集成学习结合策略之——stacking
1.stacking思想
基本思想:
将各个弱学习器的学习成果,并行结合起来,形成以预测值(标签)为数据的训练集,用来训练下一层学习器。
实例:
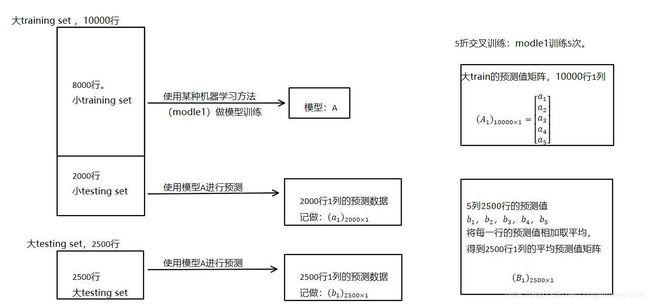
假设我们整个training set包含10000行数据,testing set包含2500行数据,那么每一次交叉验证其实就是对training set进行划分,在每一次的交叉验证中training data将会是8000行,testing data是2000行。
 stacking 思想举例
stacking 思想举例
每一次的交叉验证包含两个过程:
1. 基于training data训练模型;
2. 基于training data训练生成的模型对testing data进行预测。
在整个第一次的交叉验证完成之后我们将会得到关于当前testing data的预测值,这将会是一个一维2000行的数据,记为a1。注意!在这部分操作完成后,我们还要对数据集原来的整个testing set进行预测,这个过程会生成2500个预测值,这部分预测值将会作为下一层模型testing data的一部分,记为b1。因为我们进行的是5折交叉验证,所以以上提及的过程将会进行五次,最终会生成针对testing set数据预测的5列2000行的数据a1,a2,a3,a4,a5,对testing set的预测会是5列2500行数据b1,b2,b3,b4,b5。
在完成对Model1的整个步骤之后,我们可以发现a1,a2,a3,a4,a5其实就是对原来整个training set的预测值,将他们拼凑起来,会形成一个10000行一列的矩阵,记为A1。而对于b1,b2,b3,b4,b5这部分数据,我们将各部分相加取平均值,得到一个2500行一列的矩阵,记为B1。
以上就是stacking中一个模型的完整流程,stacking中同一层通常包含多个模型,假设还有Model2: LR,Model3:RF,Model4: GBDT,Model5:SVM,对于这四个模型,我们可以重复以上的步骤,在整个流程结束之后,我们可以得到新的A2,A3,A4,A5,B2,B3,B4,B5矩阵。
在此之后,我们把A1,A2,A3,A4,A5并列合并得到一个10000行五列的矩阵作为training data,B1,B2,B3,B4,B5并列合并得到一个2500行五列的矩阵作为testing data。让下一层的模型,基于他们进一步训练。
 新数据集_用于训练第二层学习器
新数据集_用于训练第二层学习器
2.python实现
集成学习代码:https://github.com/log0/vertebral/blob/master/stacked_generalization.py
# coding=utf8
from sklearn import datasets
from sklearn.ensemble import RandomForestClassifier, ExtraTreesClassifier, GradientBoostingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.model_selection import StratifiedKFold
import numpy as np
from sklearn.metrics import roc_auc_score
from sklearn.datasets.samples_generator import make_blobs
from sklearn import metrics
'''创建数据集'''
# X为样本特征矩阵,行数为样本数(n_samples),列数为特征数目(n_features默认2), ;Y为对应的标签值,center为2表示Y取值为0,1两类。
X, Y = make_blobs(n_samples=12500, n_features=5 ,centers=2, random_state=0, cluster_std=0.60)
print(X.shape)
print(Y.shape)
'''切分一部分数据作为测试集'''
# X_train为大训练集,X_test为大测试集。Y_train, Y_test为对应的标签
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.20, random_state=2017)
print("大训练集X_train大小:",X_train.shape)
print("大测试集X_test大小:",X_test.shape)
'''模型融合中使用到的各个单模型'''
clfs = [RandomForestClassifier(n_estimators=5, n_jobs=-1, criterion='gini'),
RandomForestClassifier(n_estimators=5, n_jobs=-1, criterion='entropy'),
ExtraTreesClassifier(n_estimators=5, n_jobs=-1, criterion='gini'),
ExtraTreesClassifier(n_estimators=5, n_jobs=-1, criterion='entropy'),
GradientBoostingClassifier(learning_rate=0.05, subsample=0.5, max_depth=6, n_estimators=5)]
'''生成0矩阵用来存放新的training set(10000*5),新的testing set(2500*5)'''
blend_train = np.zeros((X_train.shape[0], len(clfs)))
print("新训练集blend_train大小:",blend_train.shape)
blend_test = np.zeros((X_test.shape[0], len(clfs)))
print("新测试集blend_test大小:",blend_test.shape)
'''5折stacking'''
n_folds = 5
i=0
'''list() 方法用于将元组转换为列表。注:元组与列表是非常类似的,区别在于元组的元素值不能修改,元组是放在括号中,列表是放于方括号中。'''
skf = StratifiedKFold(n_folds)
print(skf)
for j, clf in enumerate(clfs):
'''依次训练各个单模型'''
print("模型",j, clf)
# blend_test_j相当于分析中的【b1,b2,b3,b4,b5】
# 大测试集行数x折叠次数,在稍后采用预测的平均值
blend_test_j = np.zeros((X_test.shape[0], n_folds))
print("储存【b1,b2,b3,b4,b5】的blend_test_j大小:",blend_test_j.shape)
for train_index, test_index in skf.split(X_train, Y_train):
'''使用第i个部分作为预测,剩余的部分来训练模型,获得其预测的输出作为第i部分的新特征。'''
print("第",i,"折")
# 生成小train,小test。X为样本(行)+特征(列)矩阵,y为标签向量
print("小TRAIN行编号:", train_index, "小TEST行编号:", test_index)
x_smatrain, y_smatrain, x_smatest, y_smatest = X_train[train_index], Y_train[train_index], X_train[test_index], Y_train[test_index]
print("生成的小train大小:",x_smatrain.shape)
print("生成的小test大小:",x_smatest.shape )
# 内循环,对小test进行预测,一个模型预测5次,组合得到【a1,a2,a3,a4,a5】(转置形成A1(10000*1)),就是这里的blend_train的1列。
'''循环完毕(5个模型*5次折叠),新的训练集blend_train=【A1,A2,A3,A4,A5】(10000*5)'''
clf.fit(x_smatrain, y_smatrain)
# 对小test进行预测,结果保存在新的训练集中,行号对应相应的小test的行号
blend_train[test_index, j] = clf.predict(x_smatest)
print("小test的预测结果矩阵a",i,"大小:",clf.predict(x_smatest).shape)
print("a", i, clf.predict(x_smatest))
print("模型",j,"对小test的预测结果矩阵blend_train 【A1,A2,A3,A4,A5】:", blend_train)
# 对大test进行预测,得到[b1,b2,b3,b4,b5]
blend_test_j[:, i] = clf.predict(X_test)
print("b",i,clf.predict(X_test))
print("模型",j,"对大test的预测结果矩阵blend_test_j [b1,b2,b3,b4,b5]:",blend_test_j)
i = (i + 1) % 5
'''取b1,b2,b3,b4,b5的均值形成Bj(外循环完毕形成新的测试集blend_test=【B1,B2,B3,B4,B5】(2500*5))'''
blend_test[:, j] = np.mean(blend_test_j, axis = 1)
print("大test的预测结果矩阵[B1,B2,B3,B4,B5]:",blend_test)
# clf = LogisticRegression()
# 接着用blend_train, Y_dev去训练第二层的学习器LogisticRegression
bclf = LogisticRegression()
bclf.fit(blend_train, Y_train)
# 用最终的强学习器进行预测
Y_test_predict = bclf.predict(blend_test)
score = metrics.accuracy_score(Y_test, Y_test_predict)
print("Accuracy = %s" % (score))
运行结果
Accuracy = 0.998