spark参数调优
spark参数调优
前言
为什么要发这篇文章呢?因为搞了半天,感觉这个更新换代很快啊~ 今天运行sparksql作业的时候,发现yarn上面的CPU资源,被占用完了,这™还搞个锤子并发嘛?
任务没有资源无法运行截图如下:
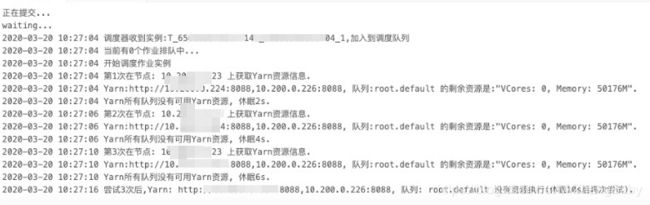
看了一下报错信息,原来是没有核数了~ 内存很充足~
怎么回事呢?才刚刚提了一个sparksql任务就给占满了?
排查过程
经过排查代码后发现,代码中开启了动态资源分配,代码片段如下:

原来这玩意儿不能随便加呀,不然资源都会动态没了~
解决方法
- 首先去掉代码中的参数配置
- 去掉集群中的动态资源配置(CDH集群)
- 修改spark-default配置文件,去除动态资源配置
相关截图如下:
在CDH集群界面上选择spark,点击配置,找到如下配合,勾勾去掉即可

配置文件修改参数为false
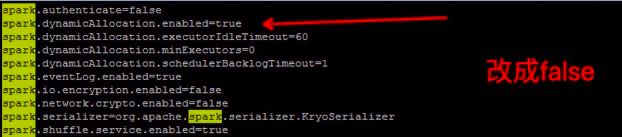
关闭完动态资源分配,下一步就是如何进行配置资源了?
如何进行资源调优呢?
首先配置指定相关的参数呢?可以参考官网: http://spark.apache.org/docs/2.3.0/configuration.html
but,我发现貌似有一些参数,官网上并没有,也不知道是俺找的地方不对,还是怎么滴~
调优比较多,后面抽空会完完整整的整理一份,针对于目前的问题,只需要调整cpu-core即可,如何调整呢?
下面先来看一个简单的任务提交并执行的流程吧:

也不准备详细说,就是简单的了解下,其中有几个资源消耗关键的地方:Driver、Executor(Task)
我们使用spark-submit提交一个Spark作业之后,这个作业就会启动一个对应的Driver进程。提交作业的节点称为Master节点,Driver进程就是开始执行你Spark程序的那个Main函数(Driver进程不一定在Master节点上)。根据你使用的部署模式(deploy-mode)不同,Driver进程可能在本地启动,也可能在集群中某个工作节点上启动。
Driver进程本身会根据我们设置的参数,占有一定数量的内存和CPU core。而Driver进程要做的第一件事情,就是向集群管理器申请运行Spark作业需要使用的资源,这里的资源指的就是Executor进程。YARN集群管理器会根据我们为Spark作业设置的资源参数,在各个工作节点Worker上,启动一定数量的Executor进程,每个Executor进程都占有一定数量的内存和CPU core。
那么就很清晰了,资源使用主要在Driver和Executor上面,那么我们调整参数就比较好调整了嘛?
首先Driver端,个人感觉直接按默认值即可,官网配置示例如下:
为什么呢?
因为大部分都不会去进行collect() 等一些方法,所以Driver端不需要占用太大的资源,当然资源充足的情况下,也可以扩大一倍,改为2、2、2即可
spark.driver.cores |
1 | Number of cores to use for the driver process, only in cluster mode. |
spark.driver.maxResultSize |
1g | Limit of total size of serialized results of all partitions for each Spark action (e.g. collect) in bytes. Should be at least 1M, or 0 for unlimited. Jobs will be aborted if the total size is above this limit. Having a high limit may cause out-of-memory errors in driver (depends on spark.driver.memory and memory overhead of objects in JVM). Setting a proper limit can protect the driver from out-of-memory errors. |
spark.driver.memory |
1g | Amount of memory to use for the driver process, i.e. where SparkContext is initialized, in MiB unless otherwise specified (e.g. 1g, 2g).Note: In client mode, this config must not be set through the SparkConf directly in your application, because the driver JVM has already started at that point. Instead, please set this through the --driver-memory command line option or in your default properties file. |
那么下面就来唠一下Executor资源参数配置?下面首先看下官网的配置:
| Property Name | Default | Meaning |
|---|---|---|
spark.executor.memory |
1g | Amount of memory to use per executor process, in MiB unless otherwise specified. (e.g. 2g, 8g). |
spark.executor.cores |
1 in YARN mode, all the available cores on the worker in standalone and Mesos coarse-grained modes. | The number of cores to use on each executor. In standalone and Mesos coarse-grained modes, for more detail, see this description. |
spark.default.parallelism |
For distributed shuffle operations like reduceByKey and join, the largest number of partitions in a parent RDD. For operations like parallelize with no parent RDDs, it depends on the cluster manager: Local mode: number of cores on the local machine Mesos fine grained mode: 8 Others: total number of cores on all executor nodes or 2, whichever is larger |
Default number of partitions in RDDs returned by transformations like join, reduceByKey, and parallelize when not set by user. |
spark.cores.max |
(not set) | When running on a standalone deploy cluster or a Mesos cluster in "coarse-grained" sharing mode, the maximum amount of CPU cores to request for the application from across the cluster (not from each machine). If not set, the default will be spark.deploy.defaultCores on Spark's standalone cluster manager, or infinite (all available cores) on Mesos. |
在官网上貌似就找到这些设置cores,memory的一些参数,那么有一个问题就是?我怎么去指定executor的个数呢?
好像没有这个参数哎?慌不慌?我是没看到,不知道在哪,可能找的地方不对吧~
然后搜了一波,发现了下面这两种参数,加上官网看起来有点像的参数 spark.cores.max,那就是三种如下
set spark.executor.instances = 8;
set spark.num.executors = 4;
set spark.cores.max = 12;某位博主的博客说是这样的:

然后我就开始设置,总核数和单个executor的核数,发现不生效!!!
然后我就又开始设置一个参数,那就是 set spark.num.executors = 4; 来指定executor的个数,发现还是不生效!!!
心态崩了呀,怎么™都不生效???那我怎么搞?
然后继续搜,如何制定executor的个数,发现了一篇博客写这个参数,spark.executor.instance 在spark-default的配置文件中,用来制定executor的个数,测试后发现,executor的个数发生了改变,成功啦!!!
后来发现貌似 ”--num-executors“ 这个参数也是生效的,在使用spark-submit命令时,添加“--num-executors NUM”参数设置Executor个数。因为什么呢?输入spark-submit --help 即可看到:



look 一下 参数在这里,你说怎么说,气不气?好像这两个参数指定也是生效的,但是不能再代码里面进行set key = value;
不知道为什么官网并没有这些参数的说明,不知道为啥,反正问题解决了就行,就先这样吧~
知道的大佬,也可以不吝指教咯~