数据分析入门之KNN影片类型和癌症预测
文章目录
- 1、预测电影类型
- 1.1、导入相关库
- 1.2、导入数据
- 1.3、切分出 x 和 y
- 1.4、声明算法
- 1.5、进行训练
- 1.6、生成数据(导入预测值)
- 1.7、使用算法进行预测
- 2、预测是否患癌症
- 2.1、获取数据
- 2.1.1、导入数据
- 2.1.2、切分出 x数据 和 y目标值
- 2.1.3、分出训练集和测试集
- 2.3、声明算法并学习
- 2.4、结果预测
- 2.5、概率预测
- 2.6、预测值与真实值对比
- 2.7、计算预测的准确率
- 方法一:均值法
- 方法二:knn.score()
操作环境: window10,Python3.7,Jupyter notebook
数据资料: https://www.lanzous.com/i96s2id
1、预测电影类型
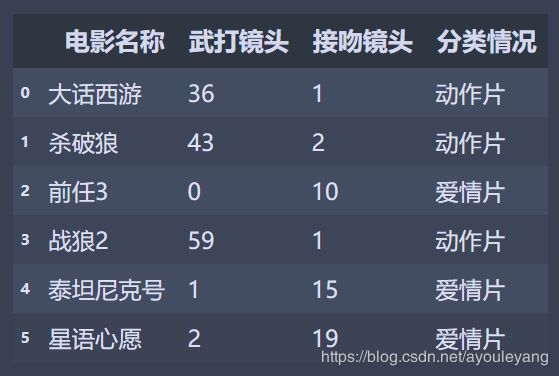
- 一部电影的类型可以通过它的 武打镜头 和 接吻镜头 的多少了确定影片是
动作片还是爱情片
| 电影名称 | 武打镜头 | 接吻镜头 | 分类情况 |
|---|---|---|---|
| 大话西游 | 36 | 1 | 动作片 |
| 杀破狼 | 43 | 2 | 动作片 |
| 前任3 | 0 | 10 | 爱情片 |
| 战狼2 | 59 | 1 | 动作片 |
| 泰坦尼克号 | 1 | 15 | 爱情片 |
| 星语心愿 | 2 | 19 | 爱情片 |
1.1、导入相关库
import numpy as np
import pandas as pd
from pandas import Series, DataFrame
from sklearn.neighbors import KNeighborsClassifier
1.2、导入数据
- 准备数据,Dataframe类型的数据,numpy类型的数据
- 数据 x 必须是二维的[[样本一], [样本二], [样本三]]
- 目标值 y 没有定义要求
data = pd.read_excel('movies.xlsx', sheet_name=1)
data
1.3、切分出 x 和 y
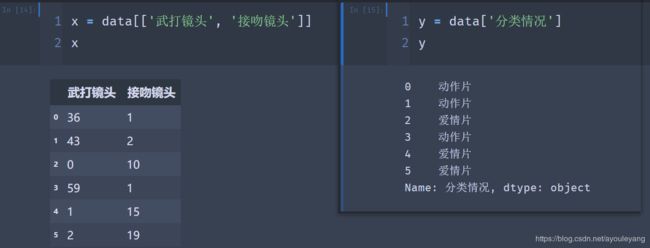
x = data[['武打镜头', '接吻镜头']]
y = data['分类情况']
1.4、声明算法
knn = KNeighborsClassifier(n_neighbors=5)
1.5、进行训练
knn.fit(x, y)
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=None, n_neighbors=5, p=2,
weights='uniform')
1.6、生成数据(导入预测值)
1、碟中谍6——>动作片
2、李茶的姑妈——>爱情片
x_test = np.array([[100, 2], [2, 15]])
1.7、使用算法进行预测
knn.predict(x_test)
array(['动作片', '爱情片'], dtype=object)
2、预测是否患癌症
- 细胞核的特征:
- 第一个特征是ID;第二个特征是这个案例的癌症诊断结果,编码“M”表示恶性,“B”表示良性。
- 其他30个特征是数值的其他指标,包括细胞核的半径(Radius)、质地(Texture)、周长(Perimeter)、面积(Area)和光滑度(Smoothness)等的均值、标准差和最大值。
2.1、获取数据
- x数据,样本(人)特征,细胞核的质地、光滑度等
- y目标值,样本(人)诊断结果、两种:M恶性,B良性
2.1.1、导入数据
import numpy as np
import pandas as pd
from pandas import Series, DataFrame
from sklearn.neighbors import KNeighborsClassifier
# 导入数据
# 二分类问题,良性和恶行
data = pd.read_csv('cancer.csv', sep='\t')
data
| ID | Diagnosis | radius_mean | texture_mean | perimeter_mean | area_mean | smoothness_mean | compactness_mean | concavity_mean | concave_mean | ... | radius_max | texture_max | perimeter_max | area_max | smoothness_max | compactness_max | concavity_max | concave_max | symmetry_max | fractal_max | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 842302 | M | 17.99 | 10.38 | 122.80 | 1001.0 | 0.11840 | 0.27760 | 0.30010 | 0.14710 | ... | 25.380 | 17.33 | 184.60 | 2019.0 | 0.16220 | 0.66560 | 0.7119 | 0.2654 | 0.4601 | 0.11890 |
| 1 | 842517 | M | 20.57 | 17.77 | 132.90 | 1326.0 | 0.08474 | 0.07864 | 0.08690 | 0.07017 | ... | 24.990 | 23.41 | 158.80 | 1956.0 | 0.12380 | 0.18660 | 0.2416 | 0.1860 | 0.2750 | 0.08902 |
| 2 | 84300903 | M | 19.69 | 21.25 | 130.00 | 1203.0 | 0.10960 | 0.15990 | 0.19740 | 0.12790 | ... | 23.570 | 25.53 | 152.50 | 1709.0 | 0.14440 | 0.42450 | 0.4504 | 0.2430 | 0.3613 | 0.08758 |
| 3 | 84348301 | M | 11.42 | 20.38 | 77.58 | 386.1 | 0.14250 | 0.28390 | 0.24140 | 0.10520 | ... | 14.910 | 26.50 | 98.87 | 567.7 | 0.20980 | 0.86630 | 0.6869 | 0.2575 | 0.6638 | 0.17300 |
| 4 | 84358402 | M | 20.29 | 14.34 | 135.10 | 1297.0 | 0.10030 | 0.13280 | 0.19800 | 0.10430 | ... | 22.540 | 16.67 | 152.20 | 1575.0 | 0.13740 | 0.20500 | 0.4000 | 0.1625 | 0.2364 | 0.07678 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 564 | 926424 | M | 21.56 | 22.39 | 142.00 | 1479.0 | 0.11100 | 0.11590 | 0.24390 | 0.13890 | ... | 25.450 | 26.40 | 166.10 | 2027.0 | 0.14100 | 0.21130 | 0.4107 | 0.2216 | 0.2060 | 0.07115 |
| 565 | 926682 | M | 20.13 | 28.25 | 131.20 | 1261.0 | 0.09780 | 0.10340 | 0.14400 | 0.09791 | ... | 23.690 | 38.25 | 155.00 | 1731.0 | 0.11660 | 0.19220 | 0.3215 | 0.1628 | 0.2572 | 0.06637 |
| 566 | 926954 | M | 16.60 | 28.08 | 108.30 | 858.1 | 0.08455 | 0.10230 | 0.09251 | 0.05302 | ... | 18.980 | 34.12 | 126.70 | 1124.0 | 0.11390 | 0.30940 | 0.3403 | 0.1418 | 0.2218 | 0.07820 |
| 567 | 927241 | M | 20.60 | 29.33 | 140.10 | 1265.0 | 0.11780 | 0.27700 | 0.35140 | 0.15200 | ... | 25.740 | 39.42 | 184.60 | 1821.0 | 0.16500 | 0.86810 | 0.9387 | 0.2650 | 0.4087 | 0.12400 |
| 568 | 92751 | B | 7.76 | 24.54 | 47.92 | 181.0 | 0.05263 | 0.04362 | 0.00000 | 0.00000 | ... | 9.456 | 30.37 | 59.16 | 268.6 | 0.08996 | 0.06444 | 0.0000 | 0.0000 | 0.2871 | 0.07039 |
2.1.2、切分出 x数据 和 y目标值
- 将数据一分为二,划分后数据是一 一对应的
# 诊断结果、目标值
y = data['Diagnosis']
# 训练数据,特征,细胞核一系列特征,光滑度,质地等
x = data.iloc[:,2:] #第二列后面的所有数据
2.1.3、分出训练集和测试集
from sklearn.model_selection import train_test_split
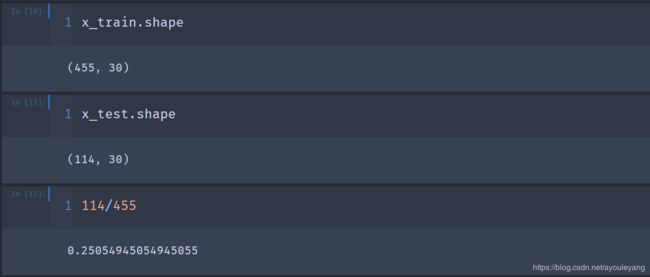
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2) #使用20%的数据来测试数据
2.3、声明算法并学习
knn = KNeighborsClassifier()
# 算法学习455个样本
knn.fit(x_train, y_train)
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=None, n_neighbors=5, p=2,
weights='uniform')
2.4、结果预测
# 使用算法进行预测
y_pre = knn.predict(x_test)
y_pre
array(['B', 'B', 'B', 'B', 'B', 'M', 'M', 'B', 'B', 'M', 'B', 'B', 'M',
'B', 'B', 'B', 'M', 'B', 'B', 'M', 'M', 'B', 'M', 'M', 'B', 'B',
'B', 'B', 'B', 'B', 'B', 'B', 'B', 'M', 'B', 'B', 'M', 'M', 'M',
'B', 'M', 'M', 'B', 'B', 'B', 'M', 'B', 'B', 'M', 'M', 'M', 'B',
'B', 'B', 'B', 'B', 'M', 'B', 'M', 'B', 'B', 'B', 'M', 'B', 'M',
'B', 'M', 'B', 'B', 'B', 'B', 'B', 'M', 'B', 'B', 'B', 'B', 'B',
'M', 'B', 'M', 'B', 'M', 'B', 'M', 'B', 'B', 'B', 'B', 'B', 'M',
'M', 'M', 'B', 'M', 'M', 'B', 'B', 'B', 'B', 'B', 'M', 'B', 'M',
'B', 'B', 'B', 'M', 'B', 'B', 'M', 'B', 'B', 'M'], dtype=object)
2.5、概率预测
knn.predict_proba(x_test) # proba概率
array([[1. , 0. ],
[0.8, 0.2],
[1. , 0. ],
[1. , 0. ],
[1. , 0. ],
......
[1. , 0. ],
[0. , 1. ],
[1. , 0. ],
[0.6, 0.4],
[0. , 1. ]])
2.6、预测值与真实值对比
# 真实情况进行比对,验证算法好不好
display(y_pre)
# 刚才保留,真实的数据
display(y_test.values)
array(['B', 'B', 'B', 'B', 'B', 'M', 'M', 'B', 'B', 'M', 'B', 'B', 'M',
'B', 'B', 'B', 'M', 'B', 'B', 'M', 'M', 'B', 'M', 'M', 'B', 'B',
'B', 'B', 'B', 'B', 'B', 'B', 'B', 'M', 'B', 'B', 'M', 'M', 'M',
'B', 'M', 'M', 'B', 'B', 'B', 'M', 'B', 'B', 'M', 'M', 'M', 'B',
'B', 'B', 'B', 'B', 'M', 'B', 'M', 'B', 'B', 'B', 'M', 'B', 'M',
'B', 'M', 'B', 'B', 'B', 'B', 'B', 'M', 'B', 'B', 'B', 'B', 'B',
'M', 'B', 'M', 'B', 'M', 'B', 'M', 'B', 'B', 'B', 'B', 'B', 'M',
'M', 'M', 'B', 'M', 'M', 'B', 'B', 'B', 'B', 'B', 'M', 'B', 'M',
'B', 'B', 'B', 'M', 'B', 'B', 'M', 'B', 'B', 'M'], dtype=object)
array(['B', 'B', 'B', 'B', 'B', 'M', 'M', 'M', 'B', 'M', 'B', 'B', 'B',
'B', 'B', 'B', 'M', 'B', 'B', 'M', 'M', 'B', 'M', 'M', 'B', 'B',
'B', 'B', 'B', 'B', 'B', 'B', 'B', 'M', 'B', 'B', 'M', 'M', 'M',
'B', 'M', 'M', 'M', 'B', 'B', 'B', 'B', 'M', 'M', 'M', 'M', 'B',
'B', 'B', 'B', 'B', 'M', 'B', 'M', 'B', 'B', 'B', 'M', 'B', 'M',
'B', 'M', 'B', 'B', 'B', 'B', 'B', 'M', 'B', 'B', 'B', 'B', 'B',
'M', 'B', 'M', 'B', 'M', 'B', 'M', 'B', 'B', 'B', 'B', 'B', 'M',
'B', 'M', 'B', 'M', 'M', 'B', 'B', 'B', 'B', 'B', 'M', 'B', 'M',
'M', 'B', 'B', 'M', 'B', 'B', 'M', 'B', 'M', 'M'], dtype=object)
2.7、计算预测的准确率
方法一:均值法
- 用预测值和真实值对比,返回结果为 True 和 False ,对其求均值得到准确率
(y_pre == y_test.values).mean()
0.9298245614035088
方法二:knn.score()
knn.score(x_test, y_test) #x_test是用来测试的数据, y_test是真实的数据
0.9298245614035088