flink源码分析-flink-yarn-session job独立部署模式的任务提交流程
前言
最近一直在处理着规则引擎项目在flink job的部署问题。目前咱们这边的基础设施有hadoop集群,所以想将flink job部署到yarn上。目前flink on yarn的部署方式有2种:
- flink 与 yarn建立session(通过yarn-session.sh脚本启动),然后所有的job通过该session去提交执行;
- flink per job on yarn /独立部署模式(通过flink run 命令)
以上2种方式有啥本质的区别呢?第一种方式,flink像yarn申请好空间之后,就不能改变了,当提交新的job的时候,如果空间不足,则只能等前一个job执行完成并释放空间才能提交执行,否则无法提交任务。第二种方式,是一个任务会对应一个yarn上job,向yarn申请资源,直到作业执行完成,并不会影响下一个作业的正常运行,除非是yarn上面没有任何资源的情况下。本篇就从源码的角度来分析一下flink job的独立部署模式(flink版本为:1.9.0)
flink job独立模式分析
获取入口类
flink rest client的开发,首要任务是理清flink per job on yarn的job提交流程,只有理清才能进行开发工作。首先我们从flink bin目录下的flink 脚本开始吧。
./bin/flink run -m yarn-cluster ./examples/batch/WordCount.jar
这个是flink 官网提供的一个提交一个单个job到yarn上执行的example.
我们打开bin目录下的flink 脚本的最后一行:
# Add HADOOP_CLASSPATH to allow the usage of Hadoop file systems
exec $JAVA_RUN $JVM_ARGS "${log_setting[@]}" -classpath "`manglePathList "$CC_CLASSPATH:$INTERNAL_HADOOP_CLASSPATHS"`" org.apache.flink.client.cli.CliFrontend "$@"
得知,命令行执行提交job的入口类为org.apache.flink.client.cli.CliFrontend。
入口类main方法解析
我们来看一下org.apache.flink.client.cli.CliFrontend的main方法:
/**
* Submits the job based on the arguments.
*/
public static void main(final String[] args) {
EnvironmentInformation.logEnvironmentInfo(LOG, "Command Line Client", args);
// 1. find the configuration directory
final String configurationDirectory = getConfigurationDirectoryFromEnv();
// 2. load the global configuration
final Configuration configuration = GlobalConfiguration.loadConfiguration(configurationDirectory);
// 3. load the custom command lines
final List<CustomCommandLine<?>> customCommandLines = loadCustomCommandLines(
configuration,
configurationDirectory);
try {
final CliFrontend cli = new CliFrontend(
configuration,
customCommandLines);
SecurityUtils.install(new SecurityConfiguration(cli.configuration));
int retCode = SecurityUtils.getInstalledContext()
.runSecured(() -> cli.parseParameters(args));
System.exit(retCode);
}
catch (Throwable t) {
final Throwable strippedThrowable = ExceptionUtils.stripException(t, UndeclaredThrowableException.class);
LOG.error("Fatal error while running command line interface.", strippedThrowable);
strippedThrowable.printStackTrace();
System.exit(31);
}
}
在这个方法主要干了3件事情:初始化系统全局的配置信息、解析命令行参数与命令、创建CliFrontend的对象并调用parseParameters方法。
parseParameters
接着我们看一下parseParameters方法干了什么
/**
* Parses the command line arguments and starts the requested action.
*
* @param args command line arguments of the client.
* @return The return code of the program
*/
public int parseParameters(String[] args) {
......
// get action
String action = args[0];
// remove action from parameters
final String[] params = Arrays.copyOfRange(args, 1, args.length);
try {
// do action
switch (action) {
case ACTION_RUN:
run(params);
return 0;
case ACTION_LIST:
list(params);
return 0;
case ACTION_INFO:
info(params);
return 0;
case ACTION_CANCEL:
cancel(params);
return 0;
case ACTION_STOP:
stop(params);
return 0;
case ACTION_SAVEPOINT:
savepoint(params);
return 0;
case "-h":
case "--help":
CliFrontendParser.printHelp(customCommandLines);
return 0;
case "-v":
case "--version":
String version = EnvironmentInformation.getVersion();
String commitID = EnvironmentInformation.getRevisionInformation().commitId;
System.out.print("Version: " + version);
System.out.println(commitID.equals(EnvironmentInformation.UNKNOWN) ? "" : ", Commit ID: " + commitID);
return 0;
default:
System.out.printf("\"%s\" is not a valid action.\n", action);
System.out.println();
System.out.println("Valid actions are \"run\", \"list\", \"info\", \"savepoint\", \"stop\", or \"cancel\".");
System.out.println();
System.out.println("Specify the version option (-v or --version) to print Flink version.");
System.out.println();
System.out.println("Specify the help option (-h or --help) to get help on the command.");
return 1;
}
} catch (CliArgsException ce) {
return handleArgException(ce);
} catch (ProgramParametrizationException ppe) {
return handleParametrizationException(ppe);
} catch (ProgramMissingJobException pmje) {
return handleMissingJobException();
} catch (Exception e) {
return handleError(e);
}
}
这个方法主要干了一件事情:获取命令第一个参数(动作类型),然后根据动作类型执行相应的操作;具体的动作如下:
- run:执行任务;
- list:任务列表;
- info:查询job的执行计划信息;
- cancel:取消一个job;
- stop:停止一个job并执行savepoint;
- savepoint:执行job的savepoint;
- -h/–help:帮助;
- -v/–version:查看flink版本;
run方法执行提交流程解析
本次我们主要看job是如何提交的,所以我们得看一下run方法:
/**
* Executions the run action.
*
* @param args Command line arguments for the run action.
*/
protected void run(String[] args) throws Exception {
LOG.info("Running 'run' command.");
final Options commandOptions = CliFrontendParser.getRunCommandOptions();
final Options commandLineOptions = CliFrontendParser.mergeOptions(commandOptions, customCommandLineOptions);
final CommandLine commandLine = CliFrontendParser.parse(commandLineOptions, args, true);
final RunOptions runOptions = new RunOptions(commandLine);
// evaluate help flag
if (runOptions.isPrintHelp()) {
CliFrontendParser.printHelpForRun(customCommandLines);
return;
}
if (!runOptions.isPython()) {
// Java program should be specified a JAR file
if (runOptions.getJarFilePath() == null) {
throw new CliArgsException("Java program should be specified a JAR file.");
}
}
final PackagedProgram program;
try {
LOG.info("Building program from JAR file");
program = buildProgram(runOptions);
}
catch (FileNotFoundException e) {
throw new CliArgsException("Could not build the program from JAR file.", e);
}
final CustomCommandLine<?> customCommandLine = getActiveCustomCommandLine(commandLine);
try {
runProgram(customCommandLine, commandLine, runOptions, program);
} finally {
program.deleteExtractedLibraries();
}
}
该方法主要干了3件事情:
1. 根据用户提交的jar来构建PackagedProgram对象;
2. 获取当前活动的自定义命令行(CustomCommandLine);
3. 调用runProgram。
我们来具体分析一下这3件事情:
根据用户提交的jar来构建PackagedProgram对象
首先我们得搞清楚PackagedProgram这个类是干嘛用的,还是来看一下源码:
/**
* This class encapsulates represents a program, packaged in a jar file. It supplies
* functionality to extract nested libraries, search for the program entry point, and extract
* a program plan.
*/
public class PackagedProgram {
//此次省略1千字
......
}
在这个类中,我省略了很多,但是我们重点关注这个类的注释。从注释中我们知道了这个类要干以下三件事情:
- 从jar中抽取出job依赖的jar包(解析jar目录结构,如果存在lib目录,则对该目录进行扫描,看是否有jar包,如果有,则会提取jar包并写入到本地的临时目录中,供后期使用。);
- 从jar包中获取job的入口类(解析jar中的manifest,如果有program-class配置,则优先使用该配置,否则再看一下是否有Main-Class配置);
- 从jar包中获取job的执行计划;
获取当前活动的自定义命令行(CustomCommandLine)
CustomCommandLine是个接口,我看一下这个接口的实现类有哪些:

实现类有:DefaultCLI、DummyCustomCommandLine、FlinkYarnSessionCli。然后看一下,当前run方法里的CustomCommandLine到底指的是哪一个呢?我们再回顾头看一下CliFrontend的main方法里:
// 3. load the custom command lines
final List<CustomCommandLine<?>> customCommandLines = loadCustomCommandLines(
configuration,
configurationDirectory);
在main方法里调用了loadCustomCommandLines方法,loadCustomCommandLines内容如下:
public static List<CustomCommandLine<?>> loadCustomCommandLines(Configuration configuration, String configurationDirectory) {
List<CustomCommandLine<?>> customCommandLines = new ArrayList<>(2);
// Command line interface of the YARN session, with a special initialization here
// to prefix all options with y/yarn.
// Tips: DefaultCLI must be added at last, because getActiveCustomCommandLine(..) will get the
// active CustomCommandLine in order and DefaultCLI isActive always return true.
final String flinkYarnSessionCLI = "org.apache.flink.yarn.cli.FlinkYarnSessionCli";
try {
customCommandLines.add(
loadCustomCommandLine(flinkYarnSessionCLI,
configuration,
configurationDirectory,
"y",
"yarn"));
} catch (NoClassDefFoundError | Exception e) {
LOG.warn("Could not load CLI class {}.", flinkYarnSessionCLI, e);
}
customCommandLines.add(new DefaultCLI(configuration));
return customCommandLines;
}
到这里,我们就可以知道run方法里的CustomCommandLine就是FlinkYarnSessionCli。
runProgram方法分析
接着我们看run方法里调用的runProgram方法具体干了什么。
private <T> void runProgram(
CustomCommandLine<T> customCommandLine,
CommandLine commandLine,
RunOptions runOptions,
PackagedProgram program) throws ProgramInvocationException, FlinkException {
final ClusterDescriptor<T> clusterDescriptor = customCommandLine.createClusterDescriptor(commandLine);
try {
final T clusterId = customCommandLine.getClusterId(commandLine);
final ClusterClient<T> client;
// directly deploy the job if the cluster is started in job mode and detached
if (clusterId == null && runOptions.getDetachedMode()) {
int parallelism = runOptions.getParallelism() == -1 ? defaultParallelism : runOptions.getParallelism();
final JobGraph jobGraph = PackagedProgramUtils.createJobGraph(program, configuration, parallelism);
final ClusterSpecification clusterSpecification = customCommandLine.getClusterSpecification(commandLine);
client = clusterDescriptor.deployJobCluster(
clusterSpecification,
jobGraph,
runOptions.getDetachedMode());
logAndSysout("Job has been submitted with JobID " + jobGraph.getJobID());
try {
client.shutdown();
} catch (Exception e) {
LOG.info("Could not properly shut down the client.", e);
}
} else {
final Thread shutdownHook;
if (clusterId != null) {
client = clusterDescriptor.retrieve(clusterId);
shutdownHook = null;
} else {
// also in job mode we have to deploy a session cluster because the job
// might consist of multiple parts (e.g. when using collect)
final ClusterSpecification clusterSpecification = customCommandLine.getClusterSpecification(commandLine);
client = clusterDescriptor.deploySessionCluster(clusterSpecification);
// if not running in detached mode, add a shutdown hook to shut down cluster if client exits
// there's a race-condition here if cli is killed before shutdown hook is installed
if (!runOptions.getDetachedMode() && runOptions.isShutdownOnAttachedExit()) {
shutdownHook = ShutdownHookUtil.addShutdownHook(client::shutDownCluster, client.getClass().getSimpleName(), LOG);
} else {
shutdownHook = null;
}
}
try {
client.setPrintStatusDuringExecution(runOptions.getStdoutLogging());
client.setDetached(runOptions.getDetachedMode());
int userParallelism = runOptions.getParallelism();
LOG.debug("User parallelism is set to {}", userParallelism);
if (ExecutionConfig.PARALLELISM_DEFAULT == userParallelism) {
userParallelism = defaultParallelism;
}
executeProgram(program, client, userParallelism);
} finally {
if (clusterId == null && !client.isDetached()) {
// terminate the cluster only if we have started it before and if it's not detached
try {
client.shutDownCluster();
} catch (final Exception e) {
LOG.info("Could not properly terminate the Flink cluster.", e);
}
if (shutdownHook != null) {
// we do not need the hook anymore as we have just tried to shutdown the cluster.
ShutdownHookUtil.removeShutdownHook(shutdownHook, client.getClass().getSimpleName(), LOG);
}
}
try {
client.shutdown();
} catch (Exception e) {
LOG.info("Could not properly shut down the client.", e);
}
}
}
} finally {
try {
clusterDescriptor.close();
} catch (Exception e) {
LOG.info("Could not properly close the cluster descriptor.", e);
}
}
}
该方法涉及到的业务逻辑比较多,也是比较重要的方法,还是通过流程图来梳理一下:

以上是这个方法执行的整个流程。我们本次只关注任务提交的流程,一些细节后期将会写篇(比如JobGraph是什么东西)。在这个方法里,我们重点关注在Detached模式下的clusterDescriptor.deployJobCluster方法与attached模式下的executeProgram。我们先来看一下clusterDescriptor.deployJobCluster方法。这里的clusterDescriptor实际上就是YarnClusterDescriptor类的实例。
独立模式部署实现
在上面的方法里,独立部署模式调用的是clusterDescriptor.deployJobCluster,我们先来看看这个方法的实现:
@Override
public ClusterClient<ApplicationId> deployJobCluster(
ClusterSpecification clusterSpecification,
JobGraph jobGraph,
boolean detached) throws ClusterDeploymentException {
// this is required because the slots are allocated lazily
jobGraph.setAllowQueuedScheduling(true);
try {
return deployInternal(
clusterSpecification,
"Flink per-job cluster",
getYarnJobClusterEntrypoint(),
jobGraph,
detached);
} catch (Exception e) {
throw new ClusterDeploymentException("Could not deploy Yarn job cluster.", e);
}
}
在deployJobCluster方法里又调用了deployInternal方法,deployInternal方法所需参数有以下几个:
- ClusterSpecification:集群运行时的具体参数配置 ;
- ApplicationName:集群应用的名称,这里已经设置为Flink per-job cluster;
- yarnClusterEntrypoint:启动AM/JobManager的入口类,这里调用了getYarnJobClusterEntrypoint()方法并返回YarnJobClusterEntrypoint.class.getName();
- JobGraph:job执行的结构图;
- detached:是否时独立模式,这里实际上一直都是true;
我们看一下deployInternal方法的具体实现:
/**
* This method will block until the ApplicationMaster/JobManager have been deployed on YARN.
*
* @param clusterSpecification Initial cluster specification for the Flink cluster to be deployed
* @param applicationName name of the Yarn application to start
* @param yarnClusterEntrypoint Class name of the Yarn cluster entry point.
* @param jobGraph A job graph which is deployed with the Flink cluster, {@code null} if none
* @param detached True if the cluster should be started in detached mode
*/
protected ClusterClient<ApplicationId> deployInternal(
ClusterSpecification clusterSpecification,
String applicationName,
String yarnClusterEntrypoint,
@Nullable JobGraph jobGraph,
boolean detached) throws Exception {
// ------------------ Check if configuration is valid --------------------
validateClusterSpecification(clusterSpecification);
if (UserGroupInformation.isSecurityEnabled()) {
// note: UGI::hasKerberosCredentials inaccurately reports false
// for logins based on a keytab (fixed in Hadoop 2.6.1, see HADOOP-10786),
// so we check only in ticket cache scenario.
boolean useTicketCache = flinkConfiguration.getBoolean(SecurityOptions.KERBEROS_LOGIN_USETICKETCACHE);
UserGroupInformation loginUser = UserGroupInformation.getCurrentUser();
if (loginUser.getAuthenticationMethod() == UserGroupInformation.AuthenticationMethod.KERBEROS
&& useTicketCache && !loginUser.hasKerberosCredentials()) {
LOG.error("Hadoop security with Kerberos is enabled but the login user does not have Kerberos credentials");
throw new RuntimeException("Hadoop security with Kerberos is enabled but the login user " +
"does not have Kerberos credentials");
}
}
isReadyForDeployment(clusterSpecification);
// ------------------ Check if the specified queue exists --------------------
checkYarnQueues(yarnClient);
// ------------------ Add dynamic properties to local flinkConfiguraton ------
Map<String, String> dynProperties = getDynamicProperties(dynamicPropertiesEncoded);
for (Map.Entry<String, String> dynProperty : dynProperties.entrySet()) {
flinkConfiguration.setString(dynProperty.getKey(), dynProperty.getValue());
}
// ------------------ Check if the YARN ClusterClient has the requested resources --------------
// Create application via yarnClient
final YarnClientApplication yarnApplication = yarnClient.createApplication();
final GetNewApplicationResponse appResponse = yarnApplication.getNewApplicationResponse();
Resource maxRes = appResponse.getMaximumResourceCapability();
final ClusterResourceDescription freeClusterMem;
try {
freeClusterMem = getCurrentFreeClusterResources(yarnClient);
} catch (YarnException | IOException e) {
failSessionDuringDeployment(yarnClient, yarnApplication);
throw new YarnDeploymentException("Could not retrieve information about free cluster resources.", e);
}
final int yarnMinAllocationMB = yarnConfiguration.getInt(YarnConfiguration.RM_SCHEDULER_MINIMUM_ALLOCATION_MB, 0);
final ClusterSpecification validClusterSpecification;
try {
validClusterSpecification = validateClusterResources(
clusterSpecification,
yarnMinAllocationMB,
maxRes,
freeClusterMem);
} catch (YarnDeploymentException yde) {
failSessionDuringDeployment(yarnClient, yarnApplication);
throw yde;
}
LOG.info("Cluster specification: {}", validClusterSpecification);
final ClusterEntrypoint.ExecutionMode executionMode = detached ?
ClusterEntrypoint.ExecutionMode.DETACHED
: ClusterEntrypoint.ExecutionMode.NORMAL;
flinkConfiguration.setString(ClusterEntrypoint.EXECUTION_MODE, executionMode.toString());
ApplicationReport report = startAppMaster(
flinkConfiguration,
applicationName,
yarnClusterEntrypoint,
jobGraph,
yarnClient,
yarnApplication,
validClusterSpecification);
String host = report.getHost();
int port = report.getRpcPort();
// Correctly initialize the Flink config
flinkConfiguration.setString(JobManagerOptions.ADDRESS, host);
flinkConfiguration.setInteger(JobManagerOptions.PORT, port);
flinkConfiguration.setString(RestOptions.ADDRESS, host);
flinkConfiguration.setInteger(RestOptions.PORT, port);
// the Flink cluster is deployed in YARN. Represent cluster
return createYarnClusterClient(
this,
validClusterSpecification.getNumberTaskManagers(),
validClusterSpecification.getSlotsPerTaskManager(),
report,
flinkConfiguration,
true);
}
这个方法比较长,但干的活就几件:
- 发布前做各种参数的合法性校验以及必须参数的校验;
- 调用startAppMaster在yarn上启动flink的AM/JobManager;
- 等待AM/JobManager启动成功之后更新JobManager的rpc的最新地址;
- 构建YarnClusterClient;
所以这个方法里调用最关键的方法就是startAppMaster。
public ApplicationReport startAppMaster(
Configuration configuration,
String applicationName,
String yarnClusterEntrypoint,
JobGraph jobGraph,
YarnClient yarnClient,
YarnClientApplication yarnApplication,
ClusterSpecification clusterSpecification) throws Exception {
// ------------------ Initialize the file systems -------------------------
org.apache.flink.core.fs.FileSystem.initialize(
configuration,
PluginUtils.createPluginManagerFromRootFolder(configuration));
// initialize file system
// Copy the application master jar to the filesystem
// Create a local resource to point to the destination jar path
final FileSystem fs = FileSystem.get(yarnConfiguration);
final Path homeDir = fs.getHomeDirectory();
// hard coded check for the GoogleHDFS client because its not overriding the getScheme() method.
if (!fs.getClass().getSimpleName().equals("GoogleHadoopFileSystem") &&
fs.getScheme().startsWith("file")) {
LOG.warn("The file system scheme is '" + fs.getScheme() + "'. This indicates that the "
+ "specified Hadoop configuration path is wrong and the system is using the default Hadoop configuration values."
+ "The Flink YARN client needs to store its files in a distributed file system");
}
ApplicationSubmissionContext appContext = yarnApplication.getApplicationSubmissionContext();
Set<File> systemShipFiles = new HashSet<>(shipFiles.size());
for (File file : shipFiles) {
systemShipFiles.add(file.getAbsoluteFile());
}
//check if there is a logback or log4j file
File logbackFile = new File(configurationDirectory + File.separator + CONFIG_FILE_LOGBACK_NAME);
final boolean hasLogback = logbackFile.exists();
if (hasLogback) {
systemShipFiles.add(logbackFile);
}
File log4jFile = new File(configurationDirectory + File.separator + CONFIG_FILE_LOG4J_NAME);
final boolean hasLog4j = log4jFile.exists();
if (hasLog4j) {
systemShipFiles.add(log4jFile);
if (hasLogback) {
// this means there is already a logback configuration file --> fail
LOG.warn("The configuration directory ('" + configurationDirectory + "') contains both LOG4J and " +
"Logback configuration files. Please delete or rename one of them.");
}
}
addEnvironmentFoldersToShipFiles(systemShipFiles);
// Set-up ApplicationSubmissionContext for the application
final ApplicationId appId = appContext.getApplicationId();
// ------------------ Add Zookeeper namespace to local flinkConfiguraton ------
String zkNamespace = getZookeeperNamespace();
// no user specified cli argument for namespace?
if (zkNamespace == null || zkNamespace.isEmpty()) {
// namespace defined in config? else use applicationId as default.
zkNamespace = configuration.getString(HighAvailabilityOptions.HA_CLUSTER_ID, String.valueOf(appId));
setZookeeperNamespace(zkNamespace);
}
configuration.setString(HighAvailabilityOptions.HA_CLUSTER_ID, zkNamespace);
if (HighAvailabilityMode.isHighAvailabilityModeActivated(configuration)) {
// activate re-execution of failed applications
appContext.setMaxAppAttempts(
configuration.getInteger(
YarnConfigOptions.APPLICATION_ATTEMPTS.key(),
YarnConfiguration.DEFAULT_RM_AM_MAX_ATTEMPTS));
activateHighAvailabilitySupport(appContext);
} else {
// set number of application retries to 1 in the default case
appContext.setMaxAppAttempts(
configuration.getInteger(
YarnConfigOptions.APPLICATION_ATTEMPTS.key(),
1));
}
final Set<File> userJarFiles = (jobGraph == null)
// not per-job submission
? Collections.emptySet()
// add user code jars from the provided JobGraph
: jobGraph.getUserJars().stream().map(f -> f.toUri()).map(File::new).collect(Collectors.toSet());
// local resource map for Yarn
final Map<String, LocalResource> localResources = new HashMap<>(2 + systemShipFiles.size() + userJarFiles.size());
// list of remote paths (after upload)
final List<Path> paths = new ArrayList<>(2 + systemShipFiles.size() + userJarFiles.size());
// ship list that enables reuse of resources for task manager containers
StringBuilder envShipFileList = new StringBuilder();
// upload and register ship files
List<String> systemClassPaths = uploadAndRegisterFiles(
systemShipFiles,
fs,
homeDir,
appId,
paths,
localResources,
envShipFileList);
final List<String> userClassPaths = uploadAndRegisterFiles(
userJarFiles,
fs,
homeDir,
appId,
paths,
localResources,
envShipFileList);
if (userJarInclusion == YarnConfigOptions.UserJarInclusion.ORDER) {
systemClassPaths.addAll(userClassPaths);
}
// normalize classpath by sorting
Collections.sort(systemClassPaths);
Collections.sort(userClassPaths);
// classpath assembler
StringBuilder classPathBuilder = new StringBuilder();
if (userJarInclusion == YarnConfigOptions.UserJarInclusion.FIRST) {
for (String userClassPath : userClassPaths) {
classPathBuilder.append(userClassPath).append(File.pathSeparator);
}
}
for (String classPath : systemClassPaths) {
classPathBuilder.append(classPath).append(File.pathSeparator);
}
// Setup jar for ApplicationMaster
Path remotePathJar = setupSingleLocalResource(
"flink.jar",
fs,
appId,
flinkJarPath,
localResources,
homeDir,
"");
// set the right configuration values for the TaskManager
configuration.setInteger(
TaskManagerOptions.NUM_TASK_SLOTS,
clusterSpecification.getSlotsPerTaskManager());
configuration.setString(
TaskManagerOptions.TASK_MANAGER_HEAP_MEMORY,
clusterSpecification.getTaskManagerMemoryMB() + "m");
// Upload the flink configuration
// write out configuration file
File tmpConfigurationFile = File.createTempFile(appId + "-flink-conf.yaml", null);
tmpConfigurationFile.deleteOnExit();
BootstrapTools.writeConfiguration(configuration, tmpConfigurationFile);
Path remotePathConf = setupSingleLocalResource(
"flink-conf.yaml",
fs,
appId,
new Path(tmpConfigurationFile.getAbsolutePath()),
localResources,
homeDir,
"");
paths.add(remotePathJar);
classPathBuilder.append("flink.jar").append(File.pathSeparator);
paths.add(remotePathConf);
classPathBuilder.append("flink-conf.yaml").append(File.pathSeparator);
if (userJarInclusion == YarnConfigOptions.UserJarInclusion.LAST) {
for (String userClassPath : userClassPaths) {
classPathBuilder.append(userClassPath).append(File.pathSeparator);
}
}
// write job graph to tmp file and add it to local resource
// TODO: server use user main method to generate job graph
if (jobGraph != null) {
try {
File fp = File.createTempFile(appId.toString(), null);
fp.deleteOnExit();
try (FileOutputStream output = new FileOutputStream(fp);
ObjectOutputStream obOutput = new ObjectOutputStream(output);){
obOutput.writeObject(jobGraph);
}
final String jobGraphFilename = "job.graph";
flinkConfiguration.setString(JOB_GRAPH_FILE_PATH, jobGraphFilename);
Path pathFromYarnURL = setupSingleLocalResource(
jobGraphFilename,
fs,
appId,
new Path(fp.toURI()),
localResources,
homeDir,
"");
paths.add(pathFromYarnURL);
classPathBuilder.append(jobGraphFilename).append(File.pathSeparator);
} catch (Exception e) {
LOG.warn("Add job graph to local resource fail");
throw e;
}
}
final Path yarnFilesDir = getYarnFilesDir(appId);
FsPermission permission = new FsPermission(FsAction.ALL, FsAction.NONE, FsAction.NONE);
fs.setPermission(yarnFilesDir, permission); // set permission for path.
//To support Yarn Secure Integration Test Scenario
//In Integration test setup, the Yarn containers created by YarnMiniCluster does not have the Yarn site XML
//and KRB5 configuration files. We are adding these files as container local resources for the container
//applications (JM/TMs) to have proper secure cluster setup
Path remoteKrb5Path = null;
Path remoteYarnSiteXmlPath = null;
boolean hasKrb5 = false;
if (System.getenv("IN_TESTS") != null) {
File f = new File(System.getenv("YARN_CONF_DIR"), Utils.YARN_SITE_FILE_NAME);
LOG.info("Adding Yarn configuration {} to the AM container local resource bucket", f.getAbsolutePath());
Path yarnSitePath = new Path(f.getAbsolutePath());
remoteYarnSiteXmlPath = setupSingleLocalResource(
Utils.YARN_SITE_FILE_NAME,
fs,
appId,
yarnSitePath,
localResources,
homeDir,
"");
String krb5Config = System.getProperty("java.security.krb5.conf");
if (krb5Config != null && krb5Config.length() != 0) {
File krb5 = new File(krb5Config);
LOG.info("Adding KRB5 configuration {} to the AM container local resource bucket", krb5.getAbsolutePath());
Path krb5ConfPath = new Path(krb5.getAbsolutePath());
remoteKrb5Path = setupSingleLocalResource(
Utils.KRB5_FILE_NAME,
fs,
appId,
krb5ConfPath,
localResources,
homeDir,
"");
hasKrb5 = true;
}
}
// setup security tokens
Path remotePathKeytab = null;
String keytab = configuration.getString(SecurityOptions.KERBEROS_LOGIN_KEYTAB);
if (keytab != null) {
LOG.info("Adding keytab {} to the AM container local resource bucket", keytab);
remotePathKeytab = setupSingleLocalResource(
Utils.KEYTAB_FILE_NAME,
fs,
appId,
new Path(keytab),
localResources,
homeDir,
"");
}
final ContainerLaunchContext amContainer = setupApplicationMasterContainer(
yarnClusterEntrypoint,
hasLogback,
hasLog4j,
hasKrb5,
clusterSpecification.getMasterMemoryMB());
if (UserGroupInformation.isSecurityEnabled()) {
// set HDFS delegation tokens when security is enabled
LOG.info("Adding delegation token to the AM container..");
Utils.setTokensFor(amContainer, paths, yarnConfiguration);
}
amContainer.setLocalResources(localResources);
fs.close();
// Setup CLASSPATH and environment variables for ApplicationMaster
final Map<String, String> appMasterEnv = new HashMap<>();
// set user specified app master environment variables
appMasterEnv.putAll(Utils.getEnvironmentVariables(ResourceManagerOptions.CONTAINERIZED_MASTER_ENV_PREFIX, configuration));
// set Flink app class path
appMasterEnv.put(YarnConfigKeys.ENV_FLINK_CLASSPATH, classPathBuilder.toString());
// set Flink on YARN internal configuration values
appMasterEnv.put(YarnConfigKeys.ENV_TM_COUNT, String.valueOf(clusterSpecification.getNumberTaskManagers()));
appMasterEnv.put(YarnConfigKeys.ENV_TM_MEMORY, String.valueOf(clusterSpecification.getTaskManagerMemoryMB()));
appMasterEnv.put(YarnConfigKeys.FLINK_JAR_PATH, remotePathJar.toString());
appMasterEnv.put(YarnConfigKeys.ENV_APP_ID, appId.toString());
appMasterEnv.put(YarnConfigKeys.ENV_CLIENT_HOME_DIR, homeDir.toString());
appMasterEnv.put(YarnConfigKeys.ENV_CLIENT_SHIP_FILES, envShipFileList.toString());
appMasterEnv.put(YarnConfigKeys.ENV_SLOTS, String.valueOf(clusterSpecification.getSlotsPerTaskManager()));
appMasterEnv.put(YarnConfigKeys.ENV_DETACHED, String.valueOf(detached));
appMasterEnv.put(YarnConfigKeys.ENV_ZOOKEEPER_NAMESPACE, getZookeeperNamespace());
appMasterEnv.put(YarnConfigKeys.FLINK_YARN_FILES, yarnFilesDir.toUri().toString());
// https://github.com/apache/hadoop/blob/trunk/hadoop-yarn-project/hadoop-yarn/hadoop-yarn-site/src/site/markdown/YarnApplicationSecurity.md#identity-on-an-insecure-cluster-hadoop_user_name
appMasterEnv.put(YarnConfigKeys.ENV_HADOOP_USER_NAME, UserGroupInformation.getCurrentUser().getUserName());
if (remotePathKeytab != null) {
appMasterEnv.put(YarnConfigKeys.KEYTAB_PATH, remotePathKeytab.toString());
String principal = configuration.getString(SecurityOptions.KERBEROS_LOGIN_PRINCIPAL);
appMasterEnv.put(YarnConfigKeys.KEYTAB_PRINCIPAL, principal);
}
//To support Yarn Secure Integration Test Scenario
if (remoteYarnSiteXmlPath != null) {
appMasterEnv.put(YarnConfigKeys.ENV_YARN_SITE_XML_PATH, remoteYarnSiteXmlPath.toString());
}
if (remoteKrb5Path != null) {
appMasterEnv.put(YarnConfigKeys.ENV_KRB5_PATH, remoteKrb5Path.toString());
}
if (dynamicPropertiesEncoded != null) {
appMasterEnv.put(YarnConfigKeys.ENV_DYNAMIC_PROPERTIES, dynamicPropertiesEncoded);
}
// set classpath from YARN configuration
Utils.setupYarnClassPath(yarnConfiguration, appMasterEnv);
amContainer.setEnvironment(appMasterEnv);
// Set up resource type requirements for ApplicationMaster
Resource capability = Records.newRecord(Resource.class);
capability.setMemory(clusterSpecification.getMasterMemoryMB());
capability.setVirtualCores(flinkConfiguration.getInteger(YarnConfigOptions.APP_MASTER_VCORES));
final String customApplicationName = customName != null ? customName : applicationName;
appContext.setApplicationName(customApplicationName);
appContext.setApplicationType(applicationType != null ? applicationType : "Apache Flink");
appContext.setAMContainerSpec(amContainer);
appContext.setResource(capability);
if (yarnQueue != null) {
appContext.setQueue(yarnQueue);
}
setApplicationNodeLabel(appContext);
setApplicationTags(appContext);
// add a hook to clean up in case deployment fails
Thread deploymentFailureHook = new DeploymentFailureHook(yarnClient, yarnApplication, yarnFilesDir);
Runtime.getRuntime().addShutdownHook(deploymentFailureHook);
LOG.info("Submitting application master " + appId);
yarnClient.submitApplication(appContext);
LOG.info("Waiting for the cluster to be allocated");
final long startTime = System.currentTimeMillis();
ApplicationReport report;
YarnApplicationState lastAppState = YarnApplicationState.NEW;
loop: while (true) {
try {
report = yarnClient.getApplicationReport(appId);
} catch (IOException e) {
throw new YarnDeploymentException("Failed to deploy the cluster.", e);
}
YarnApplicationState appState = report.getYarnApplicationState();
LOG.debug("Application State: {}", appState);
switch(appState) {
case FAILED:
case FINISHED:
case KILLED:
throw new YarnDeploymentException("The YARN application unexpectedly switched to state "
+ appState + " during deployment. \n" +
"Diagnostics from YARN: " + report.getDiagnostics() + "\n" +
"If log aggregation is enabled on your cluster, use this command to further investigate the issue:\n" +
"yarn logs -applicationId " + appId);
//break ..
case RUNNING:
LOG.info("YARN application has been deployed successfully.");
break loop;
default:
if (appState != lastAppState) {
LOG.info("Deploying cluster, current state " + appState);
}
if (System.currentTimeMillis() - startTime > 60000) {
LOG.info("Deployment took more than 60 seconds. Please check if the requested resources are available in the YARN cluster");
}
}
lastAppState = appState;
Thread.sleep(250);
}
// print the application id for user to cancel themselves.
if (isDetachedMode()) {
LOG.info("The Flink YARN client has been started in detached mode. In order to stop " +
"Flink on YARN, use the following command or a YARN web interface to stop " +
"it:\nyarn application -kill " + appId + "\nPlease also note that the " +
"temporary files of the YARN session in the home directory will not be removed.");
}
// since deployment was successful, remove the hook
ShutdownHookUtil.removeShutdownHook(deploymentFailureHook, getClass().getSimpleName(), LOG);
return report;
}
这个方法也是非常非常的long,梳理下来之后发现,它只干了3件事:
- 准备启动AM所需资源,将需要的资源上传到HDFS上;
- 设置启动AM的环境变量以及最终启动脚本;
- 通过YarnClient向Yarn提交请求并自旋等待yarn的响应结果并返回;
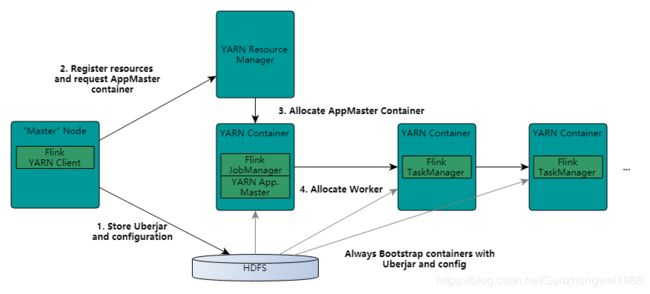
到此为止,flink 提交任务的独立模式从源码的角度已分析结束。