Python借助smote实现不均衡样本数据的上采样和下采样,并可视化展示样本分布
smote是一个很有用的用于样本生成的方法,在Python中已经有了现成的实现可以直接调用,对于安装可以直接使用命令:
pip install imblearn
由于imblearn包比较大40多MB,需要耐心等一会才可以,安装成功就可以使用了
今天主要是借助于样本生成的方法,来对原始不均衡样本数据集的扩充,使得其“尽力平衡”
下面是简单的实验:
def create_dataset(n_samples=1000, weights=(0.01, 0.01, 0.98), n_classes=3,class_sep=0.8, n_clusters=1):
'''
创建虚拟数据集
'''
return make_classification(n_samples=n_samples, n_features=2,n_informative=2, n_redundant=0, n_repeated=0,
n_classes=n_classes,n_clusters_per_class=n_clusters,weights=list(weights),class_sep=class_sep, random_state=0)
def dataset_show(savepath='dataset_show.png'):
'''
数据及样本可视化
原始样本数据经过采样后会形成将近1:1的数据集
'''
X, y=create_dataset(n_samples=3000, weights=(0.6, 0.4),n_classes=2)
print('Original dataset shape {}'.format(Counter(y)))
startnum=221
pca=PCA(n_components=2)
#将数据矩阵转化为二维矩阵
X_vis=pca.fit_transform(X)
#应用SMOTE
sm=SMOTE()
X_resampled, y_resampled_SMOTE=sm.fit_sample(X, y)
print('SMOTE dataset shape {}'.format(Counter(y_resampled_SMOTE)))
X_res_vis_SMOTE=pca.transform(X_resampled)
#应用SMOTE + ENN
sm=SMOTEENN()
X_resampled, y_resampled_SMOTEENN=sm.fit_sample(X, y)
print('SMOTEENN dataset shape {}'.format(Counter(y_resampled_SMOTEENN)))
X_res_vis_SMOTEENN=pca.transform(X_resampled)
#应用SMOTE + Tomek
smt=SMOTETomek()
X_resampled, y_resampled_SMOTETomek=smt.fit_sample(X, y)
print('SMOTETomek dataset shape {}'.format(Counter(y_resampled_SMOTETomek)))
X_res_vis_SMOTETomek=pca.transform(X_resampled)
plot_data_list=[[X_vis,y],[X_res_vis_SMOTE,y_resampled_SMOTE],[X_res_vis_SMOTEENN,y_resampled_SMOTEENN],[X_res_vis_SMOTETomek,y_resampled_SMOTETomek]]
plot_subplot(plot_data_list,savepath=savepath)我们使用sklearn库提供的make_classification方法来随机生成符合要求的样本数据集,dataset_show主要实现对数据集的可视化展示,由于我们的样本数据都是多维的,为了展示方便,这里我们都是使用PCA方法将其降到2维来处理,我们分别对比了三种不同的采样方法得到的样本数据分布和原始的样本数据分布情况,结果如下:
实验一:两类样本数据,比例为:3:2
数据统计结果为:
Original dataset shape Counter({0: 1792, 1: 1208})
SMOTE dataset shape Counter({0: 1792, 1: 1792})
SMOTEENN dataset shape Counter({1: 1528, 0: 1431})
SMOTETomek dataset shape Counter({0: 1719, 1: 1719})数据集可视化展示为:
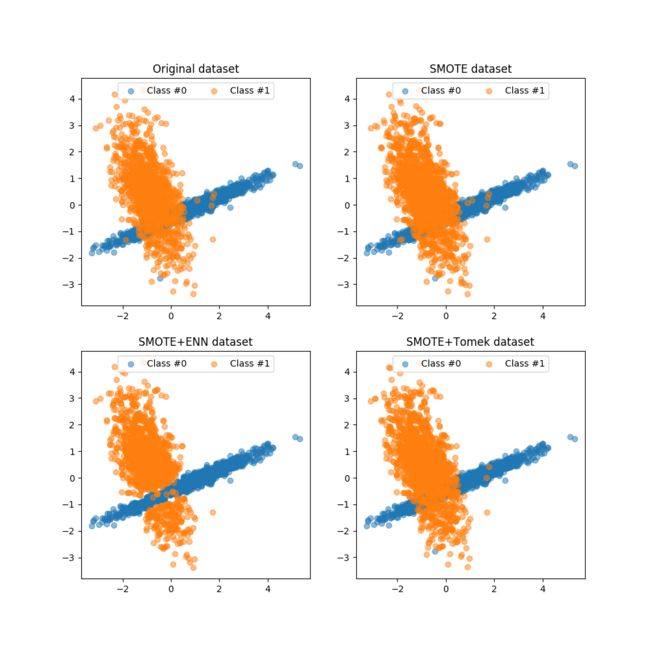
实验二:两类样本数据,数据比例为:9:1
数据统计结果为:
Original dataset shape Counter({0: 2686, 1: 314})
SMOTE dataset shape Counter({0: 2686, 1: 2686})
SMOTEENN dataset shape Counter({1: 2380, 0: 2232})
SMOTETomek dataset shape Counter({0: 2584, 1: 2584})数据集可视化展示为:
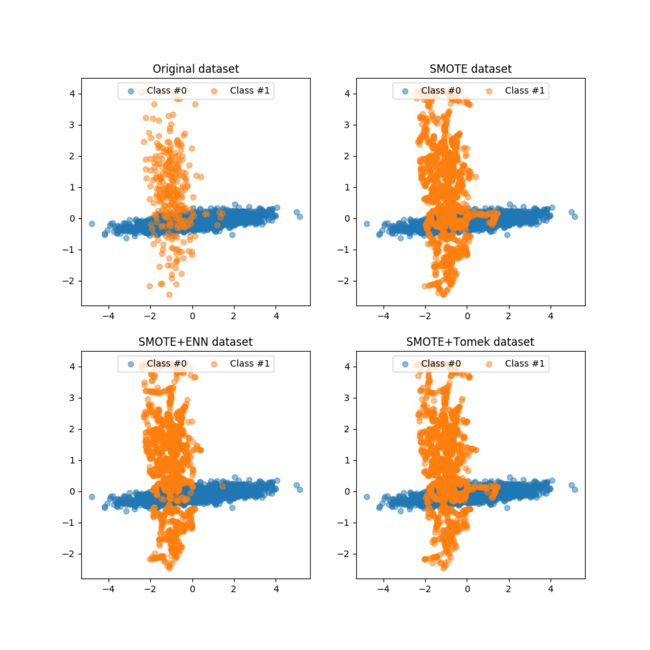
从上面可以简单发现:
当数据比例不是很不平衡的时候,在使用采样方法得到的数据集分布以及样本局部密度不会改变很大
当数据样本比例失衡加大的时候,在使用采样方法会明显的改变样本的局部分布密度,在整体分布轮廓上会很接近原始数据集