belk学习
beats
elk架构图:
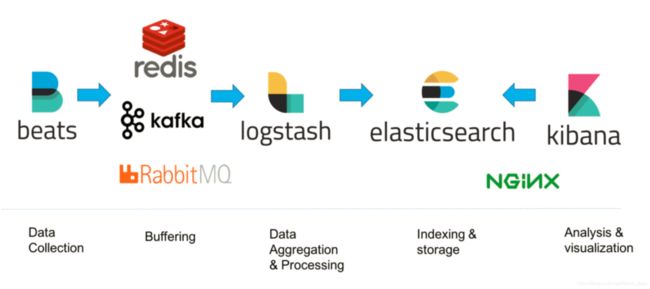
Filebeat负责从web服务器上实时抓取数据,当log文件发生变化时,将文件内容吐给kafka。
Kafka是消息队列,主要作用是在filebeat和logstash之间做缓存,避免因写入logstash的数据量过大,导致数据丢失。
filebeat(go语言开发)
官网:https://www.elastic.co/cn/beats/filebeat
功能:用于监控、收集服务器日志文件.
1.advantage
-
性能稳健,不错过任何检测信号
无论在任何环境中,随时都潜伏着应用程序中断的风险。Filebeat 能够读取并转发日志行,如果出现中断,还会在一切恢复正常后,从中断前停止的位置继续开始。
-
Filebeat 让简单的事情简单化
Filebeat 内置有多种模块(Apache、Cisco ASA、Microsoft Azure、NGINX、MySQL 等等),可针对常见格式的日志大大简化收集、解析和可视化过程,只需一条命令即可。之所以能实现这一点,是因为它将自动默认路径(因操作系统而异)与 Elasticsearch 采集节点管道的定义和 Kibana 仪表板组合在一起。不仅如此,数个 Filebeat 模块还包括预配置的 Machine Learning 任务。
-
它不会导致您的管道过载
当将数据发送到 Logstash 或 Elasticsearch 时,Filebeat 使用背压敏感协议,以应对更多的数据量。如果 Logstash 正在忙于处理数据,则会告诉 Filebeat 减慢读取速度。一旦拥堵得到解决,Filebeat 就会恢复到原来的步伐并继续传输数据。
2.架构:
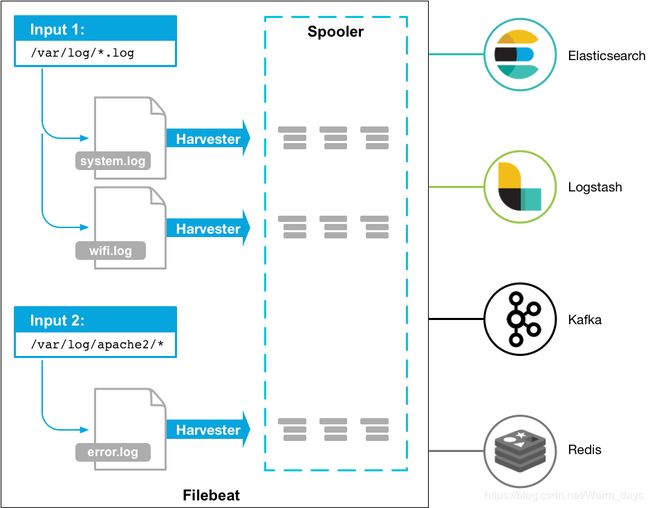
3.Filebeat工作原理
Filebeat由两个主要组件组成:input和 harvester。
-
harvester:
- 负责读取单个文件的内容。
- 如果文件在读取时被删除或重命名,Filebeat将继续读取文件。
-
input
-
输入负责管理收割机并查找所有可读取的资源。
-
如果输入类型为
log,则输入将在驱动器上找到与定义的全局路径匹配的所有文件,并为每个文件启动收集器。每个输入都在其自己的Go例程中运行。 -
支持多种输入类型 eg:log,Container,Kafka,Redis,UDP,Docker…
-
-
Filebeat如何保持文件的状态
- Filebeat 保存每个文件的状态并经常将状态刷新到磁盘上的注册文件中。
- 该状态用于记住harvester正在读取的最后偏移量,并确保发送所有日志行。
- 如果输出(例如Elasticsearch或Logstash)无法访问,Filebeat会跟踪最后发送的行,并在输出再次可用
时继续读取文件。 - 在Filebeat运行时,每个prospector内存中也会保存的文件状态信息,当重新启动Filebeat时,将使用注册 文件的数据来重建文件状态,Filebeat将每个harvester在从保存的最后偏移量继续读取。
- 文件状态记录在data/registry文件中。
4.部署及运行:
-
部署:https://www.elastic.co/guide/en/beats/filebeat/current/filebeat-installation.html
-
配置
核心配置文件filebeat.yml
- 控制台测试修改filebeat.yml:
-
filebeat.inputs: - type: stdin enabled: true setup.template.settings: index.number_of_shards: 3 output.console: pretty: true enable: true
2.启动filebeat
./filebeat -e -c filebeat.yml
输入:hello beats
控制台显示结果:
-
{ "@timestamp": "2020-05-13T02:40:47.361Z", "@metadata": { #元数据信息 "beat": "filebeat", "type": "_doc", "version": "7.6.2" }, "ecs": { "version": "1.4.0" }, "host": { "name": "centos-200" }, "agent": { "ephemeral_id": "e5774b50-26b5-4793-942e-19ff3a60afa1", "hostname": "centos-200", "id": "62898e4b-d500-4a1b-8fd5-5090ff5e1cc7", "version": "7.6.2", "type": "filebeat" }, "log": { "offset": 0, "file": { "path": "" } }, "message": "hello beats", #输入结果 "input": { #控制台标准输入 "type": "stdin" } }3.读取文件测试
-
修改filebeat.yml配置文件 filebeat.inputs: - type: log enabled: true paths: - /root/zqc/logs/*.log setup.template.settings: index.number_of_shards: 3 output.console: pretty: true enable: true
运行结果
-
{ "@timestamp": "2020-05-13T02:53:29.266Z", "@metadata": { "beat": "filebeat", "type": "_doc", "version": "7.6.2" }, "log": { "offset": 0, "file": { "path": "/root/zqc/logs/a.log" } }, "message": "abc", "input": { "type": "log" }, "ecs": { "version": "1.4.0" }, "host": { "name": "centos-200" }, "agent": { "ephemeral_id": "ab92a3cf-0509-412f-ac4d-8a7bc507c7db", "hostname": "centos-200", "id": "62898e4b-d500-4a1b-8fd5-5090ff5e1cc7", "version": "7.6.2", "type": "filebeat" } }4.自定义字段:打标签
-
#修改filebeat.yml文件 filebeat.inputs: - type: log enabled: true paths: /root/zqc/logs/*.log tags: ["zqc"] fields: from: zqc-input setup.template.settings: index.number_of_shards: 3 output.console: pretty: true enable: true运行结果
{ "@timestamp": "2020-05-13T03:07:42.105Z", "@metadata": { "beat": "filebeat", "type": "_doc", "version": "7.6.2" }, "message": "456", "tags": [ "zqc" #添加的标签 ], "input": { "type": "log" }, "fields": { #添加的字段 "from": "zqc-input" }, "agent": { "id": "62898e4b-d500-4a1b-8fd5-5090ff5e1cc7", "version": "7.6.2", "type": "filebeat", "ephemeral_id": "86991f47-98b3-4528-b686-404a8dcff0af", "hostname": "centos-200" }, "ecs": { "version": "1.4.0" }, "host": { "name": "centos-200" }, "log": { "offset": 8, "file": { "path": "/root/zqc/logs/a.log" } } }
5.Module
在Filebeat中,有大量的Module,可以简化我们的配置,直接就可以使用,如:mysql,redis,mongodb等
./filebeat modules enable redis #启动
./filebeat modules disable redis #禁用
Metricbeat
功能:用于从系统和服务收集指标。
1.advantage
-
系统级监控,更简洁
将 Metricbeat 部署到您的所有 Linux、Windows 和 Mac 主机,并将它连接到 Elasticsearch 就大功告成了:您 可以获取系统级的 CPU 使用率、内存、文件系统、磁盘 IO 和网络 IO 统计数据,还可针对系统上的每个进程获得与 top 命令类似的统计数据
-
单个二进制文件提供多种模块
Metricbeat 提供多种内部模块,这些模块可从多项服务(诸如 Apache、Jolokia、NGINX、MongoDB、MySQL、PostgreSQL、Prometheus 等等)中收集指标。安装简单,完全零依赖性。只需在配置文件中启用您所需的模块即可。
而且,如果您没有看到要找的模块,还可以自己构建。以 Go 语言编写 Metricbeat 模块,过程十分简单。
- 容器就绪
近来是不是所有工作都转移到了 Docker 中?通过 Elastic Stack,您能够轻松地监测容器。将 Metricbeat 部署到同一台主机上的一个单独容器后,它将收集与主机上运行的其他每一个容器相关的统计数据。在收集统计数据时,它直接从 proc 文件系统读取 cgroup 信息,这就意味着它无需特权即可访问 Docker API,并且同样适用于其他 Runtime。针对 Docker 的 Autodiscovery 让事情进一步简化,您只需指定一个条件即可开启 Metricbeat 模块。
- 不错过任何检测信号
将指标通过假脱机传输方式输送至磁盘,这样您的数据管道再也不会错过任何一个数据点,即使发生中断(例如网络问题),也勿需担心。Metricbeat 会保留传入的数据,并在重新上线后将这些指标输送至 Elasticsearch 或 Logstash
2.架构
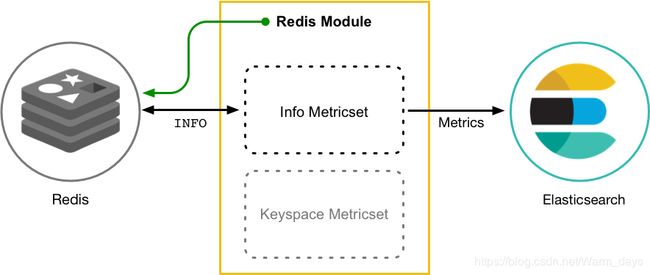
Metricbeat有2部分组成,一部分是Modules,另一部分为Metricsets
- Metricbeat Module
定义了从特定服务(例如Redis,MySQL等)收集数据的基本逻辑。 该Module指定有关服务的详细信息,包括如何连接,收集度量的频率以及收集哪些度量。
- Metricsets
收集指标的集合,如:cpu、memory、network等;
3.部署运行
配置文件
默认收集系统module数据system.yml
修改配置文件:metricbeat.yml
-
metricbeat.config.modules: path: /etc/metricbeat/modules.d/*.yml reload.enabled: false setup.template.settings: index.number_of_shards: 1 index.codec: best_compression output.elasticsearch: hosts: ["192.168.16.129:9200"] processors: #使用处理器过滤和增强数据 - add_host_metadata: ~ - add_cloud_metadata: ~
运行:./metricbeat -e
待补充 Packetbeat
Packetbeat 是一个实时网络数据包分析工具,与elasticsearch一体来提供应用程序的监控和分析系统。
Packetbeat通过嗅探应用服务器之间的网络通讯,来解码应用层协议类型如HTTP、MySQL、redis等等,关联请求与响应,并记录每个事务有意义的字段。
Packetbeat可以帮助我们快速发现后端应用程序的问题,如bug或性能问题等等,修复排除故障也很快捷。
Packetbeat目前支持的协议有:
- HTTP
- MySQL
- PostgreSQL
- Redis
- Thrift-RPC
- MongoDB
- DNS
- Memcache
Packetbeat可以将相关事务直接插入到elasticsearch或redis(不推荐)或logstash。
Packetbeat可以运行在应用服务器上或者独自的服务器。当运行在独自服务器上时,需要从交换机的镜像端口或者窃听设备上获取网络流量。
LOGSTASH
1.介绍
官网:https://www.elastic.co/guide/en/logstash/current/first-event.html
-
集中、转换和存储数据
Logstash 是开源的服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到您 最喜欢的“存储库”中。
-
输入、过滤器和输出
Logstash 能够动态地采集、转换和传输数据,不受格式或复杂度的影响。利用 Grok 从非结构化数据中派生出结构,从 IP 地址解码出地理坐标,匿名化或排除敏感字段,并简化整体处理过程。
-
实时解析和转换数据
数据从源传输到存储库的过程中,Logstash 过滤器能够解析各个事件,识别已命名的字段以构建结构,并将它们转换成通用格式,以便更轻松、更快速地分析和实现商业价值。
- 利用 Grok 从非结构化数据中派生出结构
- 从 IP 地址破译出地理坐标
- 将 PII(unencrypted personal data ) 数据匿名化,完全排除敏感字段
- 简化整体处理,不受数据源、格式或架构的影响
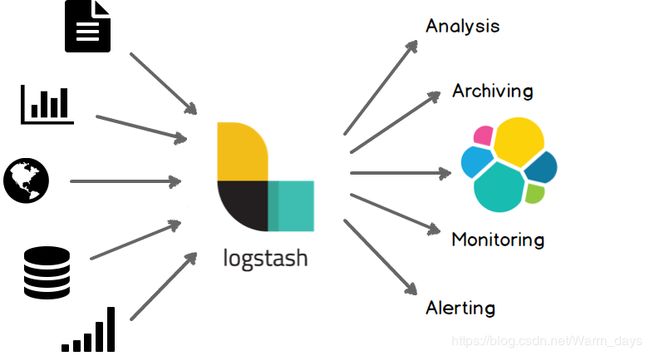
流程图:
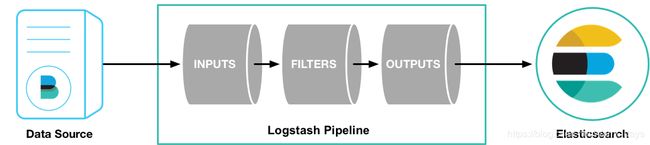
2.部署与运行
接收Filebeat输入的日志
Filebeat读取nginx的日志,发送到logstash,通过logstash发送到es
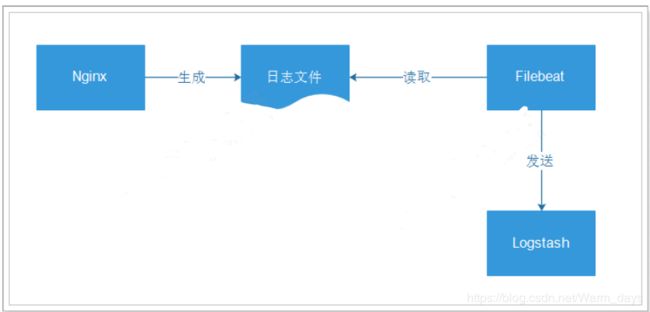
步骤:
1.编辑filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/nginx/access.log
tags: ["log"]
fields:
from: nginx
fields_under_root: false
output.logstash:
hosts: ["192.168.16.129:5044"]
2.编辑logstash.yml
input {
beats {
port => "5044"
}
}
filter {
grok {
patterns_dir => "/usr/share/logstash/nginx-patterns"
match => { "message" => "%{NGINX_ACCESS}"}
remove_tag => [ "_grokparsefailure" ]
add_tag => [ "nginx_access" ]
}
}
output {
elasticsearch {
index => "abc" #将结果输出到es
}
}
3.运行
先启动logstash
#启动 --config.test_and_exit 用于测试配置文件是否正确
bin/logstash -f logstash.conf --config.test_and_exit
#正式启动 --config.reload.automatic 热加载配置文件,修改配置文件后无需重新启动
bin/logstash -f logstash.conf --config.reload.automatic
,再启动filebeat
./filebeat -e -c filebeat.yml
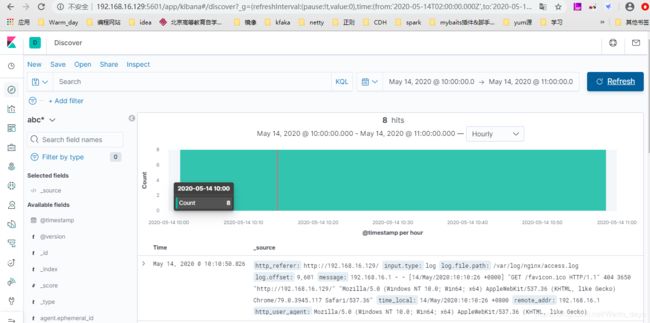
刷新浏览器之后kibana页面显示的点击次数