SparkStreaming---Spark流式数据计算模块
目录:
- 一、Spark Streaming概述
- 二、Spark Streaming特点
- 三、Spark Streaming架构
- 四、Spark Streaming代码实时分析数据
- 1.实时分析端口或目录中的数据
- 2.实时分析kafka传来的数据
- 3.实时分析flume传来的数据
- 五、Spark Streaming运行流程
一、Spark Streaming概述
Spark Streaming是构建在Spark上的流式处理框架。
Spark Streaming支持高吞吐量、可容错处理的实时流数据处理,其核心思路是将流数据分解成一系列短小的批处理作业,每个短小的批处理作业都可以使用Spark Core进行快速处理。Spark Streaming支持多种数据输入源,如Kafka,Flume和TCP套接字等。

和Spark基于RDD的概念很相似,Spark Streaming使用离散化流作为抽象表示,叫做DStream。DStream是随着时间推移而收到的数据的序列。在内部,每个时间区间收到的数据都作为RDD存在,而DStream就是由这些RDD组成的序列(因此,得名"离散化")

DStream可以从各种输入源中创建,比如Flume、kafka或者HDFS。创建出来的DStream支持两种操作,一种是转换操作(transformation),会生成一个新的DStream,另一种是输出操作(output operation),可以把数据写入外部系统中。DStream提供了许多与RDD所支持的操作相类似的操作支持,还增加了与时间相关的新操作,例如滑动窗口。
二、Spark Streaming特点
(1) 易用

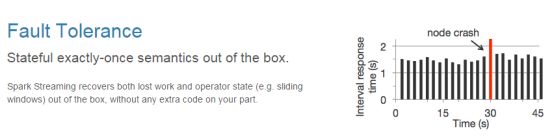
(2) 容错
(3) 易整合到Spark体系
三、Spark Streaming架构

Spark Streaming在Spark的驱动器程序—工作节点的结构的执行过程如上图所示。Spark Streaming为每个输入源启动对应的接收器。接收器以任务的形式运行在应用的执行器进程中,从输入源收集数据并保存为 RDD。它们收集到输入数据后会把数据复制到另一个执行器进程来保障容错性(默 认行为)。数据保存在执行器进程的内存中,和缓存 RDD 的方式一样。驱动器程序中的 StreamingContext 会周期性地运行Spark 作业 来处理这些数据,把数据与之前时间区间中的 RDD 进行整合。
四、Spark Streaming代码实时分析数据
1.实时分析端口或目录中的数据
pom.xml 加入以下依赖:
org.apache.spark
spark-streaming_2.11
2.2.0
package com.sparkstreaming.demo1
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* 1.实时分析端口中传来的数据
* 2.实时分析目录中的数据
*/
object SparkStreaming_wordcount {
def main(args: Array[String]): Unit = {
//spark配置对象
val conf = new SparkConf().setMaster("local[*]").setAppName("WordCount")
//实时数据分析环境对象
//采集周期(Seconds()秒)以指定的时间为周期采集实时数据
val ssc = new StreamingContext(conf, Seconds(5))
//1.创建一个将连接到主机名:端口的DStream,例如localhost:9999
val lines: ReceiverInputDStream[String] = ssc.socketTextStream("master", 9999)
//2.实时读取并分析目录中的数据
// 注意:1)文件需要有相同的数据格式
// 2)文件进入目录的方式需要通过移动或者重命名来实现。
// 3)一旦文件移动进目录,则不能再修改,即便修改了也不会读取新数据。
// val lines: DStream[String] = ssc.textFileStream("test")
// 将每一行拆分成单词(数据扁平化)
val words = lines.flatMap(_.split(" "))
// 计算每批中的每个单词
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
// 将在此DStream中生成的每个RDD的前十个元素打印到控制台
wordCounts.print()
ssc.start() // 开始计算
ssc.awaitTermination() // 等待计算终止
}
}
2.实时分析kafka传来的数据
Spark对kafka有两种连接方式:直连方式和接收器方式。
Pom.xml 加入以下依赖:
org.apache.spark
spark-streaming-kafka-0-8_2.11
2.0.2
package com.sparkstreaming.demo1
import kafka.serializer.StringDecoder
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, InputDStream, ReceiverInputDStream}
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* SparkStreaming整合kafka
*/
object kafkaStreaming {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[2]").setAppName("sparkstreamkafka")
val ssc = new StreamingContext(conf,Seconds(5))
// 配置kafka参数。使用map集合。
val kafkaParmas = Map(
"metadata.broker.list" -> "192.168.137.3:9092,192.168.137.4:9092,192.168.137.5:9092",
"group.id" -> "kafka_Direct")
// 主题配置
val topics = Set("kafka_spark")
// 使用kafkaUtil。当做数据源获取数据(直连方式)
val streams: InputDStream[(String, String)] = KafkaUtils.createDirectStream[String,String,StringDecoder,StringDecoder](ssc,kafkaParmas,topics)
/*
// 只用kafkaUtil 当做数据源读取数据(接收器模式)
var zkServer = "192.168.137.3:2181,192.168.137.4:2181,192.168.137.5:2181,"
val topics1 = Map[String,Int]("kafka_spark1"->1)
val line1: ReceiverInputDStream[(String, String)] = KafkaUtils.createStream(ssc,zkServer,"p1",topics1)
*/
val line: DStream[String] = streams.map(_._2)
val reduced: DStream[(String, Int)] = line.flatMap(_.split(" ").map((_,1))).reduceByKey(_+_)
reduced.print()
ssc.start()
ssc.awaitTermination()
}
}
3.实时分析flume传来的数据
Spark提供两个不同的接收器来使用Apache Flume,一个是推式接收器,一个是拉式接收器。
• 推式接收器该接收器以 Avro 数据池的方式工作,由 Flume 向其中推数据。
• 拉式接收器该接收器可以从自定义的中间数据池中拉数据,而其他进程可以使用 Flume 把数据推进 该中间数据池。
集群中添加sparkStream和flume连接的配置
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#source
a1.sources.r1.channels = r1
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /home/liu/flumedata //文件必须存在
a1.sources.r1.fileHeader = true
#channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 20000
a1.channels.c1.transactionCapacity = 5000
#sinks
a1.sinks.k1.channels = c1
a1.sinks.k1.type = org.apache.spark.streaming.flume.sink.SparkSink
a1.sinks.k1.hostname = 192.168.137.3
a1.sinks.k1.port = 8888
a1.sinks.k1.batchSize = 2000
org.apache.spark
spark-streaming-flume_2.11
2.0.2
org.scala-lang
scala-library
2.11.11
// 推式接收器
package com.demo.sparkstreaming
import java.net.InetSocketAddress
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.flume.{FlumeUtils, SparkFlumeEvent}
object SparkStreamingFlume_Push {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setAppName("SparkStreamingFlume_Push").setMaster("local[2]")
val sc = new SparkContext(sparkConf)
val ssc = new StreamingContext(sc, Seconds(15))
val stream: ReceiverInputDStream[SparkFlumeEvent] = FlumeUtils.createStream(ssc,"192.168.137.1",8888)
val lineDstream: DStream[String] = stream.map(x => new String(x.event.getBody.array()))
val wordAndOne: DStream[(String, Int)] = lineDstream.flatMap(_.split(" ")).map((_, 1))
val result: DStream[(String, Int)] = wordAndOne.reduceByKey(_ + _)
result.print()
ssc.start()
ssc.awaitTermination()
}
}
// 拉式接收器
package com.demo.sparkstreaming
import java.net.InetSocketAddress
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.flume.{FlumeUtils, SparkFlumeEvent}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
object SparkStreamingFlume_Poll {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setAppName("SparkStreamingFlume_Poll").setMaster("local[2]")
val sc = new SparkContext(sparkConf)
val ssc = new StreamingContext(sc, Seconds(15))
val address = Seq(new InetSocketAddress("192.168.137.3", 8888))
val stream: ReceiverInputDStream[SparkFlumeEvent] = FlumeUtils.createPollingStream(ssc, address, StorageLevel.MEMORY_AND_DISK_SER_2)
val lineDstream: DStream[String] = stream.map(x => new String(x.event.getBody.array()))
val wordAndOne: DStream[(String, Int)] = lineDstream.flatMap(_.split(" ")).map((_, 1))
val result: DStream[(String, Int)] = wordAndOne.reduceByKey(_ + _)
result.print()
ssc.start()
ssc.awaitTermination()
}
}
五、Spark Streaming运行流程
基本概念:
(1)Application =>Spark的应用程序,包含一个Driver program和若干Executor
(2)SparkContext => Spark应用程序的入口,负责调度各个运算资源,协调各个Worker Node上的Executor
(3)Driver Program => 运行Application的main()函数并且创建SparkContext
(4)Executor => 是为Application运行在Worker node上的一个进程,该进程负责运行Task,并且负责将数据存在内存或者磁盘上。每个Application都会申请各自的Executor来处理任务
(5)Cluster Manager =>在集群上获取资源的外部服务 (例如:Standalone、Mesos、Yarn)
(6)Worker Node => 集群中任何可以运行Application代码的节点,运行一个或多个Executor进程
(7)Task => 运行在Executor上的工作单元
(8)Job => SparkContext提交的具体Action操作,常和Action对应
(9)Stage => 每个Job会被拆分很多组task,每组任务被称为Stage,也称TaskSet
(10)DAGScheduler => 根据Job构建基于Stage的DAG,并提交Stage给TaskScheduler
(11)TaskScheduler => 将Taskset提交给Worker node集群运行并返回结果

Spark Streaming运行流程:
- 客户端提交作业后启动Driver,Driver是park作业的Master。
- 每个作业包含多个Executor,每个Executor以线程的方式运行task,Spark Streaming至少包含一个receiver task。
- Receiver接收数据后生成Block,并把BlockId汇报给Driver,然后备份到另外一个Executor上。
- ReceiverTracker维护Reciver汇报的BlockId。
- Driver定时启动JobGenerator,根据Dstream的关系生成逻辑RDD,然后创建Jobset,交给JobScheduler。
- JobScheduler负责调度Jobset,交给DAGScheduler,DAGScheduler根据逻辑RDD,生成相应的Stages,每个stage包含一到多个task。
- TaskScheduler负责把task调度到Executor上,并维护task的运行状态。
- 当tasks,stages,jobset完成后,单个batch才算完成。