Spark SQL架构
Spark SQL架构
Spark技术栈(Spark生态站):Spark SQL主要是对信息的处理,包括数据转化,数据抽取
Spark周边有Python/Scala/java/MLLib/等等
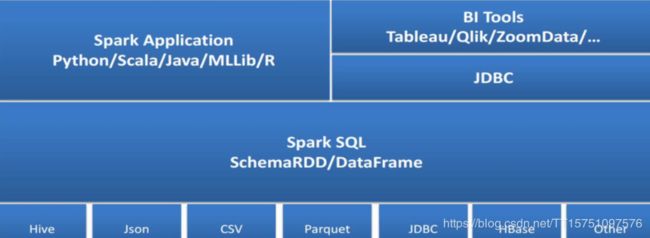
Spark可以集成Hive,Json,CSV,parqueet,JDBC,HBase,Other等等
Catalyst优化器是Spark SQL的核心。

Dataset与Frame的区别:???
使用Case Class创建Dataset???
Dataset里面有没元数据结构的,他里面只有一行一行的日志文件
三者的关系。

使用Dataset完成零售商店指标统计
需求说明:
完成数据装载
使用RDD装载临售商店业务数据
定义样例类
将RDD转换成Dataset
请找出:
谁的消费额最高??
那个产品销量最高??
思路:
select g.userid,sum(g.totalprice) sp from
(select i.*,o.orderid,o.userid from
orders o inner join order_items i
on o.orderid=i.orderid) g group by g.uerid
order by sp desc limit 1
//打开虚拟机把数据导进去,然后创建几个文件。
//如果是HDFS文件就需要使用hdfs:///...方式导入,我现在是本地文件则使用file
val orderRDD = sc.textFile("file:///opt/data/orders.csv")
val itemsRDD = sc.textFile("file:///opt/data/order_items.csv")
//RDD创建成功
scala> val orderRDD = sc.textFile("file:///opt/data/orders.csv")
orderRDD: org.apache.spark.rdd.RDD[String] = file:///opt/data/orders.csv MapPartitionsRDD[1] at textFile at :24
scala> val itemsRDD = sc.textFile("file:///opt/data/order_items.csv")
itemsRDD: org.apache.spark.rdd.RDD[String] = file:///opt/data/order_items.csv MapPartitionsRDD[3] at textFile at :24
//查看一下oderRDD转换成toDS文件,显示前三行。
scala> orderRDD.toDS.show(3)
+--------------------+
| value|
+--------------------+
|"1","2013-07-25 0...|
|"2","2013-07-25 0...|
|"3","2013-07-25 0...|
+--------------------+
only showing top 3 rows
//查看一下oderRDD转换成toDF格式,显示前三行。
scala> orderRDD.toDF.show(3)
+--------------------+
| value|
+--------------------+
|"1","2013-07-25 0...|
|"2","2013-07-25 0...|
|"3","2013-07-25 0...|
+--------------------+
only showing top 3 rows
scala>
//使用Case Class创建Dataset
class Orders(orderid:String,date:String,userid:String,statu:String)
class Items(iid:String,orderid:String,proid:String,num:Double,tp:Double,sp:Double)
//创建成功
scala> class Orders(orderid:String,date:String,userid:String,statu:String)
defined class Orders
scala> class Items(iid:String,orderid:String,proid:String,num:Double,tp:Double,sp:Double)
defined class Items
scala>
//切片,按照逗号切割
val ods = orderRDD.map(line=>{var arr = line.replaceAll("\"","").split(",");Orders(arr(0),arr(1),arr(2),arr(3))}).toDS
val its = itemsRDD.map(line=>{var arr = line.replaceAll("\"","").split(",");Items(arr(0),arr(1),arr(2),arr(3).toDouble,arr(4).toDouble,arr(5).toDouble)}).toDS
//两表相连
val tmp = its.join(ods,its("orderid")===("orderid"))
//查看两表相连的结果
scala> tmp.printSchema
//分区
scala> tmp.goruoBy("userid").agg(sum(tp)).show(3)
scala> val cet = tmp.groupBy("userid").agg(sum("tp")as.("ttp")).orderBy(desc("ttp")).limit(1)
DataFrameAPI常用操作
val users = spark.read.format("csv").option("delimiter",",").load("file:///opt/data/users.csv")
scala> users.show(2)
scals> val userDF = users.whth
DataFrame与RDD的区别
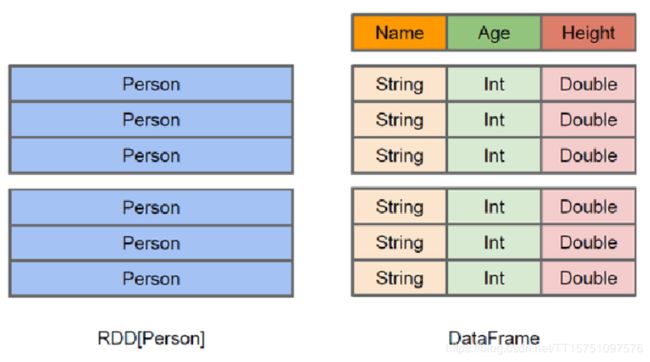
主要区别:
RDD:数据可以是非架构化,没有格式信息
DataFrame:有格式信息,是结构化信息。Data Frame就是Schema on read(或者Schema RDD)
结合上图进行理解:
RDD与DataFrame都是分布式的 可以并行处理的 一个集合
但是DataFrame更像是一个二维表格,在这个二维表格里面,我们是知道每一列的名称
第一列是Name,它的类型是String
第二列是Age,它的类型是Int
第三列是Height,它的类型是Double
而对于DataFrame来说,它不仅可以知道里面的数据,而且它还可以知道里面的schema信息
因此能做的优化肯定也是更多的,举个例子:
因为每一列的数据类型是一样的,因此可以采用更好的压缩,这样的话整个DF存储所占用的东西必然是比RDD要少很多的(这也是DF的优点)
想要优化的更好,所要暴露的信息就需要更多,这样系统才能更好大的进行优化
RDD的类型可以是Person,但是这个Person里面,我们是不知道它的Name,Age,Height的,因此相比DF而言更难进行优化
Java/Scala 操作RDD的底层是跑在JVM上的
Python 操作RDD的底层不跑在JVM上,它有Python Execution
因此使用RDD编程带来一个很大的问题:
由于使用不同语言操作RDD,底层所运行的环境不同(使用Java/Scala 与 Python 所运行的效率完全是不一样的,Python是会慢一些的)
但是有了DataFrame是不一样的
DF不是直接到运行环境的,中间还有一层是logicplan,统统先转换成逻辑执行计划之后,再去进行运行的;所以现在DF不管采用什么语言,它的执行效率都是一样的
从编程时,引入的依赖包角度进行理解:
我们会发现在工作中,只需要添加Spark SQL的依赖就可以了,不需要再特地添加Spark Core的依赖了
因为Spark SQL也需要依赖Spark Core,因此可以不添加Spark Core的依赖