Python源码之dict字典底层解析
文章目录
- 1、PyDictObject
- 1.2 PyDictKeyEntry
- 1.3PyDictKeysObject
- 1.4 PyDictObject
- 2、探究entry三种状态
- 3、PyDictObject的创建与操作
- 3.1 PyDictObject的创建
- 3.2 谈谈PyDictObject中的hash table
- 3.3 PyDictobject对象的元素搜索
- 3.4 PyDictObject的元素插入
- 3.5 PyDictObject元素删除操作
- 4、PyDictObject对象缓冲池
python中的dict可能我们最常用的容器之一了,它是一种用来存储某种关系映射的数据对的集合。在其他语言中例如Java也有相应的容器类型,例如map。它们底层实现的方式也不尽相同,而我们Python中的dict底层怎么实现的呢?实际上它就是一个Hash Table,由于其查找效率非常高所以在实际开发中,我们经常使用这个中数据容器。关于hash table我们在这里就不展开取讲述了,如果不清楚的可以去看数据结构的Hash Table原理。
关于Hash Table我们这里只提一点,我们知道在将键通过hash function散列的时候,不同的对象可能会生成相同的hash值,也就是“哈希冲突”,显然这是我们所不允许的。因此我们需要对这种冲突进行处理,在Python中选择的处理方式是 “开放定址法” 所采用的策略是 “二次探测再散列” 。也就是说当出现哈希冲突的时候,会通过一个 “二次数列” 的地址偏量再次进行探测直到找到一个可以放下元素的位置。在这个再次探测的过程中就会形成一个探测序列,可以试想一下这个问题,假如探测序列上的某个元素被删除了会出现什么问题?没错,这个探测序列就被中断了,假如我们需要查找的元素在这个被删除的元素之后,那么我们就search不到这个元素了。这显然是不行的,因此在采用开放定址发的策略中必须解决这个问题,而Python的解决方式就是使用dummy的删除方式。这个我们后面再讲。
1、PyDictObject
PyDictObject对象包含很多子结构,整个结构相对比较复杂,因此我们有必要先了解清楚整个PyDictObject的内存构造以及子结构。
-
1.2 PyDictKeyEntry
我们知道dict中实际上存储的是键值对,那么这个键值对是以什么样的形式存在的呢?接下来就看一看键值对在底层是如何定义的
// dict-common.h
typedef struct {
/* Cached hash code of me_key. */
Py_hash_t me_hash;
PyObject *me_key;
PyObject *me_value; /* This field is only meaningful for combined tables */
} PyDictKeyEntry;
可以看到这里面有三个变量,me_hash是用来缓存键的哈希值,这样可以避免每次查询的时候重复计算。me_key和me_value这两个域用来存储键和值,可以看见它们都是PyObject *类型,因此dict可以存储各种类型对象。
-
1.3PyDictKeysObject
从命名我们就知道它是和字典中的key相关的一个结构体,我们看看它的定义
// dict-common.h
/* dict_lookup_func() returns index of entry which can be used like DK_ENTRIES(dk)[index].
* -1 when no entry found, -3 when compare raises error.
*/
typedef Py_ssize_t (*dict_lookup_func)
(PyDictObject *mp, PyObject *key, Py_hash_t hash, PyObject ***value_addr,
Py_ssize_t *hashpos);
struct _dictkeysobject {
Py_ssize_t dk_refcnt;
Py_ssize_t dk_size;
dict_lookup_func dk_lookup;
Py_ssize_t dk_usable;
Py_ssize_t dk_nentries;
/* Actual hash table of dk_size entries. It holds indices in dk_entries,
or DKIX_EMPTY(-1) or DKIX_DUMMY(-2).
Indices must be: 0 <= indice < USABLE_FRACTION(dk_size).
The size in bytes of an indice depends on dk_size:
- 1 byte if dk_size <= 0xff (char*)
- 2 bytes if dk_size <= 0xffff (int16_t*)
- 4 bytes if dk_size <= 0xffffffff (int32_t*)
- 8 bytes otherwise (int64_t*)
Dynamically sized, 8 is minimum. */
union {
int8_t as_1[8];
int16_t as_2[4];
int32_t as_4[2];
#if SIZEOF_VOID_P > 4
int64_t as_8[1];
#endif
} dk_indices;
};
是不是看着有点懵圈?别急我们慢慢解读。
dk_refcnt是指引用计数;
dk_size是指hash table的大小,也就是dk_indices的大小,它的值必须为2的幂;
dk_lookup是哈希表的操作相关的函数,它被定义为一个函数指针,内部间接调用了search相关操作以及处理冲突的策略;
dk_usable指dk_entries中的可用的键值对数量;
dk_nentries指dk_entries中已经使用的键值对数量;
dk_indices是一个共用体,其内部成员变量共享一片内存,其成员变量是一个数组,用于存储dk_entries的哈希索引,它具体结构是什么可先不用管,后面我们会详细解析。需要注意的是数组中的元素类型会随着hash table的大小变化,代码注释中也显示了当哈希表大小 <= 128 时,索引数组的元素类型为 int_8_t,这是C语言中的一种结构标注,并非新的数据类型,它使用typedef定义的,它代表了一个有符号的char类型占用一个字节。int_16_t表示当哈希表大小<=0xffff时用两个字节,也就是short,以此类推。这样做可以节省内存使用;
我们看到的dk_entries是个什么东西?为什么一直说到它?它实际上也是一个数组,数组的元素类型就是PyDictKeysEntry,一个键值对就是一个entry。
-
1.4 PyDictObject
PyDictObject就是dict的底层实现啦,我们也来看看它的定义
// dictobject.h
typedef struct _dictkeysobject PyDictKeysObject;
/* The ma_values pointer is NULL for a combined table
* or points to an array of PyObject* for a split table
*/
typedef struct {
PyObject_HEAD
/* Number of items in the dictionary */
Py_ssize_t ma_used;
/* Dictionary version: globally unique, value change each time
the dictionary is modified */
uint64_t ma_version_tag;
PyDictKeysObject *ma_keys;
/* If ma_values is NULL, the table is "combined": keys and values
are stored in ma_keys.
If ma_values is not NULL, the table is splitted:
keys are stored in ma_keys and values are stored in ma_values */
PyObject **ma_values;
} PyDictObject;
ma_used字段用以存储字典中元素的个数;ma_version_tag字段代表字典的版本,全局唯一,每一次字典改变它的值都会改变;如果ma_values的值为NULL,这张表为combained,此时key和value的值都存储在ma_keys中,如果ma_values的值不为NULL,这张表为split,key都存在ma_keys中,而value存储在ma_values这个数组中。我们用一张图来增加我们的理解

是不是突然就恍然大悟了,一张图胜过千言万语,哈哈哈。
2、探究entry三种状态
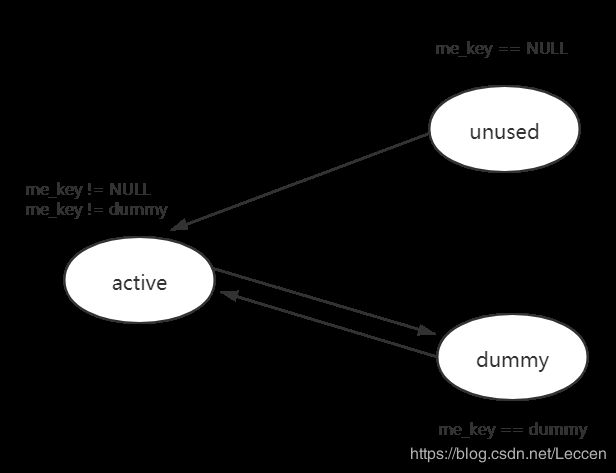
在操作系统中我们知道进程有三种存活的状态:运行状态,阻塞状态,就绪状态。在Python中,当PyDictObject发生变化时,entry会在三种状态中切换,那么这三种entry的状态究竟是怎么样一回事呢?我们来看看。
- unused态:当entry中的me_key字段和me_value字段都为NULL时,此时的entry处于unsed态,处于此状态的entry表明这个entry没有存储任何键值对,并且之前也没有存储过键值对。任何entry在初始化的时候都处于这个状态,而且me_key只有在这个状态下才为NULL,而me_value都可能为0,这取决于表的方式是combined还是split。
- active态:当entry中存储了键值对时,entry的状态就从unused态切换为active态,此状态下me_key和me_value都不能为NULL
- dummy态:当dict中的entry被删除后,此entry的状态就从active态变为了dummy态,它并不是在被删除后就直接变为了unused态,因为在开篇我们提到过,当发生哈希冲突时,Python会沿着探测序列继续探测下一个位置,如果此时的entry变为unused态则探测序列就中断了。当Python沿着一条探测序列search时,如果探测到某个entry处于dummy态,就说明此entry是一个无效的entry但是后面可能还存在着有效的entry,因此就保证了探测的连续性而不会导致中断。当search到某个处于unused态的entry时,证明确实不存在这样的一个key.
我们用一个图示来简单表示三种状态以及它们之间的转换关系。
3、PyDictObject的创建与操作
-
3.1 PyDictObject的创建
在内部,Python通过PyDict_New()函数来创建一个新的PyDictObject对象,其函数原型如下。
// dictobject.c
PyObject *
PyDict_New(void)
{
PyDictKeysObject *keys = new_keys_object(PyDict_MINSIZE);
if (keys == NULL)
return NULL;
return new_dict(keys, NULL);
}
从代码中可看出,在创建PyDictObject对象时会先通过new_keys_object()函数创建一个PyDictKeysObject对象,并通过宏传入一个大小,它表示dict的初始大小也就是哈希表的大小,指定为8. 然后再通过new_dict()函数创建一个Dict对象。我们再来看看new_keys_object()的原型。
// dictobject.c
static PyDictKeysObject *new_keys_object(Py_ssize_t size)
{
PyDictKeysObject *dk;
Py_ssize_t es, usable;
assert(size >= PyDict_MINSIZE);
assert(IS_POWER_OF_2(size));
// 装载因子,研究显示哈希表中的数量应当不超过表长的2/3,这样产生的冲突概率比较低
usable = USABLE_FRACTION(size);
if (size <= 0xff) {
es = 1;
}
else if (size <= 0xffff) {
es = 2;
}
#if SIZEOF_VOID_P > 4
else if (size <= 0xffffffff) {
es = 4;
}
#endif
else {
es = sizeof(Py_ssize_t);
}
// 使用缓冲池
if (size == PyDict_MINSIZE && numfreekeys > 0) {
dk = keys_free_list[--numfreekeys];
}
// 不使用缓冲池
else {
dk = PyObject_MALLOC(sizeof(PyDictKeysObject)
- Py_MEMBER_SIZE(PyDictKeysObject, dk_indices)
+ es * size
+ sizeof(PyDictKeyEntry) * usable);
if (dk == NULL) {
PyErr_NoMemory();
return NULL;
}
}
DK_DEBUG_INCREF dk->dk_refcnt = 1;
// 哈希表的大小
dk->dk_size = size;
// dk_entries中可用的数量
dk->dk_usable = usable
// 使用默认的以PyStringObject对象的搜索策略
dk->dk_lookup = lookdict_unicode_nodummy;
// dk_entries中使用的数量
dk->dk_nentries = 0;
memset(&dk->dk_indices.as_1[0], 0xff, es * size);
memset(DK_ENTRIES(dk), 0, sizeof(PyDictKeyEntry) * usable);
return dk;
}
我们可以看见在代码中插入了一些断言语句,主要用于做一些检查,首先会检查传入的size也就是entry的容量是否大于等于8,并且检查size的大小是否为2的幂。es变量主要是用来确定hash table的索引占用多少字节,可以看到当size的值小于等于0xff也就是十进制的255时,es为一个字节,以此类推。USABLE_FRACTION()函数用于指定哈希表的可用容量大小,其内部做了这样一个运算:(((n) << 1)/3),实际上就是将size乘以一个2/3,为什么要乘2/3呢?前面我们也提到过,因为通过研究表明当hash table中的元素数量达到总容量的三分之二时,就很容易出现hash冲突。
接下来开始创建对象,可以看到dict也使用了缓冲池的技术,当缓冲池中有可用的对象时直接取出即可,如果没有可用的对象则调用malloc()函数在堆内存中分配空间用以创建新的对象。创建完对象后开始调整引用计数,并设置hash table的容量。dk_lookup中包含了hash function以及当出现hash conflict时二次探测函数的具体实现,其默认的search方式为Unicode,它实际上只是通用搜索的一个特例,我们后面会详细讲解。最后调用万能函数 memset() 来初始化内存,第一个memset()函数调用是指将dk->dk_indices.as_1[0]所在的内存初始化为0xff,由于这个函数是以字节为单位copy,所以第三个参数是总的字节数,这点很重要。它实际上完成的工作就是将哈希表中的dk_indices索引数组初始化,而第二个函数调用是将hash table中真正存储键值对的数组初始化。这与这一点您先记住,看不懂也没关系,后面我们会讲解这个东西,我可以告诉你的是它是在Python3.6之后对hash table进行了优化方式。
回到PyDict_New()函数中,当创建完PyDictKeysObject对象后接着调用new_dict()函数,其原型如下。
// dictobject.c
static PyObject *
new_dict(PyDictKeysObject *keys, PyObject **values)
{
PyDictObject *mp;
assert(keys != NULL);
if (numfree) {
mp = free_list[--numfree];
assert (mp != NULL);
assert (Py_TYPE(mp) == &PyDict_Type);
_Py_NewReference((PyObject *)mp);
}
else {
mp = PyObject_GC_New(PyDictObject, &PyDict_Type);
if (mp == NULL) {
DK_DECREF(keys);
free_values(values);
return NULL;
}
}
mp->ma_keys = keys;
mp->ma_values = values;
mp->ma_used = 0;
mp->ma_version_tag = DICT_NEXT_VERSION();
assert(_PyDict_CheckConsistency(mp));
return (PyObject *)mp;
}
接下来开始创建PyDictObject对象,首先会检查keys是否为一个有效对象,紧接着在检查缓冲池中是否有可用的对象,如果有就直接取出即可,如果没有就调用PyObject_GC_New()函数为对象在系统堆内存中分配内存用以创建对象,并为key和value设置值。
-
3.2 谈谈PyDictObject中的hash table
在上一节的解析中我提出了一个问题,在调用memset()函数时具体做的事情。现在我就来讲解一下关于hash table的结构。假如说让你自己来设计一个hash table用来实现dict你会怎么做呢?首先用一个指针指向dict内部的hash table,它实际上是一个二维数组,数组的每一行代表着存储一个键值对以及key的哈希值。于是乎,它的结构就成了下图中上面的那张图所示的结构。
当我们添加一个元素
Python3.6之后,对hash table的结构做了部分优化,怎么优化的呢?将hash table 的哈希索引和真正的键值对分开存储,首先有两个数组—indices和entries,indices值存储hash table的索引,而真正的hash table存储在entries中。如下图中第二张表所示,当插入元素
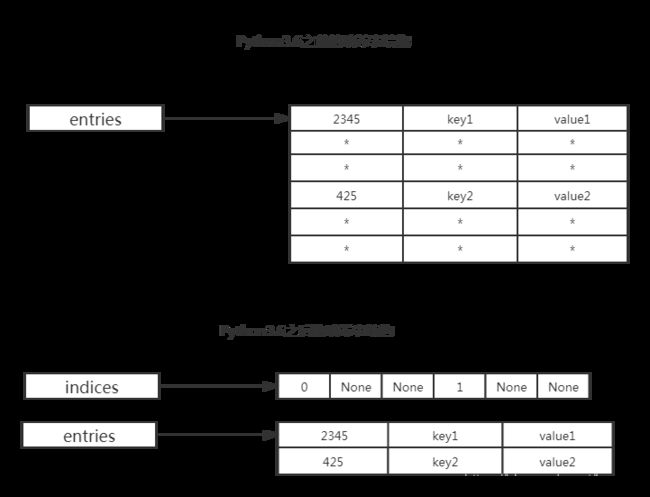
-
3.3 PyDictobject对象的元素搜索
注意这里说的搜索并非仅仅指查找,其实无论插入元素,查找元素或是删除元素都要经过搜索策略。python为哈希表搜索提供了多种函数,lookdict、lookdict_unicode、lookdict_index,一般通用的是lookdict,lookdict_unicode则是专门针对key为unicode的entry,lookdict_index针对key为int的entry,可以把lookdict_unicode、lookdict_index看成lookdict的特殊实现,只不过这两种可以非常的常用,因此单独实现了一下。我们来看看look_dict的实现。
// dictobject.c
static Py_ssize_t
lookdict(PyDictObject *mp, PyObject *key,
Py_hash_t hash, PyObject ***value_addr, Py_ssize_t *hashpos)
{
size_t i, mask;
Py_ssize_t ix, freeslot;
int cmp;
PyDictKeysObject *dk;
PyDictKeyEntry *ep0, *ep;
PyObject *startkey;
top:
dk = mp->ma_keys;
mask = DK_MASK(dk);
ep0 = DK_ENTRIES(dk);
i = (size_t)hash & mask;
// 获取该key所对应的哈希表中位置的索引
ix = dk_get_index(dk, i);
// 如果没有存储值,该entry处于unused态也就是没有搜索到,将值的指针设置为NULL
if (ix == DKIX_EMPTY) {
if (hashpos != NULL)
*hashpos = i;
*value_addr = NULL;
return DKIX_EMPTY;
}
// 如果待搜索的entry处于dummy态
if (ix == DKIX_DUMMY) {
// 将这个entry记录下来
// 遍历探测链上的下一个entry
freeslot = i;
}
// 如果该entry处于active态
else {
// 通过indices数组中存储的哈希表索引将该entry的地址取出
ep = &ep0[ix];
assert(ep->me_key != NULL);
// 如果指定的key与待搜索的key为同一个对象
// 取出me_value指针的地址
if (ep->me_key == key) {
*value_addr = &ep->me_value;
if (hashpos != NULL)
*hashpos = i;
return ix;
}
// 如果指定的key与待搜索的key的哈希值相等
if (ep->me_hash == hash) {
startkey = ep->me_key;
Py_INCREF(startkey);
// 比较key的“值”是否相等
cmp = PyObject_RichCompareBool(startkey, key, Py_EQ);
Py_DECREF(startkey);
// 如果在比较中发生错误
// 返回一个错误的标识
if (cmp < 0) {
*value_addr = NULL;
return DKIX_ERROR;
}
// 如果字典没有发生内存变化
if (dk == mp->ma_keys && ep->me_key == startkey) {
// 如果结果大于0,则说明这两个key相等
if (cmp > 0) {
*value_addr = &ep->me_value;
if (hashpos != NULL)
*hashpos = i;
return ix;
}
}
// 字典由于某种原因发生内存或其他变化,继续执行上述步骤
else {
/* The dict was mutated, restart */
goto top;
}
}
freeslot = -1;
}
// 继续探测探测链上的下一个entry
for (size_t perturb = hash;;) {
// 将哈希值右移5,即乘以二的5次方
perturb >>= PERTURB_SHIFT;
// 使用开放定址法的二次探测再散列
i = ((i << 2) + i + perturb + 1) & mask;
ix = dk_get_index(dk, i);
// 搜索失败
if (ix == DKIX_EMPTY) {
if (hashpos != NULL) {
// 如果探测链上未存在处于dummy态的entry则标记这个处于unused态的entry
// 为一个立即可用的entry
*hashpos = (freeslot == -1) ? (Py_ssize_t)i : freeslot;
}
*value_addr = NULL;
return ix;
}
// 如果该entry处于dummy态
if (ix == DKIX_DUMMY) {
// 探测链上未出现处于dummy态的entry
if (freeslot == -1)
freeslot = i;
continue;
}
// 如果该entry处于active态
ep = &ep0[ix];
assert(ep->me_key != NULL);
if (ep->me_key == key) {
if (hashpos != NULL) {
*hashpos = i;
}
*value_addr = &ep->me_value;
return ix;
}
if (ep->me_hash == hash) {
startkey = ep->me_key;
Py_INCREF(startkey);
// 比较值是否相等
cmp = PyObject_RichCompareBool(startkey, key, Py_EQ);
Py_DECREF(startkey);
if (cmp < 0) {
*value_addr = NULL;
return DKIX_ERROR;
}
if (dk == mp->ma_keys && ep->me_key == startkey) {
if (cmp > 0) {
if (hashpos != NULL) {
*hashpos = i;
}
*value_addr = &ep->me_value;
return ix;
}
}
else {
/* The dict was mutated, restart */
goto top;
}
}
}
assert(0); /* NOT REACHED */
return 0;
}
一看代码就晕?别急,我们慢慢开抽丝剥茧。首先通过一个宏DK_MASK做一些操作,这个宏就做了一件事情,就是将dk中的size减1然后赋值给mask变量。然后再通过DK_ENTRIES这个宏对dk做处理,这个宏做了什么事情呢?我们来看看它的定义
#define DK_SIZE(dk) ((dk)->dk_size)
#if SIZEOF_VOID_P > 4
#define DK_IXSIZE(dk) \
(DK_SIZE(dk) <= 0xff ? \
1 : DK_SIZE(dk) <= 0xffff ? \
2 : DK_SIZE(dk) <= 0xffffffff ? \
4 : sizeof(int64_t))
#else
#define DK_IXSIZE(dk) \
(DK_SIZE(dk) <= 0xff ? \
1 : DK_SIZE(dk) <= 0xffff ? \
2 : sizeof(int32_t))
#endif
#define DK_ENTRIES(dk) \
((PyDictKeyEntry*)(&(dk)->dk_indices.as_1[DK_SIZE(dk) * DK_IXSIZE(dk)]))
看着这么多的东西,实际上它就做了两件事情,其一是根据hash table的大小动态调整indices数组中的元素的数据类型;其二是将dk_entries数组中的首地址取出赋值给ep0. 是不是突然就简单了? OK我们接着聊,接下来将hash这个变量和mask做了一个 “与” 的操作,这样就将key在哈希表中的位置计算出来。我们知道哈希值是一个非常大的数字,而hash table的大小可能远远没有这么大,因此将两者做一个 “与” 运算可就能将结果映射到表的大小以内了。需注意计算迟来的结果仅仅是indices这个数组中的位置而非键值对的数组的位置,在上面我们已经分析过了。接着就开始通过dk_get_index()这个函数作用是根据上述步骤计算出来的值,在dk_entries数组中找到所对应的键值对在数组中的位置索引。它的具体实现我们就不赘述了,很简单,有兴趣可以参考源码。
继续回到lookdict()函数中,由于我已经在代码中对一些重要的地方做了注释,因此我接下来只是阐述整个函数所做的操作而不再详细地分析。OK,当计算出该key所对应的hash table的索引 ix 后,如果其值为 DKIX_EMPTY,也就是说该entry处于unused态,则搜索失败。则记录下该entry对象在indices数组中的位置,表示它是一个立即可用的entry,并返回DKIX_EMPTY. 如果该entry处于dummy态,则标记该entry在indices数组中的位置,这里用freeslot变量,这个freeslot变量就是用来记录探测链上可用的entry. 如果该entry处于active态,则将指定的key和待搜索的key做比较,如果相同则将该entry中的值取出,并标记它在哈希表中的位置并返回索引。注意,这里的相同有两个衡量标准,一是它们是同一个对象也就是它们的地址是相同的,二是它们不是同一个对象但是它们的 “值” 是相等的。因此总结起来探测过程如下步骤:
- 通过哈希值来获取探测链上第一个entry的索引
- 当满足两种情况结束搜索
- 如果冲突链上该entry助于unused态,搜索完成,表明搜索失败
- 如果该entry处于active态,且它们的key为同一个对象 - 如果该entry处于dummy态,则设置freeslot
- 检查处于active态的entry的key与待检查的key是否 “值” 相等,如果相等则搜索成功
当探测链上第一个entry的key与待查找的key不匹配时,会继续遍历下一个entry,其方式一样,也就是代码中的for语句代码块,我们也来看看它的步骤 - 根据探测函数,获取下一个待探测的entry
- 当检查到处于unused态的entry时,有两种情况:一是freeslot没有被标记,则将新计算出来的位置标记;二是freeslot已经标记过了,则直接将之前的freeslot标记。
- 检查处于active态的entry的key是否 “相同” (两个衡量标准)
- 如果有处于dummy态的entry,且没有被标记则设置freeslot.
花了好大功夫终于说完了搜索原理了,需要注意的是,搜索几乎涵盖了字典的很多操作,插入,删除都离不开它,都是给予此基础上的。因此,写下俩的内容我会尽量简单地阐述,因为现在已经一万三千多字了,太多了(捂脸)。 -
3.4 PyDictObject的元素插入
插入操作也是需要通过搜索来实现的,在内部通过insertdict()函数来实现,我们来看看它的源码
dictobject.c
static int
insertdict(PyDictObject *mp, PyObject *key, Py_hash_t hash, PyObject *value)
{
PyObject *old_value;
PyObject **value_addr;
PyDictKeyEntry *ep, *ep0;
Py_ssize_t hashpos, ix;
// 增加key和value的引用计数
Py_INCREF(key);
Py_INCREF(value);
// 检查key和value是否合法
if (mp->ma_values != NULL && !PyUnicode_CheckExact(key)) {
if (insertion_resize(mp) < 0)
goto Fail;
}
// 调用dk_lookup()函数搜索
// 若在搜索过程中发生错误
ix = mp->ma_keys->dk_lookup(mp, key, hash, &value_addr, &hashpos);
if (ix == DKIX_ERROR)
goto Fail;
// 检查函数指针
assert(PyUnicode_CheckExact(key) || mp->ma_keys->dk_lookup == lookdict);
MAINTAIN_TRACKING(mp, key, value);
/* When insertion order is different from shared key, we can't share
* the key anymore. Convert this instance to combine table.
*/
// 检查共享的key,是否对哈希表扩容
if (_PyDict_HasSplitTable(mp) &&
((ix >= 0 && *value_addr == NULL && mp->ma_used != ix) ||
(ix == DKIX_EMPTY && mp->ma_used != mp->ma_keys->dk_nentries))) {
if (insertion_resize(mp) < 0)
goto Fail;
find_empty_slot(mp, key, hash, &value_addr, &hashpos);
ix = DKIX_EMPTY;
}
// 如果lookdict搜索结果失败则代表该entry是一个unused态,即该位置可以插入
if (ix == DKIX_EMPTY) {
/* Insert into new slot. */
// 对哈希表扩容
if (mp->ma_keys->dk_usable <= 0) {
/* Need to resize. */
if (insertion_resize(mp) < 0)
goto Fail;
find_empty_slot(mp, key, hash, &value_addr, &hashpos);
}
// 如果不需要扩容
// 取出哈希表中可用的entry的地址
ep0 = DK_ENTRIES(mp->ma_keys);
ep = &ep0[mp->ma_keys->dk_nentries];
// 设置索引,将该entry在哈希表中的索引,存储在dk_indices数组中的指定位置
// 设置entry中的key并缓存哈希值避免重复计算
dk_set_index(mp->ma_keys, hashpos, mp->ma_keys->dk_nentries);
ep->me_key = key;
ep->me_hash = hash;
// 如果这张表是一张split 表
if (mp->ma_values) {
assert (mp->ma_values[mp->ma_keys->dk_nentries] == NULL);
mp->ma_values[mp->ma_keys->dk_nentries] = value;
}
// 否则这是一张combined表
else {
ep->me_value = value;
}
mp->ma_used++;
mp->ma_version_tag = DICT_NEXT_VERSION();
mp->ma_keys->dk_usable--;
mp->ma_keys->dk_nentries++;
assert(mp->ma_keys->dk_usable >= 0);
assert(_PyDict_CheckConsistency(mp));
return 0;
}
assert(value_addr != NULL);
// 该entry为active态
// 将原来的value值取出
// 将新的值放入该entry的value中
old_value = *value_addr;
if (old_value != NULL) {
*value_addr = value;
mp->ma_version_tag = DICT_NEXT_VERSION();
assert(_PyDict_CheckConsistency(mp));
Py_DECREF(old_value); /* which **CAN** re-enter (see issue #22653) */
Py_DECREF(key);
return 0;
}
/* pending state */
assert(_PyDict_HasSplitTable(mp));
assert(ix == mp->ma_used);
*value_addr = value;
mp->ma_used++;
mp->ma_version_tag = DICT_NEXT_VERSION();
assert(_PyDict_CheckConsistency(mp));
Py_DECREF(key);
return 0;
Fail:
// 插入失败则将key和value的引用计数减少
Py_DECREF(value);
Py_DECREF(key);
return -1;
}
我在代码中也进行了详细的注释,所以在这里我尽可能简单地叙述。在插入一个entry时,也就是在字典中进行插入操作,会首先调用搜索函数,如果搜索函数通过哈希映射找到一个unused态的entry,则直接插入即可,并将哈希表中的该entry的索引存储在索引数组indices中;如果搜索函数找到一个处于active态的entry则直接将原来的值替换掉即可。其实我们可以看见,整个过程最主要的还是依赖于搜索函数,所以对前面所讲的搜索函数它的原理一定要非常清楚。叙述虽然简单,但是其中的细节与处理过程,可参考代码中的注释。
在调用insertdict函数时,传入了一个哈希值,这个哈希值是在什么地方生成的呢?它实际上是在PyDict_SetItem()函数中生成的,其原型如下所示。
dictobject.c
int PyDict_SetItem(PyObject *op, PyObject *key, PyObject *value)
{
PyDictObject *mp;
Py_hash_t hash;
// 类型检查以及key和value的合法性
// .......
if (!PyUnicode_CheckExact(key) ||
(hash = ((PyASCIIObject *) key)->hash) == -1)
{
hash = PyObject_Hash(key);
if (hash == -1)
return -1;
}
return insertdict(mp, key, hash, value);
}
原来如此,在这个函数内部会先通过PyObject_Hash()函数生成一个哈希值,然后再将这个哈希值通过参数传递给insertdict()函数。
在插入操作中,当dk_usable<=0时,也就是说明此时dict中的item数量达到了总容量的2/3,此时需要对dict扩容,也就是对哈希表扩容啦。那么对于dict的内部内存如何管理的呢?在内部通过调用insertion_resize()函数来实现,其原型如下
dictobject.c
#define GROWTH_RATE(d) (((d)->ma_used *2) + ((d)->ma_keys->dk_size >> 1))
static int
insertion_resize(PyDictObject *mp)
{
return dictresize(mp, GROWTH_RATE(mp));
}
可以看到在函数内部间接调用了dictresize()函数,它需要传递两个参数,其中一个是增长率,这个宏实际上就是将dict中的item数量乘以2再和哈希表的大小的1/2做一个加运算。
dictobject.c
static int dictresize(PyDictObject *mp, Py_ssize_t minsize)
{
Py_ssize_t i, newsize;
PyDictKeysObject *oldkeys;
PyObject **oldvalues;
PyDictKeyEntry *ep0;
/* Find the smallest table size > minused. */
// 根据增长率找到最小的哈希表的大小
for (newsize = PyDict_MINSIZE;
newsize < minsize && newsize > 0;
newsize <<= 1)
;
if (newsize <= 0) {
PyErr_NoMemory();
return -1;
}
// 将原PyDictObject对象的keys和values赋值给变量
oldkeys = mp->ma_keys;
oldvalues = mp->ma_values;
/* Allocate a new table. */
// 根据计算出来的哈希表的新大小在分配新的内存用以创建keys对象
mp->ma_keys = new_keys_object(newsize);
// 如果内存分配失败则将原来的keys重新赋值给ma_keys
// 注意,这里所有的赋值都是指针赋值
// 并返回一个负值表示扩容失败
if (mp->ma_keys == NULL) {
mp->ma_keys = oldkeys;
return -1;
}
// New table must be large enough.
// 新的表必须满足可用的值大于等于已经使用的值
assert(mp->ma_keys->dk_usable >= mp->ma_used);
if (oldkeys->dk_lookup == lookdict)
// 将搜索的函数指针赋值给dk_lookup
mp->ma_keys->dk_lookup = lookdict;
// 将ma_value指针置为NULL
// 取出原哈希表中存储键值对的内存的地址赋值给ep0
mp->ma_values = NULL;
ep0 = DK_ENTRIES(oldkeys);
/* Main loop below assumes we can transfer refcount to new keys
* and that value is stored in me_value.
* Increment ref-counts and copy values here to compensate
* This (resizing a split table) should be relatively rare */
if (oldvalues != NULL) { // 原表为split表
for (i = 0; i < oldkeys->dk_nentries; i++) {
if (oldvalues[i] != NULL) {
Py_INCREF(ep0[i].me_key);
// 则将原表中的值copy到新表也就是combined表中
ep0[i].me_value = oldvalues[i];
}
}
}
/* Main loop */
// 原表如果是combined表则调用insertdict_clean进行搬运操作
for (i = 0; i < oldkeys->dk_nentries; i++) {
PyDictKeyEntry *ep = &ep0[i];
if (ep->me_value != NULL) {
insertdict_clean(mp, ep->me_key, ep->me_hash, ep->me_value);
}
}
mp->ma_keys->dk_usable -= mp->ma_used;
if (oldvalues != NULL) {
/* NULL out me_value slot in oldkeys, in case it was shared */
for (i = 0; i < oldkeys->dk_nentries; i++)
ep0[i].me_value = NULL;
DK_DECREF(oldkeys);
if (oldvalues != empty_values) {
free_values(oldvalues);
}
}
else {
assert(oldkeys->dk_lookup != lookdict_split);
assert(oldkeys->dk_refcnt == 1);
DK_DEBUG_DECREF PyObject_FREE(oldkeys);
}
return 0;
}
如果需要扩容则我们必须先确定扩容后的哈希表的大小,这里根据增长率先确定哈希表的大小。在确定了哈希表大小后,为新的哈希表分配内存并创建PyDictKeysObject对象,如果内存分配失败则将PyDictObject对中的ma_keys指回原来的内存地址。如果分配成功,下一步就是进行内存的搬运工作,将原来的数据搬运到新开辟的内存中。这里需要注意的是在搬运时,之copy那些处于active态的entry而对于那些处于dummy态的entry则直接丢弃,因为dummy的存在是为了保证探测链的连续性,当所有的active态的entry都已经搬运到新内存中后就形成了一条新的探测链,原来的探测链就不需要了,此外如果原表指向堆内存的一片区域还需要释放掉,否则会造成内存泄漏。
-
3.5 PyDictObject元素删除操作
当你明白插入元素的底层实现后,举一反三你应该也大致清楚,删除时大概的操作了。其实我觉得我应该都可以不用讲了,但是为了让文章更加完整,我还是说说吧。删除操作是通过PyDictDelItem()函数来实现的,先计算key的哈希值,内部再间接调用了_PyDict_DelItem_KnownHash()函数,这个函数真正实现了删除操作,show code
dictobject.c
int
_PyDict_DelItem_KnownHash(PyObject *op, PyObject *key, Py_hash_t hash)
{
Py_ssize_t hashpos, ix;
PyDictObject *mp;
PyObject **value_addr;
if (!PyDict_Check(op)) {
PyErr_BadInternalCall();
return -1;
}
assert(key);
assert(hash != -1);
mp = (PyDictObject *)op;
ix = (mp->ma_keys->dk_lookup)(mp, key, hash, &value_addr, &hashpos);
if (ix == DKIX_ERROR)
return -1;
if (ix == DKIX_EMPTY || *value_addr == NULL) {
_PyErr_SetKeyError(key);
return -1;
}
assert(dk_get_index(mp->ma_keys, hashpos) == ix);
// Split table doesn't allow deletion. Combine it.
if (_PyDict_HasSplitTable(mp)) {
if (dictresize(mp, DK_SIZE(mp->ma_keys))) {
return -1;
}
ix = (mp->ma_keys->dk_lookup)(mp, key, hash, &value_addr, &hashpos);
assert(ix >= 0);
}
return delitem_common(mp, hashpos, ix, value_addr);
}
我靠,终于见到少点的代码了,少吗?实际上也不少,因为内部还有很多间接调用 (捂脸) 。同样内部先进行一系列的类型检查。调用搜索函数沿着探测链探测,如果发现存在unused态的entry,则返回错误值,说明key设置错误,未找到正确的entry. 如果是找到这个entry需要进行一个判断,如果此表是split表,他是不支持删除操作的,需要转换成combined表。可以看到最后又调用了一个delitem_common()函数。我们也来看看其原型
dictobject.c
static int
delitem_common(PyDictObject *mp, Py_ssize_t hashpos, Py_ssize_t ix,
PyObject **value_addr)
{
PyObject *old_key, *old_value;
PyDictKeyEntry *ep;
old_value = *value_addr;
assert(old_value != NULL);
*value_addr = NULL;
mp->ma_used--;
mp->ma_version_tag = DICT_NEXT_VERSION();
ep = &DK_ENTRIES(mp->ma_keys)[ix];
dk_set_index(mp->ma_keys, hashpos, DKIX_DUMMY);
ENSURE_ALLOWS_DELETIONS(mp);
old_key = ep->me_key;
ep->me_key = NULL;
Py_DECREF(old_key);
Py_DECREF(old_value);
assert(_PyDict_CheckConsistency(mp));
return 0;
}
在这个函数中,确定要删除这个item,先将ma_used的值减1,因为删除一个entry后,字典中的已经存在的item数量就少1,此外将字典版本减1. DK_ENTRIES(mp->ma_keys)这个宏是将PyDictKeysObject对象中的存储entry的数组的内存地址取出来然后通过搜索得到的索引,就可以定位到这个entry。通过调用dk_set_index()函数将此entry的状态设置为dummy态,并在哈希索引表中记录下。然后将key的值设置为NULL,并使原来的key和value的引用计数减少。是不是很简单?没错,当你搞清楚之前的原理,不用说你也能知道删除操作。花了这么大的篇幅终于讲完了。
4、PyDictObject对象缓冲池
在创建对象时,我们看到dict同样也使用了缓冲池的技术,实际上dict所用的缓冲池技术和list相同。
// dictobject.c
// ........
#define PyDict_MAXFREELIST 80
#endif
static PyDictObject *free_list[PyDict_MAXFREELIST];
static int numfree = 0;
static PyDictKeysObject *keys_free_list[PyDict_MAXFREELIST];
static int numfreekeys = 0;
可以看到PyDictObject对象和PyDictKeysObject对象都维护了一个缓冲池,其大小为80。它和list的缓冲池一样,开始时缓冲池中并没有任何对象。这里以PyDictObject为例讲解,当创建对象时,会先在缓冲池中查找是否有可用的对象,如果有则取出使用,如果没有则新创建一个对象。可是,缓冲池中的对象是什么时候放进去的呢?我想你也应该猜到了,没错,就是在对象被销毁时。对象被销毁时会调用dict_dealloc()函数,其原型如下所示。
dictobject.c
static void
dict_dealloc(PyDictObject *mp)
{
PyObject **values = mp->ma_values;
PyDictKeysObject *keys = mp->ma_keys;
Py_ssize_t i, n;
/* bpo-31095: UnTrack is needed before calling any callbacks */
PyObject_GC_UnTrack(mp);
Py_TRASHCAN_SAFE_BEGIN(mp)
if (values != NULL) {
if (values != empty_values) {
for (i = 0, n = mp->ma_keys->dk_nentries; i < n; i++) {
Py_XDECREF(values[i]);
}
free_values(values);
}
DK_DECREF(keys);
}
else if (keys != NULL) {
assert(keys->dk_refcnt == 1);
DK_DECREF(keys);
}
if (numfree < PyDict_MAXFREELIST && Py_TYPE(mp) == &PyDict_Type)
free_list[numfree++] = mp;
else
Py_TYPE(mp)->tp_free((PyObject *)mp);
Py_TRASHCAN_SAFE_END(mp)
}
在销毁一个dict对象时,底层函数主要做了几件事。第一,检查此dict对象中的哈希表是否为一张split表,如果是则将ma_value数组中的元素对象的引用计数减少,并通过调用freevalue()函数,这个函数是通过宏定义的python/c API中的Py_MEM_FREE()来释放在对内存中申请的内存块。然后通过DK_DECREF()这个宏来处理PyDictKeysObject对象,这个宏的定义如下
#define DK_DECREF(dk) if (DK_DEBUG_DECREF (–(dk)->dk_refcnt) == 0) free_keys_object(dk)
可以看到最后也会通过调用free_keys_object()函数来释放keys对象的空间。接着会检查缓冲池中的对象数量是否超过阈值,如果没有超过则将这个PyDictObject对象放入到缓冲池中,如果超过了则直接将这块内存释放归还给系统。
因此我们可以看出,整个对象缓冲池的机制和list几乎一样,缓冲池中仅仅保存了PyDictObject对象,而它里面所维护的哈希表的内存已经被释放掉归还给系统了。对于keys对象也是一样的道理。所以我们能得出一个结论,无论是PyDictObject对象还是PyDictKeysObject对象,缓冲池中存储的仅仅是这个对象本身。
终于写完了一共两万多字的解析,花了很多时间和精力研究源码终于也算是弄清楚了底层的原理,当然这只是一部分,字典的功能相当丰富,其底层实现也大同小异,有兴趣可以去看其他部分的底层实现。创作不易,希望能帮助到你,如有错误还请指出!