MySQL
MysSQL
Mysql笔记:
什么是数据库:存储和管理数据的仓库(给你一堆数据给它存起来)
常见的数据库
Oracle适用于大型企业领域
DB2—适用于大中型企业领域
Mysql—开源,适用于中小型企业领域(公司一般用它,因为免费)
Sql server—适用于中小型企业领域
mySql主要功能:增删改查
ctrl+R 运行所有
ctrl+shif+R 选中那行执行
MySql 三种注释写法:
单行注释:
– 这种注释两个横杆后面要加一个空格
ctrl + /
多行注释:
/* 注释信息 */
专业术语
(一)表:具有固定的列数和任意的行数组成,跟excel里面一样
(二)列:指的是字段
(三)行:指的是记录
(四)数据库:数据库是一些关联表的集合
(五)主键:主键是唯一的,一个数据表中只能包含一个主键,如[用户id]
(六)外键:用于关联表
(七)索引:索引用于快速找出在某个列中有一特定值的行,不使用索引,MySQL必须从第一条记录开始读完整个表,直到找出相关的行,表越大,查询数据所花费的时间就越多,如果表中查询的列有一个索引,MySQL能够快速到达一个位置去搜索数据文件,而不必查看所有数据,那么将会节省很大一部分时间。
MysSQL语句
show databases; 显示数据库列表
CREATE DATABASE 数据库名; 创建数据库
use 数据库名;-进入数据库
DROP DATABASE 数据库名;删除数据库
创建表:
CREATE TABLE 表名()
show TABLEs;显示当前数据库里的表
DESC 表名;查看表字段信息
IF EXISTS 为可选,判断是否存在,如果存在就删除,如果不存在可以避免错误提示
ALTER TABLE 表名 add 列名 类型(长度) 添加一列
ALTER TABLE 表名 MODIFY 列名 类型(长度) 修改一个表的字段类型
ALTER TABLE 表名 CHANGE 原始列名 新列名 数据类型(长度)修改列名
Insert into 表名(列名1,列名2,…) value(列值1,列值2,…) 插入单条数据
Insert into 表名(列名1,列名2,…) value(列值1,列值2,…) ,(列值1,列值2,…) 插入多条数据
Insert into 表名 value(跟你表的字段一样就可以,不可缺省) 插入所有字段
Drop table 表名 删除表
Alter table 表名 drop 字段名 删除表一列
Select * from 表名 查询表中所有数据
Select 列名1,列名2…from 表名 查询指定列数据
条件查询:
条件查询就是在查询时给出where子句,在where子句中可以使用一些运算符及关键字,写在 from 表名 后面
条件查询运行符及关键字
=(等于),!=(不等于),<>(不等于),<(小于),<=(小于等于),>=(大于等于),>(大于)
between…and 值在什么范围
In(值)在什么里面
is null 为空 , is not null 不为空
And 与 , or 或 , not非
sql语句优化
SQL语句优化有哪些方法
(1)Where子句中:where表之间的连接必须写在其他Where条件之前,那些可以过滤掉最大数量记录的条件必须写在Where子句的末尾.HAVING最后。
(2)用EXISTS替代IN、用NOT EXISTS替代NOT IN。
(3) 避免在索引列上使用计算
(4)避免在索引列上使用IS NULL和IS NOT NULL
(5)对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。
(6)应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描
(7)应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描
连接俩个结果
union ALL
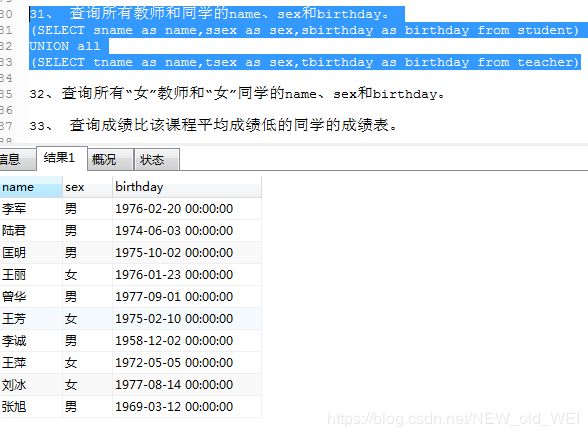
31、 查询所有教师和同学的name、sex和birthday。
(SELECT sname as name,ssex as sex,sbirthday as birthday from student) #学生
UNION all
(SELECT tname as name,tsex as sex,tbirthday as birthday from teacher) #老师
模糊查询:
使用like关键字后跟通配符,进行模糊查询
通配符:
① ”__”下划线是任意一个字符
② ”%“ 百分号就任意0~n个字符
例: like ‘金_’ 第一个字符是金字的两个字的信息
show databases; -- 显示数据库列表
CREATE DATABASE 数据库study;-- 创建数据库
use 数据库study;-- 进入数据库
DROP DATABASE 数据库study;-- 删除数据库
创建表:
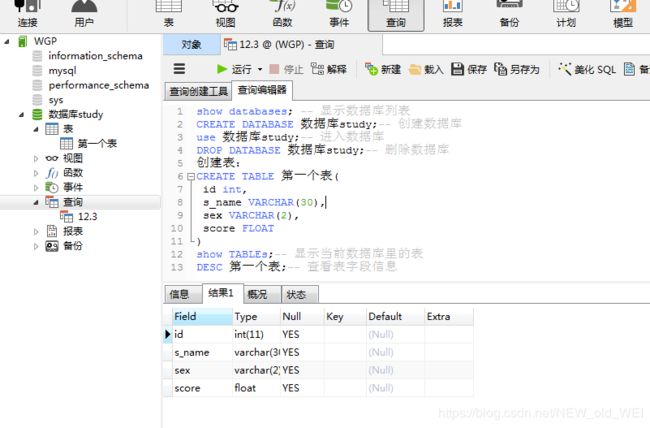
CREATE TABLE 第一个表(
id int,
s_name VARCHAR(30),
sex VARCHAR(2),
score FLOAT
)
show TABLEs;-- 显示当前数据库里的表
DESC 第一个表;-- 查看表字段信息
-------------------------------------
SELECT 列名 选择那些列显示 *代表所有
from 表名 从何处选择行
where 条件... 行满足什么条件
GROUP BY 列名 怎样对结果分组
having 条件... 行必须满足的第二条件
ORDER BY 列名 怎样对结果排序
LIMIT m,n 结果限定 m+1 ~~~~ n
SELECT 语句的执行顺序
FROM
where
GROUP BY
计算聚合
HAVING
计算表达式
ORDER BY
LIMIT
SELECT
group by 对什么列进行分组
order by 排序
asc 升序
desc 倒序
LIMIT 几个 显示倒序几个
LIMIT 2,3 从第2个开始取3个
#子查询
所有的子查询必须在括号里
SELECT 可以使用子查询 ——只能返回一列
FROM 可以使用子查询 ——子查询必须起别名
WHERE 可以使用子查询--只能返回一列
group by
order by
limit
ROUND(数据,保留几位小数)
保留几位小数
#聚合函数
SELECT var_pop(列名) from tablename #指定列的总体方差
SELECT VAR_SAMP(列名) from tablename #指定列的样本方差
SELECT STDDEV_POP(列名) from tablename #指定列的总体标准差
SELECT STDDEV_SAMP(列名) from tablename #指定列的样本标准差
#数学函数
#ABS 绝对值函数
#ceiling 天花板整数,也就是大于x最小的整数
select CEILING(2.3) #roundup
#FLOOR(X)小于x的最大整数
select FLOOR(2.9) #rounddown
#EXP(X)自然对数e为底的x次方
select exp(2)
#返回集合中最大的值,least返回最小的,注意跟max,min不一样,max里面跟的是col,返回这个列的最大值最小值
select GREATEST(1,2,3,4)
select qa3,qa4,qa8,GREATEST(qa3,qa4,qa8),LEAST(qa3,qa4,qa8) from ccss_sample
#ln(x)返回对数
SELECT ln(10)
SELECT exp(ln(10))
#log(x,y),以x为底y的对数
select log(10,100)
#mod(x,y)返回x/y的余数
select mod (5,2)
#pi() 返回pi
select pi()
#RAND()返回0,1之间随机数
select rand()
#round(x,y)返回x四舍五入有y位小数的值
select round(4.6,0)
select round(2.3473,2)
#sign(x) 返回x符号
select sign(-5)
#sqrt(x)返回x的平方根
select SQRT(4)
#truncate(x,y) 返回数字x截断为y位小数的结果,就是不考虑四舍五入,直接砍掉
select TRUNCATE(4.67,1) #截断取整,不四舍五入
#冗余:冗余降低了性能,但提高了数据的安全性。
#主键:主键是唯一的。一个数据表中只能包含一个主键。你可以使用主键来查询数据。
#外键:外键用于关联两个表。
外键约束种类
NULL、RESTRICT、NO ACTION
删除:从表记录不存在时,主表才可以删除。删除从表,主表不变
更新:从表记录不存在时,主表才可以更新。更新从表,主表不变
CASCADE(级联删除)
删除:删除主表时自动删除从表。删除从表,主表不变
更新:更新主表时自动更新从表。更新从表,主表不变
SET NULL
删除:删除主表时自动更新从表值为NULL。删除从表,主表不变
更新:更新主表时自动更新从表值为NULL。更新从表,主表不变 */
表关联
UNION ALL 对同结构的数据进行直接连接,不去重
UNION 对同结构的数据进行直接连接,去重
#left join 以 join 左边的表为主,右表做补充,没有填NULL
SELECT * from student left join sc on sc.sid = student.sid
#RIGHT join 以 join 右边的表为主,左表做补充,没有填NULL
SELECT * from student RIGHT join sc on sc.sid = student.sid
#inner join 左右表同时的关联内容同时存在时才查出结果(交集)
SELECT * from student inner join sc on sc.sid = student.sid
#outer join 左右表并集
SELECT * from student left join sc on sc.sid = student.sid
UNION
SELECT * from student RIGHT join sc on sc.sid = student.sid
备份
#创建表
CREATE table newtable(字段1 类型 长度...)
-- 创建一个结构和老表一样的新表
CREATE table newtable like oldtable
CREATE table newtable AS #对数据表进行备份
SELECT 语句
#插入
INSERT oldtable(字段名1....)
VALUES(值......)
INSERT oldtable(字段名1....)
VALUES(值......),(值......)
INSERT oldtable(字段名1.....)
SELECT 语句 #查询结果与列名一定要一一匹配
-- 备份一个表ccss_sample 框架 命名cc_bak
CREATE TABLE cc_bak like ccss_sample
SELECT * from ccss_sample
SELECT * from cc_bak
SELECT * from ccss_sample#显示原表
SELECT * from cc_bak#显示备份的表
-- 先查询想要插入的数据 然后和 INSERT cc_bak 插入备份表一起运行
INSERT cc_bak (城市,性别 )
SELECT 城市,性别 from ccss_sample WHERE id>10 and id <12
INSERT cc_bak
SELECT * from ccss_sample LIMIT 2
DELETE from cc_bak where id=1 #s删除表里数据 加where进行条件限制
DROP TABLE cc_bak #删除整个表
#WHERE
#比较运算符 > < >= <= <>或!=
#逻辑运算 and or NOT
#特殊
like % _
in(值1,值2) not in(值1,值2)
BETWEEN 开始值 and 结束值
is null is not NULL
drop table 表名 #直接删除表
drop table if EXISTS 表名 #if EXISTS 判断是否存在
#修改表结构
#1 添加列
ALTER table 表名 add 列名 类型 长度
ALTER table test add city VARCHAR(20);
#2 删除一列
ALTER table 表名 drop 列名
ALTER table test drop city;
#3更改类型
ALTER TABLE 表名 MODIFY 列名 新类型
alter table test MODIFY age VARCHAR(10);
#修改表数据
UPDATE 表名 set 字段名1=新值1,字段名2=新值2,... where 条件修改
#where 使用与delete SELECT 的where 一样
用于处理字符串的函数
合并字符串函数:concat(str1,str2,str3…) 类似于excel &,
CONCAT_WS(separator,str1,str2,...) 以指定的分隔符进行连接
比较字符串大小函数:strcmp(str1,str2)
获取字符串字节数函数:length(str) 类似excel lenb ,char_length(str) 类似excel len
字母大小写转换函数:大写:upper(x),ucase(x);小写lower(x),lcase(x)
字符串查找函数 LOCATE(要找谁,从哪各字段找)、POSITION(要找谁 IN 从哪各字段找)、INSTR(从哪各字段找,要找谁)
获取指定位置的子串 SUBSTRING(s,n,len)、MID(s,n,len),SUBSTR,LEFT(sname,1) RIGHT(str,len)
字符串去空函数: TRIM([remstr FROM] str) 默认去空格,LTRIM(s)、RTRIM(s)
字符串替换函数:REPLACE(列名,要替换掉的值,新值)
字符串截取:LEFT(sname,1) RIGHT(str,len)
#SELECT 条件语句
case when 条件1 then 条件真
when 条件2 then 条件真
else 条件假
END
case 字段名 when 值1 then 条件真
when 值1 then 条件真
else 条件假
END
更改储存路径
指令导出查询结果
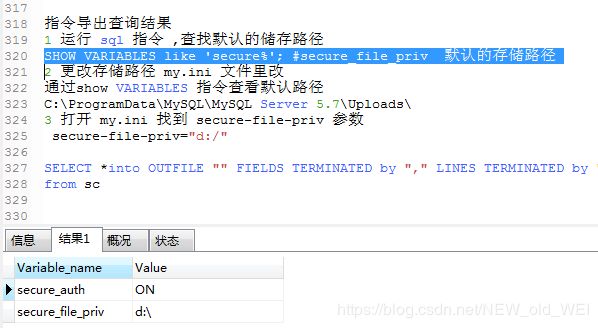
1 运行 sql 指令 ,查找默认的储存路径
SHOW VARIABLES like 'secure%'; #secure_file_priv 默认的存储路径
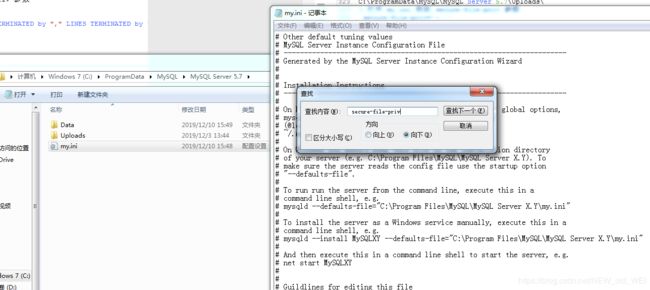
2 更改存储路径 my.ini 文件里改
通过show VARIABLES 指令查看默认路径
C:\ProgramData\MySQL\MySQL Server 5.7\Uploads\
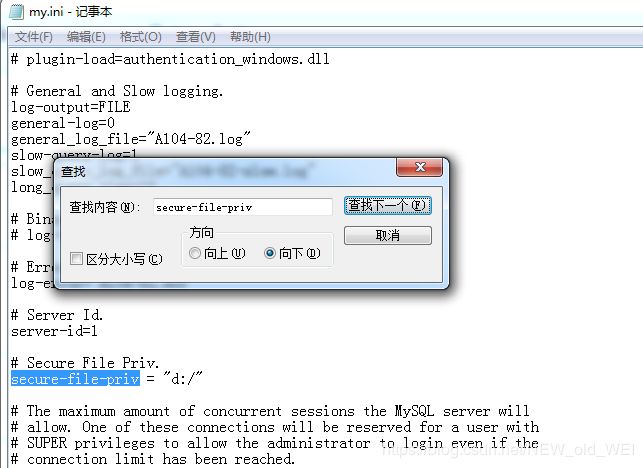
3 打开 my.ini 找到 secure-file-priv 参数
secure-file-priv="d:/"
#4 导出查询结果
select 语句的 from 前,加 into outfile "d:/文件名.txt"
导出文件香关设置
1 查看系统变量secure_file_priv的值
取值的类型
1. secure_file_priv="" 表示可以把结果存到任何位置
2. secure_file_priv=Null 没有权限向外写文件
3. secure_file_priv="d:/" 可以导出到指定处 注意目录分割用/
查看
1. select @@secure_file_priv
2. show variables like '%secure%';
只有 secure_file_priv 值为非NULL 时 才能用 into outfile 向外写文件(不能覆盖文件)
select 列1,列2,... into OUTFILE 指定的路径+文件名txt|csv from 表名
2 修改secure_file_priv的取值
1 找到my.ini,修改secure_file_priv的值
2 重新mysql启动服务 , 我的电脑—— 右键 --管理 ——服务——mysql——右键重启
show variables like '%secure%';
C:\ProgramData\MySQL\MySQL Server 5.7\Uploads\
select * into OUTFILE "d:/ttt.txt"
from mianshi.student
where id <10
SELECT @@secure_file_priv
drop PROCEDURE jihua1;
CREATE PROCEDURE jihua1()
BEGIN
DECLARE filename VARCHAR(30);
set filename = CONCAT("d:/week1",UNIX_TIMESTAMP(CURRENT_TIMESTAMP()),".txt");
set @outstr = CONCAT("select * into OUTFILE '",filename,"' from 贷款表") ;
PREPARE ss from @outstr;
EXECUTE ss;
end
select DATE_FORMAT(now(),"%Y%m%d%h%i%s")
call jihua1()
call jihua1();
BEGIN
insert 统计表
select DATE_SUB(CURRENT_DATE(),INTERVAL 1 day),count(DISTINCT uid) from shijian where shijian > DATE_SUB(CURRENT_DATE(),INTERVAL 1 day) and shijian<CURRENT_DATE()
and active="denglu"
end


停止 ------启动
储存
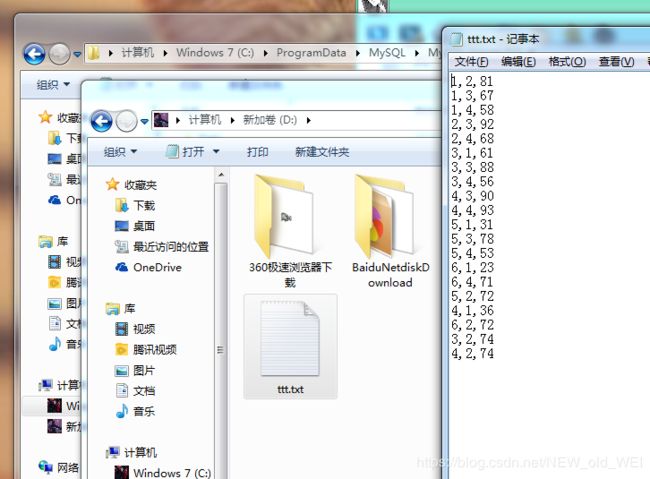
into OUTFILE "d:/ttt.txt" FIELDS TERMINATED by "," LINES TERMINATED by "\r\n"
导出sc 数据 到d:/ 命名为ttt.txt
SELECT *into OUTFILE "d:/ttt.txt" FIELDS TERMINATED by "," LINES TERMINATED by "\r\n"
from sc
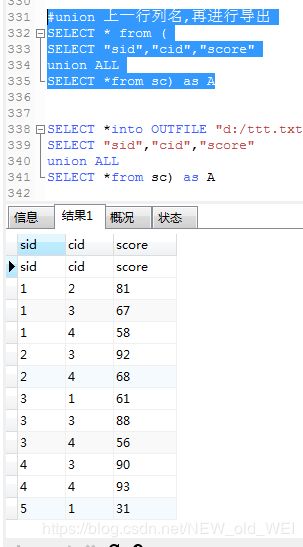
#union 上一行列名,再进行导出
SELECT * from (
SELECT "sid","cid","score"
union ALL
SELECT *from sc) as A
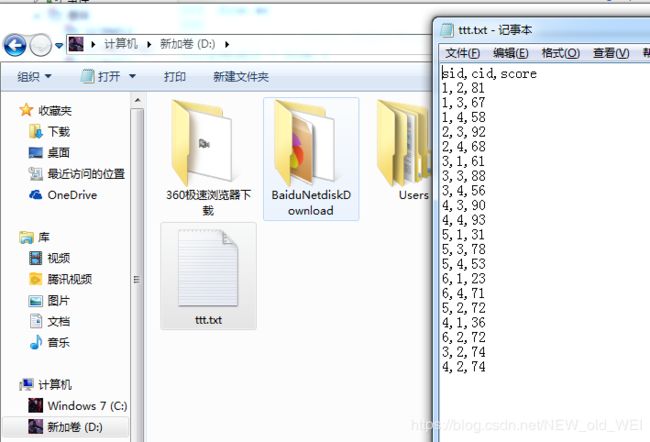
SELECT *into OUTFILE "d:/ttt.txt" FIELDS TERMINATED by "," LINES TERMINATED by "\r\n"from (
SELECT "sid","cid","score"
union ALL
SELECT *from sc) as A
日期函数
select * into OUTFILE "d:/ttt.txt"
from ccss_sample
where id <10
select curdate(),current_date()
select curtime(),current_time(),now()
SELECT month(curdate()),MONTHNAME(curdate()),dayname(curdate())
select DATE_ADD(日期,INTERVAL 数 单位)
select DATE_sub(curdate(),INTERVAL 2 day)
select TIMESTAMPDIFF(MONTH,'2019-09-09',curdate())
SELECT DATEDIFF('2019-12-31 23:59:50','2018-12-31 23:59:50')
获取当前日期:curdate(),current_date()
获取当前时间:curtime(),current_time()
获取当前日期时间:now()
从日期中选择出月份数:
month(date),monthname(date),week(date),year(date),hour(time),minute(time) ,weekday(date),dayname(date)
时间加 DATE_ADD(date,INTERVAL expr type)、ADDDATE(date,INTERVAL expr type),ADDTIME(date,expr)
时间减 DATE_SUB(date,INTERVAL expr type)、SUBDATE(date,INTERVAL expr type), SUBTIME(date,expr)
指定类型时间差 TIMESTAMPDIFF(时间单位_year_month_day_hour),开始时间,结束时间)
天之差 DATEDIFF(结束时间,开始时间)
DATEDIFF('2019-12-31 23:59:50','2018-12-31 23:59:50') #
TIMESTAMPDIFF(year,19920202,CURDATE())
UNIX_TIMESTAMP(时间字符串 或 时间) 把给定的内容转化为时间戳
FROM_UNIXTIME(时间戳[,格式]) 时间戳转化为时间或指定格式的字符串
STR_TO_DATE(时间字符串,格式) 字符串转化为时间
select UNIX_TIMESTAMP(curdate())
SELECT FROM_UNIXTIME(1568131200)
SELECT FROM_UNIXTIME(1568131200,"%y/%m/%d")
SELECT STR_TO_DATE("20190901")
SELECT STR_TO_DATE("01 may 19","%d %b %y")
索引
#索引
索引作用
提高查询速度,
几千条记录 无需创建
索引类型
full-text 全文索引 , char varchar text
unique 唯一索引, 可以有一个Null ,不能重复
normal 普通索引
主键索引 不能重复 不能有NULL
索引方法
hash > = < in
BTREE 二叉树形式构建查询
把索引列放到条件前边, 左侧原则
select * from artists where artist_location = "天津市"
create index 索引名 on 表名(字段名)
show index from 表名 #查看指定表的索引
select version(); #产看版本
存储过程(Stored Procedure)是一组为了完成特定功能的SQL语句集
存储过程的优点:
(1).增强SQL语言的功能和灵活性:存储过程可以用控制语句编写,有很强的灵活性,可以完成复杂的判断和较复杂的运算。
(2).标准组件式编程:存储过程被创建后,可以在程序中被多次调用,而不必重新编写该存储过程的SQL语句。而且数据库专业人员可以随时对存储过程进行修改,对应用程序源代码毫无影响。
(3).较快的执行速度:如果某一操作包含大量的Transaction-SQL代码或分别被多次执行,那么存储过程要比批处理的执行速度快很多。因为存储过程是预编译的。在首次运行一个存储过程时查询,优化器对其进行分析优化,并且给出最终被存储在系统表中的执行计划。而批处理的Transaction-SQL语句在每次运行时都要进行编译和优化,速度相对要慢一些。
(4).减少网络流量:针对同一个数据库对象的操作(如查询、修改),如果这一操作所涉及的Transaction-SQL语句被组织进存储过程,那么当在客户计算机上调用该存储过程时,网络中传送的只是该调用语句,从而大大减少网络流量并降低了网络负载。
(5).作为一种安全机制来充分利用:通过对执行某一存储过程的权限进行限制,能够实现对相应的数据的访问权限的限制,避免了非授权用户对数据的访问,保证了数据的安全。
存储过程与自定义函数的区别:
存储过程实现的过程要复杂一些,而函数的针对性较强;
存储过程可以有多个返回值,而自定义函数只有一个返回值;
存储过程一般独立的来执行,而函数往往是作为其他SQL语句的一部分来使用;
#存储过程定义
create PROCEDURE 过程名(in/out/inout 参数名 参数类型,....)
BEGIN
过程体
end
#调用存储过程
call 过程名(参数1,参数2)
#查看存储过程
1. navicat 数据库——》函数下
2. 到mysql库下得 proc 表查看
use mysel
SELECT * from proc
3. SHOW PROCEDURE STATUS WHERE db='数据库名';#查指定数据库下的存储过程 (和第二条类似)
#查看存储过程详细信息
SHOW CREATE PROCEDURE 数据库名.过程名;
show create PROCEDURE mianshi.test1
#删除一个过程
drop PROCEDURE 数据库名.过程名;
drop PROCEDURE if EXISTS 过程名;
#定义 用户变量
set @变量名 = 变量值;
#显示变量内容
select @变量名;
# 变量赋值
1 通过Set 直接指定 @变量名 = 变量值;
2 select @变量名1 := 字段名1,@变量名2 := 字段名2, from 表
3 select 字段名1, 字段名2 into @变量名1,@变量名2 from 表
#定义局部变量
DECLARE 变量名 变量类型 DEFAULT 值
#局部变量
select 字段名1, 字段名2 into 变量名1,变量名2 from 表
#局部变量显示
select 变量名
#预制语句 (PREPARE语句用于预备一个语句,并赋予它名称,借此在以后引用该语句)
PREPARE 定义名 FROM 语句字符串; #预制语句sql 语句
EXECUTE 定义名 #执行sql语句
DROP PREPARE 定义名; #删除预定义名
索引&视图&存储
#视图
#创建
create view 视图名 as
select 语句
#表与视图的区别
物理空间 操作
视图 创建视图定义空间 只能查,不能进行增删改
表 实际记录数据空间 增删改查
创建视图时不能有变量
#修改
#1
create or REPLACE view 视图名
as
select 语句
#2
ALTER view 旧视图名
as
select 语句
#删除
drop view v1
#使用(同查表一样)
select * from 旧视图名
#sql 优化(提高查询速度)
# 创建索引
# * ,like, in(索引会失效,用OR代替)
# where 后 表达式放到等号右边
#索引(书的目录)
索引作用
提高查询速度,
几千条记录 无需创建
索引类型
full-text 全文索引 , char varchar text
unique 唯一索引, 可以有一个Null ,不能重复
normal 普通索引 常用
主键索引 不能重复 不能有NULL
索引注意事项
#常做增删改的表尽量不要有索引(降低增删改的速度)
#左侧原则: 把有索引的条件放到查询的条件的前面
索引方法
hash > = < in
BTREE 二叉树形式构建查询
#创建
create index 索引名 on 表名(字段名)
#显示索引
show index from 表名
create index dier on ccss_sample(月份,性别,年龄)
show CREATE table ccss_sample
#产看版本
select version(); #5.1 版本 默认存储引擎 INNODB ,所以支持存储过程
#事务: 包含的sql语句都成功或者都失败, (提交,回滚)
存储过程(Stored Procedure)是一组为了完成特定功能的SQL语句集
存储过程的优点:(事务,速度快,防注入)
(1).增强SQL语言的功能和灵活性:存储过程可以用控制语句编写,有很强的灵活性,可以完成复杂的判断和较复杂的运算。
(2).标准组件式编程:存储过程被创建后,可以在程序中被多次调用,而不必重新编写该存储过程的SQL语句。而且数据库专业人员可以随时对存储过程进行修改,对应用程序源代码毫无影响。
(3).较快的执行速度:如果某一操作包含大量的Transaction-SQL代码或分别被多次执行,那么存储过程要比批处理的执行速度快很多。因为存储过程是预编译的。在首次运行一个存储过程时查询,优化器对其进行分析优化,并且给出最终被存储在系统表中的执行计划。而批处理的Transaction-SQL语句在每次运行时都要进行编译和优化,速度相对要慢一些。
(4).减少网络流量:针对同一个数据库对象的操作(如查询、修改),如果这一操作所涉及的Transaction-SQL语句被组织进存储过程,那么当在客户计算机上调用该存储过程时,网络中传送的只是该调用语句,从而大大减少网络流量并降低了网络负载。
(5).作为一种安全机制来充分利用:通过对执行某一存储过程的权限进行限制,能够实现对相应的数据的访问权限的限制,避免了非授权用户对数据的访问,保证了数据的安全。
存储过程与自定义函数的区别:
存储过程实现的过程要复杂一些,而函数的针对性较强;
存储过程可以有多个返回值,而自定义函数只有一个返回值;
存储过程一般独立的来执行,而函数往往是作为其他SQL语句的一部分来使用;
#存储过程定义
create PROCEDURE proc_1(in/out/inout 参数名 参数类型)
BEGIN
sql 语句 #一定要有语句结束标记;
end
##存储过程调用
call proc_1(实参1,实参2)
#查看存储过程
1. navicat 数据库——》函数下
2. 到mysql库下得 proc 表查看
use mysql
SELECT * from proc
3. SHOW PROCEDURE STATUS WHERE db='数据库名'; #查指定数据库下的存储过程 (和第二条类似)
#查看存储过程详细信息
SHOW CREATE PROCEDURE 过程名;
show create PROCEDURE proc_1
#删除一个过程
drop PROCEDURE 过程名;
drop PROCEDURE if EXISTS 过程名;
#定义 用户变量
set @变量名 = 变量值;
#显示变量内容
select @变量名;
# 变量赋值
1 通过Set 直接指定默认值 @变量名 = 变量值;
2 select @变量名1 := 字段名1,@变量名2 := 字段名2, from 表
3 select 字段名1, 字段名2 into @变量名1,@变量名2 from 表
#定义局部变量( 定义在过程的最上边)
DECLARE 变量名 变量类型 DEFAULT 值
#局部变量
select 字段名1, 字段名2 into 变量名1, 变量名2 from 表
#局部变量显示
select 变量名
#预制语句 (PREPARE语句用于预备一个语句,并赋予它名称,借此在以后引用该语句)
PREPARE 定义名 FROM 语句字符串; #预制语句sql 语句
EXECUTE 定义名 #执行sql语句
DROP PREPARE 定义名; #删除预定义名
#开窗函数
函数: row_number() , rank(),dense_rank,lag(列名,前几位,不存在时的默认值), lead(列名,后几位,不存在时的默认值)
开窗: over (partiton by 分组列名 order by 列名)#()里的设置可以缺省——
set @id = 0;
CREATE table t1 as
select *,@id:=@id+1 as id from sc
order by cid ,score desc
set @paiming = 0 ;
select *,@paiming :=if(t1.cid =(select cid from t1 as subt1 where subt1.id = t1.id -1 ) ,@paiming+1,1) as paiming
from t1
select *,
(select count(sid) from sc as subsc where subsc.cid =sc.cid and subsc.score> sc.score) +1 as paiming
from sc
order by cid ,paiming
CREATE PROCEDURE proc_1(in kechengming varchar(10))
BEGIN
select * from sc,course
where sc.cid = course.cid
and cname=kechengming;
end
call proc_1("语文")
#1 指定老师的成绩单
#2 指定表,指定条件的数据
drop PROCEDURE proc_2;
create PROCEDURE proc_2(in tname VARCHAR(10),in tianjian varchar(30))
BEGin
set @sql_str = CONCAT(" select * from sc where ",tianjian);
PREPARE sql_1 from @sql_str;
EXECUTE sql_1;
end
call proc_2("sc","score>=60")
create PROCEDURE proc_3(out shuiliang int)
BEGIN
select count(*),avg(score) into shuiliang,pingjun from sc;
end
set @liang = 0;
select @liang;
call proc_3(@liang);
select @liang;
create PROCEDURE proc_5(inout zhi int)
begin
select max(score) into zhi from sc where sid = zhi;
end
set @id_maxS = 3;
select @id_maxS;
call proc_5(3,@id_maxS);
select @id_maxS;
drop PROCEDURE 名
create PROCEDURE proc_6(in _cid int, out _sname varchar(10))
begin
declare _maxScore int;
declare _sid int;
select max(score) into _maxScore from sc where cid = _cid;
select sid into _sid from sc where cid = _cid and score = _maxScore;
select sname into _sname from student where sid = _sid;
end
set @renming ="";
call proc_6(1,@renming);
select @renming
练习
1 创建表test ,存储用户基本信息至少三个字段,创建表的其他两种方式
create table test(
sid int,
name varchar(20),
sex VARCHAR(20)
)
2 向 test 里插入一条语句,插入多条查询结果
insert into test (sid,name,sex) values(1,'张三','男')
select * from test
3 修改表结构,test 添加列, 删除列 ,更改列类型
alter table test add age int
alter table test drop age
alter table test MODIFY sid int
4 更改一条表数据,删除一条表数据,删除表
update test set name = '李四' where sid = 1
delete from test where sid =1
drop table test
5 为test 表加一个一般索引
create index soso on test(name)
show index from test
6 创建一个查询test 前3条数据的视图
create view v3 as
select * from test limit 3
7 创建存储过程找到指定学生的最高考试科目
create PROCEDURE pro7(in xueshengming varchar(10))
BEGIN
select sname,max(score),cname from student,sc,course where student.sid = sc.sid and SC.cid = course.cid and sname=xueshengming GROUP BY sname;
END
call pro7("张三")
8 创建存储过程找到指定学生参加的课程数
create PROCEDURE pro8(in zhiding varchar(10))
BEGIN
select sname,count(sc.cid) from student ,sc,course where student.sid = sc.sid and SC.cid = course.cid and sname = zhiding GROUP BY sname;
END
call pro8("刘一")
9 创建存储过程找到指定学生参加的课程列表
create PROCEDURE pro9(in zhiding varchar(10))
BEGIN
select sname,GROUP_CONCAT(DISTINCT cname) from student ,sc,course where student.sid = sc.sid and SC.cid = course.cid and sname = zhiding GROUP BY sname;
END
call pro9("张三")
10 创建存储过程找到指定老师的所教课程
create PROCEDURE pro10(in laoshi varchar(10))
BEGIN
select tname,GROUP_CONCAT(DISTINCT course.cname) from teacher,course where teacher.tid = course.tid and tname=laoshi GROUP BY tname;
END
call pro10("叶平")
12 创建存储过程显示出学生成绩单(课程名,分数)
create PROCEDURE pro11(in xingming VARCHAR(10))
BEGIN
select sname,cname,score from student,sc,course where student.sid = sc.sid and SC.cid = course.cid and sname=xingming GROUP BY sname;
END
call pro11("钱二")
13 创建存储过程找到指定老师的最差学生
create PROCEDURE pro12(in laoshi VARCHAR(10))
BEGIN
select tname,sname,min(score) from teacher,course,sc,student where teacher.tid = course.tid and course.cid = SC.cid and SC.sid = student.sid and tname = laoshi GROUP BY tname;
END
call pro12("叶平")
14 找到指定老师的前2名学生
create PROCEDURE pro14(in laoshi VARCHAR(10))
BEGIN
select tname,sname,score as sco from teacher,course,sc,student where teacher.tid = course.tid and course.cid = SC.cid and SC.sid = student.sid and tname=laoshi ORDER BY sco desc limit 2;
END
call pro14("叶平")
15 找到下个月过生日的人
select first_name from employees where month(hire_Date) = 1
16 找到未来15天内过生日的人
select first_name,month(now()) as xian,month(hire_Date) as sheng from employees GROUP BY first_name having xian=sheng and first_name in (
(select first_name from employees where (day(now()) - day(hire_date))<15 and (day(now()) - day(hire_date))>0))
#预制语句
PREPARE 预制语句名 from 字符串(是用户级变量名)
EXECUTE 预制语句名
#开窗
row_number bank desn_bank lag lead 聚合函数
over(PARTITION by 字段名 ORDER BY 字段名 )
#对未参加考试的学生进行录入成绩,
#及格率>0.6 成绩为此科目的均值
#及格率>0.8 成绩为此科目的均值 + 10
#否则 成绩为此科目的均值的0.9
select * from sc order by sid
CREATE table sc_bak
SELECT * from sc
drop PROCEDURE proc_10;
CREATE PROCEDURE proc_10(in _sid int)
BEGIN
declare weixue_cid int ;
declare pingjun FLOAT ;
declare cishu int;
declare xunhuanci int DEFAULT 1;
select count(cid) into cishu from course where cid not in (SELECT cid from sc where sid = _sid);
WHILE xunhuanci<=cishu do
select cid into weixue_cid from (
select cid from course where cid not in (SELECT cid from sc where sid = _sid) limit 1 ) as A ;
select avg(score) into pingjun from sc where cid = weixue_cid;
if pingjun > 0.6 then
INSERT sc VALUES(_sid,weixue_cid,pingjun);
ELSEIF pingjun > 0.8 then
INSERT sc VALUES(_sid,weixue_cid,pingjun+10);
else
INSERT sc VALUES(_sid,weixue_cid,pingjun*0.9);
end if;
SELECT xunhuanci+1 into xunhuanci;
end WHILE;
end
call proc_10(1)
触发器
触发器(trigger):监视某种情况,并触发某种操作,它是提供给程序员和数据分析员来保证数据完整性的一种方法,它是与表事件相关的特殊的存储过程,
它的执行不是由程序调用,也不是手工启动,而是由事件来触发,例如当对一个表进行操作( insert,delete, update)时就会激活它执行。
触发器经常用于加强数据的完整性约束和业务规则等。 触发器创建语法四要素:
1.监视地点(table)
2.监视事件(insert/update/delete)
3.触发时间(after/before) after
4.触发事件(insert/update/delete)
begin
if EXISTS(select * from 老师业绩 where tid= new.tid) then
update 老师业绩 set qian = qian+50 where tid= new.tid
else
insert 老师业绩 VALUES(new.tid,50)
end if
insert 型触发器 new 表示将要 before 或者 已经新增的数据 after
Update 型触发器 old 用来表示将要 before 或者已经被跟新的语句 after
new 表示将要 before 或 者已经修改的为数据after
DELETE 型触发器 old 用来表示将要 before 或 者已经被删除的语句 after
绩效考核
CREATE table 反馈表(
日期 date,
班级 int,
事件 VARCHAR(10),
人数 int
id int)
ALTER table 反馈表 add tid int
CREATE TABLE 绩效成绩(
老师 VARCHAR(10),
职位 VARCHAR(10),
日期 date,
绩效 int
tid int)
ALTER TABLE 绩效成绩 add tid int
UPDATE 绩效成绩 set tid=1
SELECT * from 绩效成绩
ALTER TABLE 反馈表 add id int
INSERT 反馈表 VALUES("2019-12-12",125,"口碑",5,2,3)
------------------------------------------------
插入
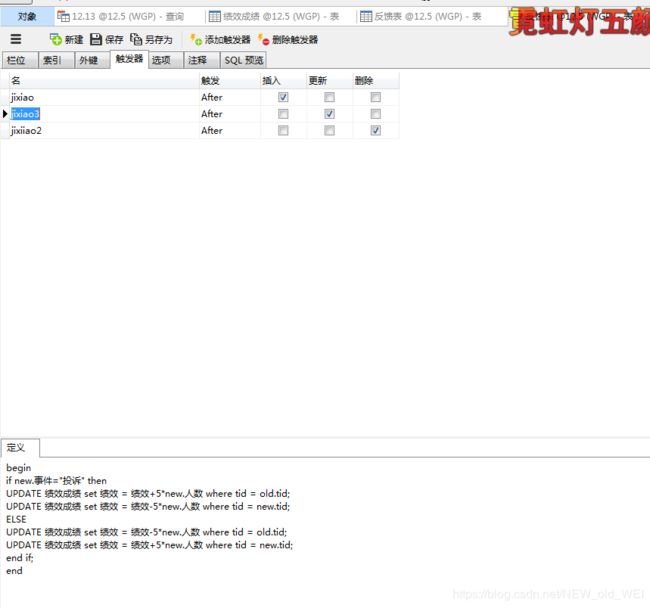
if new.事件="投诉" then
update 绩效成绩 set 绩效= 绩效-5*new.人数 where tid = new.tid;
else
update 绩效成绩 set 绩效= 绩效+5*new.人数 where tid = new.tid;
end if;
---------------------------------------------
更新
if 事件="投诉" then
UPDATE 绩效成绩 set 绩效 = 绩效+5*new.人数 where tid = old.tid;
UPDATE 绩效成绩 set 绩效 = 绩效-5*new.人数 where tid = new.tid;
ELSE
UPDATE 绩效成绩 set 绩效 = 绩效-5*new.人数 where tid = old.tid;
UPDATE 绩效成绩 set 绩效 = 绩效+5*new.人数 where tid = new.tid;
end if;
----------------------------------------------------------------
删除
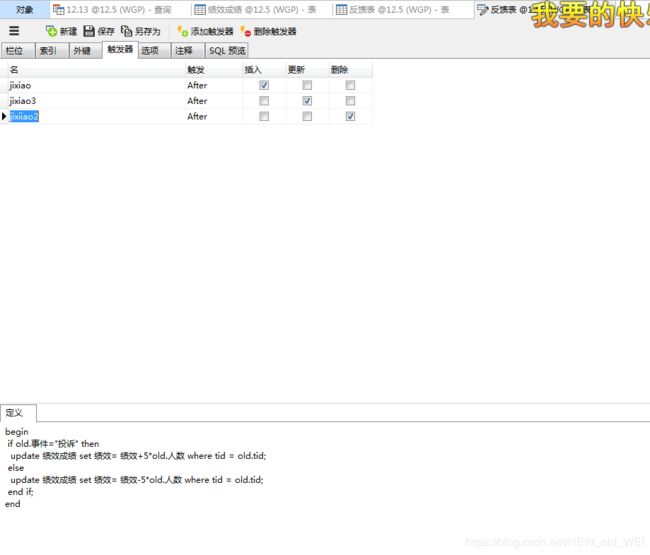
if new.事件="投诉" then
update 绩效成绩 set 绩效= 绩效+5*new.人数 where tid = old.tid;
else
update 绩效成绩 set 绩效= 绩效-5*new.人数 where tid = old.tid;
end if;
--------------------------------------------------------------
INSERT 绩效成绩 VALUES("谷","数据","2019-12-1",100,1)
INSERT 绩效成绩 VALUES("菜","数据","2019-12-1",100,2)
插入删除更新反馈表的信息时 绩效表也跟着变
INSERT 反馈表 VALUES("2019-12-12",125,"投诉",2,1,1)
INSERT 反馈表 VALUES("2019-12-12",125,"口碑",2,2,2)
INSERT 反馈表 VALUES("2019-12-12",125,"口碑",2,2,3)

创建新函数
创建新函数:
定义
Create function 函数名(参数1 参数类型, 参数2 参数类型,...) #定义函数头
returns 返回值类型 #提前告知函数的返回类型 注意是returns
#函数体用begin end 包起来
begin
函数体内容(每条语句后加;)
RETURN 值;#返回数据 注意此处为 RETURN
end
CREATE FUNCTION f1(a int, b int)
RETURNS INT
BEGIN
if a>b THEN
RETURN a-b;
ELSE
RETURN a+b;
end if;
end
select f1(1,4)
SELECT *,kushu1(sid) as cankaoshu from mianshi.student;
SELECT *,left(sname,1) as 姓氏 from mianshi.student
CREATE FUNCTION kushu1(xsid int)
RETURNs INT
BEGIN
DECLARE con int ;
select count(cid) into con from mianshi.sc where sid = xsid;
RETURN con;
end
#定义函数实现给定cid 找到学生数
#给定 姓名和性别 实现 按”_“ 合并为一个字符串
create FUNCTION hebing(x VARCHAR(10), y VARCHAR(10))
RETURNS VARCHAR(10)
begin
return CONCAT(x,"_",y);
end;
SELECT hebing("三类","变量")
select *,hebing(sname,ssex) from mianshi.student
mysql 三类变量
@ #用户及变量 set 定义 set @aaa = "";
DECLARE #局部变量,在存储过程和函数里定义 declare aa int DEFAULT "";
@@ #系统变量 , mysql.ini 配置文件中产生的
SELECT @@log_bin_trust_function_creators #查看指定系统变量的值
set global log_bin_trust_function_creators=TRUE #更改指定系统变量的值
show variables #显示所有系统便量
show variables like '%变量名部分内容%' #对系统变量进行模糊查找
调用:和系统函数试用方法一样 如power(2,3);
删除
DROP FUNCTION IF EXISTS function_name;
create function sum_xy(x float,y float)
RETURNs FLOAT
BEGIN
RETURN x+y;
end
DROP FUNCTION IF EXISTS sum_xy
游标
认识游标(cursor): 游标就是一个可读的标识,用来标识数据取到什么地方了。
使用游标: 需要强调的是,游标必须在定义处理程序之前被定义,但变量必须在定义游标之前被定义,
顺序就是变量定义-游标定义-处理程序。
游标用到 存储过程里 因为declare是用到存储过程里的
游标作用: 对每行数据进行分别处理
定义游标
declare 游标名 cursor for select语句
定义游标结束标记
declare CONTINUE HANDLER FOR NOT FOUND set 变量名 = 值;
打开游标
open 游标名
推进游标指针
FETCH 游标名 into 变量名(此变量存储的是当前记录的值);
关闭游标
close 游标名
CREATE PROCEDURE test46()
BEGIN
declare cur_sid int;
declare isend int DEFAULT 0;
DECLARE cur1 CURSOR for select sid from mianshi.sc where cid=1 and sid<6; #定义指针,执行查询结果
DECLARE CONTINUE HANDLER for not found set isend=1; #压到最后时的标记
open cur1; #打开游标
FETCH cur1 into cur_sid; #推到第一条记录
while isend=0 DO
select cur_sid;
FETCH cur1 into cur_sid;
end while;
close cur1; #关闭游标
END
#找到最大成绩
create PROCEDURE test50()
BEGIN
declare max_x int DEFAULT 0;
declare xscore int;
DECLARE isend int DEFAULT 0;
declare cur1 cursor for SELECT score from mianshi.sc;
declare CONTINUE HANDLER for not found set isend=1;
open cur1;
FETCH cur1 into xscore;
while isend =0 DO
if xscore> max_x THEN
set max_x = xscore;
end if;
FETCH cur1 into xscore;
end while;
select max_x;
close cur1;
end
sex renshu
f 20
m 40
create table zongji
(sex varchar(10),
shu int)
insert zongji VALUES("f",20);
insert zongji VALUES("m",40)
select * from zongji
create table yuan
(sex varchar(10))
select * from yuan
sex
f
f
m
m
create PROCEDURE test51()
BEGIN
DECLARE isend int DEFAULT 0; #记录游标是否到最后
DECLARE cur_sex varchar(10); #游标当前位置的 sex
DECLARE cur_shu int ; #游标当前位置的 shu
DECLARE i int DEFAULT 1; #循环次数 i
declare cur1 cursor for SELECT * from zongji; #定义游标 指向查询结果
declare CONTINUE HANDLER for not found set isend=1; #游标到最后时, 更改标记
open cur1; #打开游标
FETCH cur1 into cur_sex,cur_shu; #推进游标指向第一行
while isend =0 DO #判断游标是否结束
set i=1; #重新循环计数
while i<=cur_shu do #循环插入同一性别数据
insert yuan VALUES(cur_sex);
set i=i+1;
end while;
FETCH cur1 into cur_sex,cur_shu; #推进游标指向下一行
end while;
close cur1; #关闭游标
end
call test51();
#给定cid 计算其平均分
事件
show processlist;
事件(event)是MySQL在相应的时刻调用的过程式数据库对象。
一个事件可调用一次AT ,也可周期性的启动 EVERY ,它由一个特定的线程来管理的,也就是所谓的“事件调度器”。
事件和触发器类似,都是在某些事情发生的时候启动。当数据库上启动一条语句的时候,触发器就启动了,
而事件是根据调度事件来(时间周期)启动的。由于他们彼此相似,所以事件也称为临时性触发器。
SHOW PROCESSLIST; #参看在运行的线程(确定事件调度器是否启动)
#事件计划保存 启动事件服务
show variables like '%sche%';
set global event_scheduler =ON;
show EVENTS #当前数据库的所有事件
drop EVENT 计划1 #删除指定事件
log
shijian uid active
2019-9-14 12:12:12 1 denglu
2019-9-14 12:12:12 2 denglu
2019-9-14 12:12:13 3 denglu
2019-9-14 12:12:13 1 liulan
....
2019-9-14 12:20:1 1 购物
2019-9-14 12:20:55 1 付款
.....
2019-9-13 30W
2019-9-14 50W
2019-9-15 0
统计表
日期 访问人数 购买数 成交额
drop PROCEDURE ttt
create PROCEDURE ttt()
BEGIN
set @sql_1=concat("select * into outfile 'd:/t",UNIX_TIMESTAMP(now()),".txt' from mianshi.sc ");
prepare execsql from @sql_1;
EXECUTE execsql;
end
call ttt()
SELECT CONCAT("d:/test",now(),".txt")
show variables like 'char%';
select * into outfile 'd:/test2.txt' from mianshi.sc
SELECT UNIX_TIMESTAMP(now())
事件练习 表分区
CREATE TABLE test_grade(sname VARCHAR(20), grade int);
INSERT test_grade VALUES("tom",60),("john",89),("green",70),("tim",100),("nancy",100)
#1. 实现下图
-- SELECT * from test_grade
-- set @rank =0;
-- SELECT *,@rank:=@rank + 1 as mingci from test_grade ORDER BY grade desc
SELECT *,(select count(DISTINCT grade) from test_grade where grade > a.grade) + 1 as 排名 from test_grade as a ORDER BY grade desc
#1 用指令建立事件,实现分钟为sc表的 1号学生,1号课程加 5分
SET @score = (SELECT score from sc where sid = 1 and cid = 1)
CREATE event jiafen
on SCHEDULE
EVERY 5 MINUTE
STARTs '2019-12-16 19:26:00'
ENDS '2019-12-16 19:30:00'
@score := @score + 5;
ON COMPLETION not PRESERVE
enable
DO
UPDATE TABLE sc set score = @score;
#2 用指令建立触发器,删除course 表记录时,要删除相应的sc 表对应的成绩
CREATE TRIGGER tri_2
BEFORE DELETE on course
for EACH ROW
BEGIN
DELETE from sc where cid = old.cid;
end
DELETE from course where cid = 12
#3 对学生按年龄进行分区
alter TABLE student PARTITION by list(sage)
(
PARTITION age1 values in(17),
PARTITION age2 values in(18),
PARTITION age3 values in(19)
)
SELECT * from student PARTITION(age1)
#4 对test_grade 表按grade 分区
SELECT * from test_grade
alter TABLE test_grade PARTITION by range(grade)
(
PARTITION grade1 values less than(70),
PARTITION grade2 values less than(90),
PARTITION grade3 values less than(MAXVALUE)
)
SELECT * from test_grade PARTITION(grade1)
#5 对sc 表加等级字段(及格,不及格,优秀) ,并按此字段分区
ALTER table sc add 等级 varchar(10)
if score >=80 then
INSERT into sc(cid,等级) VALUES(1,"优秀");
elseif score >=60 and score <80 then
INSERT into sc(等级) VALUES("及格");
else
iNSERT into sc(等级) VALUES("不及格");
update sc set 等级 = "优秀" WHERE score >= 80;
update sc set 等级 = "及格" WHERE score >=60 and score <80 ;
update sc set 等级 = "不及格" WHERE score < 60
alter TABLE sc PARTITION by list COLUMNs(等级)
(
PARTITION LEVEL_1 values in("优秀"),
PARTITION LEVEL_2 values in("及格"),
PARTITION LEVEL_3 values in("不及格")
)
SELECT * from sc PARTITION(LEVEL_1)
表分区
mysql数据库中的数据是以文件的形势存在磁盘上的,
默认放在/mysql/data下面(可以通过my.cnf中的datadir来查看),
一张表主要对应着三个文件,一个是frm存放表结构的,一个是myd存放表数据的,一个是myi存表索引的。
如果一张表的数据量太大的话,那么myd,myi就会变的很大,查找数据就会变的很慢,
这个时候我们可以利用mysql的分区功能,在物理上将这一张表对应的三个文件,分割成许多个小块,
这样呢,我们查找一条数据时,就不用全部查找了,只要知道这条数据在哪一块,然后在那一块找就行了。
如果表的数据太大,可能一个磁盘放不下,这个时候,我们可以把数据分配到不同的磁盘里面去。
分区表的限制因素
(1)、一个表最多只能有1024个分区。
(2)、如果分区字段中有主键或者唯一索引的列,那么多有主键列和唯一索引列都必须包含进来。
即:分区字段要么不包含主键或者索引列,要么包含全部主键和索引列。
(3)、分区表中无法使用外键约束。
MySQL支持的分区类型
(1)、RANGE分区:基于属于一个给定连续区间的列值,把多行分配给分区。
(2)、LIST分区:类似于按RANGE分区,区别在于LIST分区是基于列值匹配一个离散值集合中的某个值来进行选择。
(3)、HASH分区:基于用户定义的表达式的返回值来进行选择的分区,该表达式使用将要插入到表中的这些行的列值进行计算。这个函数可以包含MySQL 中有效的、产生非负整数值的任何表达式。
(4)、KEY分区:类似于按HASH分区,区别在于KEY分区只支持计算一列或多列,且MySQL服务器提供其自身的哈希函数。必须有一列或多列包含整数值。
#建表时做分区
create table 表名(
列...
partition by range(cid)(
partition p0 values less than (6),
partition p1 values less than (11),
partition p2 values less than (16),
partition p3 values less than (21)
);
#对已经存在的表进行分区
#查看数据库路径
show variables like '%dir%';
#如果表存在主键或外键,只能用主键或外键进行分区
##列值为数值 RANGE
alter table score PARTITION by RANGE(id)
(
PARTITION qu1 VALUES less than(10),
PARTITION qu2 VALUES less than(MAXVALUE)
)
#列值为数值但可数 list
select * from sc
alter table sc PARTITION by list(cid)
(
PARTITION qu1 VALUES in(1,2),
PARTITION qu2 VALUES in(3,4,9,10)
)
#列值为字符串 list COLUMNS
alter table score PARTITION by list COLUMNS(c_name)
(
PARTITION qu1 VALUES in("计算机","英语"),
PARTITION qu2 VALUES in("中文",)
)
#删除分区数据(数据会丢失)
alter table score drop partition qu1;
#删除分区(保留数据)
Alter table teacher remove PARTITIONING
#合并分区
alter table te
reorganize partition qu1_1,qu1_2 into
(partition qu1 values less than (10));
#分解分区
alter table score
reorganize partition qu1 into
(
partition qu1_1 values less than (5),
partition qu1_2 values less than (MAXVALUE)
);
#查找指定分区的数据
select * from score PARTITION(qu1)
#查看指定表的分区情况
show create table score
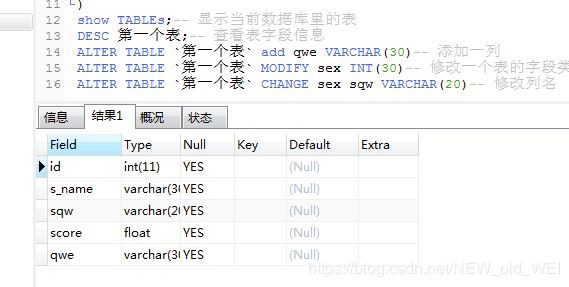
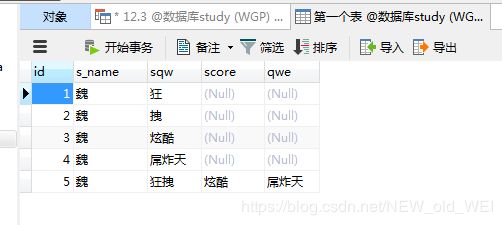
ALTER TABLE `第一个表` add qwe VARCHAR(30)-- 添加一列
ALTER TABLE `第一个表` MODIFY sex INT(30)-- 修改一个表的字段类型
ALTER TABLE `第一个表` CHANGE sex sqw VARCHAR(20)-- 修改列名
INSERT INTO `第一个表`(id,s_name,sqw) VALUES(1,"魏","狂")-- 插入单条数据
INSERT INTO `第一个表`(id,s_name,sqw) VALUES(2,"魏","拽"),(3,"魏","炫酷"),(4,"魏","屌炸天")-- 插入多条数据
ALTER TABLE `第一个表` MODIFY score VARCHAR(30)-- 修改一个表的字段类型
INSERT into `第一个表` VALUES(5,"魏","狂拽","炫酷","屌炸天")
-- 1 找出名字为两个字的学生
SELECT 姓名 FROM `学生信息表` where `姓名`LIKE"__"
-- 2 找出所有男生的名字
SELECT 姓名 FROM `学生信息表`WHERE 性别="男"
-- 3. 查出所有学生的学号和姓名
SELECT 学号,姓名 FROM `学生信息表`
-- 4. 查出籍贯山东的所有学生的学号和姓名
SELECT 学号,姓名 FROM `学生信息表`WHERE 籍贯="山东"
-- 5. 查出落户的所有学生的学号和姓名
SELECT 学号,姓名 FROM `学生信息表`WHERE 落户="已落"
-- 6. 查出所有南宁男生的所有信息
SELECT * from `学生信息表` where 籍贯="南宁" and 性别 ="男"
-- 7. 查出所有女生的学生信息
SELECT * FROM `学生信息表`WHERE 性别="女"
-- 8. 查出籍贯是河池的学生信息
SELECT * FROM `学生信息表`WHERE 籍贯="河池"
-- 9. 查出姓张的学生的信息
SELECT * FROM `学生信息表`WHERE 姓名 like "张%"
-- 10. 查出名字中有小字的学生信息
SELECT * FROM `学生信息表`WHERE 姓名 like "%小%"
-- 11. 查出3月份过生日的学生信息
SELECT * FROM `学生信息表`WHERE MONTH(出生日期)=3
-- 12. 查出学号为1,2,3的学生信息
SELECT * FROM `学生信息表`WHERE 学号 BETWEEN 1 and 3
-- 13. 查出李明、冯伟的学生信息
SELECT * FROM `学生信息表`WHERE 姓名 in("李明","冯伟")
-- 14. 查出河池地区的男学生信息
SELECT * from `学生信息表` where 性别="男" and 籍贯="河池"
-- 15. 查出不是河池地区的学生信息
SELECT * from `学生信息表` where 籍贯 not in("河池")
-- 16. 查出山东的女同学信息
SELECT * from `学生信息表` where 性别="女" and 籍贯="山东"
-- 17. 查出不是山东的男同学信息
SELECT * from `学生信息表` where 性别="男" and 籍贯 not in("山东")
-- 18. 查出男女生的平均分
SELECT 性别,AVG(`语文成绩`),AVG(`数学成绩`),AVG(`英语成绩`) from `学生信息表` GROUP BY 性别
-- 19. 查出姓名第一个字是王的学生信息
SELECT * from `学生信息表` where 姓名 like "王%"
-- 20. 查出名字中含有“小玉明”的学生
SELECT 姓名 from `学生信息表` where 姓名 like "%玉%" or 姓名 like"%明%" OR 姓名 like "%小%"
-- 21. 查出山东,河池的人
SELECT 姓名 from `学生信息表` where 籍贯 in ("山东","河池")
-- 26. 查出 落户的所有学生
SELECT 姓名 from `学生信息表` where 落户="已落"
-- 27. 查出是男生并且姓张的
SELECT 姓名 from `学生信息表` where 性别="男" and 姓名 like "张%"
-- 28. 查出山东海口南京的女学生信息
SELECT * from `学生信息表` where 籍贯 in ("山东","海口","南京") and 性别="女"
-- 29. 查出没落户的男学生信息
SELECT * from `学生信息表` where 性别="男" and 落户="未落"
-- 30. 名字中含小的学生信息
SELECT * from `学生信息表` where 姓名 like ("%小%")
-- 31. 查出 3班的所有学生
SELECT 姓名 from `学生信息表` where 班级=3
-- 32. 查出 2班的所有女同学
SELECT 姓名 from `学生信息表` where 班级=2 and 性别="女"
-- 33. 查出 三个字名字的女同学
SELECT 姓名 from `学生信息表` where 姓名 like "___"and 性别="女"
-- 34. 查出每个学生的三科平均分,降序排
SELECT 姓名,`语文成绩`,`数学成绩`,`英语成绩` ,AVG(`语文成绩`+`数学成绩`+`英语成绩`) as 平均分 from `学生信息表` GROUP BY 姓名 ORDER BY 平均分 DESC
-- 36. 查出英语成绩在85~90之前的
SELECT 姓名 from `学生信息表` where `英语成绩` BETWEEN 85 and 90
-- 37. 查出1班姓李和王的汉族学生
SELECT 姓名 from `学生信息表` where 班级=1 and 姓名 like ("李%" or "王%") and 民族="汉族"
-- 38. 查出此表的班级数
SELECT COUNT(DISTINCT 班级) from `学生信息表`
-- -- 39. 查出此表都有哪几个籍贯的学生
SELECT 籍贯 from `学生信息表` GROUP BY 籍贯
-- 40. 查出此表学生都那几个月过生日
SELECT DISTINCT MONTH(出生日期) from `学生信息表` GROUP BY 出生日期
-- 41. 查出语文成绩大于90分的
SELECT 姓名 from `学生信息表` where 语文成绩>=90
-- 42. 找出民族是汉族 或已落户的学生
SELECT 姓名 from `学生信息表` where 民族="汉族"or 落户="已落户"
-- 43. 查一下余刚的成绩
SELECT 语文成绩,`数学成绩`,`英语成绩` from `学生信息表` where 姓名="余刚"
-- 44. 找所有南宁的学生姓名
SELECT 姓名 from `学生信息表` where 籍贯="南宁"
-- 45. 找出1978 年出生的人
SELECT 姓名 from `学生信息表` where YEAR(`出生日期`)=1978
-- 46. 各班的平均成绩
SELECT 班级,AVG(`语文成绩`),AVG(`数学成绩`),AVG(`英语成绩`)from `学生信息表` GROUP BY 班级
-- 47. 查出不是山东的男同学信息
SELECT * from `学生信息表` where 籍贯 <>"山东" and 性别="男"
-- 48. 找出不在河池和百色的学生
SELECT 姓名 from `学生信息表` where 籍贯 <>"河池" or 籍贯 <>"百色"
-- 49. 哪个班级的语文平均成绩比较高
SELECT `班级`,AVG(`语文成绩`) from `学生信息表` GROUP BY 班级 DESC
-- 50. 查出8或10月过生日的学生
SELECT 姓名 from `学生信息表` where month(出生日期) in (8,10)
-- 51. 除了8或10月过生日的学生
SELECT 姓名 from `学生信息表` where month(出生日期) not in (8,10)
-- 34. 查出每个学生的三科平均分,降序排
SELECT 姓名,`语文成绩`,`数学成绩`,`英语成绩` ,AVG(`语文成绩`+`数学成绩`+`英语成绩`) as 平均分 from `学生信息表` GROUP BY 姓名 ORDER BY 平均分 DESC
SELECT * from world
-- 1.找到name,continent,population列数据
SELECT name,continent,population from world
-- 2.找到人口大于200w的国家的名字和人口
SELECT name,population from world where population>2000000
-- 3.找到人口大于200w的国家的名字和人均GDP
SELECT continent,area from world where population>2000000
-- 4.找到南美洲大陆所有国家和对应的人口总数(以百万单位展示)
SELECT continent,SUM(population)/1000000 from world where continent="South America"
-- 5.找到France,Italy,Germany对应的人口总数(in,注意字符串)
SELECT SUM(population) from world where name in ("France","Italy","Germany")
-- 6.找到名字中包含'united'的国家(like)
SELECT name from world WHERE name like "%united%"
-- 7.找出名字包含三个或三个以上a的国家
SELECT name from world WHERE name like "%a%a%a%"
-- 8.找出名字第二个字母为t的国家(占位符用_)
SELECT name from world WHERE name like "_t%"
-- 9.找出所有国家,其名字都有两个字母 o,被另外两个字母相隔
SELECT name from world WHERE name like "%o__o%"
-- 10.找出首都和国家名字相同的国家
SELECT name from world WHERE name=capital
-- 11.找到面积大于3000000或者人口总数大于250000000的国家,人口和面积
SELECT name,population,area from world WHERE area>300000 OR population>250000000
-- 12.找到南美洲的国家,人口和GDP(人口以百万显示,GDP以10亿显示,保留两位小数)(round函数)
SELECT name,population,gdp from world WHERE continent="South America"
-- 13.找到国家名字和首都名字字符长度一致的国家和首都(length函数)
SELECT name,capital from world where LENGTH(`name`)=LENGTH(capital)
-- 14.找到国家和首都名字的首字母一致,但是全称不一致的国家和首都(left(c,1),<>)
SELECT name,capital from world where LEFT(name,1)=LEFT(capital,1) AND name<>capital
-- 15.找到以U开头的国家名
SELECT name from world where name like "U%"
-- 16.找到以U开头的国家名,但是名字里不包含空格
SELECT name from world where NAME LIKE "U%" AND name NOT LIKE ("% %")
-- 17.找到以c开头以a结尾的国家名
SELECT name from world where NAME LIKE "C%A"
-- 18.找到"United Kingdom"对应的人口总数
SELECT population from world where name="United Kingdom"
-- 19.找到人口总数小于10000的国家和对应的人口数
SELECT NAME,population from world where population<10000
-- 20.找到人口总数小于10000的国家和对应的人口数(人口数以万为单位,保留两位小数)
SELECT NAME,ROUND(population/10000,2) from world where population<10000
-- 21.找到国家的首字母和对应的首都尾字母相同的国家和对应的首都
SELECT name,capital FROM world WHERE LEFT(name,1)=RIGHT(capital,1)
-- 22.找到亚洲和欧洲各国的名字和GDP
SELECT name,gdp FROM world WHERE continent="Europe" OR continent="Asia"
-- 计算世界的总人口(sum)
SELECT SUM(population)from world
-- 计算非洲的GDP总数
SELECT SUM(gdp) from world where continent="Africa"
-- 计算'Estonia', 'Latvia', 'Lithuania'的人口总数
SELECT SUM(population) from world WHERE name in ('Estonia', 'Latvia', 'Lithuania')
-- 计算世界有多少个不同的大洲(distinct)
SELECT COUNT(DISTINCT continent) from world
-- 计算国土面积超过1000000平方公里的国家总数
SELECT COUNT(DISTINCT name)from world WHERE area>1000000
-- 计算亚洲和美洲的国家总数和人口总数
SELECT SUM(population)from world where continent in ("Asia","%America")
-- 计算gdp超过100亿的所有国家数和gdp总数
SELECT COUNT(DISTINCT name),SUM(gdp)FROM world where gdp>10000000000
-- 找到每个大洲对应的国家总数
SELECT continent,COUNT(name) from world GROUP BY continent
-- 找到每个大洲对应的国家总人口数
SELECT continent,SUM(population) from world GROUP BY continent
-- 找到每个大洲对应的国家gdp平均数
SELECT continent,AVG(gdp) from world GROUP BY continent
-- 找到每个大洲比非洲所有国家gdp都高的GDP总数
SELECT continent,SUM(gdp) from world GROUP BY continent HAVING SUM(gdp) > (SELECT SUM(gdp) from world where continent="Africa")
-- 找到每个大洲对应的国家人口超过10000000的国家总数
SELECT continent,COUNT(name) from world where population>10000000 GROUP BY continent
-- 找到人口比Russia人口多的国家
SELECT name FROM world WHERE population>(SELECT population from world where name="Russia")
-- 找到人均gdp比United kingdom多的欧洲国家
SELECT name,gdp/population as 人均GDP from world WHERE continent="Europe" and gdp/population>(SELECT gdp/population from world where NAME="United kingdom")
-- 找到Argentina or Australia所在洲对应的国家和洲名
SELECT name,continent from world where continent in(SELECT continent from world WHERE (name ='Argentina' or name='Australia'))
-- 找到人口比Canada多但是比Poland少的国家的名字和人口between(select) and(select)
SELECT name,population from world where population BETWEEN (SELECT population from world where name="Canada") and (SELECT population from world where name="Poland")
-- 计算欧洲各个国家人口总数占德国人口总数的百分比
SELECT name, population /(SELECT population from world where name="Germany") from world where continent="Europe"
-- 找到比欧洲各个国家GDP都高的那些国家 gdp>all(select gdp from wrold where continent = europe )
SELECT name from world WHERE gdp> (SELECT MAX(f.gdp)from(select gdp from world where continent = "europe" ) as f)
-- 找到人口,gdp比印度多的国家
SELECT name from world where population>(SELECT population from world WHERE name="India") and gdp>(SELECT gdp FROM world WHERE name="India")
-- 找到人口比法国多的国家和对应的洲
SELECT name,continent from world WHERE population>(SELECT population FROM world WHERE name="France")
-- 找到人均gdp比中国多,比美国少的欧洲国家
SELECT name,gdp/population FROM world WHERE continent="Europe" and gdp/population BETWEEN (SELECT gdp/population FROM world WHERE name="China") and (SELECT gdp/population FROM world WHERE name="United States")
-- 找到south africa和Vietnam所在州对应的国家和人均gdp(保留两位小数)
SELECT name,ROUND(gdp/population,2) from world where continent in(SELECT continent from world WHERE (name ='south africa' or name='Vietnam'))
-- 找到人口比Canada多但是比France少的国家的名字和人口(两种方式写)
SELECT name,population from world WHERE population BETWEEN (SELECT population from world WHERE name="Canada") and (SELECT population FROM world WHERE name="France")
-- 计算亚洲各个国家人均gdp占中国人均gdp的百分比(保留4位有效数字)
SELECT name,ROUND(gdp/population/(SELECT gdp/population from world where name="China"),3) from world where continent="Asia"
-- 找到比非洲各个国家gpd都高的亚洲国家
SELECT name from world WHERE continent="Asia" and gdp>(SELECT MAX(gdp)from(select gdp from world where continent = "Africa" )as f)
-- 找到比亚洲各个国家国土面积都大的北美洲国家
SELECT name from world WHERE continent="North America" and area>(SELECT MAX(area)from(select area from world where continent = "Asia" )as f)
--
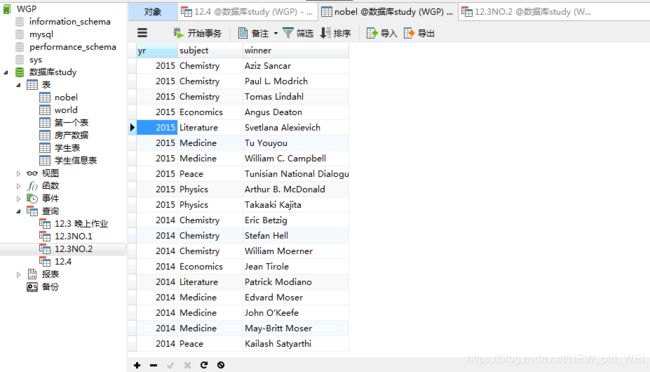
-- 找到每年的诺奖总数
SELECT yr,COUNT(yr) from nobel GROUP BY yr
-- 找到每个奖项对应的总人数
SELECT SUBJECT,COUNT(SUBJECT) FROM nobel GROUP BY subject
-- 找到2014年每个奖项对应的人数的top5(按获奖人数)
SELECT SUBJECT,COUNT(SUBJECT)AS 人数 FROM nobel WHERE yr=2014 GROUP BY subject ORDER BY 人数 DESC LIMIT 5
-- 找到1998年化学奖奖情况
SELECT * from nobel WHERE yr=1998 and subject="Chemistry"
-- 找到1962年物理学获奖者
SELECT winner from nobel WHERE yr=1962 and subject="Physics"
-- 找到2000年后文学奖得主
SELECT winner from nobel WHERE yr=2000 and SUBJECT= "literature"
-- 找到2001年到2004年间的所有医学奖获奖情况
SELECT * from nobel WHERE (yr BETWEEN 2001 and 2004 )and SUBJECT="Medicine"
-- 找到Theodore Roosevelt,Woodrow Wilson,Jimmy Carter,Barack Obama的获奖详情
SELECT * from nobel WHERE winner in ("Theodore Roosevelt","Woodrow Wilson","Jimmy Carter","Barack Obama")
-- 找到名字为frank的所有获奖者
SELECT winner from nobel WHERE winner like "%frank%"
-- 找到1980年除化学奖和医学奖之外的所有奖项的具体信息
SELECT * from nobel WHERE yr=1980 and (SUBJECT<>"Medicine" or SUBJECT<>"Chemistry")
-- 找到1910年之前的医学奖和2000年之后的物理学奖
SELECT *FROM nobel where (yr<1910 and subject="Chemistry") or (yr>2000 and subject="Physics")
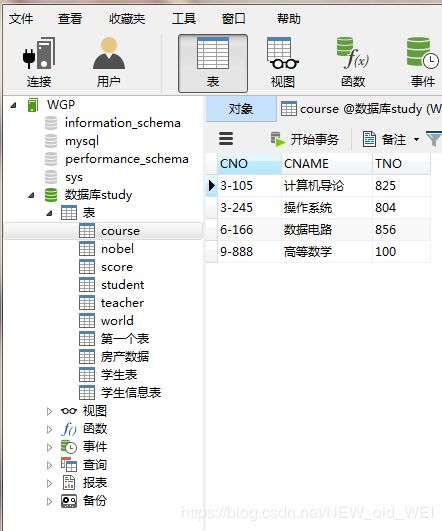
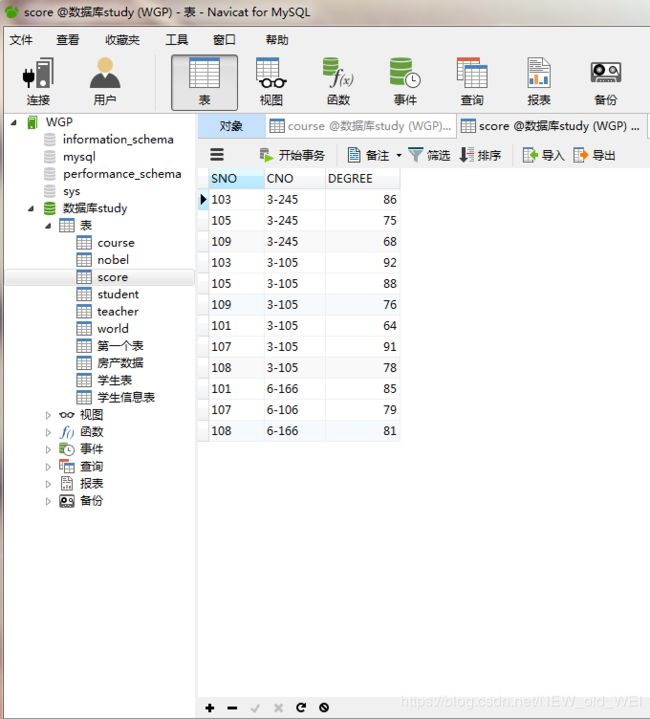
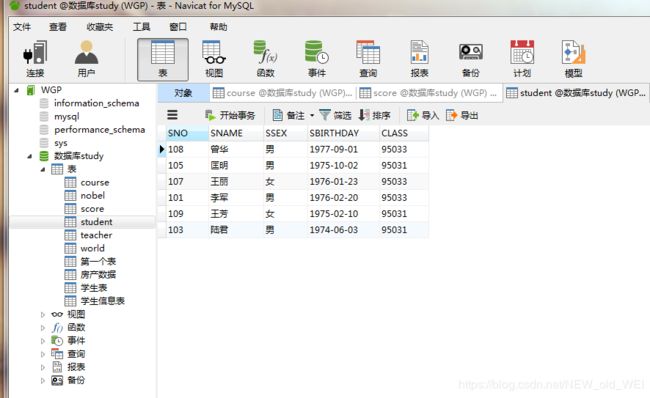
-- 查询score表中成绩在60到80之间的所有记录
SELECT * from score where degree BETWEEN 60 and 80
-- 查询score表中成绩为85,86或88的记录
SELECT * from score where degree in (85,86,88)
-- 查询student表中"95031"班且性别为"女"的同学记录
SELECT * from student where class="95031" and ssex="女"
-- 以class降序查询student表的所有记录
SELECT * from student ORDER BY class DESC
-- 以cno升序、degree降序查询score表的所有记录(升序关键字为asc)
SELECT * from score ORDER BY cno asc, degree desc
-- 查询"95031"班的学生人数
SELECT COUNT(class) from student where class="95031"
-- 查询score表中的最高分的学生学号和课程号(子查询)
SELECT CNO,sno from score where degree=(SELECT MAX(degree) from score )
-- 查询"3-105"号课程的平均分
SELECT AVG(degree) from score WHERE cno="3-105"
-- 查询score表中至少有5名学生选修的并以3开头的课程号和该课程的平均分数(group by,having)
SELECT CNO,AVG(degree)as 平均分,COUNT(sno) as 人数 from score where CNO like "3%" GROUP BY CNO HAVING COUNT(sno)>=5
-- 查询最低分大于70,最高分小于90的sno列(having)
SELECT sno,MAX(degree),MIN(degree)from score GROUP BY sno HAVING MAX(degree)<90 and MIN(degree)>70
-- 查询"95033"班学生所选课程的平均分
SELECT CNO,AVG(degree)from score where SNO in (SELECT SNO FROM student where class="95033")
-- 查询score表中选修"3-105"课程的成绩高于"109"号同学'3-105'课程成绩的所有同学的记录
SELECT * from score where CNO= '3-105' and degree in (SELECT degree from score where CNO="3-105" and degree>(SELECT degree from score where CNO="3-105" and SNO="109"))
-- 查询存在有85分以上成绩的课程cno
SELECT CNO from score where degree>=85 GROUP BY CNO
-- 查询至少有2名男生的班号
SELECT class from student where ssex="男" GROUP BY class HAVING COUNT(class)>=2
-- 查询Student表中不姓“王”的同学记录
SELECT * from student where sname not like "王%"
-- 查询student表中每个学生的姓名和年龄year(now()-year(sbirthday))
SELECT sname,(YEAR(NOW())-year(sbirthday)) as 年龄 from student
备份

短暂小总结
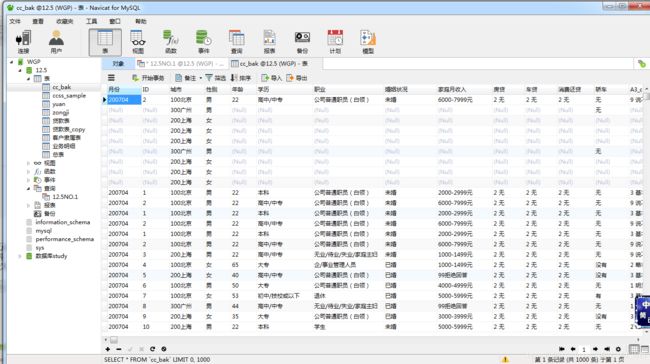

-- 性别为男的轿车改为无
update cc_bak set 轿车="无" where 性别="男"
-- 婚姻状况为未婚 年龄改为22
UPDATE cc_bak set 年龄=22 where 婚姻状况="未婚"
-- 城市北京 并且 性别为女 学历改为本科
UPDATE cc_bak set 学历="本科" where 城市 like "%北京" and 性别="女"
-- 学历为高中/中专 的改为 专科
UPDATE cc_bak set 学历="专科" where 学历 ="高中/中专"
-- 家庭月收入为99拒绝回答的改为"拒绝回答"
UPDATE cc_bak set 家庭月收入="拒绝回答" where 家庭月收入="99拒绝回答"
GROUP_CONCAT(列名) 单元格里有所有选项
SELECT 性别,count(性别) from ccss_sample GROUP BY 性别
SELECT 性别,count(性别) as 人数 ,min(年龄)as 最小,max(年龄)as 最大 from ccss_sample GROUP BY 性别
SELECT 性别,count(性别) as 人数 ,min(年龄)as 最小,max(年龄)as 最大 ,SUM(年龄),AVG(年龄),GROUP_CONCAT(DISTINCT 学历)from ccss_sample GROUP BY 性别
SELECT 城市,COUNT(性别) as 人数,婚姻状况,MAX(id),MIN(id),AVG(年龄) from ccss_sample GROUP BY 城市
SELECT 城市,家庭月收入,COUNT(性别),AVG(Qa3),MAX(Qa4),MIN(总指数) from ccss_sample GROUP BY 城市,家庭月收入
SELECT 性别,GROUP_CONCAT(DISTINCT 学历) from ccss_sample WHERE id<20 GROUP BY 性别

#1 找到平均年龄大于37的城市
SELECT 城市,AVG(年龄) from ccss_sample GROUP BY 城市 HAVING AVG(年龄)>37
#2 找到人数多余500的城市
SELECT 城市,COUNT(性别) as 人数 from ccss_sample GROUP BY 城市 HAVING COUNT(性别)>500
#3 找到前三个热门的职业
SELECT 职业,COUNT(性别) from ccss_sample GROUP BY 职业 ORDER BY COUNT(性别) DESC LIMIT 3
#4 男生最高年龄与女生最高年龄之差
SELECT (SELECT MAX(年龄) from ccss_sample WHERE 性别="男")-(SELECT MAX(年龄) from ccss_sample WHERE 性别="女")
SELECT max(IF(性别="男",年龄,null) )-max(IF(性别="女",年龄,null) ) from ccss_sample
#5 学历按人数排序倒叙
SELECT 学历,COUNT(性别) as 人数 from ccss_sample GROUP BY 学历 ORDER BY 人数 desc
#6 2008年的各地区人员数及平均年龄
SELECT 城市,COUNT(性别) as 人数 ,AVG(年龄) from ccss_sample where 月份 like "2008%" GROUP BY 城市
#7 每年男生的人数
SELECT 月份,性别,LEFT(月份,4)as 年,COUNT(性别) from ccss_sample where 性别="男"GROUP BY 年
#8 各地区A9的答案选项
SELECT 城市,GROUP_CONCAT(a9) from ccss_sample GROUP BY 城市
#9 总指数大于90的各城市人数
SELECT 城市,COUNT(性别)from ccss_sample where 总指数>90 GROUP BY 城市
#10 各职业婚姻状况的分布
SELECT 职业,GROUP_CONCAT(DISTINCT 婚姻状况)from ccss_sample GROUP BY 职业
多个条件语句
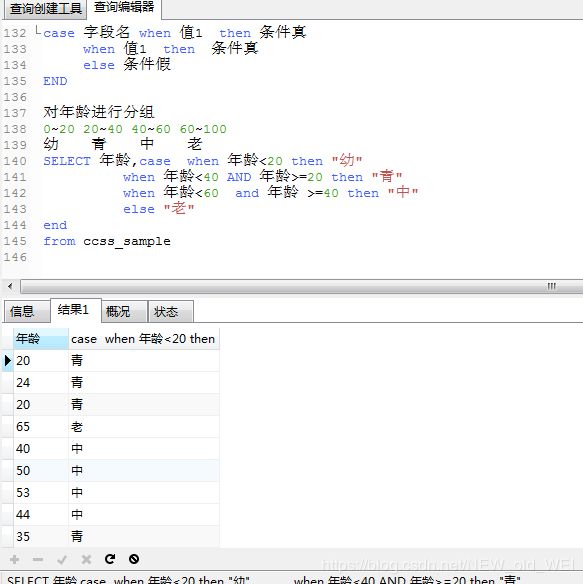
#SELECT 条件语句
case when 条件1 then 条件真
when 条件2 then 条件真
else 条件假
END
case 字段名 when 值1 then 条件真
when 值1 then 条件真
else 条件假
END
对年龄进行分组
0~20 20~40 40~60 60~100
幼 青 中 老
SELECT 年龄,case when 年龄<20 then "幼"
when 年龄<40 AND 年龄>=20 then "青"
when 年龄<60 and 年龄 >=40 then "中"
else "老"
end
from ccss_sample
#1. 轿车列的取值
SELECT GROUP_CONCAT(DISTINCT 轿车) from ccss_sample
#2. 房贷, 车贷, 消费还贷只留代码
SELECT GROUP_CONCAT(DISTINCT 房贷),GROUP_CONCAT(DISTINCT 车贷),GROUP_CONCAT(DISTINCT 消费还贷)from ccss_sample
#3. 学历的取值 , 学历 初中 技校 中专 高中都改为专科及以下
UPDATE ccss_sample set 学历="专科及以下" where 学历 in ("初中" ,"技校","高中/中专")
SELECT GROUP_CONCAT(DISTINCT 学历) from ccss_sample
SELECT IF(LEFT(学历,2)in("初中" ,"技校","高中","中专"),"专科以下",学历) from ccss_sample
#4. 职业中 括号及括号中的内容去掉
UPDATE ccss_sample set 职业 = if(职业 like "%(%",left(职业,locate("(",职业)),职业)
#5. 婚姻状况 设置为对应的编码 0,1,2
SELECT 婚姻状况, case when 婚姻状况="未婚" then 0
when 婚姻状况="已婚" then 1
else 2
end
from ccss_sample
#6. A3_q的包含拒答的,改为拒答
UPDATE ccss_sample set A3_q = "拒答" where A3_q like "%拒答%"
SELECT if(a3_q like "&拒答&","拒答",A3_Q) FROM ccss_sample
#7. 找出 A3_q到 好时机列中有拒答的数据
SELECT *from ccss_sample WHERE a3_q like "%拒答%" or a3a1 like "%拒答%" or a3a2 like "%拒答%" or a4_q like "%拒答%" or a8 like "%拒答%" or a9 like "%拒答%" or a10 like "%拒答%" or 好时机 like "%拒答%"
#8. 计算总指数与逾期指数的差异
SELECT 总指数-预期指数 from ccss_sample
#9. Qs9~Qa16的合计
SELECT QS9+QA3+QA4+QA8+QA9+QA10+QA16 FROM ccss_sample
#10.找到本科男生的职业取值
SELECT GROUP_CONCAT(DISTINCT 职业) from ccss_sample where 学历="本科" and 性别="男"
#11.找出无贷款的记录
SELECT * from ccss_sample WHERE 房贷 like "%无%" and 车贷 like "%无%" and 消费还贷 like "%无%"
#12.找出家庭收入大于5000的记录
SELECT * from ccss_sample where 家庭月收入>5000
#13.找出异常数据 有车贷 但 轿车是没有的
SELECT * from ccss_sample where 车贷 like "%有%" and 轿车="没有"
#14.对总指数,现状指数, 预期指数取整, 进行取整
SELECT ROUND(总指数,0),ROUND(现状指数,0),ROUND(预期指数,0) from ccss_sample
#15.找出职业为教师并且已婚的年龄小于28的
SELECT *from ccss_sample where 职业="教师" and 婚姻状况="已婚" and 年龄<28
#16.找出id大于20 是7月的 地区为北京的
SELECT *,RIGHT(月份,2)from ccss_sample where id>20 and 城市 like "%北京%" HAVING RIGHT(月份,2)=07
#17.找出年龄大于60的女生或者年龄小于25的男生
SELECT * from ccss_sample where (年龄>60 and 性别="女") or (年龄<25 and 性别="男")
#18.找出北京,上海有房贷的人
SELECT * from ccss_sample where (城市 like "%北京%" or "%上海%" )and 房贷 like "%有%"
#19.找出无车贷但有车的人
SELECT * from ccss_sample WHERE 车贷 like "%无%" and 轿车="有"
#20.列出2008年 职业为教师的 家庭收入
SELECT 家庭月收入,LEFT(月份,4) from ccss_sample where 职业="教师" and left(月份,4)=2008
#21.上海男生硕士的职业
SELECT 职业 from ccss_sample where 城市 like "%上海%" and 性别="男" and 学历="硕士"
#22.列出年龄比id小的记录
SELECT * from ccss_sample where 年龄<id
#23 新加 年列,值为 月份中的年
ALTER TABLE ccss_sample add 年 VARCHAR(20)
UPDATE ccss_sample set 年=left(月份,4)
#24 月份 只存月
UPDATE ccss_sample set 月份=RIGHT(月份,2)
#25 城市 只要城市不要城市代码
UPDATE ccss_sample set 城市=RIGHT(城市,2)
#26 学历字段去掉 /
UPDATE ccss_sample set 学历=REPLACE(学历,"/","")
#27 新加收入下限,收入上限,值来自于 家庭月收入
ALTER TABLE ccss_sample add 收入下限 VARCHAR(20)
ALTER TABLE ccss_sample add 收入上限 VARCHAR(20)
UPDATE ccss_sample set 家庭月收入=REPLACE(家庭月收入,"元","")
UPDATE ccss_sample set 收入下限=left(家庭月收入,locate("-",家庭月收入)-1)
UPDATE ccss_sample set 收入上限=right(家庭月收入,LENGTH(家庭月收入)-locate("-",家庭月收入))
#28 房贷 车贷 消费还款 A3_q 都去掉数字
UPDATE ccss_sample set 房贷=REPLACE(房贷,left(房贷,1),""),车贷=REPLACE(车贷,left(车贷,1),""),消费还贷=REPLACE(消费还贷,left(消费还贷,1),""),a3_q=REPLACE(a3_q,left(a3_q,1),"")
#29 A3a1 A3a2 的数据#NULL!改为 NULL
UPDATE ccss_sample set a3a1=null where a3a1= "#NULL!"
UPDATE ccss_sample set a3a2=null where a3a2= "#NULL!"
#30 把 职业为 企/事业管理人员 的 /去掉
UPDATE ccss_sample set 职业=REPLACE(职业,"/","")WHERE 职业="企/事业管理人员"
#31 职业 中含有失业的,改为失业
UPDATE ccss_sample set 职业="失业"WHERE 职业 like "%失业%"
#贷款表,客户隶属表
SELECT *from `贷款表`
SELECT * from `客户隶属表`
#大区 ,借款类型 无缝连接
SELECT CONCAT(大区,借款类型) from `贷款表`
#借款类型 所属销售 以 |线分割连接
SELECT CONCAT(借款类型,"|",所属销售) from `贷款表`
#所属销售中 "文" 字所在的位置(通过三个函数查找)
SELECT LOCATE("文",所属销售)from `贷款表`
SELECT POSITION("文" in 所属销售)from `贷款表`
SELECT INSTR(所属销售,"文")from `贷款表`
#脱敏手机中 5的位置(客户隶属表)
SELECT LOCATE(5,客户姓名) from `客户隶属表`
#借款类型的字符串长度,字节长度
SELECT length(借款类型)from `贷款表`
SELECT char_length(借款类型)from `贷款表`
#精英A类 和 精英B类 都改为精英类
UPDATE `贷款表` set 借款类型="精英类" where 借款类型 in("精英A类","精英B类")
#统计个借款类型的人数,平均金额,最大金额,最小金额
SELECT 借款类型,COUNT(借款类型),AVG(金额),MAX(金额),MIN(金额) from `贷款表` GROUP BY 借款类型
#统计个借款类型的人数 显示格式为
-- 公积金类 精英类 工薪类
-- 人数 人数 人数
SELECT sum(IF(借款类型="公积金类",1,0))as 公积金类,sum(IF(借款类型="精英类",1,0))as 精英类,sum(IF(借款类型="工薪类",1,0))as 工薪类 from 贷款表
#按大区统计平均金额,最大金额,最小金额
SELECT 大区,AVG(金额),MAX(金额),MIN(金额)from 贷款表 GROUP BY 大区
#按大区统计借款类型的人数 显示格式为
-- 公积金类 精英类 工薪类
-- 华西 人数 人数 人数
-- 华北 人数 人数 人数
SELECT 大区,sum(IF(借款类型="公积金类",1,0))as 公积金类,sum(IF(借款类型="精英类",1,0))as 精英类,sum(IF(借款类型="工薪类",1,0))as 工薪类 from 贷款表 GROUP BY 大区
.
#
总表
-- 去掉课程名称的 括号及其中内容update
UPDATE 总表 set 课程名称=if(课程名称 like "%(%",LEFT(课程名称,LOCATE("(",课程名称)-1),课程名称)
-- 按开课单位统计课程名称数
SELECT 课程名称,开课单位,COUNT(开课单位)from 总表 GROUP BY 课程名称,开课单位
-- 找出清华大学 或人民大学出版的图书
SELECT 教材名称 from 总表 WHERE 出版社 like "%清华大学%" or 出版社 like "%人民大学%"
-- 保险学院没带保险字样的书籍 的占比
SELECT (SELECT COUNT(教材名称)from 总表 where 开课单位="保险学院" and 教材名称 not like "%保险%")/(SELECT COUNT(教材名称)from 总表 where 开课单位="保险学院")
-- 各开课单位开课数的占比
SELECT 开课单位,count(课程名称)/(SELECT COUNT(课程名称) from 总表) from 总表 GROUP BY 开课单位

-- #业务明细表
-- 各地区各年的平均收入,最高收入
SELECT 城市,left(结算日期,4),AVG(收入),MAX(收入)from `业务明细` GROUP BY 城市,left(结算日期,4)
-- 各年各用户代码的平均收入总收入,
SELECT left(结算日期,4),用户代码,AVG(收入),sum(收入)from `业务明细` GROUP BY left(结算日期,4),用户代码
-- 各业务的总收入并排序
SELECT 业务代码,SUM(收入) from `业务明细` GROUP BY 业务代码 ORDER BY SUM(收入)
-- 各年个月的总收入,并按年升序,收入倒叙
SELECT left(结算日期,7),sum(收入)from `业务明细` GROUP BY left(结算日期,7) ORDER BY left(结算日期,4) ASC, sum(收入) desc
-- 各地区各用户代码的总收入 并按地区升序,收入倒叙
SELECT 城市,用户代码,SUM(收入)from `业务明细` GROUP BY 城市,用户代码 ORDER BY 城市 asc,SUM(收入) desc
-- 各地区个业务代码的总收入
-- 显示格式为
-- 业务代码 CPRJ cpyj ...
-- 华西 总收入
SELECT 城市,
sum(if(业务代码='CPRJ',收入,0))as CPRJ,
sum(if(业务代码='CPYJ',收入,0))as CPYJ,
sum(if(业务代码='FWHL',收入,0))as FWHL,
sum(if(业务代码='FWPX',收入,0))as FWPX
FROM `业务明细`
GROUP BY 城市
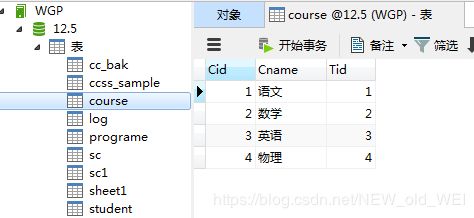
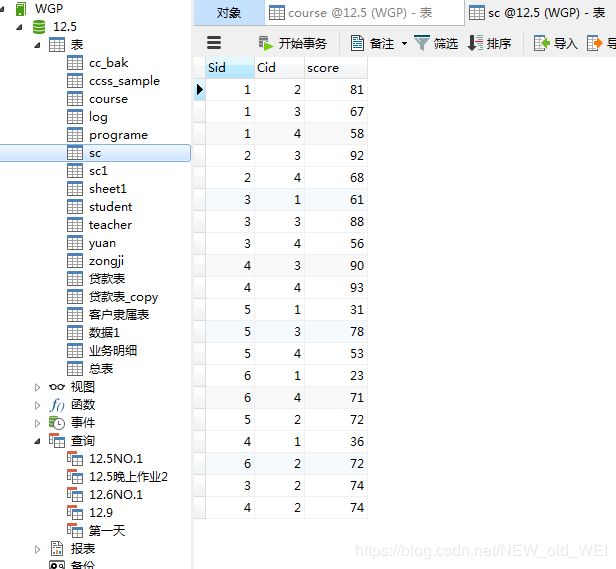
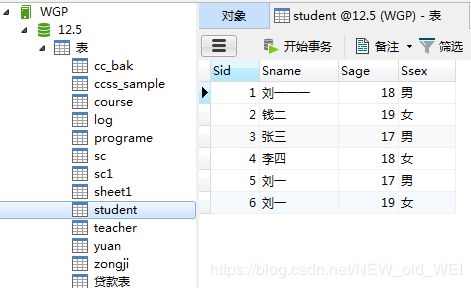
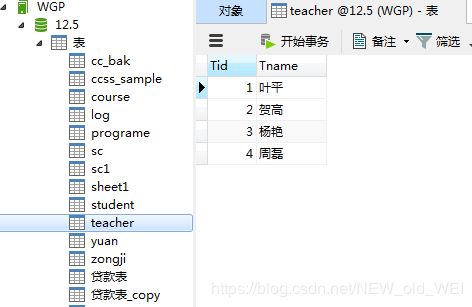
#各科的报考人数
SELECT cname,COUNT(Sid) from sc left join course ON sc.cid=course.cid GROUP BY Cname
#每个学生的参与课程
SELECT sname,(SELECT GROUP_CONCAT(cname) from sc LEFT JOIN course on sc.cid=course.cid WHERE sid = student.sid) from student
#各课程老师的名字
SELECT cname,(SELECT tname from teacher where tid=course.tid) from course
#每个学生的最高分
SELECT sname,MAX(score) from student LEFT JOIN sc on student.sid=sc.sid group by sname
#每个老师所教的课程名名
SELECT tname,(SELECT cname from course WHERE tid=teacher.tid) from teacher
#每科中的最高分是谁
SELECT *,(SELECT MAX(score) from sc where cid = course.cid) as fen,
(SELECT sname from sc
INNER JOIN student on sc.sid=student.Sid
where Cid = course.cid and score=(SELECT MAX(score) from sc where cid = course.cid)
) as REN,
(SELECT sc.sid from sc
INNER JOIN student on sc.sid=student.Sid
where Cid = course.cid and score=(SELECT MAX(score) from sc where cid = course.cid)
) as xue
from course
#学生哪科考最好
# 1 查询“1”课程比“2”课程成绩高的所有学生的学号;
SELECT sname from student
where (SELECT score from sc where cid=1 and sid=student.sid) > (SELECT score from sc where cid=2 and sid=student.sid)
SELECT * from
(SELECT sid,cid,score as score_1 from sc where cid=1)as ke1
INNER JOIN
(SELECT sid,cid,score as score_2 from sc where cid=2)as ke2
on ke1.sid=ke2.sid
WHERE score_1>score_2
# 2 查询平均成绩大于60分的同学的学号和平均成绩;
SELECT sid,AVG(score)from sc GROUP BY sid HAVING AVG(score)>60
SELECT *,(SELECT AVG(score) from sc where sid=student.sid)as pingjun from student
where (SELECT AVG(score) from sc where sid=student.sid)>60
# 3 查询所有同学的学号、姓名、选课数、总成绩;
SELECT sid,(SELECT sname from student where sid=sc.sid),COUNT(cid),SUM(score)from sc GROUP BY sid
SELECT sid,sname,(SELECT COUNT(cid) from sc where sid=student.sid),(SELECT sum(score) from sc where sid=student.sid) from student
# 4 查询姓“李”的老师的个数;
SELECT COUNT(tname) from teacher WHERE tname like "李%"
# 5 查询没学过“叶平”老师课的同学的学号、姓名;
SELECT * from student where sid NOT in (
SELECT sid from teacher
LEFT JOIN course on teacher.tid=course.Tid
LEFT JOIN sc on sc.cid=course.Cid
WHERE tname="叶平")
# 6 查询学过“1”并且也学过编号“2”课程的同学的学号、姓名;
SELECT student.sid,sname from student
WHERE (SELECT COUNT(1) from sc WHERE (cid = 1 or cid = 2) and sid = student.sid) = 2
# 7 查询学过“叶平”老师所教的所有课的同学的学号、姓名;
SELECT student.sid,sname
from student
LEFT JOIN sc ON student.sid=sc.Sid
LEFT JOIN course on sc.cid=course.Cid
LEFT JOIN teacher on course.tid=teacher.tid
WHERE tname="叶平"
# 8 查询课程编号“2”的成绩比课程编号“1”课程低的所有同学的学号、姓名;
SELECT sid,sname from student
where (SELECT score from sc where sid=student.sid and cid=2)<(SELECT score from sc where sid=student.sid and cid=1)
# 9 查询有课程成绩小于60分的同学的学号、姓名;
SELECT sc.sid,sname,Min(score) from sc
INNER JOIN student on sc.sid=student.Sid
GROUP BY sc.Sid
having Min(score)<60
SELECT *from student
where EXISTS(SELECT * from sc where score <60 and sid=student.sid)
# 10 查询没有学全所有课的同学的学号、姓名;
SELECT sid,COUNT(sid) shu from sc
GROUP BY Sid
HAVING shu<(SELECT COUNT(cid) from course)
-- 查询没有学全所有课的同学的学号、姓名,课程号;
SELECT *,(SELECT GROUP_CONCAT(cid) from sc where sid=student.sid),
(SELECT GROUP_CONCAT(cid)from course where cid not in (SELECT cid from sc where sid =student.sid))
from student
# 11 查询至少有一门课与学号为“001”的同学所学相同的同学的学号和姓名;
SELECT DISTINCT sc.sid,sname from sc
INNER JOIN student on sc.sid=student.sid
where sc.sid!=1 and cid in (
SELECT cid from sc where sid =1)
# 12 把“SC”表中“叶平”老师教的课的成绩都更改为此课程的平均成绩;
CREATE TABLE sc1
SELECT * from sc
SELECT AVG(score) from sc,course,teacher
where sc.cid=course.cid and course.tid=teacher.Tid
and tname='叶平'
UPDATE sc set score=
# 13 查询和“2”号的同学学习的课程完全相同的其他同学学号和姓名;
SELECT sid,count(sid) shu from sc where sid!=2 and cid not in (SELECT cid from sc where sid=2)
GROUP BY sid
# 14 删除学习“叶平”老师课的SC表记录;
DELETE from scl
where cid in ()
# 15 向SC表中插入一些记录,这些记录要求符合以下条件:①没有上过编号“002”课程的同学学号;②插入“002”号课程的平均成绩;
INSERT sc1 VALUES(
(SELECT sid from student where sid not in (
SELECT sid from sc where cid=2))
,
2,
(SELECT avg(score) from sc WHERE cid=2))
SELECT * from sc1
desc sc1
INSERT sc1
SELECT sid,2,(SELECT avg(score) from sc WHERE cid=2) from student where sid not in(
SELECT sid from sc where cid=2)
# 16 按平均成绩从低到高显示所有学生的“语文”、“数学”、“英语”三门的课程成绩,按如下形式显示:
#学生ID,语文,数学,英语,有效课程数,有效平均分
#1
SELECT *,(SELECT score FROM sc where sid=student.sid and cid=1) as 语文,
(SELECT score from sc where sid =student.sid and cid=2)as 数学,
(SELECT COUNT(cid) from sc where sid =student.sid)as 有效课程数,
(SELECT AVG(score)from sc where sid=student.sid)as 平均分
from student
#2
SELECT sc.sid,sname,sum(if(cid=1,score,null))as 语文,
sum(if(cid=2,score,null))as 数学,
COUNT(cid) 有效课程数,
AVG(score) 平均分
from student
left join sc on student.sid=sc.Sid
group by sc.sid,sname
# 17 查询各科成绩最高和最低的分:以如下形式显示:课程ID,最高分,最低分;
SELECT cid,max(score),MIN(score) from sc GROUP BY cid
# 18 按各科平均成绩从低到高和及格率的百分数从高到低顺序;
SELECT cid,AVG(score) as pingjunfen,SUM(score>=60)/COUNT(sid) jigelv from sc
GROUP BY Cid
ORDER BY pingjunfen asc ,jigelv desc
# 19 查询如下课程平均成绩和及格率的百分数(备注:需要在1行内显示:
#语文平均分,语文及格比,数学平均分,数学及格比,英语平均分,英语及格比
SELECT AVG(IF(cid=1,score,null)) 语文平均分,
concat(round(SUM(cid=1 and score>=60)/sum(cid=1)*100,2),"%") 语文及格比,
AVG(IF(cid=2,score,null)) 数学平均分,
concat(round(SUM(cid=2 and score>=60)/sum(cid=2)*100,2),"%") 数学及格比,
AVG(IF(cid=3,score,null)) 英语平均分,
concat(round(SUM(cid=3 and score>=60)/sum(cid=3)*100,2),"%") 英语及格比
from sc
# 20 查询不同老师所教不同课程平均分从高到低显示( Cid,Cname,Tid,Tname,平均分)
SELECT course.cid,course.cname,teacher.tid,teacher.tname,avg(score)as 平均分 FROM course
INNER JOIN sc on sc.cid=course.cid
INNER JOIN teacher on teacher.tid=course.Tid
GROUP BY tname
ORDER BY 平均分 desc
# 21 排名第 3 名到第 6 名的学生成绩单 (Sid,Sname,语文,数学,英语,物理,平均成绩 )
SELECT sc.sid,sname,sum(if(cid=1,score,null))as 语文,
sum(if(cid=2,score,null))as 数学,
AVG(score) 平均分
from student
left JOIN sc on student.sid=sc.Sid
GROUP BY sc.sid,sname
ORDER BY 平均分 DESC
LIMIT 2,4
# 22 统计列印各科成绩,各分数段人数:Cid,Cname,[100-85],[85-70],[70-60],[ <60]
SELECT
cid,
SUM(score<60)'[ <60]',
SUM(score>=60 and score<70)'[70-60]',
SUM(score>=70 and score<85)'[85-70]',
SUM(score>=85 and score<=100)'[100-85]',
COUNT(sid)
FROM sc
GROUP BY cid
# 23 学生平均成绩及其名次;(Sid,sName,平均分,排名)
set @mingci=0;
SELECT *,@mingci:=@mingci+1 as mingci from(
SELECT sid,AVG(score) pingjun from sc
GROUP BY sid
ORDER BY pingjun desc)as A
# 24 查询各科成绩前三名的记录:(不考虑成绩并列情况)
SELECT *from sc
where
(SELECT COUNT(sid) from sc as sub_sc WHERE sub_sc.cid=sc.cid and sub_sc.score>sc.score)<3
ORDER BY cid,score desc
SELECT * from(
SELECT *,(SELECT score from sc as sub_sc where cid =sc.cid order by score desc LIMIT 2,1)as disan from sc
ORDER BY cid,score desc )as A
WHERE score>disan
# 25 查询每门课程被选修的学生数;
SELECT cid,COUNT(sid)from sc GROUP BY cid
# 26 查询出只选修了一门课程的全部学生的学号和姓名;
SELECT sc.sid,sname,COUNT(cid) from sc
INNER JOIN student on sc.sid=student.sid
GROUP BY sid
HAVING COUNT(cid)=1
# 27 查询男生、女生的人数;
SELECT ssex,COUNT(ssex) from student GROUP BY ssex
# 28 查询姓“张”的学生名单;
SELECT sname from student WHERE sname like "张%"
# 29 查询同名同姓学生名单,并统计同名人数;
SELECT sname,COUNT(sname) from student GROUP BY sname HAVING COUNT(sname)>1
# 30 查询每门课程的平均成绩,结果按平均成绩升序排列,平均成绩相同时,按课程号降序排列;
SELECT course.cid,
course.cname,
AVG(score) from course
INNER JOIN sc on course.cid=sc.cid
GROUP BY cname
ORDER BY AVG(score),
cid desc
# 31 查询平均成绩大于85的所有学生的学号、姓名和平均成绩;
SELECT sc.sid,
sname,
avg(score)as 平均分 from sc
INNER JOIN student on sc.sid=student.sid
GROUP BY sname
# 32 查询课程名称为“数学”,且分数低于60的学生姓名和分数;
SELECT sname,score from sc
INNER JOIN student on sc.sid=student.sid
INNER JOIN course on sc.cid=course.cid
WHERE cname="数学" and score<60
# 33 查询所有学生的选课情况(Sid,Sname, Cid,Cname)
SELECT sc.sid,sname,sc.cid,cname from sc
INNER JOIN student on sc.sid=student.sid
INNER JOIN course on sc.cid=course.cid
# 34 查询任何一门课程成绩在70分以上的姓名、课程名称和分数; (Sid,Sname,Cname,score)
SELECT sname,cname,score from sc
INNER JOIN student on sc.sid=student.sid
INNER JOIN course on sc.cid=course.cid
where score>70
# 35 查询有不及格的课程,并按课程号从大到小排列;
SELECT cid,score from sc
where score<60
ORDER BY cid desc
# 36 查询课程编号为003且课程成绩在80分以上的学生的学号和姓名;
SELECT sc.sid,sname,score from sc
INNER JOIN student on sc.sid=student.sid
where score>80 and cid=3
# 37 查询选修“杨艳”老师所授课程的学生中,成绩最高的学生姓名及其成绩;
SELECT sname,score from course
INNER JOIN sc on sc.cid=course.cid
INNER JOIN student on sc.sid=student.sid
INNER JOIN teacher on teacher.tid=course.tid
WHERE tname="杨艳"
ORDER BY score desc
LIMIT 1
# 38 查询各个课程及相应的选修人数;
SELECT cname,COUNT(sc.cid) from sc
INNER JOIN course on course.cid=sc.cid
GROUP BY cname
# 39 查询不同课程但成绩相同的学生的学号、课程号、学生成绩;
SELECT sid,sc.cid,score,COUNT(score)as 分数个数 from course
INNER JOIN sc on sc.cid=course.cid
GROUP BY sid,cid
HAVING 分数个数>1
# 40 查询每门课程成绩最好的前两名;
SELECT cname,sname,score from course
INNER JOIN sc on sc.cid=course.cid
INNER JOIN student on sc.sid=student.sid
where
(SELECT COUNT(sid) from sc as sub_sc WHERE sub_sc.cid=sc.cid and sub_sc.score>sc.score)<2
ORDER BY cname,score desc
# 41 统计每门课程的学生选修人数(超过10人的课程才统计)。要求输出课程号和选修人数,查询结果按人数降序排列,查询结果按人数降序排列,若人数相同,按课程号升序排列
SELECT cid,COUNT(cid)from sc
GROUP BY cid
ORDER BY COUNT(cid) desc,
cid asc
# 42 检索至少选修两门课程的学生学号;
SELECT sid,COUNT(cid) from sc
GROUP BY sid
HAVING COUNT(cid)>1
# 43 查询全部学生都选修的课程的课程号和课程名;
SELECT sc.cid,cname,COUNT(sid)from sc
INNER JOIN course on sc.cid=course.cid
GROUP BY cid
HAVING COUNT(sid)=(SELECT COUNT(DISTINCT sid) from sc)
# 44 查询没学过“叶平”老师讲授的任一门课程的学生姓名;
SELECT sname,GROUP_CONCAT(tname)from course
INNER JOIN sc on sc.cid=course.cid
INNER JOIN student on sc.sid=student.sid
INNER JOIN teacher on teacher.tid=course.tid
GROUP BY sname
HAVING GROUP_CONCAT(tname) not like "%叶平%"
# 45 查询两门以上不及格课程的同学的学号及其平均成绩;
SELECT sid,COUNT(score),AVG(score)from sc
WHERE score < 60
GROUP BY sid
HAVING COUNT(score)>=2