主动学习策略需要更多的标注成本。算法 3-1展示了 NRMSL-BMAL 的基本流程中,初始化环节使用了迁移学习方法对目标模型进行预训练,并且初始训练样本集为空集。此外,第二章介绍了半监督学习的效果在一定程度上依赖于初始模型的质量。在初始训练样本集为空集的情况下, NRMSL-BMAL 框架能够缓解半监督学习将模型带偏的问题,主要归功于 BMAL 环节(步骤 13 至 16)提供的高质量标签以及 NRMSL 算法(步骤 17 至 22)引入的噪声样本自动调整方法。在获取样本类标的环节中:首先,专家标注的样本加入集合 L1 中并从未标注样本池 U 中移除;然后,通过目标模型得到标签的样本加入集合 L2 中并从 U 中移除;最后,将上述两个集合共同组成训练样本集 L。由于集合 L1 中的样本标签来源于标注专家,因此,噪声样本的自动调整方法主要针对噪声样本较多的集合 L2;但是在实际应用场景中,专家标注的样本也可能引入噪声,因此,需要根据实际情况决定噪声处理方法的对象。算法 3-1的终止条件是目标模型达到预设的目标准确率,详见本章的实验部分。
3.2.1 批量式主动学习算法
批量式主动学习(Batch Mode Active Learning, BMAL)旨在缓解样本筛选过程中的串行问题(每次迭代只筛选出一个样本)。然而,在实际应用中往往需要并行的标注环境,允许多名专家同时对一批样本进行标注,并尽可能权衡时间成本和标注成本。 BMAL 算法最核心的挑战是:缓解选的批量样本之间存在的大量冗余信息。这样使 BMAL 既能够提供并行的标注环境,又能够进一步减少额外的标注成本。本节将围绕两种不同的 BMAL 算法展开详细地介绍,包括: 1) CAE-C-BMAL通过聚类算法衡量样本之间的差异性和代表性,并结合不确定性策略综合筛选出一批待标注样本; 2)基于差异性度量方法的 BMAL:将 CNN 提取的特征作为样本差异性的指标,并结合不确定性策略综合筛选出一批待标注样本。其中,本章将使用entropy 和 BvSB 策略分别作为二分类任务和多分类任务的不确定性指标。

(1) CAE-C-BMAL: 聚类算法通过无监督的训练方式将相似度较高的样本聚成同一个簇,相似度较低的样本分布在不同的簇。在图像处理领域中,由于样本的维度较高,因此传统的聚类算法需要先进行特征提取再聚类,聚类效果在一定程度上取决于特征的质量。近几年,深度聚类算法将深度学习应用到无监督学习领域,在图像处理领域表现出更加明显的优势。 Xie 等[89]在 2016 年提出了一种深度潜入聚类算法(Deep Embedded Clustering, DEC),通过降噪自编码逐层贪婪训练,组合成栈式自编码,并使用相对熵作为损失函数对模型进行优化。但 DEC 在处理复杂图像数据的时候,直接使用传统手工特征 HOG[57],特征尚未能较好的表示未标注图像数据集。 Guo 等[90]在 DEC 的基础上提出了 IDEC 算法,使用完备自编码提升嵌入式空间的代表性,但在处理复杂图像时仍需要大量的参数。 CNN 在提取复杂图像的特征时能够大量减少参数量(详见第2.2.2 节),卷积自编码能够以较少的参数量提取出具有代表性的特征。鉴于此, Guo 等[43]在 DEC 网络结构的基础上加入了卷积自编码,提出了深度卷积嵌入式聚类算法(Deep Convolutional EmbeddedClustering, DCEC),在处理复杂图像时取得了更好的聚类效果。如图3.2展示了DEC 的网络结构示意图, DCEC 的网络结构只需将图3.2中的全连接层换成卷积层。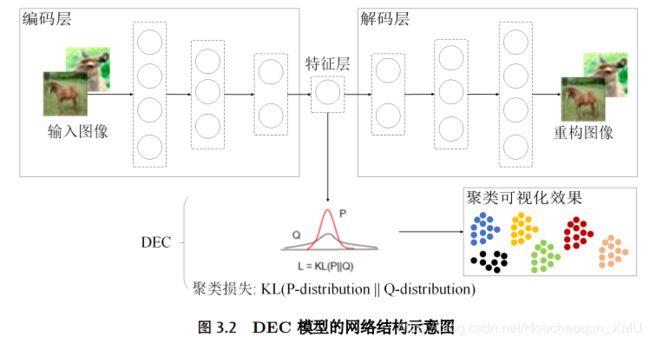
本章的 CAE-C-BMAL 算法借鉴了 DCEC 算法,如图3.1的“编号-1”展示了一个简易版的 CAE 聚类模型。首先,我们使用 CAE 聚类算法衡量样本之间的差异性和代表性。紧接着,我们将 CAE 聚类算法与主动学习方法的不确定性策略进一步结合,从而提出 CAE-C-BMAL 算法。通常情况下,主动学习方法在每次迭代筛选样本时,筛选的样本个数往往大于聚类算法得到的簇数。换言之,我们需要从每个簇中筛选出多个样本。 CAE-C-BMAL 采用两个阶段的筛选策略,第一个阶段使用不确定性策略筛选出一批规模较大的样本集;第二个阶段使用聚类算法从样本集中筛选出比较具有代表性的样本。综上所述, CAE-C-BMAL 算法在一定程度上缓解了批量样本之间存在的大量冗余信息。
(2)结合 CNN 特征与不确定性策略的批量式主动学习方法: CNNs 以端到端的方式将特征提取和分类整合在同一个网络结构中,同时具有较好的特征提取能力,本章相关实验部分的目标模型也是基于 CNN 网络结构的 AlexNet 模型(相关理论详见第二章,此处不再赘述)。因此,假设当前模型的性能已经具有提取代表性特征的能力。此时,我们通过将样本的特征作为距离度量方法的输入,从而衡量样本之间的差异性。在本章的实验部分,我们设置一个验证集准确率阈值来体现当前模型在提取特征方面的能力。换言之,当模型在验证集上的预测准确率达到预先设定的阈值(例如, 85%),我们就认为通过当前模型提取的特征已经具有一定的代表性。
如图3.3展示了结合不确定性策略和样本差异性的 BMAL 示意图。左图展示了样本之间的差异性,未标注样本的差异性度量对象包括: 1)已标注样本; 2)当前迭代中已被筛选的未标注样本。左图中列举出部分带有权值的连接线表示样本之间的距离,值越大表示样本的差异性越大。公式化描述如下:每个未标注样本 u 得到的最终差异值(dissimilarity)取决于与之相关联的所有样本组成的集合X, dissimilarity = min ({distance (x; u) jx 2 X})。其中, distance (x; u) 表示距离度量函数,例如欧式距离或者 cosine 距离等。假设只使用差异性度量筛选样本时,左图所示的 3 个未标注样本中,编号-1 所代表的未标注样本将会被优先选中。因为编号-1 与已标注样本之间的最终差异值为 1.0,而编号-2 和编号-3 的未标注样本的最终差异值分别为 0.4 和 0.2,因此优先选中差异值最高的未标注样本(编号-1)。但实际上编号-1 具有的信息量相对更少,加入训练集后对提升模型性能的贡献较小,理想状态下应该优先选择编号-2。因此,我们同时使用了不确定性策略和样本差异性策略,如3.3右图所示,红色矩形框内表示通过不确定性策略筛选的样本集。首先,框外的未标注样本(编号-1)已经通过不确定性策略排除。紧接着,由于框内的未标注样本(编号-2)和未标注样本(编号-3)满足不确定性指标,因此,再根据样本差异性策略进一步筛选。最后,综合筛选出编号-2 所代表的未标注样本,同时保证了样本的信息量和差异性。
两种 BMAL 方法的总结: 基于样本差异性的 BMAL 与 CAE-C-BMAL 都希望能够挑选出差异值较高的一批样本,从而减少所筛选样本之间的冗余信息。值得注意的是,这两种方法在筛选样本的过程中都需要跟主动学习策略进行结合,才能发挥更好的效果。例如,首先,通过不确定性策略先筛选出一批候选样本,能够在一定程度上剔除部分离群样本和信息量较低的样本。然后,通过差异性指标进一步筛选出最具有代表性的样本。本章的实验部分将上述两种不同的 BMAL 方法进行组合应用: 1)目标模型 AlexNet 在提取图像的特征时,由于前几次迭代的目标训练样本较少,因此 AlexNet 提取特征的能力较弱。此时,我们将使用 CAE 聚类算法作为筛选多样性样本的指标; 2)随着训练样本不断增多, AlexNet 的性能也将随之提升。当性能满足阈值条件时,我们同时将上述两种方法作为衡量样本多样性的指标。这样做的主要原因在于:通过多个视角进行衡量,从而更进一步保证了样本的多样性。
3.2.2 噪声鲁棒的记忆式自学习算法
半监督学习方法中存在一个明显的不足:通过模型给定样本伪标签的时候,将很有可能引入大量的噪声样本。例如,在图像分类任务中产生大量具有错误类标的样本。噪声样本会让模型学习到一些错误的信息(例如,把猫误认为狗),将严重地削弱模型的性能。目前,大多数包括深学习的模型在训练过程中对噪声样本非常敏感,少量的噪声样本就有可能导致模型学习不到样本真实的分布。因此,为了缓解噪声样本对模型的影响,我们分别从减少噪声样本的产生、增加模型对噪声样本的鲁棒性等两个方面综合考虑,提出一个噪声鲁棒的记忆式自学习算法(Noisy Robust Memorized Self Learning, NRMSL)。本节将分别围绕记忆式自学习(Memorized Self Learning, MSL)和噪声样本的自动调整方法展开介绍。
(1)设计记忆式的数据结构: MSL 假设在不同迭代状态下,模型对相同未标注样本的预测信息具有一定的价值。因此,我们将样本的记忆预测信息构成筛选样本的约束条件,从而减少噪声样本的产生。如图3.4所示,我们设计了一种数据结构,用于存储未标注样本在每次迭代过程的预测信息。我们将其体现在算法 3-1的字典变量 Dict 中,键和值(Key-Value)分别用于存储每个样本的路径和历史预测信息。 Dict 将不断更新最近的 m 次预测信息及其相关的约束条件。目前,我们使用的约束条件主要包括: 1)最新的 m 次预测结果对应的类标保持一致; 2)最新的 m次不确定分数(Entropy)控制在一定的范围内[Minentropy, Maxentropy]。这样既能够保证样本预测结果比较准确,又能够保证样本的信息量。此外,记忆式的预测信息将很容易被扩展到更多的限制条件中(例如,方差或者均值等),从而发挥更大的性能。本章的实验部分将简要地围绕 MSL 算法的执行过程展开讨论,并通过实验结果验证 MSL 算法能够减少部分噪声样本的产生。
(2)噪声样本的自动调整方法: Liu 等[88]假设模型通过训练正确的标注样本能够不断提升性能,从而提出了一种自动校正噪声标签的方法(Self-Error-Correcting Convolutional Neural Network, SEC-CNN)。 SEC-CNN 的核心思想是:首先,设计了一种置信度策略,并将其用于决定是否修改样本类标。紧接着,通过对损失函数进行改造,使得样本的类标将以一定的概率被修改为当前模型输出层中,概率最大的神经元对应的类标。例如,在十分类任务中,模型的输出层 softmax 将返回分别属于十个类标的概率值。值得注意的是,概率值最大的神经元所对应的类标(记为 ~y)有可能跟样本现有的类标不一样,此时,我们可以选择使用样本原来的类标或者 ~y。我们将对 SEC-CNN 进行简要地总结,并将其应用到半监督学习方法中。 SEC-CNN 的主要步骤如下: 1)随机筛选一定数量的样本对目标模型进行预训练; 2)使用当前模型对训练集中的所有样本进行预测并记录对应的概率值; 3)根据公式 Ct = C0 ∗ (1 - Tt )λ 计算出本次迭代的置信值 Ct。其中, C0 为初始置信值、 t为当前训练的迭代次数、 T 为预设的训练迭代总次数、 λ 用于控制 Ct 对应的多项式指数;值得注意的是,随着训练迭代次数 t 的不断增加,“步骤 3”中的置信值Ct 将不断减小,意味着样本的类标将以更大的概率修改为 ~y; 4)结合伯努利分布(Bernoulli Distribution)进一步决定每个样本的类标:通过生成一个取值范围为 0到 1 的随机数 r,如果 r > Ct 则将当前样本的类标更改为 ~y,反之不改变样本的类标; 5)模型对更新后的标注样本进行训练,并观察模型的性能是否有所提升(作者在原文中的做法是:使用了一个自定义的 softmax 损失函数,通过反向传播过程中的梯度值反映出修改类标后的样本信息); 6)重复执行上述“步骤 2”至“步骤5”,直到 t >= T 为止。至此,完成了 SEC-CNN 的核心流程。
SEC-CNN 跟传统的基于未标注样本池的主动学习方法以及半监督学习方法有个相似的过程:上述总结的“步骤 2”中, SCE-CNN 使用当前模型对相关的样本进行预测。其中, SEC-CNN 主要将其作为修改样本类别的依据,主动学习和半监督学习主要用于计算相关的策略得分(筛选样本的依据)。因此,我们几乎不需要额外的计算代价,就能够将 SEC-CNN 应用到 NRMSL-BMAL 框架中,从而提升目标模型的抗噪能力。在具体的应用中,我们主要将 SEC-CNN 应用到 NRMSL 方法中,使得 NRMSL 既能够自动标注样本的同时,又能够对噪声样本进行自动校正。
3.3 仿真实验与分析
( 暂略。。。)
实验参数设置
全样本训练实验
对比实验结果与分析
NRMSL-BMAL 选中样本的代表性
单模式主动学习方法与 BMAL 的对比实验
MSL 的分析与讨论
3.4 本章小结
本章主要提出了一个噪声鲁棒的半监督主动学习框架(NRMSL-BMAL),旨在尽可能最大化利用有限的资源,在保证不削弱模型性能的情况下减少人为的标注成本,并将其应用到图像分类任务中。首先,针对半监督学习提出一个噪声鲁棒的记忆式自学习算法(NRMSL),根据历史预测信息设置约束条件,减少了噪声样本的产生。此外,为了降低剩余噪声样本的影响,我们引入了 SEC-CNN 方法提升模型的抗噪能力。然后,考虑到 BMAL 可能产生一些具有重复信息的样本,我们尝试CAE 聚类算法引入主动学习方法中,从而增加了筛选样本的多样性,减少了样本之间冗余信息。最后, NRMSL-BMAL 巧妙地组合了 NRMSL 和 CAE-C-BMAL,并分别在五组数据集上进行了实验。实验结果表明, NRMSL-BMAL 在图像分类任务上取得了较好的效果,在实验的五组数据集中减少了 44.34% 至 95.93% 的标注成本。与此同时,为了验证 NRMSL-BMAL 筛选的样本能够在一定程度上代表剩余未被选中的样本。我们使用达到目标准确率的分类模型对所有未被主动学习方法筛选的样本进行预测,并分别计算预测准确率。实验结果表明,五组数据集得到的准确率非常接近 100%,意味着由 NRMSL-BMAL 选中的样本足以表示未被选中的样本。此外,我们分别从标注成本和时间成本的角度,对单模式的主动学习方法和 BMAL进行了对比实验。实验结果表明,虽然单模式的主动学习方法能够在一定程度上减少具有冗余信息样本的产生,但在不同数据集上的效果不稳定并且非常耗时。因此,在复杂程度不同的实际应用中,时间成本和标注成本的权衡也将是值得考虑的指标。