C嵌入汇编之vld1.f32和vst1.f32指令理解
想完成类似与memcpy,使用arm的neon指令完成,第一次代码
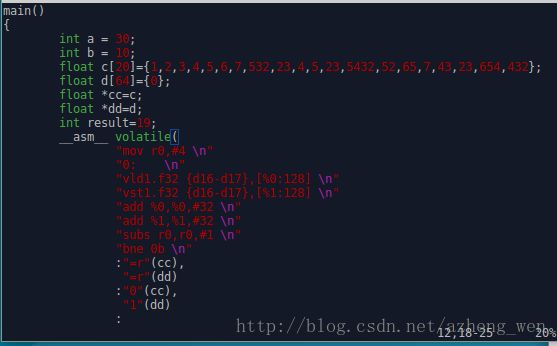
关键点
第一点:
add %0,%0,#32,表示每次移动32/4=8个float
第二点:
subs r0,r0,#1才能改变状态标志位,sub不行
第三点:
vld1.f32 {d16-d17},[%0:128]
add %0,%0,#16 //16=128/32*4,移动%0到第四个位置
与
vld1.f32 {d16-d17},[%0:128]!
是一个意思,这里加个!表示做完vld,并将%0更新(加上其传送的字节数)!

以下代码是为了验证当内嵌汇编程序传入参数过多时,可以通过连续内存来传参,具体规则可以参考https://www.cnblogs.com/crmn/articles/6580139.html
主要几点:
1、子程序间通过寄存器r0-r3传参,寄存器r4-r11来保存局部变量,如果在子程序中用到了r4-r11,需要保存这些寄存器的值;
2、对于参数个数可变的子程序,当参数不超过4个时,可以使用寄存器R0~R3来进行参数传递,当参数超过4个时,还可以使用数据栈来传递参数,在参数传递时,将所有参数看做是存放在连续的内存单元中的字数据。然后,依次将各名字数据传送到寄存器R0,R1,R2,R3;
3、 对于参数个数固定的子程序,参数传递与参数个数可变的子程序参数传递规则不同,如果系统包含浮点运算的硬件部件。 浮点参数将按照下面的规则传递: (1)各个浮点参数按顺序处理; (2)为每个浮点参数分配FP寄存器; 分配的方法是,满足该浮点参数需要的且编号最小的一组连续的FP寄存器.第一个整数参数通过寄存器R0~R3来传递,其他参数通过数据栈传递.
4、子程序结果返回规则:1.结果为一个32位的整数时,可以通过寄存器R0返回.2.结果为一个64位整数时,可以通过R0和R1返回,依此类推. 3.结果为一个浮点数时,可以通过浮点运算部件的寄存器f0,d0或者s0来返回. 4.结果为一个复合的浮点数时,可以通过寄存器f0-fN或者d0~dN来返回.5.对于位数更多的结果,需要通过调用内存来传递.
看完这篇博客后,我感觉还是很晕,于是采用了下面的方法:
int za1[8] = { 0,1,2,3,4,5,6,7 };
int za2[8] = { 10,11,12,13,14,15,16,17 };
int za3[8] = { 30,31,32,33,34,35,36,37 };
int za4[8] = { 40,41,42,43,44,45,46,47};
int za5[8] = { 50,51,52,53,54,55,56,57 };
int za6[8] = { 60,61,62,63,64,65,66,67};
int za7[8] = { 70,71,72,73,74,75,76,77};
int* test_data = (int*)malloc(4*sizeof(int));
int* tmp[] = { za1,za2,za3,za4,za5,za6,za7}; //
int** tmp_addr = tmp;
__asm__ volatile(
//"ld1 {v0.16b}, [%0],#16 \n"
//"vld1.f32 {d0-d1},[%0:128] \n"
"ldr r0,[%0,#20] \n" //za6
"add r0, r0,#4 \n" //r0偏移4个字节,即加载61 62 63 64
"vld1.f32 {d0-d1},[r0] \n" //:128表示字节对齐
"vst1.f32 {d0-d1},[%1] \n"
:"=r"(tmp_addr),
"=r"(test_data)
:"0"(tmp_addr),
"1"(test_data)
);
printf("res\n");
for (int zz = 0; zz < 4; zz++)
{
printf("%8d",test_data[zz]);
}
printf("\n");通过tmp_addr指向的连续内存,能够获取所需的参数。
写的时候还是需要注意下:
1、数组名不能当参数传入嵌入汇编中,不然会报错。。。(坑了好久)
2、vld.f32 {d0-d1},[r0:128]中的128表示对齐规则,如果不是对齐的,也会有bus error;