参考:http://liuyuan418921673.iteye.com/blog/2256120
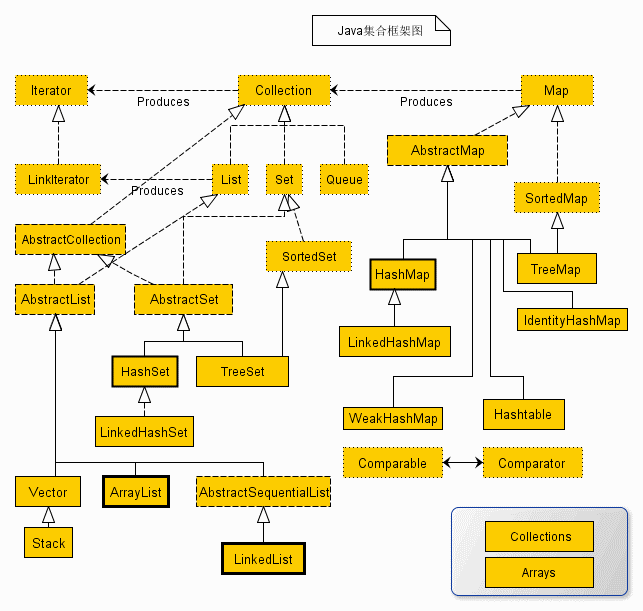
1. ArrayList和LinkedList的区别和使用场景
ArryList 与linkedList 都实现了List 接口
ArrayList:实现list接口 采用数组结构保存对象
优点:便于对集合进行快速的随机访问 查询操作效率比较高
缺点:插入和删除操作效率比较低
原因:指定位置索引插入对象时,会同时将此索引位置之后的所有对象相应的向后移动一位。删除会同时向前移动一位。
linkedList:实现list接口 采用链表结构保存对象
优点:插入和删除操作效率比较高
缺点:查询操作效率比较低
原因:链表结构在插入对象时只需要简单的需该链接位置,省去了移动对象的操作 在查询上LinkedList只能从链表的一端移动到另一端故效率较低
使用场景:
ArrayList使用场景:一般顺序遍历情况下使用ArrayList 尽量不对ArrayList进行插入或删除操作(删除尾部除外),若有多次删除/插入操作又有随机遍历的需求,可以再构建一个ArrayList,把复合条件的对象放入新ArrayList,而不要频繁操作原ArrayList
LinkedList使用场景:经常有删除/插入操作而顺序遍历列表
3. HashSet与TreeSet的使用场景
HashSet:哈希表是通过使用称为散列法的机制来存储信息的,元素并没有以某种特定顺序来存放
TreeSet:提供一个使用树结构存储Set接口的实现(红黑树算法),对象以升序顺序存储,访问和遍历的时间很快。
使用场景:HashSet是基于Hash算法实现的,其性能通常都优于TreeSet。我们通常都应该使用HashSet,在我们需要排序的功能时,我们才使用TreeSet。
4.HashSet与TreeSet的底层运行方式:
HashSet集合对象的加入过程:
hashset底层是hash值的地址,它里面存的对象是无序的。
第一个对象进入集合时,hashset会调用object类的hashcode根据对象在堆内存里的地址调用对象重写的hashcode计算出一个hash值,然后第一个对象就进入hashset集合中的任意一个位置。
第二个对象开始进入集合,hashset先根据第二个对象在堆内存的地址调用对象的计算出一个hash值,如果第二个对象和第一个对象在堆内存里的地址是相同的,那么得到的hash值也是相同的,直接返回true,hash得到true后就不把第二个元素加入集合(这段是hash源码程序中的操作)。如果第二个对象和第一个对象在堆内存里地址是不同的,这时hashset类会先调用自己的方法遍历集合中的元素,当遍历到某个元素时,调用对象的equals方法,如果相等,返回true,则说明这两个对象的内容是相同的,hashset得到true后不会把第二个对象加入。
TreeSet集合对象的加入过程:
TreeSet的底层是通过二叉树来完成存储的,无序的集合
当我们将一个对象加入treeset中,treeset会将第一个对象作为根对象,然后调用对象的compareTo方法拿第二个对象和第一个比较,当返回至=0时,说明2个对象内容相等,treeset就不把第二个对象加入集合。返回>1时,说明第二个对象大于第一个对象,将第二个对象放在右边,返回-1时,则将第二个对象放在左边,依次类推
5. HashMap与TreeMap的使用场景
HashMap通过hashcode对其内容进行快速查找,而 TreeMap中所有的元素都保持着某种固定的顺序,如果你需要得到一个有序的结果你就应该使用TreeMap(HashMap中元素的排列顺序是不固定的)。
使用场景
HashMap:适用于在Map中插入、删除和定位元素。
Treemap:适用于按自然顺序或自定义顺序遍历键(key)
对于定位一个值,插入一个数目以及删除一个条目而言,HashMap是高效的。
6. HashMap 与 TreeMap 与 LinkedHashMAp
HashMap 是 无序的
TreeMap 是按键的升序排列的。
LinkedHashMap 是 按元素最后一次访问的时间从早到晚排序的。