参考:https://blog.csdn.net/billbliss/article/details/78929304
https://blog.csdn.net/SoaringLee_fighting/article/details/81265865
一、arm通用指令
通用算术指令:
VABA:向量差值绝对值累加、VABD:向量差值绝对值、VABS:向量绝对值、VNEG:向量求反、
VADD、VADDW、VADDL、VSUB、VSUBL、VSUBW:向量加减,包括宽型、长型和窄型三种格式。
VPADD:将两个向量的相邻元素相加
如 VPADD.I16 {d2}, d0, d1

VPADDL:VPADDL.S16 d0, d1

VMAX:最大值,VMIN:最小值
VMUL、VMULL、VMLA(乘加)、VMLS(乘减)、
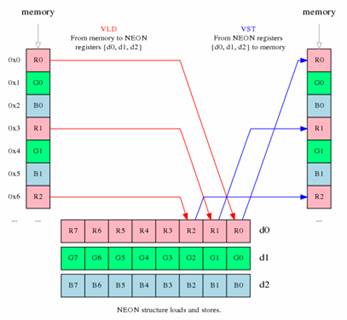
加载存储指令:
VLD和VST


交叉存取的示意图:
VREV反转元素指令:

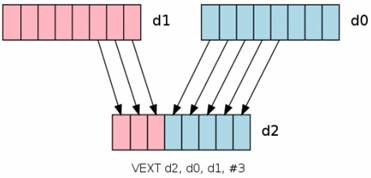
VEXT移位指令:
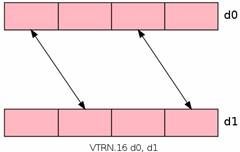
VTRN转置指令:可以用于矩阵的转置

VZIP指令:压缩,类似交叉存取

VUZP指令:解压操作,类似交叉存取

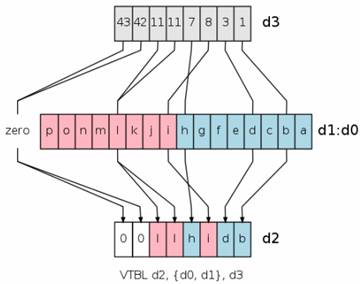
VTBL查表指令:从d0,d1中查找d3中的索引值,如果找到则取出,没有找到则为0,存入d2中
二、需要注意的地方
1、 load数据的时候,第一次load会把数据放在cache里面,只要不超过cache的大小,下一次load同样数据的时候,则会比第一次load要快很多,会直接从cache中load数据,这样在汇编程序设计的时候是非常需要考虑的问题。
如:求取一个图像的均值,8*8的窗口,先行求和,然后列求和出来均值,这时候会有两个函数,数据会加载两遍,如果按照这样去优化的话则优化不了多少。如果换成上面这种思路,先做行16行,然后再做列,这样数据都在cache里面,做列的时候load数据会很快。
2、在做neon乘法指令的时候会有大约2个clock的阻塞时间,如果你要立即使用乘法的结果,则就会阻塞在这里,在写neon指令的时候需要特别注意。乘法的结果不能立即使用,可以将一些其他的操作插入到乘法后面而不会有时间的消耗。
如:vmul.u16 q1, d3, d4
vadd.u32 q1, q2, q3
此时直接使用乘法的结果q1则会阻塞,执行vadd需要再等待2个clock的时间
3、使用饱和指令的时候,如乘法饱和的时候,在做乘法后会再去做一次饱和,所以时间要比直接做乘法要慢。
如: vmul.u16 q1, d3, d4
vqmul.u32 q1, q2, q3
后一个的时间要比第一个的时间要久。
4、在对16位数据进行load或者store操作的时候,需要注意的是字节移位。比如是16位数据,则load 8个16位数据,如果指定寄存器进行偏移,此时需要特别注意。
例如:vld1.64 {d0}, [r0], r1
5、去除数据之间的依赖
不要将当前指令的目的寄存器作为下一条指令的源寄存器。一般当前指令的运算结果会在下一条指令中使用,我们可以通过指令穿插避免数据依赖。
6、减少分支跳转
ARM处理器中广泛使用分支预测技术。但是一旦分支预测失败,性能就会损失很大。所以,
尽量不要用分支跳转!可以采用逻辑运算指令替代分支跳转!
比如:
VCEQ, VCGE, VCGT, VCLE, VCLT……
VBIT, VBIF, VBSL……
另外,可以使用条件执行指令,比如addgt,suble等减少分支跳转!
建议一次性多处理几行数据,从而减少循环跳转的次数,提升性能。