数据库系统概论三
1、SQL语言的特点
1、综合统一。 2、高度非过程化。
3、面向集合的操作方式。 4、以同一种语法结构提供多种使用方式
5、语言简洁、易学易用。
2、SQL语言的数据查询,数据定义,数据操纵功能,这些分别有哪些SQL语句?
1、数据定义:定义数据库中的基本对象、模式(架构)定义、表定义、视图和索引。

注意:SQL(Oracle除外)一般不提供修改视图定义和索引定义的操作,需要先删除再重建
(1)模式:
定义模式:CREATE SCHEMA <模式名> AUTHORIZATION <用户名>[<表定义子句>|<视图定义子句>|<授权定义子句>]
例:CREATE SCHEMA TEST AUTHORIZATION ZHANG
CREATE TABLE TAB1(COL1 SMALLINT, COL2 INT,COL3 CHAR(20),COL4 NUMERIC(10,3),COL5 DECIMAL(5,2));
为用户ZHANG创建了一个模式TEST,并在其中定义了一个表TAB1。
删除模式:DROP SCHEMA <模式名>
CASCADE(级联):删除模式的同时把该模式中所有的数据库对象全部删除
RESTRICT(限制); 没有任何下属的对象时 才能执行。
(2)表:
定义基本表:CREATE TABLE <表名>
(<列名> <数据类型>[ <列级完整性约束条件> ]
[,<列名> <数据类型>[ <列级完整性约束条件>] ] …
[,<表级完整性约束条件> ] );
列级完整性约束--涉及到该表的一个属性
-
- NOT NULL :非空值约束
- UNIQUE:唯一性(单值约束)约束
- PRIMARY KEY:主码约束
- DEFAULT <默认值>:默认(缺省)约束
- Check < (逻辑表达式) >:核查约束,定义校验条件
- NOT NULL :非空值约束
- UNIQUE:唯一性(单值约束)约束
- PRIMARY KEY:主码约束
- DEFAULT <默认值>:默认(缺省)约束
- Check < (逻辑表达式) >:核查约束,定义校验条件
表级完整性约束--涉及到该表的一个或多个属性。
-
- UNIQUE(属性列列表) :限定各列取值唯一
- PRIMARY KEY (属性列列表) :指定主码
- FOREIGN KEY (属性列列表) REFERENCES <表名> [(属性列列表)]
- Check(<逻辑表达式>) :检查约束
- PRIMARY KEY与 UNIQUE的区别?
例:建立“学生”表Student,学号是主码,姓名取值唯一
CREATE TABLE Student
(Sno CHAR(9) PRIMARY KEY,/*主码*/
Sname CHAR(20) UNIQUE, /* Sname取唯一值*/
Ssex CHAR(2),Sage SMALLINT,Sdept CHAR(20));
数据类型

修改基本表:ALTER TABLE <表名>
[ ADD <新列名> <数据类型> [ 完整性约束 ] ]
[ DROP <列名> |<完整性约束名> ]
[ ALTER COLUMN<列名> <数据类型> ];
例:向Student表增加“入学时间”列,其数据类型为日期型
ALTER TABLE Student ADD S_entrance DATE;
不论基本表中原来是否已有数据,新增加的列一律为空值
将年龄的数据类型由字符型(假设原来的数据类型是字符型)改为整数
ALTER TABLE Student ALTER COLUMN Sage INT;
注:修改原有的列定义有可能会破坏已有数据
增加课程名称必须取唯一值的约束条件。
ALTER TABLE Course ADD UNIQUE(Cname);
直接删除属性列:(新标准) 例: ALTER TABLE Student Drop Sage;
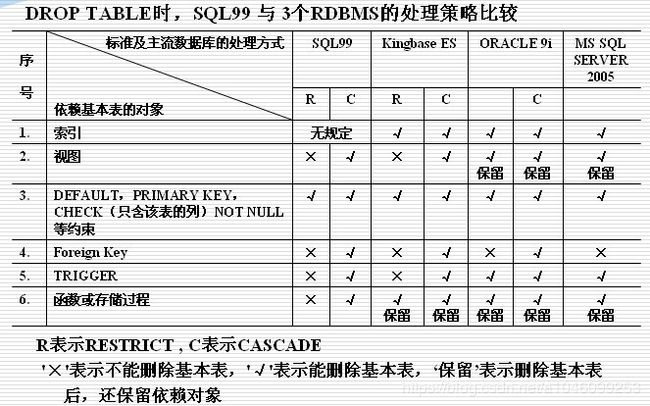
删除基本表 :DROP TABLE <表名>[RESTRICT| CASCADE];
RESTRICT:(受限) 欲删除的基本表不能被其他表的约束所引用,如果存在依赖该表的对象(触发器,视图等),则此表不能被删除。
CASCADE:(级联)在删除基本表的同时,相关的依赖对象一起删除。
例:删除Student表 DROP TABLE Student CASCADE ;
基本表定义被删除,数据被删除;表上建立的索引、视图、触发器等一般也将被删除 。
(3)索引:
建立索引的目的:加快查询速度。
DBA 或 表的属主(即建立表的人)(显式);DBMS一般会自动建立以下约束列上的索引(隐式)PRIMARY KEY UNIQUE 建立索引。
CREATE [UNIQUE] [CLUSTER] INDEX <索引名>
ON <表名> (<列名>[<次序>][,<列名>[<次序>] ]…);
用<次序>指定索引值的排列次序,升序:ASC,降序:DESC。默认:ASC。
UNIQUE表明此索引的每一个索引值只对应唯一的数据记录
CLUSTER表示要建立的索引是聚簇索引。索引项顺序与表中记录的物理顺序一致。
聚簇索引 CLUSTER
例:CREATE CLUSTER INDEX Stusname ON Student(Sname);
在Student表的Sname(姓名)列上建立一个聚簇索引,而 且Student表中的记录将按照Sname值的升序存放。
一个基本表上最多只能建立一个聚簇索引;在最经常查询的列上建立聚簇索引以提高查询效率;经常更新的列不宜建立聚簇索引。
唯一值索引 UNIQUE
例:为学生-课程数据库中的Student,Course,SC三个表建 立索引
CREATE UNIQUE INDEX SCno ON SC(Sno ASC,Cno DESC);
对于已含重复值的属性列不能建UNIQUE索引 。对某个列建立UNIQUE索引后,插入新记录时DBMS会自动检查新记录在该列上是否取了重复值。这相当于增加了一个UNIQUE约束。
删除索引 :DROP INDEX <索引名>;
删除索引时,系统会从数据字典中删去有关该索引的描述。
例: 删除Student表的Stusname索引:DROP INDEX Stusname
2、数据查询:基本格式
Select A1,A2,…,An
From R1,R2,.., Rm
Where F